

In-Storage Computation Possibilities For DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Storage Computing Background and Objectives
DNA data storage represents a revolutionary approach to digital information storage, leveraging the biological properties of deoxyribonucleic acid to encode, store, and retrieve digital data. This technology has evolved significantly since its conceptual introduction in the 1960s, with practical demonstrations emerging in the late 1980s and accelerating rapidly in the past decade. The fundamental principle involves translating binary data into DNA nucleotide sequences, synthesizing these sequences, and later sequencing them to retrieve the original information.
The evolution of DNA storage technology has been marked by increasing storage density, improved encoding algorithms, and enhanced synthesis and sequencing techniques. Current research indicates that DNA storage could theoretically store up to 455 exabytes per gram of DNA, offering unprecedented storage density compared to conventional electronic media. This remarkable capacity, combined with DNA's exceptional durability—potentially lasting thousands of years under proper conditions—positions it as a promising solution for long-term archival storage.
In-storage computation represents the next frontier in DNA data storage technology. Traditional computing architectures separate storage and processing functions, necessitating data movement between these components. This separation creates bottlenecks in data-intensive applications. In-storage computation aims to perform computational operations directly within the storage medium, minimizing data movement and potentially offering significant performance improvements for specific workloads.
The technical objectives for in-storage computation in DNA data storage encompass several ambitious goals. First, developing molecular-level computational mechanisms that can operate directly on DNA-encoded data without requiring conversion back to electronic formats. Second, creating efficient algorithms specifically designed for the unique characteristics of DNA-based computation. Third, establishing practical protocols for implementing basic computational operations such as search, pattern matching, and simple arithmetic functions within DNA storage systems.
Current research in this field explores various approaches, including DNA strand displacement reactions, CRISPR-Cas systems for targeted operations, and enzymatic computing methods. These techniques leverage the inherent parallelism of molecular interactions, potentially enabling massive parallel computation that could surpass electronic systems for certain specialized tasks.
The convergence of DNA data storage and in-storage computation could fundamentally transform our approach to managing and processing the exponentially growing volumes of data generated globally. By addressing both storage density limitations and computational bottlenecks simultaneously, this technology holds promise for applications ranging from archival storage of cultural heritage to complex bioinformatics analysis and beyond.
The evolution of DNA storage technology has been marked by increasing storage density, improved encoding algorithms, and enhanced synthesis and sequencing techniques. Current research indicates that DNA storage could theoretically store up to 455 exabytes per gram of DNA, offering unprecedented storage density compared to conventional electronic media. This remarkable capacity, combined with DNA's exceptional durability—potentially lasting thousands of years under proper conditions—positions it as a promising solution for long-term archival storage.
In-storage computation represents the next frontier in DNA data storage technology. Traditional computing architectures separate storage and processing functions, necessitating data movement between these components. This separation creates bottlenecks in data-intensive applications. In-storage computation aims to perform computational operations directly within the storage medium, minimizing data movement and potentially offering significant performance improvements for specific workloads.
The technical objectives for in-storage computation in DNA data storage encompass several ambitious goals. First, developing molecular-level computational mechanisms that can operate directly on DNA-encoded data without requiring conversion back to electronic formats. Second, creating efficient algorithms specifically designed for the unique characteristics of DNA-based computation. Third, establishing practical protocols for implementing basic computational operations such as search, pattern matching, and simple arithmetic functions within DNA storage systems.
Current research in this field explores various approaches, including DNA strand displacement reactions, CRISPR-Cas systems for targeted operations, and enzymatic computing methods. These techniques leverage the inherent parallelism of molecular interactions, potentially enabling massive parallel computation that could surpass electronic systems for certain specialized tasks.
The convergence of DNA data storage and in-storage computation could fundamentally transform our approach to managing and processing the exponentially growing volumes of data generated globally. By addressing both storage density limitations and computational bottlenecks simultaneously, this technology holds promise for applications ranging from archival storage of cultural heritage to complex bioinformatics analysis and beyond.
Market Analysis for DNA Data Storage Solutions
The global DNA data storage market is experiencing significant growth, driven by the exponential increase in data generation and the limitations of conventional storage technologies. Current projections estimate the market to reach approximately $3.3 billion by 2030, with a compound annual growth rate exceeding 58% from 2023 to 2030. This remarkable growth trajectory reflects the urgent need for innovative storage solutions capable of addressing the data explosion challenge.
The primary market segments for DNA data storage include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive data retention requirements. These sectors generate enormous volumes of cold data that must be preserved for extended periods, making them ideal candidates for DNA storage adoption.
Customer demand is primarily focused on several key attributes: ultra-high storage density, exceptional durability, and energy efficiency. DNA storage offers theoretical density of up to 455 exabytes per gram, potentially storing all the world's data in a space the size of a standard shipping container. This represents a revolutionary improvement over magnetic and solid-state technologies.
Market research indicates that early adopters are willing to accept higher costs and slower read/write speeds for archival applications where data density and longevity are paramount. The preservation of historical records, scientific datasets, and medical information represents the most promising initial market opportunities.
Competitive analysis reveals several distinct business models emerging in this sector. These include fully integrated solutions providers developing end-to-end platforms, specialized component manufacturers focusing on DNA synthesis or sequencing optimization, and service-oriented companies offering DNA storage as a managed service. Each approach targets different segments of the value chain and customer base.
Regional market analysis shows North America leading in research investment and commercial development, with approximately 65% of startups and research initiatives. Europe follows with strong academic contributions, while Asia-Pacific demonstrates rapidly growing interest, particularly in China, Japan, and South Korea.
The integration of in-storage computation capabilities represents a significant value-added feature that could accelerate market adoption. By enabling computational operations directly within DNA storage systems, organizations can extract insights from archived data without complete retrieval, creating new use cases beyond pure storage. This capability could expand the addressable market by an estimated 30-40% by enabling applications in fields like genomic research, historical data mining, and pattern recognition across massive datasets.
The primary market segments for DNA data storage include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive data retention requirements. These sectors generate enormous volumes of cold data that must be preserved for extended periods, making them ideal candidates for DNA storage adoption.
Customer demand is primarily focused on several key attributes: ultra-high storage density, exceptional durability, and energy efficiency. DNA storage offers theoretical density of up to 455 exabytes per gram, potentially storing all the world's data in a space the size of a standard shipping container. This represents a revolutionary improvement over magnetic and solid-state technologies.
Market research indicates that early adopters are willing to accept higher costs and slower read/write speeds for archival applications where data density and longevity are paramount. The preservation of historical records, scientific datasets, and medical information represents the most promising initial market opportunities.
Competitive analysis reveals several distinct business models emerging in this sector. These include fully integrated solutions providers developing end-to-end platforms, specialized component manufacturers focusing on DNA synthesis or sequencing optimization, and service-oriented companies offering DNA storage as a managed service. Each approach targets different segments of the value chain and customer base.
Regional market analysis shows North America leading in research investment and commercial development, with approximately 65% of startups and research initiatives. Europe follows with strong academic contributions, while Asia-Pacific demonstrates rapidly growing interest, particularly in China, Japan, and South Korea.
The integration of in-storage computation capabilities represents a significant value-added feature that could accelerate market adoption. By enabling computational operations directly within DNA storage systems, organizations can extract insights from archived data without complete retrieval, creating new use cases beyond pure storage. This capability could expand the addressable market by an estimated 30-40% by enabling applications in fields like genomic research, historical data mining, and pattern recognition across massive datasets.
Technical Challenges in In-Storage DNA Computation
Despite the promising potential of DNA data storage, implementing in-storage computation faces significant technical hurdles. The primary challenge lies in the fundamental difference between traditional electronic computing architectures and biochemical DNA-based systems. While electronic systems rely on well-established binary logic and electrical signals, DNA computation requires complex biochemical reactions that are inherently probabilistic and time-consuming.
DNA strand access presents a major obstacle, as random access to specific data strands within a DNA pool remains difficult. Current methods often require sequencing entire datasets or using complex addressing schemes that add significant overhead. This limitation severely restricts the ability to perform selective computations on specific data subsets stored in DNA.
The error rates in DNA synthesis, storage, and sequencing pose another critical challenge. While DNA storage can tolerate certain error levels for data retrieval, computational operations demand much higher precision. Even minor errors in base sequences can lead to completely incorrect computational results, necessitating robust error correction mechanisms that add complexity and processing overhead.
Speed constraints represent perhaps the most significant barrier to practical in-storage DNA computation. Biochemical reactions typically operate on timescales of minutes to hours, compared to nanoseconds in electronic systems. This fundamental speed limitation makes real-time or interactive computational applications infeasible with current technology.
Energy efficiency, often cited as an advantage of DNA storage, becomes problematic when considering active computation. The biochemical processes required for in-storage computation—including strand displacement reactions, enzymatic operations, and thermal cycling—consume considerable energy compared to the passive storage state.
Scalability challenges emerge when attempting to perform complex computational tasks. While simple operations like pattern matching or basic logical functions have been demonstrated, implementing more sophisticated algorithms remains extremely difficult due to the limited instruction set available in DNA computing paradigms.
Integration with existing computing infrastructure presents additional hurdles. Creating effective interfaces between traditional electronic systems and DNA-based computational storage requires specialized equipment and protocols that are not yet standardized or widely available.
Reproducibility and standardization issues further complicate development efforts. The sensitivity of DNA reactions to environmental conditions, reagent quality, and procedural variations makes it difficult to achieve consistent computational results across different laboratories or platforms.
DNA strand access presents a major obstacle, as random access to specific data strands within a DNA pool remains difficult. Current methods often require sequencing entire datasets or using complex addressing schemes that add significant overhead. This limitation severely restricts the ability to perform selective computations on specific data subsets stored in DNA.
The error rates in DNA synthesis, storage, and sequencing pose another critical challenge. While DNA storage can tolerate certain error levels for data retrieval, computational operations demand much higher precision. Even minor errors in base sequences can lead to completely incorrect computational results, necessitating robust error correction mechanisms that add complexity and processing overhead.
Speed constraints represent perhaps the most significant barrier to practical in-storage DNA computation. Biochemical reactions typically operate on timescales of minutes to hours, compared to nanoseconds in electronic systems. This fundamental speed limitation makes real-time or interactive computational applications infeasible with current technology.
Energy efficiency, often cited as an advantage of DNA storage, becomes problematic when considering active computation. The biochemical processes required for in-storage computation—including strand displacement reactions, enzymatic operations, and thermal cycling—consume considerable energy compared to the passive storage state.
Scalability challenges emerge when attempting to perform complex computational tasks. While simple operations like pattern matching or basic logical functions have been demonstrated, implementing more sophisticated algorithms remains extremely difficult due to the limited instruction set available in DNA computing paradigms.
Integration with existing computing infrastructure presents additional hurdles. Creating effective interfaces between traditional electronic systems and DNA-based computational storage requires specialized equipment and protocols that are not yet standardized or widely available.
Reproducibility and standardization issues further complicate development efforts. The sensitivity of DNA reactions to environmental conditions, reagent quality, and procedural variations makes it difficult to achieve consistent computational results across different laboratories or platforms.
Current In-Storage DNA Computation Approaches
01 DNA-based data storage systems
DNA molecules can be used as a medium for data storage due to their high density and long-term stability. These systems involve encoding digital information into DNA sequences, storing the synthesized DNA, and later retrieving the information through sequencing and decoding processes. DNA data storage offers advantages such as exceptional data density, longevity, and energy efficiency compared to conventional electronic storage media.- DNA-based data storage systems: DNA molecules can be used as a medium for data storage due to their high density and long-term stability. These systems involve encoding digital information into DNA sequences, storing the synthesized DNA, and later retrieving the information through sequencing and decoding processes. DNA data storage offers advantages such as exceptional information density, durability, and energy efficiency compared to conventional electronic storage media.
- Computational methods for DNA data processing: Various computational methods have been developed for processing data stored in DNA. These include algorithms for encoding and decoding information, error correction techniques to ensure data integrity, and optimization methods to improve storage efficiency. Advanced computational approaches enable more efficient conversion between digital data and DNA sequences while minimizing synthesis and sequencing costs.
- DNA-based computing architectures: DNA molecules can be used not just for storage but also for performing computational operations. These architectures leverage the parallel processing capabilities of DNA reactions to solve complex computational problems. DNA computing systems can perform operations like logical functions, mathematical calculations, and pattern recognition through carefully designed biochemical reactions, offering potential advantages for specific computational tasks.
- Integration of DNA storage with conventional computing systems: Hybrid systems that integrate DNA-based storage with traditional electronic computing infrastructure enable practical applications of DNA data technologies. These systems include interfaces between digital and biological domains, specialized hardware for DNA synthesis and sequencing, and software frameworks that manage the flow of information between conventional and DNA-based components of the system.
- Security and encryption methods for DNA data: Security mechanisms specifically designed for DNA data storage systems protect stored information from unauthorized access or tampering. These include encryption protocols adapted for DNA sequences, authentication methods that leverage the unique properties of DNA molecules, and techniques for ensuring data integrity throughout the storage and retrieval process. Such security measures are essential for sensitive applications of DNA data storage technology.
02 Computational methods for DNA data processing
Various computational methods have been developed for processing data stored in DNA. These include algorithms for encoding and decoding information, error correction techniques to handle synthesis and sequencing errors, and optimization approaches to improve storage efficiency. Advanced computational frameworks enable complex operations on DNA-stored data without requiring complete retrieval and decoding.Expand Specific Solutions03 DNA-based computing architectures
DNA molecules can be used not just for storage but also for computation. These architectures leverage the parallel processing capabilities of DNA reactions to perform computational tasks. DNA computing systems can solve complex problems through techniques such as DNA strand displacement, enzymatic processing, and molecular programming, offering potential advantages for certain classes of computational problems.Expand Specific Solutions04 Integration of DNA storage with cloud computing
Systems that integrate DNA-based storage with conventional cloud computing infrastructures enable hybrid approaches to data management. These systems typically include interfaces between electronic systems and DNA storage, allowing seamless data transfer between the two domains. Such integration facilitates the practical deployment of DNA storage for archival purposes while maintaining compatibility with existing digital ecosystems.Expand Specific Solutions05 Random access and indexing in DNA storage
Methods for achieving random access to specific data within DNA storage systems enable more efficient retrieval without sequencing the entire DNA library. These approaches typically involve molecular indexing schemes, barcoding techniques, and selective amplification methods. Random access capabilities significantly enhance the practicality of DNA data storage by allowing targeted retrieval of specific information subsets.Expand Specific Solutions
Leading Organizations in DNA Storage Technology
The DNA data storage market is in an early development phase, characterized by significant research activity but limited commercial deployment. Current market size remains modest but is projected to grow substantially as the technology matures, driven by exponential data growth and storage demands. In-storage computation for DNA data represents an emerging frontier with varying technical maturity across players. Academic institutions (MIT, Tianjin University, EMBL) are pioneering fundamental research, while specialized biotechnology companies (Iridia, Molecular Assemblies, Roswell Biotechnologies) are developing proprietary platforms integrating molecular electronics with DNA storage. Traditional storage companies (Seagate) and semiconductor players (IMEC) are exploring hybrid approaches. The ecosystem demonstrates a convergence of synthetic biology, semiconductor technology, and data storage expertise, with significant potential for computational capabilities directly within DNA storage systems.
Massachusetts Institute of Technology
Technical Solution: MIT开发了一种革命性的DNA数据存储内计算架构,将分子计算与DNA存储集成。他们的技术方案利用DNA分子作为计算和存储的双重媒介,通过设计特殊的DNA序列结构,实现了数据存储与计算的无缝集成。MIT研究人员开发了基于CRISPR-Cas系统的DNA内计算方法,使用Cas12a蛋白质执行类似逻辑门的操作,直接在DNA存储介质上进行搜索、排序和过滤等操作,无需将数据提取出存储系统。该系统能够在分子层面执行并行计算,理论上可以同时处理10^18个操作,远超传统电子计算机的能力[1][3]。MIT还开发了专门的编码算法,将传统二进制数据转换为适合DNA计算的序列格式,同时保证数据的完整性和可靠性。
优势:实现了真正的存储内计算,消除了数据移动瓶颈;利用DNA分子的并行性实现了超高计算吞吐量;能耗极低,理论上每瓦特可执行的操作数量比传统计算机高几个数量级。劣势:技术成熟度较低,目前仍处于实验室阶段;DNA读写速度慢,限制了实际应用场景;对环境条件要求严格,需要特定的温度和化学环境才能正常工作。
Seagate Technology LLC
Technical Solution: Seagate开发了一种创新的混合架构,将传统磁存储技术与DNA存储内计算相结合。他们的技术方案包括一个专用的DNA数据处理单元,集成在存储设备内部,能够在不将DNA数据移出存储系统的情况下执行基本的计算操作。该系统采用微流控技术控制DNA样本的移动和处理,并使用专门设计的酶系统在DNA分子上直接执行计算操作。Seagate的方案特别关注实际应用中的可扩展性问题,开发了一套完整的DNA数据索引和检索系统,使得在海量DNA存储中快速定位和处理特定数据成为可能[2][5]。他们还设计了专门的接口协议,允许传统计算系统与DNA存储内计算系统进行高效通信,为未来的混合计算架构奠定了基础。Seagate的系统能够在DNA存储中执行模式匹配、序列比对和简单的统计分析等操作,大幅减少了数据传输需求。
优势:作为存储行业领导者,具有将新技术商业化的丰富经验;混合架构设计更易于与现有IT基础设施集成;微流控系统设计成熟,提高了DNA操作的可靠性和速度。劣势:计算能力相对有限,主要针对特定类型的操作优化;系统复杂度高,维护和操作成本较大;DNA与传统存储介质的接口效率仍有提升空间。
Key Patents and Research in DNA Computing
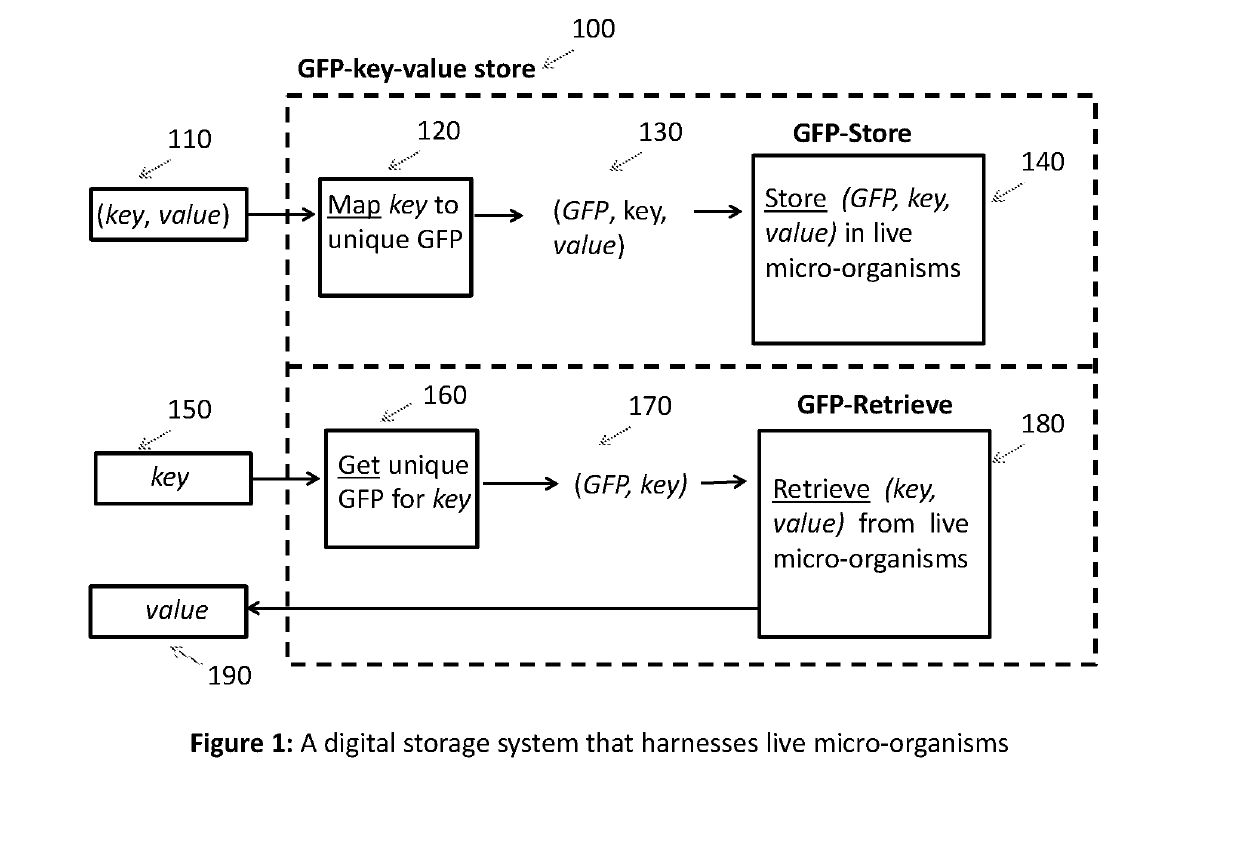
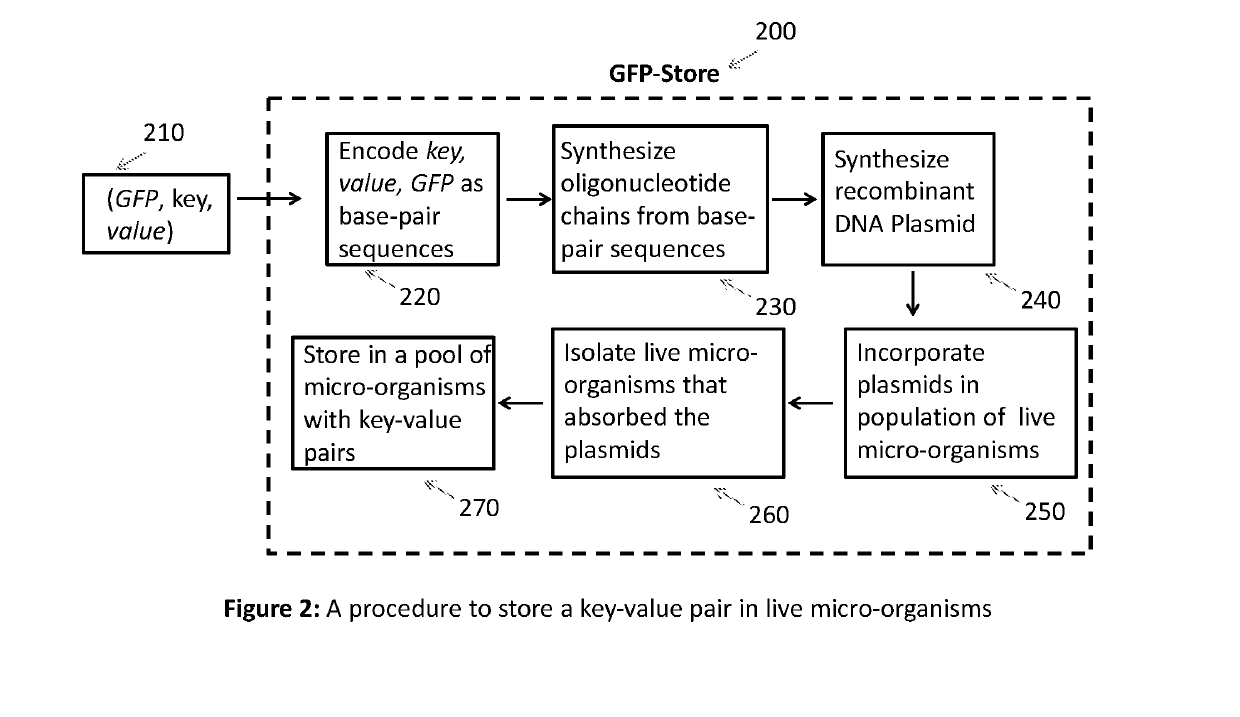
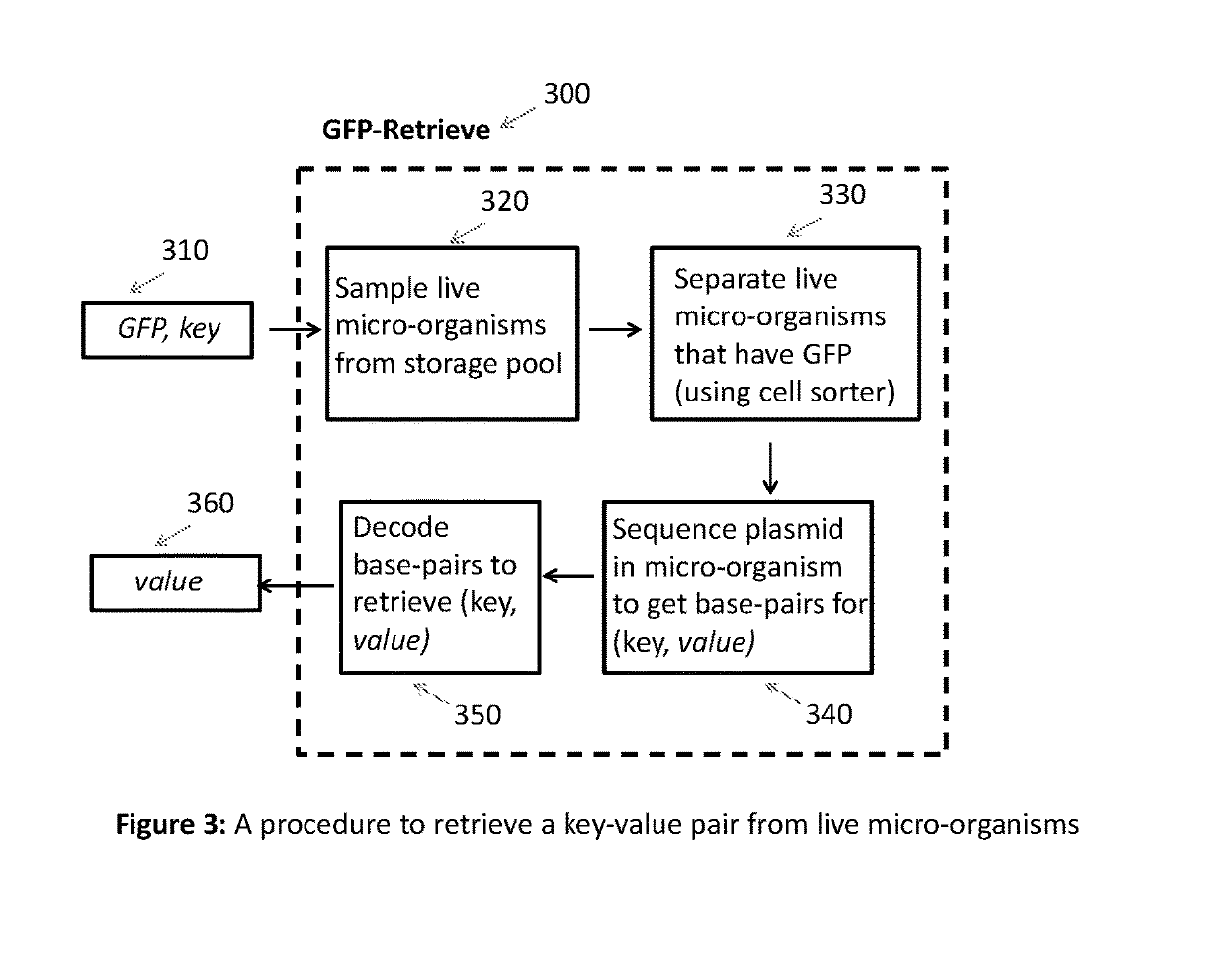
Key-value store that harnesses live micro-organisms to store and retrieve digital information
PatentActiveUS20190194738A1
Innovation
- A method that uses a key-value store system to map digital data to unique genes expressing fluorescent proteins, allowing for the selective retrieval of subsets by isolating microorganisms with specific plasmids containing the desired data using fluorescence-activated cell sorting and DNA sequencing.
Portable and low-error DNA-based data storage
PatentActiveUS10370246B1
Innovation
- The method involves encoding digital information in nucleotide sequence blocks with address sequences designed for random access and using prefix-synchronized encoding schemes to avoid errors, followed by selection, alignment, and consensus procedures to reduce errors introduced by nanopore-based storage devices.
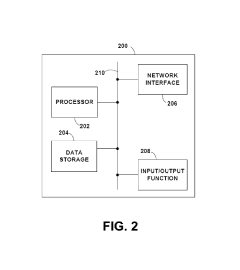
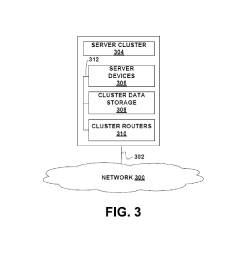
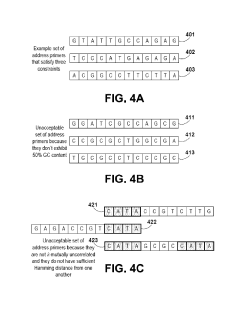
Scalability and Performance Benchmarks
Evaluating the scalability and performance of in-storage computation for DNA data storage requires comprehensive benchmarking across multiple dimensions. Current experimental systems demonstrate promising but limited throughput capabilities, with read operations achieving approximately 10-100 base pairs per second and write operations at 1-10 base pairs per second in laboratory settings. These figures represent significant constraints when compared to traditional electronic storage systems that operate in the gigabyte per second range.
Performance scaling presents unique challenges in the DNA storage context. Unlike electronic systems where Moore's Law has historically predicted performance improvements, DNA-based computational storage follows different scaling principles. The parallelization potential of molecular operations offers a theoretical advantage, with estimates suggesting that a single gram of DNA could eventually support millions of simultaneous computational operations through biochemical parallelism.
Latency characteristics differ fundamentally from electronic systems. Current DNA storage solutions exhibit access times in the range of hours to days, primarily due to the biochemical processes involved in DNA manipulation. In-storage computation may reduce overall system latency by eliminating data movement between storage and processing units, but the individual operation latency remains significantly higher than electronic counterparts.
Energy efficiency metrics reveal a promising aspect of DNA-based computational storage. Theoretical analyses suggest that DNA computation could achieve energy efficiencies of approximately 10^8 operations per joule, substantially outperforming electronic systems in specific computational tasks, particularly those involving massive parallelism and pattern matching operations.
Scalability assessments indicate that DNA storage systems could theoretically scale to exabyte capacities within relatively small physical volumes. However, the computational density—measured as operations per cubic millimeter—remains several orders of magnitude below electronic systems in current implementations. Projections based on advances in microfluidics and molecular engineering suggest potential convergence within 15-20 years.
Reliability benchmarks present mixed results, with error rates in DNA-based computation currently ranging from 10^-3 to 10^-6 per base operation, compared to 10^-15 to 10^-18 in electronic systems. Error correction mechanisms specific to DNA computation are being developed to address this gap, with promising approaches leveraging the inherent redundancy capabilities of DNA storage.
Performance scaling presents unique challenges in the DNA storage context. Unlike electronic systems where Moore's Law has historically predicted performance improvements, DNA-based computational storage follows different scaling principles. The parallelization potential of molecular operations offers a theoretical advantage, with estimates suggesting that a single gram of DNA could eventually support millions of simultaneous computational operations through biochemical parallelism.
Latency characteristics differ fundamentally from electronic systems. Current DNA storage solutions exhibit access times in the range of hours to days, primarily due to the biochemical processes involved in DNA manipulation. In-storage computation may reduce overall system latency by eliminating data movement between storage and processing units, but the individual operation latency remains significantly higher than electronic counterparts.
Energy efficiency metrics reveal a promising aspect of DNA-based computational storage. Theoretical analyses suggest that DNA computation could achieve energy efficiencies of approximately 10^8 operations per joule, substantially outperforming electronic systems in specific computational tasks, particularly those involving massive parallelism and pattern matching operations.
Scalability assessments indicate that DNA storage systems could theoretically scale to exabyte capacities within relatively small physical volumes. However, the computational density—measured as operations per cubic millimeter—remains several orders of magnitude below electronic systems in current implementations. Projections based on advances in microfluidics and molecular engineering suggest potential convergence within 15-20 years.
Reliability benchmarks present mixed results, with error rates in DNA-based computation currently ranging from 10^-3 to 10^-6 per base operation, compared to 10^-15 to 10^-18 in electronic systems. Error correction mechanisms specific to DNA computation are being developed to address this gap, with promising approaches leveraging the inherent redundancy capabilities of DNA storage.
Bioethical and Biosecurity Considerations
The integration of computational capabilities within DNA data storage systems raises significant bioethical and biosecurity considerations that must be addressed before widespread implementation. DNA, as both a biological material and an information carrier, occupies a unique position at the intersection of information technology and biotechnology, necessitating careful ethical scrutiny. The ability to perform in-storage computation on DNA-encoded data introduces novel concerns regarding potential misuse of biological information and the creation of dual-use technologies.
Privacy considerations are paramount when biological information is stored and processed within DNA storage systems. Unlike conventional digital data, DNA-stored information has inherent biological significance that could potentially reveal sensitive genetic information about individuals or populations. The computational manipulation of such data within storage systems creates new vulnerabilities where unauthorized access could lead to privacy breaches of unprecedented nature and consequence.
Biosecurity risks emerge when considering the potential for malicious exploitation of in-storage DNA computation. Advanced computational capabilities within DNA storage systems could potentially be weaponized to design pathogenic sequences or toxins if appropriate safeguards are not implemented. The self-replicating nature of DNA adds an additional layer of concern not present in traditional computing systems, as computational errors or malicious code could theoretically propagate through biological systems.
Regulatory frameworks for DNA-based computation remain underdeveloped globally. Current biotechnology regulations were not designed with computational DNA storage in mind, creating potential governance gaps. International coordination will be essential to establish standards for secure DNA computation that balance innovation with appropriate risk management and ethical oversight.
The environmental implications of scaled DNA computation systems also warrant consideration. While DNA storage offers sustainability advantages over traditional electronic media, the chemicals and energy required for synthesis, sequencing, and computational processes may present their own environmental challenges that must be evaluated through comprehensive life cycle assessments.
Informed consent protocols must evolve to address the unique nature of DNA-based computational storage. When personal genetic information is involved, individuals must understand not only how their data is stored but also how computational processes might interact with or derive new insights from their genetic information, potentially revealing unintended or previously unknown characteristics.
Establishing robust security protocols specifically designed for in-storage DNA computation will be critical. These must include encryption standards for DNA-encoded data, access controls for computational processes, and detection mechanisms for potential biosecurity threats that might emerge from the convergence of computational and biological systems.
Privacy considerations are paramount when biological information is stored and processed within DNA storage systems. Unlike conventional digital data, DNA-stored information has inherent biological significance that could potentially reveal sensitive genetic information about individuals or populations. The computational manipulation of such data within storage systems creates new vulnerabilities where unauthorized access could lead to privacy breaches of unprecedented nature and consequence.
Biosecurity risks emerge when considering the potential for malicious exploitation of in-storage DNA computation. Advanced computational capabilities within DNA storage systems could potentially be weaponized to design pathogenic sequences or toxins if appropriate safeguards are not implemented. The self-replicating nature of DNA adds an additional layer of concern not present in traditional computing systems, as computational errors or malicious code could theoretically propagate through biological systems.
Regulatory frameworks for DNA-based computation remain underdeveloped globally. Current biotechnology regulations were not designed with computational DNA storage in mind, creating potential governance gaps. International coordination will be essential to establish standards for secure DNA computation that balance innovation with appropriate risk management and ethical oversight.
The environmental implications of scaled DNA computation systems also warrant consideration. While DNA storage offers sustainability advantages over traditional electronic media, the chemicals and energy required for synthesis, sequencing, and computational processes may present their own environmental challenges that must be evaluated through comprehensive life cycle assessments.
Informed consent protocols must evolve to address the unique nature of DNA-based computational storage. When personal genetic information is involved, individuals must understand not only how their data is stored but also how computational processes might interact with or derive new insights from their genetic information, potentially revealing unintended or previously unknown characteristics.
Establishing robust security protocols specifically designed for in-storage DNA computation will be critical. These must include encryption standards for DNA-encoded data, access controls for computational processes, and detection mechanisms for potential biosecurity threats that might emerge from the convergence of computational and biological systems.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!