IP Landscape And Industry Consortia For DNA Data Storage
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Data Storage Evolution and Objectives
DNA data storage has emerged as a revolutionary approach to address the exponential growth of digital information. Since the pioneering work by Church et al. in 2012, who encoded 659 KB of data in DNA, the field has witnessed remarkable advancements. This technology leverages DNA's inherent properties - high density, longevity, and energy efficiency - to store digital information in biological molecules, potentially offering storage densities of up to 455 exabytes per gram of DNA.
The evolution of DNA data storage can be traced through several key phases. Initially, proof-of-concept demonstrations focused on encoding small amounts of data with limited retrieval capabilities. The second phase saw improvements in encoding algorithms and error correction methods, enabling more reliable data recovery. Currently, the field is transitioning toward practical implementation challenges, including cost reduction, scalability, and integration with existing digital systems.
Market projections indicate that the global DNA data storage market could reach $3.5 billion by 2030, driven by the exponential growth of data generation across sectors. The current global data sphere of approximately 100 zettabytes is expected to grow to 175 zettabytes by 2025, creating urgent demand for novel storage solutions as traditional technologies approach their physical limits.
Technical objectives in this domain focus on several critical areas. First, reducing synthesis and sequencing costs remains paramount, as current estimates of $1,000 per MB are prohibitively expensive for commercial viability. Industry targets aim to achieve costs below $1 per GB to compete with conventional storage media. Second, improving write and read speeds is essential, as current processes require days compared to milliseconds for electronic storage.
Additional objectives include enhancing storage density beyond current demonstrations of 215 petabytes per gram, developing standardized encoding/decoding protocols, and creating robust error correction mechanisms to ensure data integrity over centuries. The development of random-access capabilities also represents a significant goal, as current methods often require sequencing entire DNA pools to retrieve specific data segments.
The intellectual property landscape in DNA data storage has seen accelerated patent filing activity since 2015, with key players including Microsoft, Twist Bioscience, and Illumina establishing strategic positions. Industry consortia such as the DNA Data Storage Alliance, founded in 2020 by Microsoft, Twist Bioscience, Western Digital, and Illumina, are working to create standardized interfaces and architectures to enable interoperability across the emerging DNA storage ecosystem.
The evolution of DNA data storage can be traced through several key phases. Initially, proof-of-concept demonstrations focused on encoding small amounts of data with limited retrieval capabilities. The second phase saw improvements in encoding algorithms and error correction methods, enabling more reliable data recovery. Currently, the field is transitioning toward practical implementation challenges, including cost reduction, scalability, and integration with existing digital systems.
Market projections indicate that the global DNA data storage market could reach $3.5 billion by 2030, driven by the exponential growth of data generation across sectors. The current global data sphere of approximately 100 zettabytes is expected to grow to 175 zettabytes by 2025, creating urgent demand for novel storage solutions as traditional technologies approach their physical limits.
Technical objectives in this domain focus on several critical areas. First, reducing synthesis and sequencing costs remains paramount, as current estimates of $1,000 per MB are prohibitively expensive for commercial viability. Industry targets aim to achieve costs below $1 per GB to compete with conventional storage media. Second, improving write and read speeds is essential, as current processes require days compared to milliseconds for electronic storage.
Additional objectives include enhancing storage density beyond current demonstrations of 215 petabytes per gram, developing standardized encoding/decoding protocols, and creating robust error correction mechanisms to ensure data integrity over centuries. The development of random-access capabilities also represents a significant goal, as current methods often require sequencing entire DNA pools to retrieve specific data segments.
The intellectual property landscape in DNA data storage has seen accelerated patent filing activity since 2015, with key players including Microsoft, Twist Bioscience, and Illumina establishing strategic positions. Industry consortia such as the DNA Data Storage Alliance, founded in 2020 by Microsoft, Twist Bioscience, Western Digital, and Illumina, are working to create standardized interfaces and architectures to enable interoperability across the emerging DNA storage ecosystem.
Market Analysis for DNA-Based Storage Solutions
The DNA data storage market is experiencing significant growth, driven by the exponential increase in global data production and the limitations of conventional storage technologies. Current projections estimate the DNA data storage market to reach approximately $3.3 billion by 2030, with a compound annual growth rate exceeding 55% between 2023 and 2030. This remarkable growth trajectory reflects the urgent need for alternative storage solutions that can address the challenges of data explosion in the digital age.
The primary market segments for DNA-based storage solutions include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive data retention requirements. These segments face critical challenges with traditional storage media, including limited lifespan, high energy consumption, and physical space constraints. DNA storage offers compelling advantages by providing theoretical storage density of up to 455 exabytes per gram of DNA, potentially storing all the world's data in a space the size of a standard shipping container.
Market adoption is currently in the early stages, with most implementations focused on proof-of-concept projects and specialized archival applications. Key barriers to widespread commercial adoption include high synthesis and sequencing costs, which currently range from $1,000-$10,000 per megabyte of stored data, and relatively slow read/write speeds compared to electronic storage media. However, these costs are projected to decrease significantly as the technology matures and economies of scale are achieved.
Regional analysis indicates North America currently leads the market development efforts, with significant investments from both government agencies like DARPA and private corporations. Europe follows closely, with strong research initiatives particularly in the UK, Switzerland, and Germany. The Asia-Pacific region is rapidly increasing investments in this technology, with notable activities in China, Japan, and Singapore.
Customer demand is primarily driven by organizations with long-term data preservation requirements, particularly those handling historical archives, scientific datasets, and medical records. The value proposition centers on DNA's exceptional durability (potentially thousands of years under proper storage conditions) and remarkable storage density, which far exceeds conventional media capabilities.
Competitive dynamics in this emerging market are characterized by strategic partnerships between biotechnology firms, data storage specialists, and research institutions rather than direct competition. This collaborative approach reflects the interdisciplinary nature of DNA data storage technology and the substantial technical challenges that remain to be solved before mass commercialization becomes viable.
The primary market segments for DNA-based storage solutions include government archives, scientific research institutions, healthcare organizations, and large technology companies with massive data retention requirements. These segments face critical challenges with traditional storage media, including limited lifespan, high energy consumption, and physical space constraints. DNA storage offers compelling advantages by providing theoretical storage density of up to 455 exabytes per gram of DNA, potentially storing all the world's data in a space the size of a standard shipping container.
Market adoption is currently in the early stages, with most implementations focused on proof-of-concept projects and specialized archival applications. Key barriers to widespread commercial adoption include high synthesis and sequencing costs, which currently range from $1,000-$10,000 per megabyte of stored data, and relatively slow read/write speeds compared to electronic storage media. However, these costs are projected to decrease significantly as the technology matures and economies of scale are achieved.
Regional analysis indicates North America currently leads the market development efforts, with significant investments from both government agencies like DARPA and private corporations. Europe follows closely, with strong research initiatives particularly in the UK, Switzerland, and Germany. The Asia-Pacific region is rapidly increasing investments in this technology, with notable activities in China, Japan, and Singapore.
Customer demand is primarily driven by organizations with long-term data preservation requirements, particularly those handling historical archives, scientific datasets, and medical records. The value proposition centers on DNA's exceptional durability (potentially thousands of years under proper storage conditions) and remarkable storage density, which far exceeds conventional media capabilities.
Competitive dynamics in this emerging market are characterized by strategic partnerships between biotechnology firms, data storage specialists, and research institutions rather than direct competition. This collaborative approach reflects the interdisciplinary nature of DNA data storage technology and the substantial technical challenges that remain to be solved before mass commercialization becomes viable.
Global DNA Data Storage Technology Assessment
DNA data storage technology has emerged as a promising solution for long-term data archiving, leveraging the inherent stability and density of DNA molecules. The global landscape of DNA data storage technology reveals significant advancements across multiple regions, with North America, Europe, and parts of Asia leading research and development efforts. The United States maintains a dominant position, hosting pioneering companies like Twist Bioscience, Microsoft Research, and Catalog DNA, which have demonstrated practical DNA storage capabilities.
European contributions are substantial, with the European Molecular Biology Laboratory (EMBL) and ETH Zurich conducting groundbreaking research in DNA synthesis and sequencing technologies. The UK's involvement through institutions like the European Bioinformatics Institute has strengthened the region's position in this emerging field.
In Asia, Japan and China are making notable progress, with institutions like the Chinese Academy of Sciences investing heavily in DNA data storage research. South Korea has also entered the arena with focused initiatives on improving DNA synthesis efficiency.
The technology assessment indicates that current DNA data storage systems can achieve theoretical information densities of approximately 215 petabytes per gram of DNA, far exceeding conventional storage media. However, practical implementations currently operate at lower densities due to technical limitations in synthesis and sequencing processes.
Cost remains a significant barrier to widespread adoption, with current estimates ranging from $1,000-$10,000 per megabyte stored. Industry projections suggest these costs could decrease by orders of magnitude within the next decade as technologies mature and scale.
Read/write speeds present another challenge, with writing (synthesis) speeds currently at approximately 10-100 kilobytes per second and reading (sequencing) at 1-10 megabytes per second. These rates are significantly slower than electronic storage systems but continue to improve with technological advancements.
Error rates in DNA storage systems have shown promising improvements, with current systems achieving bit error rates of approximately 10^-7 to 10^-9, comparable to some conventional storage media. Encoding and error correction algorithms specifically designed for DNA storage have contributed significantly to this progress.
The environmental impact assessment of DNA data storage reveals potential sustainability advantages, with significantly lower energy requirements for long-term storage compared to conventional data centers. The biodegradable nature of DNA molecules also presents environmental benefits for end-of-life disposal.
Regulatory frameworks for DNA data storage remain in early development stages globally, with considerations around biosecurity, data privacy, and intellectual property rights emerging as key areas requiring policy attention.
European contributions are substantial, with the European Molecular Biology Laboratory (EMBL) and ETH Zurich conducting groundbreaking research in DNA synthesis and sequencing technologies. The UK's involvement through institutions like the European Bioinformatics Institute has strengthened the region's position in this emerging field.
In Asia, Japan and China are making notable progress, with institutions like the Chinese Academy of Sciences investing heavily in DNA data storage research. South Korea has also entered the arena with focused initiatives on improving DNA synthesis efficiency.
The technology assessment indicates that current DNA data storage systems can achieve theoretical information densities of approximately 215 petabytes per gram of DNA, far exceeding conventional storage media. However, practical implementations currently operate at lower densities due to technical limitations in synthesis and sequencing processes.
Cost remains a significant barrier to widespread adoption, with current estimates ranging from $1,000-$10,000 per megabyte stored. Industry projections suggest these costs could decrease by orders of magnitude within the next decade as technologies mature and scale.
Read/write speeds present another challenge, with writing (synthesis) speeds currently at approximately 10-100 kilobytes per second and reading (sequencing) at 1-10 megabytes per second. These rates are significantly slower than electronic storage systems but continue to improve with technological advancements.
Error rates in DNA storage systems have shown promising improvements, with current systems achieving bit error rates of approximately 10^-7 to 10^-9, comparable to some conventional storage media. Encoding and error correction algorithms specifically designed for DNA storage have contributed significantly to this progress.
The environmental impact assessment of DNA data storage reveals potential sustainability advantages, with significantly lower energy requirements for long-term storage compared to conventional data centers. The biodegradable nature of DNA molecules also presents environmental benefits for end-of-life disposal.
Regulatory frameworks for DNA data storage remain in early development stages globally, with considerations around biosecurity, data privacy, and intellectual property rights emerging as key areas requiring policy attention.
Current DNA Data Storage Architectures
01 DNA encoding and decoding methods for data storage
Various methods for encoding digital data into DNA sequences and decoding DNA back to digital information. These techniques involve converting binary data into nucleotide sequences using specific encoding algorithms that optimize for DNA synthesis constraints, error correction, and data density. The decoding process involves sequencing the DNA and applying corresponding algorithms to recover the original data. These methods aim to maximize storage capacity while ensuring data integrity over long periods.- DNA encoding and decoding methods for data storage: Various methods for encoding digital data into DNA sequences and decoding DNA back to digital data have been developed. These techniques involve converting binary data into nucleotide sequences using specific encoding algorithms that optimize storage density while minimizing error rates. Advanced error correction codes and redundancy mechanisms are implemented to ensure data integrity during storage and retrieval processes. These methods enable the transformation of conventional digital information into biological format for long-term preservation.
- DNA synthesis and sequencing technologies for data storage: Specialized DNA synthesis and sequencing technologies have been developed specifically for data storage applications. These technologies focus on improving the accuracy, speed, and cost-effectiveness of writing data to DNA and reading it back. Innovations include high-throughput parallel synthesis methods, miniaturized sequencing platforms, and optimized biochemical processes that reduce error rates. These advancements are crucial for making DNA data storage commercially viable by addressing the technical challenges of converting between digital and biological formats.
- Storage systems and architectures for DNA-based data: Complete storage systems and architectures have been designed to manage DNA-based data repositories. These systems include physical storage containers, environmental control mechanisms, sample tracking, and information management software. Some designs incorporate microfluidic technologies for automated handling of DNA samples, while others focus on scalable archival systems that can accommodate growing data volumes. These architectures address the unique requirements of biological storage media, including temperature control, humidity management, and protection from environmental degradation.
- Random access and retrieval methods for DNA data: Techniques for selectively accessing specific data stored in DNA without sequencing entire collections have been developed. These random access methods typically use PCR-based approaches with unique address sequences or primers that target only the desired data segments. Some systems employ hierarchical indexing strategies or physical separation methods to organize DNA-stored data for efficient retrieval. These innovations overcome one of the major challenges of DNA storage by enabling rapid access to specific information without processing the entire dataset.
- Long-term preservation and stability enhancement for DNA storage: Methods to enhance the stability and longevity of DNA-stored data have been developed to ensure information remains intact for thousands of years. These approaches include encapsulation technologies that protect DNA molecules from environmental damage, chemical modifications that increase nucleotide stability, and specialized storage media that minimize degradation. Some innovations focus on error detection and repair mechanisms that can identify and correct mutations that occur over time. These preservation techniques are essential for realizing the potential of DNA as an ultra-long-term storage medium.
02 DNA storage system architectures and hardware
Physical implementations and hardware systems designed specifically for DNA data storage. These include specialized devices for DNA synthesis, storage, retrieval, and sequencing integrated into cohesive storage systems. The architectures address challenges such as random access to specific data segments, physical organization of DNA libraries, and interfaces with conventional computing systems. Some implementations include microfluidic systems, automated DNA handling, and specialized containers for long-term preservation.Expand Specific Solutions03 Error correction and data integrity in DNA storage
Techniques for ensuring data integrity and reliability in DNA-based storage systems. These include specialized error correction codes designed for the unique error profiles of DNA synthesis and sequencing, redundancy mechanisms, and methods to handle strand breakage, mutations, and degradation over time. Advanced algorithms detect and correct errors that occur during DNA synthesis, storage, and sequencing processes to maintain data fidelity across long timeframes.Expand Specific Solutions04 Random access and indexing in DNA data storage
Methods for selectively accessing specific data segments within large DNA storage archives without sequencing the entire collection. These techniques involve adding address sequences, barcodes, or other indexing mechanisms to DNA strands to enable targeted retrieval. PCR-based approaches and other molecular techniques allow for efficient searching and retrieval of specific data fragments from complex DNA libraries, making the storage system more practical for real-world applications.Expand Specific Solutions05 Enzymatic and biochemical approaches for DNA data manipulation
Utilization of enzymes and biochemical processes to manipulate DNA for data storage applications. These approaches leverage natural or engineered biological systems for writing, modifying, or reading DNA-encoded information. Techniques include using specialized polymerases, nucleases, and other enzymes to perform data operations with greater efficiency or specificity than purely chemical methods. Some systems incorporate CRISPR-based technologies or other biological tools to enhance the capabilities of DNA data storage systems.Expand Specific Solutions
Key Industry Players and Consortia Landscape
The DNA data storage market is in an early development stage, characterized by significant research activity but limited commercial deployment. The global market size remains relatively small but is projected to grow exponentially as the technology matures. From a technical maturity perspective, the field is transitioning from proof-of-concept to early commercialization, with key players emerging across academic and corporate sectors. Leading companies like Microsoft Technology Licensing, Catalog Technologies, and Iridia are developing proprietary DNA synthesis and storage technologies, while academic institutions such as MIT, Nanjing University, and Tianjin University are advancing fundamental research. Research consortia involving BGI Shenzhen, Huawei, and Molecular Assemblies are forming to address technical challenges in scalability, read/write speeds, and cost reduction, indicating a collaborative approach to accelerating technology development.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has pioneered DNA data storage technology through its comprehensive end-to-end system approach. Their solution integrates automated DNA synthesis, storage, and sequencing processes with sophisticated encoding/decoding algorithms. Microsoft's platform employs a "DNA fountain" coding technique that maximizes data density while ensuring error resilience. Their system achieves storage densities exceeding 215 petabytes per gram of DNA with demonstrated retrieval accuracy of 100% for files up to 200MB. Microsoft has also developed specialized random-access methods using PCR-based selective amplification, allowing specific data segments to be retrieved without sequencing the entire DNA archive. Their technology incorporates enzymatic DNA synthesis methods that avoid the toxic chemicals used in traditional phosphoramidite chemistry, making the process more environmentally sustainable and potentially scalable. Microsoft collaborates with Twist Bioscience for DNA synthesis and has established the DNA Storage Alliance to accelerate industry standardization.
Strengths: Industry-leading data density and retrieval accuracy; comprehensive end-to-end system approach; strong partnerships with synthesis companies; pioneering work in random access methods. Weaknesses: High costs associated with DNA synthesis and sequencing; relatively slow write/read speeds compared to electronic storage; technology still primarily in research phase rather than commercial deployment.
Catalog Technologies, Inc.
Technical Solution: Catalog Technologies has developed a unique approach to DNA data storage that separates the synthesis of DNA from the encoding of information. Their proprietary "Shannon" platform uses pre-synthesized DNA molecules as building blocks that are then assembled in different combinations to represent digital data, similar to how ink is used in printing. This method significantly reduces the cost and time required for DNA synthesis compared to traditional nucleotide-by-nucleotide approaches. Catalog's technology can encode data at rates of megabits per second, which is orders of magnitude faster than conventional DNA synthesis methods. In 2019, they successfully stored all 16GB of Wikipedia's English-language text in DNA molecules. Their system employs sophisticated error correction codes and redundancy mechanisms to ensure data integrity during storage and retrieval. Catalog has also developed automated instruments for the writing and reading processes, moving toward a commercially viable DNA storage ecosystem that could potentially store exabytes of data in small volumes.
Strengths: Innovative approach separating synthesis from encoding; significantly faster writing speeds than competitors; demonstrated large-scale data storage capability; automated instrumentation development. Weaknesses: May have lower theoretical maximum storage density than nucleotide-by-nucleotide approaches; still requires expensive sequencing for data retrieval; technology remains in early commercialization phase with limited real-world deployments.
IP Portfolio Analysis in DNA Storage
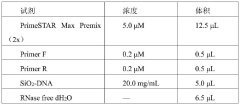
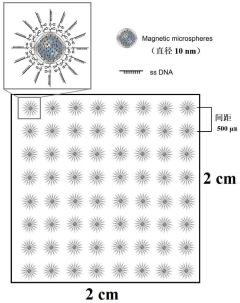
DNA storage method for composite code accompanying addressing coding
PatentActiveCN119476422A
Innovation
- The composite code accompanying addressing coding method is adopted, and a double-layer bit sequence is formed by selecting a pseudo-random sequence as a subcode, constructing a composite code as an address sequence, and coding with user data to form a double-layer bit sequence. When reading, sliding correlation detection and Chinese residual theorem are used to determine the unique position number of the read segment to achieve rapid identification and data recovery.
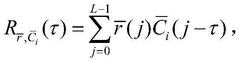
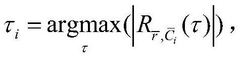
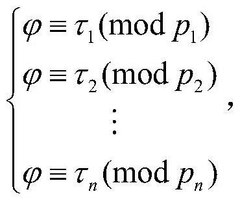
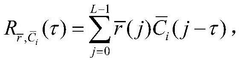
DNA storage chip and preparation method thereof
PatentPendingCN117373548A
Innovation
- Design a DNA memory chip that uses multiple matrix-distributed storage sites on the substrate. Each site accommodates multiple microspheres. The length of the DNA storage sequence is not less than 100bp, including address bits, storage bits and error correction bits. , the data is encoded and fixed on the microspheres through multi-level primer indexing algorithm and encoding algorithm, realizing high-density partition storage and fixed-point reading and writing functions.


Standardization Efforts in DNA Data Storage
Standardization efforts in DNA data storage have become increasingly crucial as the technology advances from laboratory experiments to potential commercial applications. The DNA Data Storage Alliance, formed in 2020 by founding members including Illumina, Microsoft Research, Twist Bioscience, and Western Digital, represents the most significant industry consortium dedicated to creating interoperable standards and specifications for this emerging storage medium. This alliance aims to establish a comprehensive ecosystem that enables DNA-based storage solutions to become commercially viable through standardized interfaces and protocols.
Beyond the Alliance, the IEEE has initiated working groups focused on developing technical standards for DNA storage systems, addressing critical aspects such as encoding schemes, error correction methodologies, and file system architectures. These standardization efforts are essential for ensuring that DNA-synthesized data can be accurately retrieved regardless of which company's technology was used for writing or reading the information.
The International Organization for Standardization (ISO) has also begun preliminary work on establishing global standards for DNA data storage, recognizing its potential as a revolutionary archival solution. Their focus includes developing standardized terminology, quality metrics, and testing procedures to evaluate the performance and reliability of DNA storage systems across different implementations.
Academia-industry partnerships have emerged as another vital component of standardization efforts, with research institutions collaborating with technology companies to develop open reference architectures. The Molecular Information Systems Laboratory (MISL), a collaboration between the University of Washington and Microsoft Research, has proposed several encoding standards that have gained traction within the research community.
Interoperability remains a central challenge being addressed through these standardization initiatives. Current efforts focus on establishing common file formats for DNA-encoded data, standardized addressing schemes for random access retrieval, and uniform quality control metrics for synthesis and sequencing processes. These standards aim to prevent vendor lock-in and enable a competitive marketplace for DNA storage technologies.
Regulatory bodies, including the FDA and equivalent organizations globally, are beginning to engage with industry consortia to develop appropriate regulatory frameworks for DNA data storage systems, particularly for applications in sensitive sectors such as healthcare, finance, and government archives. This collaborative approach ensures that standardization efforts align with broader regulatory requirements for data security, integrity, and longevity.
Beyond the Alliance, the IEEE has initiated working groups focused on developing technical standards for DNA storage systems, addressing critical aspects such as encoding schemes, error correction methodologies, and file system architectures. These standardization efforts are essential for ensuring that DNA-synthesized data can be accurately retrieved regardless of which company's technology was used for writing or reading the information.
The International Organization for Standardization (ISO) has also begun preliminary work on establishing global standards for DNA data storage, recognizing its potential as a revolutionary archival solution. Their focus includes developing standardized terminology, quality metrics, and testing procedures to evaluate the performance and reliability of DNA storage systems across different implementations.
Academia-industry partnerships have emerged as another vital component of standardization efforts, with research institutions collaborating with technology companies to develop open reference architectures. The Molecular Information Systems Laboratory (MISL), a collaboration between the University of Washington and Microsoft Research, has proposed several encoding standards that have gained traction within the research community.
Interoperability remains a central challenge being addressed through these standardization initiatives. Current efforts focus on establishing common file formats for DNA-encoded data, standardized addressing schemes for random access retrieval, and uniform quality control metrics for synthesis and sequencing processes. These standards aim to prevent vendor lock-in and enable a competitive marketplace for DNA storage technologies.
Regulatory bodies, including the FDA and equivalent organizations globally, are beginning to engage with industry consortia to develop appropriate regulatory frameworks for DNA data storage systems, particularly for applications in sensitive sectors such as healthcare, finance, and government archives. This collaborative approach ensures that standardization efforts align with broader regulatory requirements for data security, integrity, and longevity.
Regulatory Framework and Data Security Considerations
DNA data storage operates within a complex regulatory landscape that continues to evolve as the technology matures. Currently, there is no unified global regulatory framework specifically addressing DNA data storage, creating a patchwork of applicable regulations drawn from adjacent fields. In the United States, aspects of DNA data storage fall under the jurisdiction of multiple agencies including the FDA for biological applications, the FCC for communications technology integration, and the EPA for environmental considerations of synthetic DNA. The European Union approaches regulation through the lens of the General Data Protection Regulation (GDPR) when personal data is involved, while also applying biotechnology regulations to the DNA synthesis aspects.
Security considerations for DNA data storage present unique challenges that span both digital and biological domains. Traditional cybersecurity frameworks must be adapted to address the distinctive characteristics of DNA-based information systems. Encryption methodologies for DNA data storage require specialized approaches that maintain data integrity through biological processes while ensuring robust protection against unauthorized access. Current research focuses on developing DNA-specific encryption protocols that can withstand both conventional digital attacks and novel bio-based intrusions.
Data integrity verification presents another critical security consideration, as DNA degradation over time can introduce errors that compromise stored information. Industry standards are emerging for error detection and correction codes specifically designed for the biological medium, with organizations like the DNA Data Storage Alliance working to establish best practices for maintaining data fidelity across extended timeframes.
Privacy concerns are particularly acute when considering DNA as a storage medium, given its biological significance. Clear delineation between synthetic DNA used purely for data storage and genomic information is essential from both regulatory and ethical perspectives. Several jurisdictions are developing specific guidelines addressing consent, ownership, and usage limitations for DNA-stored data, particularly when deployed in commercial applications.
Biosecurity frameworks are increasingly incorporating provisions for DNA data storage, recognizing the dual-use potential of the technology. International agreements like the Biological Weapons Convention have implications for DNA data storage when considering the potential encoding of pathogen genomic information or synthetic biology instructions. Industry self-regulation through consortia like the International Gene Synthesis Consortium has established screening protocols for DNA synthesis that may eventually extend to data storage applications.
As the technology advances toward commercialization, regulatory harmonization efforts are underway through multi-stakeholder initiatives involving government agencies, research institutions, and industry partners. These collaborative approaches aim to develop standards that balance innovation with appropriate safeguards for this transformative data storage paradigm.
Security considerations for DNA data storage present unique challenges that span both digital and biological domains. Traditional cybersecurity frameworks must be adapted to address the distinctive characteristics of DNA-based information systems. Encryption methodologies for DNA data storage require specialized approaches that maintain data integrity through biological processes while ensuring robust protection against unauthorized access. Current research focuses on developing DNA-specific encryption protocols that can withstand both conventional digital attacks and novel bio-based intrusions.
Data integrity verification presents another critical security consideration, as DNA degradation over time can introduce errors that compromise stored information. Industry standards are emerging for error detection and correction codes specifically designed for the biological medium, with organizations like the DNA Data Storage Alliance working to establish best practices for maintaining data fidelity across extended timeframes.
Privacy concerns are particularly acute when considering DNA as a storage medium, given its biological significance. Clear delineation between synthetic DNA used purely for data storage and genomic information is essential from both regulatory and ethical perspectives. Several jurisdictions are developing specific guidelines addressing consent, ownership, and usage limitations for DNA-stored data, particularly when deployed in commercial applications.
Biosecurity frameworks are increasingly incorporating provisions for DNA data storage, recognizing the dual-use potential of the technology. International agreements like the Biological Weapons Convention have implications for DNA data storage when considering the potential encoding of pathogen genomic information or synthetic biology instructions. Industry self-regulation through consortia like the International Gene Synthesis Consortium has established screening protocols for DNA synthesis that may eventually extend to data storage applications.
As the technology advances toward commercialization, regulatory harmonization efforts are underway through multi-stakeholder initiatives involving government agencies, research institutions, and industry partners. These collaborative approaches aim to develop standards that balance innovation with appropriate safeguards for this transformative data storage paradigm.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!