

Encoding Schemes And Error Models For DNA Data Storage
AUG 27, 20258 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DNA Data Storage Evolution and Objectives
DNA data storage has emerged as a revolutionary approach to address the exponential growth of digital information. Since the pioneering work by Church et al. in 2012, which demonstrated the feasibility of storing digital data in DNA molecules, this field has witnessed remarkable advancements. The fundamental concept leverages DNA's exceptional information density—theoretically capable of storing up to 455 exabytes per gram—making it potentially thousands of times more efficient than conventional electronic storage media.
The evolution of DNA data storage technology has progressed through several distinct phases. Initially, researchers focused on proof-of-concept demonstrations with limited capacity and high error rates. By 2015-2016, significant improvements in encoding schemes enabled more reliable storage with error correction capabilities. Recent years have seen the development of random-access methods, allowing selective retrieval of specific data segments without sequencing entire DNA pools.
Current encoding schemes for DNA data storage primarily convert binary data into nucleotide sequences using various algorithms. These schemes must navigate biological constraints, including avoiding homopolymer runs (repetitions of the same nucleotide) and maintaining balanced GC content to ensure stable DNA structures. Error models have become increasingly sophisticated, accounting for synthesis errors (insertions, deletions, substitutions), storage degradation, and sequencing mistakes.
The primary objectives in this field center around addressing several critical challenges. First, improving the fidelity of DNA synthesis and sequencing to reduce error rates that currently necessitate extensive redundancy. Second, increasing the speed and reducing the cost of DNA synthesis, which remains prohibitively expensive for large-scale data storage applications. Third, developing more efficient encoding schemes that maximize information density while maintaining robustness against errors.
Looking forward, the field aims to achieve practical commercial viability within the next decade. This requires reducing costs by several orders of magnitude, from current estimates of $1,000 per megabyte to competitive levels with traditional storage media. Additionally, researchers are working toward fully automated systems that integrate synthesis, storage, and retrieval processes without human intervention.
The convergence of synthetic biology, information theory, and computer science continues to drive innovation in this domain. As traditional silicon-based storage approaches physical limitations, DNA data storage represents a promising alternative for long-term archival of the world's exponentially growing digital information.
The evolution of DNA data storage technology has progressed through several distinct phases. Initially, researchers focused on proof-of-concept demonstrations with limited capacity and high error rates. By 2015-2016, significant improvements in encoding schemes enabled more reliable storage with error correction capabilities. Recent years have seen the development of random-access methods, allowing selective retrieval of specific data segments without sequencing entire DNA pools.
Current encoding schemes for DNA data storage primarily convert binary data into nucleotide sequences using various algorithms. These schemes must navigate biological constraints, including avoiding homopolymer runs (repetitions of the same nucleotide) and maintaining balanced GC content to ensure stable DNA structures. Error models have become increasingly sophisticated, accounting for synthesis errors (insertions, deletions, substitutions), storage degradation, and sequencing mistakes.
The primary objectives in this field center around addressing several critical challenges. First, improving the fidelity of DNA synthesis and sequencing to reduce error rates that currently necessitate extensive redundancy. Second, increasing the speed and reducing the cost of DNA synthesis, which remains prohibitively expensive for large-scale data storage applications. Third, developing more efficient encoding schemes that maximize information density while maintaining robustness against errors.
Looking forward, the field aims to achieve practical commercial viability within the next decade. This requires reducing costs by several orders of magnitude, from current estimates of $1,000 per megabyte to competitive levels with traditional storage media. Additionally, researchers are working toward fully automated systems that integrate synthesis, storage, and retrieval processes without human intervention.
The convergence of synthetic biology, information theory, and computer science continues to drive innovation in this domain. As traditional silicon-based storage approaches physical limitations, DNA data storage represents a promising alternative for long-term archival of the world's exponentially growing digital information.
Market Analysis for DNA Storage Solutions
The DNA data storage market is experiencing significant growth as organizations seek innovative solutions for long-term data preservation. Current market valuations estimate the global DNA data storage market at approximately $105 million in 2023, with projections indicating potential growth to reach $3.3 billion by 2030, representing a compound annual growth rate (CAGR) of 63.4% during the forecast period.
Key market drivers include the exponential increase in global data production, which is expected to reach 175 zettabytes by 2025, creating urgent demand for high-density, long-term storage solutions. Traditional storage media face limitations in capacity, durability, and energy consumption that DNA storage directly addresses through its theoretical storage density of 455 exabytes per gram.
Market segmentation reveals distinct application sectors, with healthcare and life sciences currently dominating at 42% market share, followed by government and defense (28%), academic research (18%), and information technology (12%). Geographically, North America leads with 45% market share, followed by Europe (30%), Asia-Pacific (20%), and rest of world (5%).
The commercial landscape features established technology corporations investing heavily in DNA storage R&D, including Microsoft, Illumina, and Twist Bioscience. Specialized startups like Catalog Technologies and DNA Script have secured substantial venture funding, with total investments in DNA storage ventures exceeding $650 million since 2018.
Customer adoption analysis indicates three primary market segments: early adopters focused on archival applications with century-scale retention requirements; mid-term adopters seeking solutions for cold storage of rarely accessed but valuable data; and potential mass-market applications contingent upon significant cost reductions.
Current market barriers include prohibitive costs (approximately $1,000 per megabyte), slow read/write speeds, and technical challenges in encoding schemes and error correction. Industry experts project that encoding efficiency improvements could reduce costs by 90% within five years, potentially expanding addressable markets tenfold.
Regulatory considerations are evolving, with data protection frameworks beginning to acknowledge DNA storage as a legitimate technology. The FDA and similar international bodies are developing preliminary guidelines for biological data storage systems, potentially impacting market development timelines.
Key market drivers include the exponential increase in global data production, which is expected to reach 175 zettabytes by 2025, creating urgent demand for high-density, long-term storage solutions. Traditional storage media face limitations in capacity, durability, and energy consumption that DNA storage directly addresses through its theoretical storage density of 455 exabytes per gram.
Market segmentation reveals distinct application sectors, with healthcare and life sciences currently dominating at 42% market share, followed by government and defense (28%), academic research (18%), and information technology (12%). Geographically, North America leads with 45% market share, followed by Europe (30%), Asia-Pacific (20%), and rest of world (5%).
The commercial landscape features established technology corporations investing heavily in DNA storage R&D, including Microsoft, Illumina, and Twist Bioscience. Specialized startups like Catalog Technologies and DNA Script have secured substantial venture funding, with total investments in DNA storage ventures exceeding $650 million since 2018.
Customer adoption analysis indicates three primary market segments: early adopters focused on archival applications with century-scale retention requirements; mid-term adopters seeking solutions for cold storage of rarely accessed but valuable data; and potential mass-market applications contingent upon significant cost reductions.
Current market barriers include prohibitive costs (approximately $1,000 per megabyte), slow read/write speeds, and technical challenges in encoding schemes and error correction. Industry experts project that encoding efficiency improvements could reduce costs by 90% within five years, potentially expanding addressable markets tenfold.
Regulatory considerations are evolving, with data protection frameworks beginning to acknowledge DNA storage as a legitimate technology. The FDA and similar international bodies are developing preliminary guidelines for biological data storage systems, potentially impacting market development timelines.
Current Encoding Schemes and Technical Barriers
DNA data storage currently employs several encoding schemes, each with distinct advantages and limitations. The most prevalent approach is the nucleotide-based encoding, where digital binary data (0s and 1s) is converted into DNA's four-letter alphabet (A, T, G, C). This conversion typically follows mapping rules such as 00→A, 01→C, 10→G, and 11→T, allowing two bits of information to be stored per nucleotide.
Huffman coding has emerged as an efficient compression technique for DNA storage, reducing redundancy by assigning shorter codes to frequently occurring patterns. This approach significantly increases storage density but introduces complexity in decoding processes, particularly when errors are present.
Church's encoding scheme, pioneered in 2012, established a one-to-one correspondence between binary and DNA bases. While straightforward, this method lacks error correction capabilities, limiting its practical application in real-world storage systems where errors are inevitable.
Goldman's encoding improved upon Church's work by incorporating a rotating encoding system that prevents homopolymer runs (consecutive identical nucleotides), which are particularly prone to sequencing errors. This scheme also introduced a redundancy mechanism through overlapping segments, enhancing data recovery capabilities.
Fountain codes represent a significant advancement in DNA storage encoding. These rateless erasure codes generate a potentially limitless number of encoded packets, requiring only that a sufficient subset be recovered to reconstruct the original data. This approach provides robust error resilience but increases computational complexity.
Despite these innovations, substantial technical barriers persist. DNA synthesis error rates remain problematic, with insertion, deletion, and substitution errors occurring at rates of approximately 1% during both synthesis and sequencing processes. These errors fundamentally differ from traditional digital storage errors, which typically manifest only as substitutions.
The asymmetry between writing (synthesis) and reading (sequencing) speeds creates a significant bottleneck. While sequencing technologies have advanced rapidly, synthesis remains slow and expensive, limiting practical implementation of DNA data storage systems at scale.
Addressing these challenges requires novel encoding schemes that balance information density with error resilience. Current research focuses on developing specialized error correction codes that can handle the unique error profiles of DNA storage while maintaining high data density. Promising directions include deep learning-based encoding methods and hybrid approaches that combine multiple encoding strategies to optimize performance across different error conditions.
Huffman coding has emerged as an efficient compression technique for DNA storage, reducing redundancy by assigning shorter codes to frequently occurring patterns. This approach significantly increases storage density but introduces complexity in decoding processes, particularly when errors are present.
Church's encoding scheme, pioneered in 2012, established a one-to-one correspondence between binary and DNA bases. While straightforward, this method lacks error correction capabilities, limiting its practical application in real-world storage systems where errors are inevitable.
Goldman's encoding improved upon Church's work by incorporating a rotating encoding system that prevents homopolymer runs (consecutive identical nucleotides), which are particularly prone to sequencing errors. This scheme also introduced a redundancy mechanism through overlapping segments, enhancing data recovery capabilities.
Fountain codes represent a significant advancement in DNA storage encoding. These rateless erasure codes generate a potentially limitless number of encoded packets, requiring only that a sufficient subset be recovered to reconstruct the original data. This approach provides robust error resilience but increases computational complexity.
Despite these innovations, substantial technical barriers persist. DNA synthesis error rates remain problematic, with insertion, deletion, and substitution errors occurring at rates of approximately 1% during both synthesis and sequencing processes. These errors fundamentally differ from traditional digital storage errors, which typically manifest only as substitutions.
The asymmetry between writing (synthesis) and reading (sequencing) speeds creates a significant bottleneck. While sequencing technologies have advanced rapidly, synthesis remains slow and expensive, limiting practical implementation of DNA data storage systems at scale.
Addressing these challenges requires novel encoding schemes that balance information density with error resilience. Current research focuses on developing specialized error correction codes that can handle the unique error profiles of DNA storage while maintaining high data density. Promising directions include deep learning-based encoding methods and hybrid approaches that combine multiple encoding strategies to optimize performance across different error conditions.
Prevalent Encoding Methods and Error Correction Models
01 DNA-based encoding schemes for data storage
Various encoding schemes have been developed specifically for DNA-based data storage systems. These schemes convert digital binary data into DNA nucleotide sequences (A, T, G, C) while optimizing for storage density, error resistance, and synthesis/sequencing compatibility. Advanced encoding algorithms incorporate techniques such as base-balanced encoding, run-length limiting, and homopolymer avoidance to improve the reliability of DNA data storage systems.- DNA-based encoding schemes for data storage: Various encoding schemes have been developed specifically for DNA data storage to optimize data density, error resilience, and retrieval efficiency. These schemes convert digital binary data into DNA nucleotide sequences using specialized algorithms that account for the unique properties of DNA molecules. Advanced encoding techniques include methods to avoid homopolymer runs, balance GC content, and eliminate sequences that might form secondary structures, all of which can lead to synthesis and sequencing errors.
- Error detection and correction models for DNA storage: Error models for DNA data storage address the unique challenges of this medium, including insertion, deletion, and substitution errors that occur during synthesis, storage, and sequencing. Specialized error correction codes have been developed that can detect and correct these errors, improving the reliability of DNA-based information systems. These models often incorporate redundancy and sophisticated mathematical approaches to maintain data integrity despite the biological error mechanisms inherent to DNA.
- DNA storage system architectures and retrieval methods: System architectures for DNA data storage involve comprehensive frameworks for encoding, storing, and retrieving information. These systems include methods for organizing DNA sequences into addressable pools, implementing random access capabilities, and optimizing physical storage conditions. Advanced retrieval methods use PCR-based techniques with unique address sequences to selectively access specific data without sequencing the entire DNA archive, significantly improving efficiency and reducing costs for data retrieval operations.
- Synthesis and sequencing optimization for DNA storage: Optimization techniques for DNA synthesis and sequencing focus on improving the accuracy and efficiency of writing and reading data in DNA storage systems. These approaches include modified nucleotides, enzymatic methods for controlled synthesis, and advanced sequencing technologies that reduce error rates. By addressing the physical limitations of DNA manipulation, these optimizations enhance the practical viability of DNA as a long-term data storage medium, allowing for greater data density and reliability.
- Computational methods for DNA data processing: Computational methods for DNA data processing involve algorithms and software tools specifically designed to handle the unique challenges of DNA-based information. These include specialized compression techniques that exploit the properties of DNA sequences, efficient indexing methods for rapid data lookup, and machine learning approaches that can predict and compensate for error patterns. These computational tools form a critical layer in the DNA data storage pipeline, bridging the gap between traditional digital systems and biological storage media.
02 Error detection and correction models for DNA storage
Error detection and correction models are essential for reliable DNA data storage due to errors that can occur during synthesis, storage, and sequencing processes. These models include specialized error correction codes (ECCs) designed to address DNA-specific error types such as insertions, deletions, and substitutions. Advanced error correction techniques incorporate redundancy, parity checks, and sophisticated algorithms to ensure data integrity despite the biological medium's inherent error rates.Expand Specific Solutions03 DNA storage system architectures and implementations
Various system architectures have been developed for implementing DNA-based data storage solutions. These architectures include end-to-end systems that handle encoding, synthesis, storage, sequencing, and decoding processes. Key components include specialized hardware for DNA synthesis and sequencing, software interfaces for data management, and integration with conventional digital storage systems. These implementations focus on practical aspects such as scalability, retrieval efficiency, and long-term stability of stored information.Expand Specific Solutions04 Random access and indexing methods for DNA storage
Random access and indexing methods enable selective retrieval of specific data from DNA storage systems without sequencing the entire dataset. These techniques incorporate address sequences, barcodes, or primers that allow targeted amplification of desired data segments. Advanced indexing schemes create hierarchical structures or use specialized addressing mechanisms to improve search efficiency and reduce retrieval times, making DNA storage more practical for real-world applications.Expand Specific Solutions05 Error modeling and simulation for DNA storage systems
Error modeling and simulation frameworks help predict and analyze the behavior of DNA storage systems under various conditions. These models characterize different types of errors that occur during DNA synthesis, storage, and sequencing processes, including substitutions, insertions, deletions, and coverage variations. Simulation tools enable researchers to test encoding schemes and error correction methods before physical implementation, accelerating the development of more robust DNA storage technologies.Expand Specific Solutions
Leading Organizations in DNA Data Storage Research
DNA data storage technology is currently in the early development stage, with a growing market expected to reach significant scale as digital data storage demands increase exponentially. The competitive landscape features diverse players including academic institutions (Tianjin University, Huazhong University of Science & Technology), technology giants (Microsoft, Huawei, Samsung, Western Digital), and specialized biotechnology companies (BGI Research, Roswell Biotechnologies, Integrated DNA Technologies). Technical maturity varies across encoding schemes and error correction models, with academic institutions leading fundamental research while commercial entities focus on practical implementation challenges. Key technical hurdles include improving storage density, reducing synthesis/sequencing costs, and developing robust error correction mechanisms to ensure data integrity in this promising but still emerging field.
BGI Research
Technical Solution: BGI Research has developed a comprehensive DNA data storage platform called DNArtifact that incorporates advanced encoding schemes and error correction models. Their approach uses a quaternary coding system that maps binary data to DNA nucleotides with optimized GC content balancing to enhance synthesis and sequencing reliability. The platform employs a multi-layered error correction strategy including Reed-Solomon codes for burst error correction and fountain codes that enable robust data recovery even with significant sequence loss. BGI's system incorporates specialized algorithms that account for DNA-specific error patterns such as homopolymer errors, insertion-deletion events, and substitution errors that occur during synthesis and sequencing. Their platform also features adaptive encoding that adjusts redundancy levels based on the importance of data segments, ensuring critical information maintains higher integrity. Recent advancements include machine learning models that predict error-prone sequence patterns and avoid them during encoding, significantly improving overall system reliability.
Strengths: BGI's extensive experience in genomic sequencing provides unique insights into DNA error patterns, allowing for highly optimized error correction models. Their integrated approach combining wet-lab expertise with computational solutions enables end-to-end optimization. Weaknesses: The system requires specialized sequencing equipment compatible with BGI's platforms, potentially limiting broader adoption and interoperability with other DNA storage technologies.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has pioneered a DNA storage system called "Molecular Information Storage" (MIST) that features innovative encoding schemes and robust error models. Their approach utilizes a specialized encoding algorithm that converts binary data into DNA sequences while avoiding homopolymers and maintaining balanced GC content to improve synthesis efficiency and reduce error rates. Microsoft's system implements a hierarchical error correction framework that combines inner and outer coding schemes - using Reed-Solomon codes at the block level and LDPC (Low-Density Parity-Check) codes for sequence-level protection. A distinctive feature is their implementation of "strand addressing" where each DNA strand contains unique address sequences that enable random access to specific data portions without sequencing the entire pool. Microsoft has also developed sophisticated error models that account for the unique characteristics of DNA storage errors, including synthesis errors, sequencing errors, and degradation over time. Their system incorporates machine learning algorithms that adaptively adjust error correction parameters based on observed error patterns during preliminary test runs.
Strengths: Microsoft's approach offers exceptional data density (exabytes per gram potential) with demonstrated random access capabilities that make their system more practical for real-world applications. Their error correction framework has proven robust across multiple experimental validations. Weaknesses: The current implementation requires relatively high redundancy levels to ensure data integrity, reducing effective storage density compared to theoretical maximums. The encoding/decoding process remains computationally intensive, limiting throughput for large-scale applications.
Key Patents in DNA Storage Encoding Technologies
DNA storage cascade encoding and decoding methods for type-1 and type-2 segmented error correction internal codes
PatentWO2023130676A1
Innovation
- The DNA storage cascade encoding and decoding method using type 1 and type 2 segmented error correction internal codes is used to correct and restore DNA sequences through the Levenshtein encoder and structural decoder, and can correct deletion, insertion and substitution errors. and restore original data.
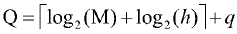
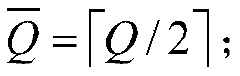
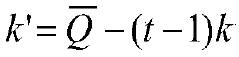
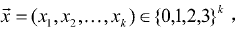
Error Correction in Binary-encoded DNA Using Linear Feedback Shift Registers
PatentInactiveUS20070113137A1
Innovation
- The encoding method employs a combination of base mapping, linear feedback shift registers (LFSR) for error detection and correction, and the Reed-Solomon algorithm to address errors like point substitution, insertion, deletion, inversion, and translocation by analyzing head and tail bits, and reconstructing sequences.
Regulatory Framework for Synthetic DNA Technologies
The regulatory landscape for DNA data storage technologies is rapidly evolving as synthetic biology advances intersect with data management policies. Currently, oversight of DNA-based storage systems falls under multiple regulatory bodies, including the FDA, EPA, and international equivalents that govern biotechnology applications. These frameworks were primarily designed for genetic engineering and synthetic biology rather than data storage applications, creating regulatory gaps that need addressing.
Key regulatory considerations include biosecurity protocols to prevent misuse of synthetic DNA sequences that could encode harmful information or be converted to pathogenic organisms. The International Gene Synthesis Consortium (IGSC) has established screening protocols for DNA synthesis orders, though these primarily target bioweapon concerns rather than data storage applications.
Privacy regulations present another critical dimension, as DNA storage could potentially contain sensitive personal or proprietary information. Existing frameworks like GDPR in Europe and HIPAA in the US provide partial coverage but lack specific provisions for non-biological data stored in biological media. This creates uncertainty regarding jurisdiction and enforcement mechanisms for DNA-encoded digital information.
Intellectual property protection represents a significant regulatory challenge. Current patent systems struggle with the dual nature of DNA storage technologies that bridge biotechnology and information technology domains. Questions remain about whether DNA-encoded data should be protected as software, biotechnology innovations, or through new hybrid frameworks.
Environmental regulations also impact DNA data storage development, with concerns about synthetic DNA release requiring containment protocols and risk assessment frameworks. The NIH Guidelines for Research Involving Recombinant DNA Molecules provide some direction, though they were not designed with mass data storage applications in mind.
International harmonization efforts are underway through organizations like the OECD and WHO to develop consistent regulatory approaches for synthetic biology applications including DNA data storage. These initiatives aim to balance innovation promotion with appropriate safeguards against misuse or unintended consequences.
As DNA data storage technologies mature toward commercialization, regulatory frameworks will need significant adaptation to address the unique challenges posed by encoding digital information in biological molecules, requiring collaboration between information technology regulators and biotechnology oversight bodies.
Key regulatory considerations include biosecurity protocols to prevent misuse of synthetic DNA sequences that could encode harmful information or be converted to pathogenic organisms. The International Gene Synthesis Consortium (IGSC) has established screening protocols for DNA synthesis orders, though these primarily target bioweapon concerns rather than data storage applications.
Privacy regulations present another critical dimension, as DNA storage could potentially contain sensitive personal or proprietary information. Existing frameworks like GDPR in Europe and HIPAA in the US provide partial coverage but lack specific provisions for non-biological data stored in biological media. This creates uncertainty regarding jurisdiction and enforcement mechanisms for DNA-encoded digital information.
Intellectual property protection represents a significant regulatory challenge. Current patent systems struggle with the dual nature of DNA storage technologies that bridge biotechnology and information technology domains. Questions remain about whether DNA-encoded data should be protected as software, biotechnology innovations, or through new hybrid frameworks.
Environmental regulations also impact DNA data storage development, with concerns about synthetic DNA release requiring containment protocols and risk assessment frameworks. The NIH Guidelines for Research Involving Recombinant DNA Molecules provide some direction, though they were not designed with mass data storage applications in mind.
International harmonization efforts are underway through organizations like the OECD and WHO to develop consistent regulatory approaches for synthetic biology applications including DNA data storage. These initiatives aim to balance innovation promotion with appropriate safeguards against misuse or unintended consequences.
As DNA data storage technologies mature toward commercialization, regulatory frameworks will need significant adaptation to address the unique challenges posed by encoding digital information in biological molecules, requiring collaboration between information technology regulators and biotechnology oversight bodies.
Scalability Challenges and Economic Feasibility
DNA data storage faces significant scalability challenges that must be addressed for widespread commercial adoption. Current DNA synthesis methods can only produce oligonucleotides at rates of approximately 200 nucleotides per second, which translates to data writing speeds of merely 50-100 bytes per second. This represents a critical bottleneck when compared to conventional electronic storage technologies that operate at gigabytes per second. Additionally, the error rates in DNA synthesis (approximately 1% per nucleotide position) necessitate robust error correction schemes that further reduce effective storage density.
From an economic perspective, the cost of DNA synthesis remains prohibitively high at approximately $0.001 per nucleotide. This translates to roughly $1 million per gigabyte of stored data, compared to less than $0.02 per gigabyte for conventional hard drives. While DNA reading costs through next-generation sequencing have decreased significantly, they still exceed $1,000 per genome, making frequent data retrieval economically unfeasible.
Scaling DNA data storage systems requires parallel processing approaches. Current research focuses on microfluidic platforms that can perform thousands of parallel synthesis reactions, potentially increasing throughput by several orders of magnitude. Similarly, advances in nanopore sequencing technology may enable direct reading of DNA molecules without amplification, reducing retrieval costs and time.
The economic feasibility of DNA data storage hinges on continued cost reduction in both synthesis and sequencing technologies. Industry projections suggest that synthesis costs need to decrease by at least four orders of magnitude to become competitive with traditional storage media for archival applications. This would require breakthrough technologies rather than incremental improvements to current methods.
Several companies, including Catalog DNA and Microsoft Research, are developing custom DNA synthesis approaches specifically optimized for data storage rather than biological applications. These specialized systems prioritize throughput and cost over sequence accuracy and length, potentially offering a faster path to economic viability for specific use cases such as ultra-long-term archival storage of rarely accessed data.
From an economic perspective, the cost of DNA synthesis remains prohibitively high at approximately $0.001 per nucleotide. This translates to roughly $1 million per gigabyte of stored data, compared to less than $0.02 per gigabyte for conventional hard drives. While DNA reading costs through next-generation sequencing have decreased significantly, they still exceed $1,000 per genome, making frequent data retrieval economically unfeasible.
Scaling DNA data storage systems requires parallel processing approaches. Current research focuses on microfluidic platforms that can perform thousands of parallel synthesis reactions, potentially increasing throughput by several orders of magnitude. Similarly, advances in nanopore sequencing technology may enable direct reading of DNA molecules without amplification, reducing retrieval costs and time.
The economic feasibility of DNA data storage hinges on continued cost reduction in both synthesis and sequencing technologies. Industry projections suggest that synthesis costs need to decrease by at least four orders of magnitude to become competitive with traditional storage media for archival applications. This would require breakthrough technologies rather than incremental improvements to current methods.
Several companies, including Catalog DNA and Microsoft Research, are developing custom DNA synthesis approaches specifically optimized for data storage rather than biological applications. These specialized systems prioritize throughput and cost over sequence accuracy and length, potentially offering a faster path to economic viability for specific use cases such as ultra-long-term archival storage of rarely accessed data.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!