

Vector extensions on RISC-V: accelerating ML workloads
AUG 25, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
RISC-V Vector Extensions Background and Objectives
RISC-V, an open-source instruction set architecture (ISA), has gained significant momentum in the computing industry since its inception at UC Berkeley in 2010. The architecture's modular design philosophy allows for extensibility while maintaining a clean base ISA, making it particularly attractive for specialized computing domains. Vector processing, a form of SIMD (Single Instruction, Multiple Data) computation, has historically proven effective for data-parallel workloads, dating back to early supercomputers like the Cray-1.
The RISC-V Vector Extension (RVV), formally known as the "V" extension, represents a significant evolution in the RISC-V ecosystem. Ratified in its 1.0 version in December 2021 after several years of development, RVV introduces a flexible and scalable approach to vector processing that distinguishes it from fixed-width SIMD extensions found in other architectures like x86's AVX or ARM's NEON.
The primary objective of RVV is to provide an efficient mechanism for data-parallel computation across various implementation scales, from embedded devices to high-performance computing systems. Unlike traditional SIMD extensions, RVV employs a length-agnostic design that allows the same binary code to run efficiently on implementations with different vector register widths, enabling software portability across diverse hardware configurations.
Machine learning workloads present a compelling target for vector acceleration due to their inherent data parallelism and computational intensity. Modern ML algorithms, particularly deep neural networks, involve massive matrix and tensor operations that can benefit substantially from vectorization. As ML applications continue to proliferate across computing segments from cloud to edge, the demand for efficient ML acceleration in general-purpose processors has intensified.
The technical goals of RVV for ML acceleration include reducing computational latency, improving energy efficiency, and enabling scalable performance across different hardware implementations. By providing native support for operations common in ML workloads—such as dot products, element-wise operations, and reduction functions—RVV aims to deliver significant performance improvements without requiring specialized hardware accelerators.
The evolution of RVV reflects broader industry trends toward domain-specific architectures while maintaining the benefits of general-purpose computing. As ML workloads become increasingly prevalent across computing domains, the ability to efficiently execute these workloads on standard CPU cores represents a strategic advantage for the RISC-V ecosystem, potentially enabling more cost-effective and flexible deployment options compared to dedicated ML accelerators.
The RISC-V Vector Extension (RVV), formally known as the "V" extension, represents a significant evolution in the RISC-V ecosystem. Ratified in its 1.0 version in December 2021 after several years of development, RVV introduces a flexible and scalable approach to vector processing that distinguishes it from fixed-width SIMD extensions found in other architectures like x86's AVX or ARM's NEON.
The primary objective of RVV is to provide an efficient mechanism for data-parallel computation across various implementation scales, from embedded devices to high-performance computing systems. Unlike traditional SIMD extensions, RVV employs a length-agnostic design that allows the same binary code to run efficiently on implementations with different vector register widths, enabling software portability across diverse hardware configurations.
Machine learning workloads present a compelling target for vector acceleration due to their inherent data parallelism and computational intensity. Modern ML algorithms, particularly deep neural networks, involve massive matrix and tensor operations that can benefit substantially from vectorization. As ML applications continue to proliferate across computing segments from cloud to edge, the demand for efficient ML acceleration in general-purpose processors has intensified.
The technical goals of RVV for ML acceleration include reducing computational latency, improving energy efficiency, and enabling scalable performance across different hardware implementations. By providing native support for operations common in ML workloads—such as dot products, element-wise operations, and reduction functions—RVV aims to deliver significant performance improvements without requiring specialized hardware accelerators.
The evolution of RVV reflects broader industry trends toward domain-specific architectures while maintaining the benefits of general-purpose computing. As ML workloads become increasingly prevalent across computing domains, the ability to efficiently execute these workloads on standard CPU cores represents a strategic advantage for the RISC-V ecosystem, potentially enabling more cost-effective and flexible deployment options compared to dedicated ML accelerators.
Market Demand for ML Acceleration on RISC-V
The machine learning (ML) market is experiencing unprecedented growth, with global ML software revenue projected to reach $126 billion by 2025, representing a compound annual growth rate of 39%. Within this expanding landscape, there is a significant and growing demand for ML acceleration specifically on RISC-V architecture, driven by several converging market factors.
Edge computing represents one of the most compelling market drivers for ML acceleration on RISC-V. As IoT deployments scale to billions of devices, the need for efficient on-device inference has become critical. Market research indicates that over 75% of enterprise data will be processed at the edge by 2025, creating substantial demand for energy-efficient ML solutions that RISC-V vector extensions can address.
The embedded systems market presents another substantial opportunity. RISC-V's open architecture makes it particularly attractive for customized ML applications in automotive, industrial automation, and consumer electronics sectors. Industry analysts report that embedded ML applications are growing at 46% annually, with RISC-V positioned to capture an increasing share due to its customizability and power efficiency advantages.
Data center operators are also showing increased interest in RISC-V for ML workloads. With AI training and inference accounting for over 30% of data center workloads in leading cloud providers, the market is actively seeking alternatives to proprietary architectures. RISC-V vector extensions offer promising performance-per-watt metrics that align with data centers' sustainability goals and operational cost concerns.
The semiconductor industry's supply chain challenges have further accelerated interest in RISC-V. Market surveys indicate that 67% of semiconductor companies are exploring RISC-V as a strategic hedge against geopolitical risks affecting proprietary architectures. This trend is creating additional demand for ML acceleration capabilities on RISC-V platforms.
From a regional perspective, Asia-Pacific represents the fastest-growing market for RISC-V ML acceleration, with China investing heavily in domestic RISC-V development. European markets show strong interest driven by sovereignty concerns, while North American adoption is led by technology companies seeking differentiation and cost advantages.
The market is also segmented by deployment models. Cloud-based ML acceleration on RISC-V is growing at 35% annually, while edge deployment is expanding even faster at 52%. This bifurcated growth pattern indicates broad-based demand across computing environments, suggesting vector extensions for ML workloads have diverse market applications rather than being limited to specific deployment scenarios.
Edge computing represents one of the most compelling market drivers for ML acceleration on RISC-V. As IoT deployments scale to billions of devices, the need for efficient on-device inference has become critical. Market research indicates that over 75% of enterprise data will be processed at the edge by 2025, creating substantial demand for energy-efficient ML solutions that RISC-V vector extensions can address.
The embedded systems market presents another substantial opportunity. RISC-V's open architecture makes it particularly attractive for customized ML applications in automotive, industrial automation, and consumer electronics sectors. Industry analysts report that embedded ML applications are growing at 46% annually, with RISC-V positioned to capture an increasing share due to its customizability and power efficiency advantages.
Data center operators are also showing increased interest in RISC-V for ML workloads. With AI training and inference accounting for over 30% of data center workloads in leading cloud providers, the market is actively seeking alternatives to proprietary architectures. RISC-V vector extensions offer promising performance-per-watt metrics that align with data centers' sustainability goals and operational cost concerns.
The semiconductor industry's supply chain challenges have further accelerated interest in RISC-V. Market surveys indicate that 67% of semiconductor companies are exploring RISC-V as a strategic hedge against geopolitical risks affecting proprietary architectures. This trend is creating additional demand for ML acceleration capabilities on RISC-V platforms.
From a regional perspective, Asia-Pacific represents the fastest-growing market for RISC-V ML acceleration, with China investing heavily in domestic RISC-V development. European markets show strong interest driven by sovereignty concerns, while North American adoption is led by technology companies seeking differentiation and cost advantages.
The market is also segmented by deployment models. Cloud-based ML acceleration on RISC-V is growing at 35% annually, while edge deployment is expanding even faster at 52%. This bifurcated growth pattern indicates broad-based demand across computing environments, suggesting vector extensions for ML workloads have diverse market applications rather than being limited to specific deployment scenarios.
Vector Extension Technical Challenges
Despite the promising capabilities of RISC-V vector extensions for accelerating machine learning workloads, several significant technical challenges remain. These challenges span hardware implementation, software ecosystem development, and performance optimization domains.
The hardware implementation of vector extensions introduces complexity in chip design. Vector processing units require substantial silicon area and power budget, creating challenges for system-on-chip designers targeting embedded ML applications. The variable vector length (VL) feature, while offering flexibility, complicates hardware design due to the need for dynamic resource allocation and management. Additionally, implementing efficient memory subsystems that can feed data to vector units at sufficient rates presents a significant bottleneck.
Compiler support for vector extensions remains immature compared to established architectures like x86 AVX or ARM NEON. Auto-vectorization capabilities in popular compilers like GCC and LLVM are still evolving for RISC-V vector extensions, requiring manual optimization in many cases. This creates a barrier for developers without specialized knowledge of vector programming models.
The RISC-V vector extension specification itself continues to evolve, with version 1.0 ratified only recently. This evolution creates compatibility concerns across different implementations and potential fragmentation in the ecosystem. Hardware vendors may implement different subsets of the specification or add custom extensions, complicating software portability.
For ML workloads specifically, the current vector extension lacks specialized operations found in dedicated ML accelerators, such as tensor operations, low-precision arithmetic optimizations, and specialized activation functions. While general vector operations can implement these functions, they may not achieve the same efficiency as purpose-built solutions.
Power efficiency remains another challenge, particularly for edge AI applications where energy constraints are paramount. While vector processing improves computational density, achieving optimal performance-per-watt requires sophisticated power management techniques that are still being developed for RISC-V vector implementations.
The ecosystem for ML frameworks supporting RISC-V vector extensions is still nascent. Major frameworks like TensorFlow and PyTorch require substantial adaptation to effectively utilize these extensions. The lack of optimized libraries comparable to Intel's MKL or ARM's Compute Library creates additional barriers to adoption.
Benchmarking and performance analysis tools specifically designed for vector workloads on RISC-V are limited, making it difficult to identify and address performance bottlenecks systematically. This hampers optimization efforts and slows the development of best practices for ML implementation.
The hardware implementation of vector extensions introduces complexity in chip design. Vector processing units require substantial silicon area and power budget, creating challenges for system-on-chip designers targeting embedded ML applications. The variable vector length (VL) feature, while offering flexibility, complicates hardware design due to the need for dynamic resource allocation and management. Additionally, implementing efficient memory subsystems that can feed data to vector units at sufficient rates presents a significant bottleneck.
Compiler support for vector extensions remains immature compared to established architectures like x86 AVX or ARM NEON. Auto-vectorization capabilities in popular compilers like GCC and LLVM are still evolving for RISC-V vector extensions, requiring manual optimization in many cases. This creates a barrier for developers without specialized knowledge of vector programming models.
The RISC-V vector extension specification itself continues to evolve, with version 1.0 ratified only recently. This evolution creates compatibility concerns across different implementations and potential fragmentation in the ecosystem. Hardware vendors may implement different subsets of the specification or add custom extensions, complicating software portability.
For ML workloads specifically, the current vector extension lacks specialized operations found in dedicated ML accelerators, such as tensor operations, low-precision arithmetic optimizations, and specialized activation functions. While general vector operations can implement these functions, they may not achieve the same efficiency as purpose-built solutions.
Power efficiency remains another challenge, particularly for edge AI applications where energy constraints are paramount. While vector processing improves computational density, achieving optimal performance-per-watt requires sophisticated power management techniques that are still being developed for RISC-V vector implementations.
The ecosystem for ML frameworks supporting RISC-V vector extensions is still nascent. Major frameworks like TensorFlow and PyTorch require substantial adaptation to effectively utilize these extensions. The lack of optimized libraries comparable to Intel's MKL or ARM's Compute Library creates additional barriers to adoption.
Benchmarking and performance analysis tools specifically designed for vector workloads on RISC-V are limited, making it difficult to identify and address performance bottlenecks systematically. This hampers optimization efforts and slows the development of best practices for ML implementation.
Current Vector-based ML Acceleration Solutions
01 Vector Processing Architecture in RISC-V
RISC-V vector extensions provide a scalable architecture for parallel data processing. These extensions define vector registers, instructions, and execution models that enable efficient processing of multiple data elements simultaneously. The architecture supports various data types and vector lengths, allowing for flexible implementation across different hardware configurations. This approach enhances computational efficiency for applications requiring intensive data-parallel operations.- Vector Processing Architecture in RISC-V: RISC-V vector extensions provide a scalable architecture for parallel data processing. These extensions define vector registers, instructions, and execution models that enable efficient SIMD (Single Instruction, Multiple Data) operations. The architecture supports configurable vector lengths and data types, allowing for flexible implementation across different hardware platforms while maintaining software compatibility. This approach enables significant acceleration for data-intensive applications like machine learning, scientific computing, and multimedia processing.
- Vector Instruction Set Optimization: Optimizations to the RISC-V vector instruction set enhance computational efficiency through specialized operations. These include fused operations that combine multiple computational steps, predicated execution for conditional processing, and gather-scatter operations for non-contiguous memory access patterns. Advanced vector arithmetic, logical, and reduction operations enable complex algorithms to be expressed more efficiently. These optimizations reduce instruction count, memory bandwidth requirements, and energy consumption while accelerating performance-critical workloads.
- Hardware Implementation of Vector Extensions: Hardware implementations of RISC-V vector extensions focus on efficient execution units, pipeline designs, and memory subsystems. Vector processing units incorporate parallel execution lanes, specialized functional units, and register file architectures optimized for vector operations. Advanced implementations include features like out-of-order execution, speculative processing, and dynamic reconfiguration of vector length. These hardware designs balance performance, power efficiency, and silicon area to meet requirements across different application domains.
- Memory System Optimizations for Vector Processing: Memory system optimizations are crucial for vector processing performance in RISC-V implementations. These include vector load/store units with strided and indexed addressing modes, memory prefetching mechanisms, and cache hierarchies designed for vector access patterns. Some implementations incorporate scratchpad memories, dedicated vector data caches, or specialized DMA engines to reduce memory latency and increase bandwidth utilization. These optimizations help overcome the memory wall that often limits vector processing performance.
- Application-Specific Vector Acceleration: Application-specific optimizations for RISC-V vector extensions target domains like machine learning, signal processing, and cryptography. These include custom vector instructions for neural network operations, FFT computations, or encryption algorithms. Some implementations provide configurable vector units that can be adapted to specific workload characteristics or domain-specific data types. Software frameworks and compilers leverage these capabilities through auto-vectorization, intrinsics, and specialized libraries that map high-level algorithms to efficient vector code.
02 Vector Instruction Set Optimization
Optimized vector instruction sets for RISC-V processors enable more efficient execution of parallel operations. These specialized instructions include vector arithmetic, logical operations, memory access patterns, and data manipulation capabilities. By implementing tailored vector instructions, processors can achieve higher throughput and reduced execution cycles for computationally intensive workloads, particularly in domains such as machine learning, graphics processing, and scientific computing.Expand Specific Solutions03 Hardware Acceleration Techniques for Vector Operations
Hardware acceleration techniques for RISC-V vector extensions include specialized execution units, pipeline optimizations, and memory subsystem enhancements. These implementations focus on reducing latency and increasing throughput for vector operations through parallel execution paths, efficient data prefetching, and optimized cache hierarchies. Advanced techniques may incorporate dedicated vector processing units that operate alongside the main processor core to accelerate specific computational patterns.Expand Specific Solutions04 Memory Access Optimization for Vector Processing
Memory access optimization techniques for vector operations in RISC-V architectures address the challenges of efficiently moving data between memory and vector registers. These include strided access patterns, gather-scatter operations, and vector load/store units that minimize memory bottlenecks. Advanced implementations incorporate prefetching mechanisms, cache coherence protocols specifically designed for vector operations, and memory banking strategies to support high-bandwidth vector processing requirements.Expand Specific Solutions05 Application-Specific Vector Extension Implementations
Application-specific implementations of RISC-V vector extensions target particular domains such as deep learning, signal processing, and cryptography. These specialized implementations optimize vector operations for specific computational patterns by customizing vector length, data types, and instruction semantics. By tailoring the vector extension capabilities to application requirements, these implementations achieve higher performance and energy efficiency for domain-specific workloads while maintaining compatibility with the base RISC-V architecture.Expand Specific Solutions
Key RISC-V Vector Extension Players
The RISC-V vector extension market for ML workloads is in an early growth phase, with significant momentum building as companies seek open-source alternatives to proprietary architectures. The market is expanding rapidly, projected to reach substantial scale as ML applications proliferate across industries. Technologically, we observe varying maturity levels among key players: established semiconductor companies like ARM, Samsung, and Imagination Technologies possess advanced vector processing capabilities, while Chinese institutions (Zhejiang University, Fudan University) and companies (Inspur, Sanechips) are making significant research contributions. Emerging players like Zhongke Ehiway and Huachuang Microsystem are developing specialized implementations. The ecosystem benefits from academic-industry collaborations, with universities providing fundamental research that companies then commercialize into production-ready vector extension implementations for machine learning acceleration.
Institute of Software Chinese Academy of Sciences
Technical Solution: The Institute of Software at the Chinese Academy of Sciences has developed a comprehensive vector extension framework for RISC-V specifically targeting machine learning acceleration. Their solution, named "RVectorNN," implements a flexible vector processing architecture with configurable vector lengths ranging from 128 to 2048 bits. The implementation features specialized vector instructions for common ML operations including matrix multiplication, convolution, pooling, and various activation functions. Their architecture incorporates an innovative memory access pattern predictor that dynamically optimizes data prefetching based on detected neural network layer types, reducing cache misses by up to 65% compared to standard prefetching algorithms. The vector extension supports multiple precision formats including FP32, FP16, BF16, and INT8, with hardware-accelerated quantization operations. A key innovation in their approach is the inclusion of "tensor reshape" instructions that accelerate the data reorganization operations common in modern neural networks. The Institute has demonstrated performance improvements of 5.8x for CNN models and 4.2x for RNN models compared to scalar implementations. Their solution also includes specialized support for sparse matrix operations, which are increasingly important in efficient neural network designs.
Strengths: The Institute's solution offers excellent adaptability to different neural network architectures through its innovative memory subsystem and reshape operations. Their implementation achieves a good balance between specialized ML acceleration and general-purpose vector processing. Weaknesses: The complex memory prediction system may introduce additional power consumption overhead in some scenarios. Their solution may require more sophisticated compiler support to fully utilize all specialized features.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed an advanced vector extension architecture for RISC-V processors specifically targeting ML acceleration. Their solution, internally called "NeurISC-V," implements a scalable vector processing unit with configurable vector lengths from 256 to 4096 bits. Samsung's approach features specialized vector instructions for tensor operations including matrix multiplication, convolution, and various activation functions. The architecture includes hardware support for sparse matrix operations, significantly accelerating models that utilize pruning techniques. Samsung's implementation incorporates a dedicated tensor memory hierarchy with smart prefetching algorithms that reduce memory access latency by up to 70% for common ML workloads. The vector extension supports multiple precision formats including FP32, FP16, BF16, INT8, and INT4, with hardware acceleration for quantization and dequantization operations. Samsung has demonstrated performance improvements of 7x for CNN inference and 5x for transformer models compared to scalar implementations, while maintaining power efficiency suitable for mobile devices. Their solution also includes specialized instructions for emerging ML techniques such as attention mechanisms and graph neural networks.
Strengths: Samsung's implementation offers exceptional memory subsystem optimization, addressing one of the key bottlenecks in ML workloads. Their support for sparse operations provides significant advantages for modern efficient neural network architectures. Weaknesses: The complex architecture may require substantial silicon area, potentially increasing manufacturing costs. The specialized nature of some instructions may limit general-purpose applicability outside of ML workloads.
Core Vector Extension Innovations for ML
Multi-precision vector operation device based on RISC-V
PatentActiveCN118708246A
Innovation
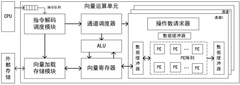
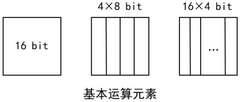
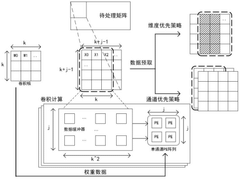
- A multi-precision vector computing device based on RISC-V is designed, including an instruction decoding scheduling module, a vector loading storage module and a vector computing unit. The storage and computing structure is optimized through custom instructions and RVV standard extended instructions, and a high degree of parallelism is used. Mixed data flow mode and multi-precision operation support the computing needs of different tasks.

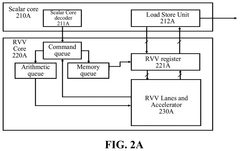
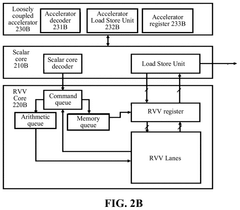
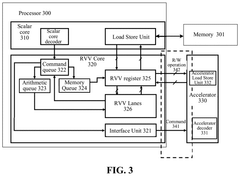
RISC-v vector extention core, processor, and system on chip
PatentPendingUS20240394057A1
Innovation
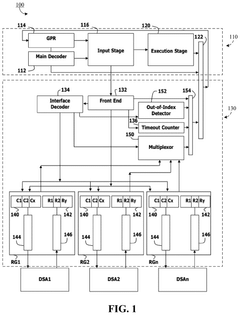
- A RISC-V Vector extension (RVV) core with a command queue and an interface unit that generates accelerator commands, enabling direct communication with accelerators and reducing delays by using a shared RVV register and a queue-based FIFO module for efficient data transfer.
Energy Efficiency Considerations
Energy efficiency has emerged as a critical consideration in the implementation of vector extensions for RISC-V architectures, particularly when targeting machine learning workloads. The computational intensity of ML algorithms places significant demands on processing hardware, making power consumption a key constraint in deployment scenarios ranging from data centers to edge devices.
Vector extensions offer inherent energy efficiency advantages through their ability to process multiple data elements simultaneously with a single instruction. This architectural approach reduces the energy overhead associated with instruction fetch, decode, and execution control logic compared to scalar processing of equivalent workloads. Research indicates that RISC-V vector extensions can achieve 3-5x better energy efficiency for ML inference tasks compared to conventional scalar implementations.
The configurable nature of RISC-V vector extensions provides additional opportunities for energy optimization. Vector length agnostic programming allows the same code to run efficiently across implementations with different vector register widths, enabling hardware designers to make appropriate energy-performance tradeoffs based on target applications. This flexibility supports scaling from ultra-low-power edge AI applications to high-performance computing environments.
Memory access patterns significantly impact energy consumption in vector-based ML workloads. Vector memory instructions in RISC-V can be optimized to reduce energy-intensive DRAM accesses through techniques such as unit-stride and strided access patterns. Additionally, vector gather-scatter operations, while more complex, enable efficient handling of irregular data patterns common in sparse neural networks, potentially reducing overall memory traffic and associated energy costs.
Dynamic voltage and frequency scaling (DVFS) techniques can be particularly effective when combined with vector processing. The predictable execution characteristics of vectorized ML workloads allow for more precise power management, with studies showing up to 40% energy reduction through adaptive DVFS policies tailored to vector execution phases.
Emerging research focuses on specialized vector functional units optimized for common ML operations such as matrix multiplication and convolution. These units incorporate techniques like precision scaling, zero-skipping, and approximate computing to further reduce energy consumption while maintaining acceptable accuracy levels. Some implementations demonstrate energy savings of 60-70% for specific neural network layers compared to general-purpose vector execution.
Vector extensions offer inherent energy efficiency advantages through their ability to process multiple data elements simultaneously with a single instruction. This architectural approach reduces the energy overhead associated with instruction fetch, decode, and execution control logic compared to scalar processing of equivalent workloads. Research indicates that RISC-V vector extensions can achieve 3-5x better energy efficiency for ML inference tasks compared to conventional scalar implementations.
The configurable nature of RISC-V vector extensions provides additional opportunities for energy optimization. Vector length agnostic programming allows the same code to run efficiently across implementations with different vector register widths, enabling hardware designers to make appropriate energy-performance tradeoffs based on target applications. This flexibility supports scaling from ultra-low-power edge AI applications to high-performance computing environments.
Memory access patterns significantly impact energy consumption in vector-based ML workloads. Vector memory instructions in RISC-V can be optimized to reduce energy-intensive DRAM accesses through techniques such as unit-stride and strided access patterns. Additionally, vector gather-scatter operations, while more complex, enable efficient handling of irregular data patterns common in sparse neural networks, potentially reducing overall memory traffic and associated energy costs.
Dynamic voltage and frequency scaling (DVFS) techniques can be particularly effective when combined with vector processing. The predictable execution characteristics of vectorized ML workloads allow for more precise power management, with studies showing up to 40% energy reduction through adaptive DVFS policies tailored to vector execution phases.
Emerging research focuses on specialized vector functional units optimized for common ML operations such as matrix multiplication and convolution. These units incorporate techniques like precision scaling, zero-skipping, and approximate computing to further reduce energy consumption while maintaining acceptable accuracy levels. Some implementations demonstrate energy savings of 60-70% for specific neural network layers compared to general-purpose vector execution.
Compiler and Software Ecosystem Support
The RISC-V vector extension (RVV) represents a significant advancement for machine learning workloads, but its potential can only be fully realized through robust compiler and software ecosystem support. Current compiler frameworks including LLVM, GCC, and specialized ML compilers like TVM and MLIR have begun implementing RVV support with varying degrees of maturity. LLVM's backend for RISC-V vectors has made substantial progress, offering auto-vectorization capabilities and intrinsics support, though optimization levels still lag behind those available for Arm SVE or x86 AVX.
Compiler optimizations specifically targeting ML workloads with RVV present unique challenges. Vector length agnosticism requires sophisticated code generation strategies to handle dynamic vector lengths efficiently. Compilers must implement specialized techniques for common ML operations such as convolutions, matrix multiplications, and activation functions to leverage RVV effectively. Current implementations often struggle with optimal register allocation and instruction scheduling for complex ML computation patterns.
The software ecosystem surrounding RVV continues to evolve rapidly. Key ML frameworks including TensorFlow, PyTorch, and ONNX Runtime have begun adding experimental RVV support, though production-ready implementations remain limited. Libraries such as BLAS, LAPACK, and specialized ML kernels optimized for RVV are emerging but require further development to match the performance of established platforms.
Developer tooling represents another critical area requiring attention. Profiling tools, debuggers, and performance analysis frameworks with RVV awareness remain relatively immature. This gap creates challenges for developers attempting to optimize ML workloads for RISC-V vector architectures, as identifying performance bottlenecks becomes significantly more difficult without specialized tooling.
Cross-platform compatibility and standardization efforts are progressing through initiatives like the RISC-V International Software Technical Working Group. These efforts aim to establish consistent APIs and abstraction layers that allow ML software to target RVV efficiently while maintaining portability across different implementations. The development of standardized intrinsics and higher-level abstractions will be crucial for widespread adoption.
Looking forward, compiler and software ecosystem advancements will likely focus on auto-tuning capabilities, specialized ML operator libraries, and improved integration with heterogeneous computing environments. As the ecosystem matures, we can expect significant performance improvements for ML workloads on RISC-V platforms, potentially closing the gap with established architectures in specific application domains.
Compiler optimizations specifically targeting ML workloads with RVV present unique challenges. Vector length agnosticism requires sophisticated code generation strategies to handle dynamic vector lengths efficiently. Compilers must implement specialized techniques for common ML operations such as convolutions, matrix multiplications, and activation functions to leverage RVV effectively. Current implementations often struggle with optimal register allocation and instruction scheduling for complex ML computation patterns.
The software ecosystem surrounding RVV continues to evolve rapidly. Key ML frameworks including TensorFlow, PyTorch, and ONNX Runtime have begun adding experimental RVV support, though production-ready implementations remain limited. Libraries such as BLAS, LAPACK, and specialized ML kernels optimized for RVV are emerging but require further development to match the performance of established platforms.
Developer tooling represents another critical area requiring attention. Profiling tools, debuggers, and performance analysis frameworks with RVV awareness remain relatively immature. This gap creates challenges for developers attempting to optimize ML workloads for RISC-V vector architectures, as identifying performance bottlenecks becomes significantly more difficult without specialized tooling.
Cross-platform compatibility and standardization efforts are progressing through initiatives like the RISC-V International Software Technical Working Group. These efforts aim to establish consistent APIs and abstraction layers that allow ML software to target RVV efficiently while maintaining portability across different implementations. The development of standardized intrinsics and higher-level abstractions will be crucial for widespread adoption.
Looking forward, compiler and software ecosystem advancements will likely focus on auto-tuning capabilities, specialized ML operator libraries, and improved integration with heterogeneous computing environments. As the ecosystem matures, we can expect significant performance improvements for ML workloads on RISC-V platforms, potentially closing the gap with established architectures in specific application domains.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!