Comparative Study on Neuromorphic Chips and AI Processors
OCT 9, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Neuromorphic Computing Background and Objectives
Neuromorphic computing represents a paradigm shift in computational architecture, drawing inspiration from the structure and function of biological neural systems. This field emerged in the late 1980s when Carver Mead first introduced the concept of using analog circuits to mimic neurobiological architectures. Since then, neuromorphic computing has evolved significantly, transitioning from theoretical frameworks to practical implementations in specialized hardware.
The evolution of neuromorphic computing has been characterized by several key milestones. Early developments focused on creating silicon neurons and synapses that could replicate basic neural functions. As semiconductor technology advanced, researchers began developing more sophisticated neuromorphic systems capable of implementing complex neural network models. Recent years have witnessed the emergence of large-scale neuromorphic chips with millions of neurons and billions of synapses, marking a significant leap in computational capabilities.
Current technological trends in neuromorphic computing are moving toward greater integration of learning capabilities, improved energy efficiency, and enhanced scalability. Unlike traditional von Neumann architectures that separate memory and processing units, neuromorphic systems co-locate these functions, potentially offering orders of magnitude improvements in energy efficiency for certain computational tasks. This architectural advantage becomes increasingly important as AI applications continue to demand more computational resources.
The primary objective of neuromorphic computing research is to develop hardware that can process information in a manner similar to biological brains, combining high computational efficiency with low power consumption. This goal encompasses several specific aims: creating systems capable of real-time sensory processing, developing hardware that can adapt and learn from its environment, and designing chips that can operate effectively under power constraints.
When comparing neuromorphic chips with traditional AI processors such as GPUs and TPUs, several fundamental differences emerge. While conventional AI processors excel at parallel processing of matrix operations critical for deep learning, they remain fundamentally digital and rely on the von Neumann architecture. Neuromorphic chips, conversely, often incorporate analog components and event-driven processing, potentially offering advantages for applications requiring real-time processing of sensory data or operation in power-limited environments.
The technological trajectory suggests that neuromorphic computing may complement rather than replace conventional AI processors, with each approach offering distinct advantages for different application domains. As research continues, the integration of neuromorphic principles with traditional computing architectures may yield hybrid systems that leverage the strengths of both paradigms.
The evolution of neuromorphic computing has been characterized by several key milestones. Early developments focused on creating silicon neurons and synapses that could replicate basic neural functions. As semiconductor technology advanced, researchers began developing more sophisticated neuromorphic systems capable of implementing complex neural network models. Recent years have witnessed the emergence of large-scale neuromorphic chips with millions of neurons and billions of synapses, marking a significant leap in computational capabilities.
Current technological trends in neuromorphic computing are moving toward greater integration of learning capabilities, improved energy efficiency, and enhanced scalability. Unlike traditional von Neumann architectures that separate memory and processing units, neuromorphic systems co-locate these functions, potentially offering orders of magnitude improvements in energy efficiency for certain computational tasks. This architectural advantage becomes increasingly important as AI applications continue to demand more computational resources.
The primary objective of neuromorphic computing research is to develop hardware that can process information in a manner similar to biological brains, combining high computational efficiency with low power consumption. This goal encompasses several specific aims: creating systems capable of real-time sensory processing, developing hardware that can adapt and learn from its environment, and designing chips that can operate effectively under power constraints.
When comparing neuromorphic chips with traditional AI processors such as GPUs and TPUs, several fundamental differences emerge. While conventional AI processors excel at parallel processing of matrix operations critical for deep learning, they remain fundamentally digital and rely on the von Neumann architecture. Neuromorphic chips, conversely, often incorporate analog components and event-driven processing, potentially offering advantages for applications requiring real-time processing of sensory data or operation in power-limited environments.
The technological trajectory suggests that neuromorphic computing may complement rather than replace conventional AI processors, with each approach offering distinct advantages for different application domains. As research continues, the integration of neuromorphic principles with traditional computing architectures may yield hybrid systems that leverage the strengths of both paradigms.
Market Analysis for Brain-Inspired Computing Solutions
The brain-inspired computing market is experiencing significant growth, driven by increasing demand for efficient AI processing solutions that mimic human neural networks. Current market valuations place this sector at approximately $2.5 billion in 2023, with projections indicating a compound annual growth rate of 24% through 2030, potentially reaching $11.4 billion. This growth trajectory is supported by substantial investments from both private and public sectors, with venture capital funding exceeding $1.2 billion in neuromorphic computing startups over the past three years.
Market segmentation reveals distinct application domains driving demand for brain-inspired computing solutions. The automotive sector represents 18% of current market share, primarily focused on advanced driver assistance systems and autonomous vehicle development. Healthcare applications account for 22%, with neuromorphic solutions enabling real-time processing of complex medical imaging and patient monitoring data. Edge computing devices constitute 27% of the market, where power efficiency is paramount. The remaining market share is distributed across robotics, aerospace, and consumer electronics applications.
Regional analysis indicates North America leads with 42% market share, followed by Europe (28%), Asia-Pacific (24%), and rest of world (6%). China and South Korea are demonstrating the fastest growth rates, with government initiatives specifically targeting neuromorphic technology development as strategic priorities. The Asia-Pacific region is projected to grow at 29% annually, potentially overtaking Europe in market share by 2027.
Customer demand patterns show increasing preference for hybrid solutions that combine traditional von Neumann architectures with neuromorphic accelerators, allowing gradual integration into existing systems. Enterprise customers cite energy efficiency as the primary adoption driver (68%), followed by real-time processing capabilities (57%) and reduced latency (49%). However, adoption barriers remain significant, with 72% of potential enterprise customers citing lack of software ecosystem maturity as a major concern.
Competitive dynamics reveal a market dominated by established semiconductor companies (38% market share) and specialized neuromorphic startups (31%). Academic institution spin-offs account for 18% of market players, while cloud service providers have entered the market with 13% share, primarily offering neuromorphic computing as specialized cloud services. This diverse competitive landscape is driving rapid innovation cycles, with new chip architectures being announced quarterly.
Market segmentation reveals distinct application domains driving demand for brain-inspired computing solutions. The automotive sector represents 18% of current market share, primarily focused on advanced driver assistance systems and autonomous vehicle development. Healthcare applications account for 22%, with neuromorphic solutions enabling real-time processing of complex medical imaging and patient monitoring data. Edge computing devices constitute 27% of the market, where power efficiency is paramount. The remaining market share is distributed across robotics, aerospace, and consumer electronics applications.
Regional analysis indicates North America leads with 42% market share, followed by Europe (28%), Asia-Pacific (24%), and rest of world (6%). China and South Korea are demonstrating the fastest growth rates, with government initiatives specifically targeting neuromorphic technology development as strategic priorities. The Asia-Pacific region is projected to grow at 29% annually, potentially overtaking Europe in market share by 2027.
Customer demand patterns show increasing preference for hybrid solutions that combine traditional von Neumann architectures with neuromorphic accelerators, allowing gradual integration into existing systems. Enterprise customers cite energy efficiency as the primary adoption driver (68%), followed by real-time processing capabilities (57%) and reduced latency (49%). However, adoption barriers remain significant, with 72% of potential enterprise customers citing lack of software ecosystem maturity as a major concern.
Competitive dynamics reveal a market dominated by established semiconductor companies (38% market share) and specialized neuromorphic startups (31%). Academic institution spin-offs account for 18% of market players, while cloud service providers have entered the market with 13% share, primarily offering neuromorphic computing as specialized cloud services. This diverse competitive landscape is driving rapid innovation cycles, with new chip architectures being announced quarterly.
Current Landscape and Technical Barriers in Neuromorphic Engineering
Neuromorphic engineering has witnessed significant advancements in recent years, with various research institutions and technology companies developing specialized hardware that mimics the brain's neural architecture. Currently, the landscape is characterized by a diverse range of approaches, from analog and digital implementations to hybrid systems that combine elements of both. Major research centers like IBM Research, Intel Labs, and academic institutions such as the University of Manchester and ETH Zurich have established themselves as pioneers in this field.
Despite these advancements, neuromorphic engineering faces several critical technical barriers. Power efficiency remains a significant challenge, as current implementations still consume considerably more energy than the human brain when performing comparable computational tasks. While the human brain operates on approximately 20 watts, most neuromorphic systems require substantially more power, limiting their practical deployment in edge computing scenarios.
Scalability presents another major obstacle. Current fabrication techniques struggle to integrate the vast number of artificial neurons and synapses required to match even a fraction of the human brain's complexity. The most advanced neuromorphic chips today feature millions of neurons, whereas the human brain contains approximately 86 billion neurons with trillions of synaptic connections.
Material limitations also constrain progress in the field. Traditional CMOS technology, while well-established, imposes fundamental limitations on how closely artificial neural systems can mimic biological ones. Alternative materials such as memristors show promise but face challenges in manufacturing consistency, reliability, and integration with existing semiconductor processes.
Learning algorithms represent another significant barrier. While traditional AI processors excel at implementing well-defined machine learning algorithms, neuromorphic systems require specialized learning approaches that can leverage their unique architectures. Current spike-based learning algorithms are still in their infancy compared to the sophisticated deep learning frameworks available for conventional AI processors.
The geographical distribution of neuromorphic research shows concentration in North America, Europe, and increasingly in Asia, particularly China and Japan. This distribution reflects both historical expertise in semiconductor technology and strategic national investments in advanced computing technologies.
When comparing neuromorphic chips with traditional AI processors, fundamental architectural differences become apparent. While AI processors like GPUs and TPUs excel at parallel matrix operations critical for deep learning, they follow a fundamentally different computing paradigm than neuromorphic systems, which prioritize event-driven processing and distributed memory. This creates significant challenges in benchmarking and standardization across these disparate approaches.
Despite these advancements, neuromorphic engineering faces several critical technical barriers. Power efficiency remains a significant challenge, as current implementations still consume considerably more energy than the human brain when performing comparable computational tasks. While the human brain operates on approximately 20 watts, most neuromorphic systems require substantially more power, limiting their practical deployment in edge computing scenarios.
Scalability presents another major obstacle. Current fabrication techniques struggle to integrate the vast number of artificial neurons and synapses required to match even a fraction of the human brain's complexity. The most advanced neuromorphic chips today feature millions of neurons, whereas the human brain contains approximately 86 billion neurons with trillions of synaptic connections.
Material limitations also constrain progress in the field. Traditional CMOS technology, while well-established, imposes fundamental limitations on how closely artificial neural systems can mimic biological ones. Alternative materials such as memristors show promise but face challenges in manufacturing consistency, reliability, and integration with existing semiconductor processes.
Learning algorithms represent another significant barrier. While traditional AI processors excel at implementing well-defined machine learning algorithms, neuromorphic systems require specialized learning approaches that can leverage their unique architectures. Current spike-based learning algorithms are still in their infancy compared to the sophisticated deep learning frameworks available for conventional AI processors.
The geographical distribution of neuromorphic research shows concentration in North America, Europe, and increasingly in Asia, particularly China and Japan. This distribution reflects both historical expertise in semiconductor technology and strategic national investments in advanced computing technologies.
When comparing neuromorphic chips with traditional AI processors, fundamental architectural differences become apparent. While AI processors like GPUs and TPUs excel at parallel matrix operations critical for deep learning, they follow a fundamentally different computing paradigm than neuromorphic systems, which prioritize event-driven processing and distributed memory. This creates significant challenges in benchmarking and standardization across these disparate approaches.
Contemporary Architectures for Neural Computing
01 Neuromorphic Computing Architecture
Neuromorphic chips are designed to mimic the structure and functionality of the human brain, using artificial neural networks to process information in a parallel and distributed manner. These architectures incorporate spiking neural networks (SNNs) that simulate the behavior of biological neurons, enabling more efficient processing of complex data patterns and reducing power consumption compared to traditional computing systems. The architecture typically includes interconnected neuron and synapse elements that can adapt and learn from input data.- Neuromorphic Computing Architecture: Neuromorphic chips are designed to mimic the structure and functionality of the human brain, using artificial neural networks to process information in a parallel and distributed manner. These architectures incorporate spiking neural networks (SNNs) that simulate the behavior of biological neurons, enabling efficient processing of complex patterns and learning from unstructured data. The neuromorphic computing approach offers advantages in terms of energy efficiency and real-time processing capabilities for AI applications.
- Hardware Acceleration for AI Processing: Specialized hardware accelerators are designed to optimize the performance of AI workloads by implementing dedicated circuits for matrix operations, tensor processing, and neural network computations. These accelerators can significantly improve the speed and energy efficiency of AI algorithms compared to general-purpose processors. The hardware acceleration techniques include parallel processing units, optimized memory hierarchies, and specialized instruction sets tailored for machine learning operations.
- Energy-Efficient AI Chip Design: Energy efficiency is a critical consideration in the design of neuromorphic chips and AI processors, particularly for edge computing applications. Various techniques are employed to minimize power consumption while maintaining computational performance, including low-power circuit design, dynamic voltage and frequency scaling, and event-driven processing. These approaches enable AI processing capabilities in resource-constrained environments such as IoT devices, wearables, and autonomous systems.
- On-Chip Learning and Adaptation: Advanced neuromorphic chips incorporate on-chip learning capabilities that allow the system to adapt and improve performance based on input data without requiring external training. These chips implement various learning algorithms such as spike-timing-dependent plasticity (STDP), reinforcement learning, and unsupervised learning mechanisms directly in hardware. The ability to learn and adapt in real-time makes these processors suitable for applications requiring continuous adaptation to changing environments.
- Integration of Emerging Memory Technologies: Neuromorphic chips and AI processors increasingly incorporate emerging non-volatile memory technologies such as resistive RAM (ReRAM), phase-change memory (PCM), and magnetoresistive RAM (MRAM) to implement synaptic functions. These memory technologies enable efficient storage of synaptic weights, reduce power consumption, and support in-memory computing paradigms. The integration of these technologies allows for more compact and energy-efficient implementations of neural networks, bridging the gap between conventional computing architectures and brain-inspired systems.
02 AI Processor Hardware Optimization
AI processors are specifically designed to accelerate machine learning workloads through hardware optimizations. These include specialized matrix multiplication units, tensor processing cores, and parallel processing elements that significantly improve the performance of neural network computations. The hardware is optimized for both training and inference operations, with features such as reduced precision arithmetic, dedicated memory hierarchies, and custom data paths that minimize data movement and maximize computational efficiency.Expand Specific Solutions03 Energy-Efficient Computing for AI
Energy efficiency is a critical aspect of modern AI and neuromorphic chip design. These processors implement various techniques to reduce power consumption while maintaining high computational performance, including event-driven processing, sparse computing, and dynamic voltage and frequency scaling. Some designs incorporate analog computing elements that perform calculations with significantly lower energy requirements than digital counterparts. These approaches enable AI processing in edge devices with limited power budgets and improve the sustainability of data center operations.Expand Specific Solutions04 On-Chip Learning and Adaptation
Advanced neuromorphic chips incorporate on-chip learning capabilities that allow the system to adapt to new data without requiring external training. These chips implement various learning algorithms directly in hardware, including spike-timing-dependent plasticity (STDP), reinforcement learning, and unsupervised learning mechanisms. The ability to learn and adapt in real-time enables applications in dynamic environments where conditions change frequently, such as autonomous systems, robotics, and adaptive signal processing.Expand Specific Solutions05 Integration of AI Accelerators in System-on-Chip Designs
Modern system-on-chip (SoC) designs increasingly incorporate dedicated AI accelerators alongside traditional processing elements. These integrated solutions combine neuromorphic or AI processing units with conventional CPUs, GPUs, memory controllers, and I/O interfaces on a single chip. The tight integration enables efficient data sharing between processing elements, reduces communication latency, and provides a complete solution for AI-enabled applications. These designs often include specialized memory architectures, such as in-memory computing or near-memory processing, to address the memory bottleneck in AI workloads.Expand Specific Solutions
Leading Organizations in Neuromorphic Chip Development
The neuromorphic chip and AI processor market is currently in a growth phase, characterized by increasing competition between established tech giants and specialized startups. The global market is expanding rapidly, projected to reach significant scale as AI applications proliferate across industries. Companies like Intel, IBM, and Samsung are leveraging their semiconductor expertise to develop advanced neuromorphic architectures, while specialized players such as Syntiant and Polyn Technology are focusing on ultra-low-power edge AI solutions. Academic institutions including Tsinghua University, KAIST, and Zhejiang University are contributing fundamental research that bridges theoretical neuroscience with practical chip design. The technology is maturing with varying approaches - IBM's TrueNorth and Intel's Loihi represent more established neuromorphic platforms, while startups are innovating with application-specific designs targeting emerging markets in IoT, wearables, and autonomous systems.
SYNTIANT CORP
Technical Solution: Syntiant has developed the Neural Decision Processor (NDP), a specialized AI chip architecture that bridges the gap between traditional AI processors and neuromorphic computing. The NDP is designed specifically for always-on applications at the edge, with an architecture optimized for deep learning inference in power-constrained environments. Syntiant's NDP100 and NDP200 series chips can process neural networks while consuming less than 1mW of power, enabling voice and sensor applications that were previously impossible on battery-powered devices. The company's technology implements a dataflow architecture that minimizes data movement, a key source of power consumption in AI processing. Syntiant's chips feature built-in memory for weights and activations, and their architecture allows for efficient processing of sparse neural networks. The latest generation NDP chips can handle multiple concurrent AI models and support various sensor inputs beyond audio, including motion, pressure, and image sensors, making them suitable for a wide range of edge AI applications.
Strengths: Ultra-low power consumption (sub-milliwatt operation); optimized for always-on edge applications; production-ready solution with commercial deployment in millions of devices. Weaknesses: More specialized for specific workloads (particularly audio processing) compared to general-purpose AI accelerators; limited to inference rather than training; smaller scale neural networks compared to cloud AI processors.
International Business Machines Corp.
Technical Solution: IBM has pioneered TrueNorth, a neuromorphic chip architecture that represents a radical departure from conventional von Neumann computing. TrueNorth contains 5.4 billion transistors organized into 4,096 neurosynaptic cores, with each core containing 256 neurons and 256×256 synapses, totaling approximately one million programmable neurons and 256 million configurable synapses. The chip operates on an asynchronous, event-driven paradigm that only consumes power when neurons fire, resulting in extremely low power consumption (70mW) while delivering 46 giga-synaptic operations per second per watt. IBM has demonstrated TrueNorth's capabilities in real-time video analysis, pattern recognition, and sensory processing tasks. More recently, IBM has been developing analog AI hardware that performs computations in memory, further advancing neuromorphic concepts by using phase-change memory (PCM) devices that can both store data and perform computations, mimicking synaptic behavior in the brain.
Strengths: Exceptional energy efficiency (orders of magnitude better than conventional processors); highly scalable architecture; proven performance in pattern recognition tasks. Weaknesses: Requires specialized programming approaches different from mainstream AI frameworks; limited commercial deployment beyond research applications; challenges in training complex models compared to conventional deep learning systems.
Key Innovations in Spiking Neural Networks and Hardware
Resistor circuit, artificial intelligence chip and method for manufacturing the same
PatentActiveUS20200394501A1
Innovation
- A resistor circuit is designed with a stack structure comprising alternately stacked resistive material layers and insulating layers, where unit resistors are electrically connected in series or parallel across different layers, with conductor elements forming connections between these layers to achieve varying resistances and effective resistance configurations.




Systems and Methods of Sparsity Exploiting
PatentInactiveUS20240095510A1
Innovation
- A neuromorphic integrated circuit with a multi-layered neural network in an analog multiplier array, where two-quadrant multipliers are wired to ground and draw negligible current when input signal or weight values are zero, promoting sparsity and minimizing power consumption, and a method to train the network to drive weight values toward zero using a training algorithm.
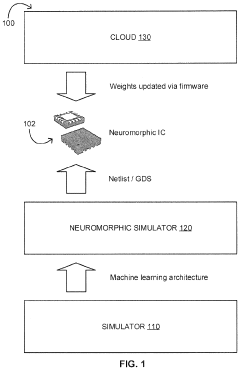
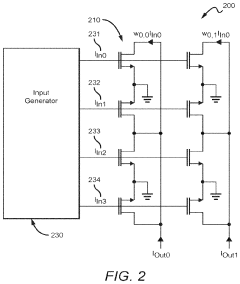
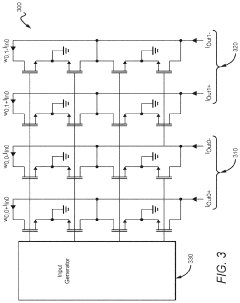
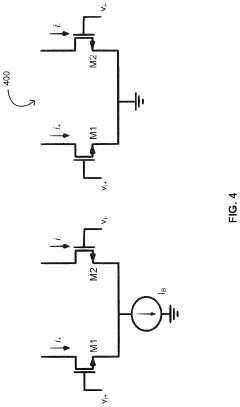
Energy Efficiency Comparison Between Computing Paradigms
The energy efficiency comparison between neuromorphic chips and traditional AI processors reveals fundamental differences in their computing approaches and power consumption profiles. Neuromorphic architectures, inspired by the human brain's neural networks, demonstrate significant advantages in energy efficiency for specific workloads, particularly those involving sparse, event-driven processing.
Traditional AI processors such as GPUs and TPUs operate on a synchronous computing model, requiring constant power regardless of computational load. These processors typically consume between 200-300 watts during intensive AI workloads. In contrast, neuromorphic chips like Intel's Loihi and IBM's TrueNorth operate asynchronously, activating components only when necessary, resulting in power consumption often below 100 milliwatts for comparable tasks.
Benchmark studies indicate that neuromorphic systems can achieve energy efficiency improvements of 100-1000x over conventional architectures for certain neural network applications. This efficiency stems from their event-driven processing paradigm, which eliminates the need for continuous clock-driven operations and reduces the energy wasted on unnecessary computations.
The energy advantage becomes particularly evident in edge computing scenarios where power constraints are critical. Neuromorphic chips can process sensory data streams with orders of magnitude less energy than conventional processors, enabling AI capabilities in battery-powered devices that would otherwise be impractical.
However, this efficiency comparison is highly workload-dependent. For dense matrix operations common in training large language models, traditional architectures often maintain performance advantages despite higher power consumption. Neuromorphic systems excel particularly in sparse, temporal pattern recognition tasks that align with their brain-inspired design.
Recent advancements in both paradigms have narrowed the gap somewhat. Modern AI processors increasingly incorporate specialized circuitry for neural network operations, while neuromorphic designs have improved their flexibility for handling diverse workloads. The SpiNNaker2 neuromorphic system, for instance, demonstrates a hybrid approach that maintains energy efficiency while supporting a broader range of computational models.
When considering total energy consumption across the AI lifecycle, the comparison must also account for training costs. While neuromorphic systems may operate efficiently during inference, their programming paradigms often require specialized approaches that can increase development energy overhead compared to the mature ecosystems surrounding traditional AI processors.
Traditional AI processors such as GPUs and TPUs operate on a synchronous computing model, requiring constant power regardless of computational load. These processors typically consume between 200-300 watts during intensive AI workloads. In contrast, neuromorphic chips like Intel's Loihi and IBM's TrueNorth operate asynchronously, activating components only when necessary, resulting in power consumption often below 100 milliwatts for comparable tasks.
Benchmark studies indicate that neuromorphic systems can achieve energy efficiency improvements of 100-1000x over conventional architectures for certain neural network applications. This efficiency stems from their event-driven processing paradigm, which eliminates the need for continuous clock-driven operations and reduces the energy wasted on unnecessary computations.
The energy advantage becomes particularly evident in edge computing scenarios where power constraints are critical. Neuromorphic chips can process sensory data streams with orders of magnitude less energy than conventional processors, enabling AI capabilities in battery-powered devices that would otherwise be impractical.
However, this efficiency comparison is highly workload-dependent. For dense matrix operations common in training large language models, traditional architectures often maintain performance advantages despite higher power consumption. Neuromorphic systems excel particularly in sparse, temporal pattern recognition tasks that align with their brain-inspired design.
Recent advancements in both paradigms have narrowed the gap somewhat. Modern AI processors increasingly incorporate specialized circuitry for neural network operations, while neuromorphic designs have improved their flexibility for handling diverse workloads. The SpiNNaker2 neuromorphic system, for instance, demonstrates a hybrid approach that maintains energy efficiency while supporting a broader range of computational models.
When considering total energy consumption across the AI lifecycle, the comparison must also account for training costs. While neuromorphic systems may operate efficiently during inference, their programming paradigms often require specialized approaches that can increase development energy overhead compared to the mature ecosystems surrounding traditional AI processors.
Standardization Challenges for Neuromorphic Systems
The standardization of neuromorphic systems presents a complex challenge in the rapidly evolving landscape of AI hardware. As neuromorphic chips and traditional AI processors continue to develop along parallel but distinct technological trajectories, the absence of unified standards creates significant barriers to widespread adoption and integration.
One primary challenge lies in the fundamental architectural differences between neuromorphic systems and conventional computing paradigms. Neuromorphic chips employ spike-based processing, event-driven computation, and distributed memory architectures that differ substantially from the deterministic, clock-driven operations of traditional processors. These differences necessitate entirely new benchmarking methodologies and performance metrics that can accurately capture the unique advantages of neuromorphic computing.
The fragmentation of neuromorphic hardware implementations further complicates standardization efforts. Various research groups and companies have developed proprietary neuromorphic architectures—including IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida—each with distinct design philosophies, programming models, and application interfaces. This diversity, while driving innovation, impedes the development of cross-platform software tools and programming frameworks.
Data representation standards present another critical challenge. Unlike conventional AI processors that operate on floating-point or integer values, neuromorphic systems process information through spikes and temporal coding schemes. The lack of standardized formats for converting traditional data into spike-based representations creates interoperability issues when integrating neuromorphic components into existing AI workflows.
Power efficiency metrics, a key selling point for neuromorphic technology, also lack standardization. Current energy consumption benchmarks designed for traditional processors fail to adequately capture the event-driven efficiency gains of neuromorphic systems, particularly in sparse data processing scenarios. This deficiency hampers fair comparisons between neuromorphic chips and conventional AI accelerators.
The emerging nature of neuromorphic applications further complicates standardization. While traditional AI processors have established benchmarks for tasks like image classification and natural language processing, neuromorphic systems excel in different domains such as continuous learning, anomaly detection, and ultra-low-power sensing applications. Developing standardized test suites that fairly evaluate performance across these diverse use cases remains challenging.
Industry collaboration through organizations like the IEEE Neuromorphic Computing Standards Working Group represents a promising path forward, but achieving consensus among academic researchers, hardware manufacturers, and software developers requires overcoming significant technical and commercial barriers. The establishment of common interfaces, programming abstractions, and evaluation methodologies will be essential for neuromorphic computing to transition from research laboratories to mainstream commercial applications.
One primary challenge lies in the fundamental architectural differences between neuromorphic systems and conventional computing paradigms. Neuromorphic chips employ spike-based processing, event-driven computation, and distributed memory architectures that differ substantially from the deterministic, clock-driven operations of traditional processors. These differences necessitate entirely new benchmarking methodologies and performance metrics that can accurately capture the unique advantages of neuromorphic computing.
The fragmentation of neuromorphic hardware implementations further complicates standardization efforts. Various research groups and companies have developed proprietary neuromorphic architectures—including IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida—each with distinct design philosophies, programming models, and application interfaces. This diversity, while driving innovation, impedes the development of cross-platform software tools and programming frameworks.
Data representation standards present another critical challenge. Unlike conventional AI processors that operate on floating-point or integer values, neuromorphic systems process information through spikes and temporal coding schemes. The lack of standardized formats for converting traditional data into spike-based representations creates interoperability issues when integrating neuromorphic components into existing AI workflows.
Power efficiency metrics, a key selling point for neuromorphic technology, also lack standardization. Current energy consumption benchmarks designed for traditional processors fail to adequately capture the event-driven efficiency gains of neuromorphic systems, particularly in sparse data processing scenarios. This deficiency hampers fair comparisons between neuromorphic chips and conventional AI accelerators.
The emerging nature of neuromorphic applications further complicates standardization. While traditional AI processors have established benchmarks for tasks like image classification and natural language processing, neuromorphic systems excel in different domains such as continuous learning, anomaly detection, and ultra-low-power sensing applications. Developing standardized test suites that fairly evaluate performance across these diverse use cases remains challenging.
Industry collaboration through organizations like the IEEE Neuromorphic Computing Standards Working Group represents a promising path forward, but achieving consensus among academic researchers, hardware manufacturers, and software developers requires overcoming significant technical and commercial barriers. The establishment of common interfaces, programming abstractions, and evaluation methodologies will be essential for neuromorphic computing to transition from research laboratories to mainstream commercial applications.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!