

Computational Screening Workflows For SAC Discovery
AUG 27, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
SAC Discovery Background and Objectives
Single-atom catalysts (SACs) have emerged as a revolutionary frontier in heterogeneous catalysis over the past decade. These catalysts, characterized by isolated metal atoms dispersed on support materials, offer exceptional atom efficiency and unique catalytic properties that bridge the gap between homogeneous and heterogeneous catalysis. The development of SACs represents a significant paradigm shift in catalyst design, moving from traditional nanoparticle-based systems to atomic-level precision engineering.
The evolution of SAC technology can be traced back to early theoretical predictions in the 1990s, followed by breakthrough experimental validations in the early 2000s. However, it was not until 2011 when Zhang and colleagues demonstrated the first practical single-atom Pt catalyst on FeOx support with remarkable CO oxidation activity that the field gained substantial momentum. Since then, research interest has grown exponentially, with applications expanding across numerous reaction types including hydrogenation, oxidation, electrocatalysis, and photocatalysis.
Despite these advances, the discovery and optimization of new SACs remain largely empirical and resource-intensive. Traditional experimental approaches involve time-consuming synthesis and characterization cycles, often yielding limited understanding of structure-property relationships. This inefficiency highlights the critical need for computational screening workflows that can accelerate the discovery process and provide deeper insights into SAC behavior.
The primary objective of computational screening for SAC discovery is to establish systematic, high-throughput virtual protocols that can rapidly evaluate thousands of potential metal-support combinations. These workflows aim to predict key properties such as metal-support binding energies, electronic structures, catalytic activity descriptors, and stability under reaction conditions. By leveraging density functional theory (DFT), machine learning algorithms, and multiscale modeling approaches, researchers seek to identify promising SAC candidates before experimental validation.
Additionally, computational screening workflows address several fundamental challenges in SAC research, including the identification of optimal anchoring sites, prediction of coordination environments, assessment of dynamic structural changes during reactions, and evaluation of deactivation mechanisms. The ultimate goal is to establish reliable computational design principles that can guide the rational development of next-generation SACs with tailored properties for specific applications.
As industrial applications of SACs continue to expand in energy conversion, environmental remediation, and fine chemical synthesis, the development of robust computational screening methodologies becomes increasingly vital for accelerating innovation and enabling more sustainable catalytic processes.
The evolution of SAC technology can be traced back to early theoretical predictions in the 1990s, followed by breakthrough experimental validations in the early 2000s. However, it was not until 2011 when Zhang and colleagues demonstrated the first practical single-atom Pt catalyst on FeOx support with remarkable CO oxidation activity that the field gained substantial momentum. Since then, research interest has grown exponentially, with applications expanding across numerous reaction types including hydrogenation, oxidation, electrocatalysis, and photocatalysis.
Despite these advances, the discovery and optimization of new SACs remain largely empirical and resource-intensive. Traditional experimental approaches involve time-consuming synthesis and characterization cycles, often yielding limited understanding of structure-property relationships. This inefficiency highlights the critical need for computational screening workflows that can accelerate the discovery process and provide deeper insights into SAC behavior.
The primary objective of computational screening for SAC discovery is to establish systematic, high-throughput virtual protocols that can rapidly evaluate thousands of potential metal-support combinations. These workflows aim to predict key properties such as metal-support binding energies, electronic structures, catalytic activity descriptors, and stability under reaction conditions. By leveraging density functional theory (DFT), machine learning algorithms, and multiscale modeling approaches, researchers seek to identify promising SAC candidates before experimental validation.
Additionally, computational screening workflows address several fundamental challenges in SAC research, including the identification of optimal anchoring sites, prediction of coordination environments, assessment of dynamic structural changes during reactions, and evaluation of deactivation mechanisms. The ultimate goal is to establish reliable computational design principles that can guide the rational development of next-generation SACs with tailored properties for specific applications.
As industrial applications of SACs continue to expand in energy conversion, environmental remediation, and fine chemical synthesis, the development of robust computational screening methodologies becomes increasingly vital for accelerating innovation and enabling more sustainable catalytic processes.
Market Analysis for Computational Screening Applications
The computational screening market for single-atom catalyst (SAC) discovery is experiencing robust growth, driven by increasing demands for more efficient and sustainable catalytic solutions across multiple industries. Current market valuations indicate that the global computational chemistry software market, which includes screening applications, exceeds $7 billion and is projected to grow at a compound annual growth rate of 10.3% through 2028.
The pharmaceutical sector represents the largest market segment, accounting for approximately 38% of computational screening applications. This dominance stems from the industry's continuous need for novel catalysts that can facilitate complex drug synthesis pathways with greater selectivity and reduced waste. Energy and petrochemical industries follow closely, comprising about 27% of the market, where computational screening tools are increasingly deployed to develop catalysts for cleaner fuel production and carbon capture technologies.
Materials science and chemical manufacturing sectors collectively represent 22% of the market share, with growing adoption rates as these industries seek to optimize production processes and develop advanced materials with specific properties. Academic and research institutions account for the remaining 13%, serving as innovation hubs that often pioneer new computational methodologies before industrial adoption.
Regionally, North America leads with 42% of the global market share, followed by Europe (28%) and Asia-Pacific (24%). The Asia-Pacific region, particularly China and South Korea, demonstrates the fastest growth rate at 14.2% annually, driven by substantial government investments in computational research infrastructure and catalysis technology.
Customer segmentation reveals three primary user groups: large corporations with dedicated computational departments (55% of market revenue), specialized research institutions (30%), and small to medium enterprises accessing these technologies through cloud-based software-as-a-service models (15%). This last segment is growing particularly rapidly at 18% annually as cloud computing reduces entry barriers.
The market is characterized by increasing demand for integrated solutions that combine quantum mechanical calculations, machine learning algorithms, and experimental validation workflows. End users consistently prioritize accuracy of predictions, computational efficiency, and seamless integration with existing research infrastructure as key purchasing factors.
Price sensitivity varies significantly across market segments, with academic institutions demonstrating high price sensitivity while industrial users focus more on return on investment through accelerated discovery timelines. The average annual expenditure on computational screening tools ranges from $50,000 for small research groups to several million dollars for multinational corporations with extensive catalyst development programs.
The pharmaceutical sector represents the largest market segment, accounting for approximately 38% of computational screening applications. This dominance stems from the industry's continuous need for novel catalysts that can facilitate complex drug synthesis pathways with greater selectivity and reduced waste. Energy and petrochemical industries follow closely, comprising about 27% of the market, where computational screening tools are increasingly deployed to develop catalysts for cleaner fuel production and carbon capture technologies.
Materials science and chemical manufacturing sectors collectively represent 22% of the market share, with growing adoption rates as these industries seek to optimize production processes and develop advanced materials with specific properties. Academic and research institutions account for the remaining 13%, serving as innovation hubs that often pioneer new computational methodologies before industrial adoption.
Regionally, North America leads with 42% of the global market share, followed by Europe (28%) and Asia-Pacific (24%). The Asia-Pacific region, particularly China and South Korea, demonstrates the fastest growth rate at 14.2% annually, driven by substantial government investments in computational research infrastructure and catalysis technology.
Customer segmentation reveals three primary user groups: large corporations with dedicated computational departments (55% of market revenue), specialized research institutions (30%), and small to medium enterprises accessing these technologies through cloud-based software-as-a-service models (15%). This last segment is growing particularly rapidly at 18% annually as cloud computing reduces entry barriers.
The market is characterized by increasing demand for integrated solutions that combine quantum mechanical calculations, machine learning algorithms, and experimental validation workflows. End users consistently prioritize accuracy of predictions, computational efficiency, and seamless integration with existing research infrastructure as key purchasing factors.
Price sensitivity varies significantly across market segments, with academic institutions demonstrating high price sensitivity while industrial users focus more on return on investment through accelerated discovery timelines. The average annual expenditure on computational screening tools ranges from $50,000 for small research groups to several million dollars for multinational corporations with extensive catalyst development programs.
Current Challenges in SAC Computational Screening
Despite significant advancements in computational screening for single-atom catalysts (SACs), several critical challenges continue to impede efficient discovery workflows. The accuracy-efficiency trade-off remains a fundamental obstacle, as high-fidelity quantum mechanical calculations like DFT demand substantial computational resources, limiting the breadth of screening campaigns. Meanwhile, more efficient methods such as machine learning models often sacrifice accuracy or require extensive training data that may not be available for novel SAC systems.
Descriptor selection presents another significant hurdle. Identifying appropriate descriptors that effectively capture the complex electronic interactions between single atoms and their support materials requires deep physical understanding. Current descriptors often fail to adequately represent the unique quantum mechanical phenomena occurring at single-atom active sites, particularly when considering different support materials and reaction environments.
Scale bridging between atomic-level simulations and practical catalyst performance remains problematic. Computational models struggle to connect fundamental properties calculated at the electronic structure level with macroscopic performance metrics like activity, selectivity, and stability under realistic operating conditions. This disconnect hampers the translation of computational predictions into experimental validation.
Data scarcity and quality issues further complicate screening efforts. Unlike bulk materials, experimental data for SACs is relatively limited and often inconsistent across different research groups. This shortage of reliable benchmark data hinders the development and validation of computational models, especially for machine learning approaches that require substantial training datasets.
Environmental effects pose additional complexity, as most computational screening approaches inadequately account for solvent interactions, pH effects, and dynamic changes under reaction conditions. These factors significantly influence SAC performance but are computationally expensive to model accurately within high-throughput workflows.
Stability prediction represents perhaps the most pressing challenge. Current computational methods struggle to reliably predict the long-term stability of SACs under reaction conditions, including potential sintering, poisoning, or leaching mechanisms. This limitation creates substantial risk in the development pipeline, as catalysts that appear promising in initial screening may fail during practical implementation.
Validation protocols also remain underdeveloped, with limited standardization in how computational predictions are experimentally verified. This creates uncertainty in assessing the true predictive power of computational screening workflows and complicates the feedback loop necessary for continuous improvement of computational methods.
Descriptor selection presents another significant hurdle. Identifying appropriate descriptors that effectively capture the complex electronic interactions between single atoms and their support materials requires deep physical understanding. Current descriptors often fail to adequately represent the unique quantum mechanical phenomena occurring at single-atom active sites, particularly when considering different support materials and reaction environments.
Scale bridging between atomic-level simulations and practical catalyst performance remains problematic. Computational models struggle to connect fundamental properties calculated at the electronic structure level with macroscopic performance metrics like activity, selectivity, and stability under realistic operating conditions. This disconnect hampers the translation of computational predictions into experimental validation.
Data scarcity and quality issues further complicate screening efforts. Unlike bulk materials, experimental data for SACs is relatively limited and often inconsistent across different research groups. This shortage of reliable benchmark data hinders the development and validation of computational models, especially for machine learning approaches that require substantial training datasets.
Environmental effects pose additional complexity, as most computational screening approaches inadequately account for solvent interactions, pH effects, and dynamic changes under reaction conditions. These factors significantly influence SAC performance but are computationally expensive to model accurately within high-throughput workflows.
Stability prediction represents perhaps the most pressing challenge. Current computational methods struggle to reliably predict the long-term stability of SACs under reaction conditions, including potential sintering, poisoning, or leaching mechanisms. This limitation creates substantial risk in the development pipeline, as catalysts that appear promising in initial screening may fail during practical implementation.
Validation protocols also remain underdeveloped, with limited standardization in how computational predictions are experimentally verified. This creates uncertainty in assessing the true predictive power of computational screening workflows and complicates the feedback loop necessary for continuous improvement of computational methods.
State-of-the-Art Computational Workflows
01 Machine learning-based screening optimization
Machine learning algorithms can significantly enhance computational screening workflows by automating the identification of patterns and relationships in large datasets. These algorithms can predict compound properties, optimize screening parameters, and prioritize candidates for further evaluation. By implementing machine learning techniques, screening efficiency can be improved through reduced computational costs and accelerated discovery of promising candidates.- Machine learning-based screening optimization: Machine learning algorithms can significantly enhance computational screening workflows by automating the identification of patterns and relationships in large datasets. These techniques can predict compound properties, optimize screening parameters, and prioritize candidates, thereby reducing the number of physical experiments required. Advanced ML models can adapt and improve over time, learning from previous screening results to increase efficiency in subsequent iterations.
- Parallel processing and distributed computing frameworks: Implementing parallel processing and distributed computing architectures allows for simultaneous execution of multiple screening tasks across networked resources. These frameworks divide computational workloads across multiple processors or computing nodes, significantly reducing the time required for large-scale virtual screening campaigns. Cloud-based solutions further enhance scalability by providing on-demand access to additional computational resources during intensive screening operations.
- Automated workflow management systems: Automated workflow management systems streamline computational screening by coordinating sequential and parallel tasks without manual intervention. These systems handle data transfer between different computational stages, manage resource allocation, and provide real-time monitoring of screening progress. They can automatically adjust parameters based on intermediate results and implement decision trees to optimize the screening pathway, significantly reducing idle time between computational steps.
- Data preprocessing and filtering techniques: Effective data preprocessing and filtering techniques improve screening efficiency by reducing the initial compound library to a more manageable size before applying computationally intensive methods. These techniques include structural filters, physicochemical property filters, and pharmacophore-based approaches that eliminate unsuitable candidates early in the workflow. By focusing computational resources on promising candidates, these methods significantly reduce the overall computational burden while maintaining screening quality.
- Integration of multiple screening methods and validation protocols: Combining multiple computational screening methods in a hierarchical or consensus approach improves both efficiency and accuracy. These integrated workflows typically begin with faster, lower-precision methods to eliminate obvious non-starters, then progressively apply more rigorous and computationally intensive techniques to promising candidates. Cross-validation protocols ensure reliability of results, while feedback loops allow refinement of screening parameters based on experimental validation data, continuously improving the screening process.
02 Parallel processing and distributed computing frameworks
Computational screening workflows can be optimized through parallel processing and distributed computing architectures. These frameworks allow for simultaneous execution of multiple screening tasks across networked systems, significantly reducing the time required for large-scale virtual screening campaigns. By distributing computational workloads efficiently, screening throughput can be maximized while maintaining accuracy and reliability.Expand Specific Solutions03 Energy-efficient computational screening methods
Energy-efficient algorithms and hardware configurations can be implemented to reduce power consumption during intensive computational screening processes. These methods include optimized resource allocation, dynamic voltage and frequency scaling, and workload consolidation techniques. By focusing on energy efficiency, screening workflows can be sustained for longer periods with reduced operational costs while maintaining high throughput.Expand Specific Solutions04 Automated workflow management systems
Automated workflow management systems can streamline computational screening processes by coordinating different stages of the screening pipeline. These systems handle task scheduling, data transfer, error recovery, and result analysis with minimal human intervention. By automating routine tasks and decision-making processes, screening efficiency can be significantly improved while reducing the potential for human error.Expand Specific Solutions05 Cloud-based screening platforms
Cloud-based platforms offer scalable resources for computational screening workflows, allowing researchers to access high-performance computing capabilities on demand. These platforms provide flexible infrastructure that can be rapidly scaled up or down based on screening requirements. By leveraging cloud resources, organizations can conduct large-scale screening campaigns without significant upfront investment in computing hardware, while also benefiting from collaborative features and centralized data management.Expand Specific Solutions
Leading Organizations in SAC Discovery Research
Computational Screening Workflows for Single-Atom Catalyst (SAC) discovery is currently in a growth phase, with the market expanding rapidly due to increasing demand for efficient catalysts in energy and chemical industries. The global market size is estimated to reach several billion dollars by 2025, driven by applications in petrochemicals and renewable energy. Technologically, the field is transitioning from early development to commercial application, with varying maturity levels across players. Leading companies like China Petroleum & Chemical Corp. and Schlumberger are investing heavily in computational screening platforms, while academic institutions such as Northwestern Polytechnical University and Harbin Institute of Technology are advancing fundamental research. Technology companies including Intel, Autodesk, and Cadence Design Systems are providing essential computational tools that accelerate the discovery process through AI and machine learning integration.
China Petroleum & Chemical Corp.
Technical Solution: China Petroleum & Chemical Corp. (Sinopec) has developed an advanced computational screening workflow for single-atom catalyst (SAC) discovery that integrates density functional theory (DFT) calculations with machine learning algorithms. Their approach employs high-throughput virtual screening to evaluate thousands of potential metal-support combinations, focusing on identifying optimal metal centers (Pt, Pd, Ru, etc.) anchored on various supports (carbon-based materials, metal oxides). The workflow incorporates descriptor-based models that correlate electronic properties with catalytic performance, enabling rapid identification of promising SAC candidates for petroleum refining applications. Sinopec's platform includes automated reaction pathway analysis to determine activation barriers and reaction energetics, allowing for mechanistic understanding of catalytic processes. Their computational infrastructure leverages GPU acceleration and parallel computing to handle complex quantum chemical calculations efficiently, reducing screening time from months to weeks.
Strengths: Direct industry application expertise in petroleum refining processes; extensive computational resources; ability to validate computational predictions with experimental facilities. Weaknesses: Potentially narrower focus on petroleum-related catalytic processes compared to academic institutions; proprietary nature may limit published methodological details.
Yanshan University
Technical Solution: Yanshan University has pioneered a multi-scale computational screening workflow for SAC discovery that combines quantum mechanical calculations with molecular dynamics simulations. Their approach focuses particularly on carbon-based supports (graphene, carbon nanotubes) doped with nitrogen and other heteroatoms for anchoring single metal atoms. The university's computational platform employs adaptive sampling techniques to efficiently explore the vast chemical space of potential SAC configurations. Their workflow incorporates machine learning models trained on DFT-calculated datasets to predict stability and catalytic activity of novel SAC structures, achieving up to 90% accuracy compared to direct DFT calculations. A distinctive feature of their approach is the integration of ab initio molecular dynamics to evaluate the dynamic behavior of SACs under realistic reaction conditions, including temperature effects and solvent interactions. The university has successfully applied this workflow to discover novel SACs for electrochemical CO2 reduction and nitrogen fixation applications.
Strengths: Strong focus on fundamental understanding of SAC anchoring mechanisms; expertise in carbon-based support materials; integration of dynamic effects in screening protocols. Weaknesses: More limited computational resources compared to large industrial players; potentially slower implementation pathway from discovery to practical applications.
Key Algorithms and Models for SAC Screening
sorbent
PatentWO2024023158A1
Innovation
- A solid sorbent with secondary amines covalently attached to a silica support, optimized through specific grafting and water ratios, allowing for high CO2 adsorption capacity, long-term thermo-chemical stability, and low regeneration heat, using temperature swing adsorption with CO2 purge for desorption.
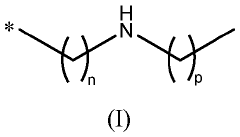
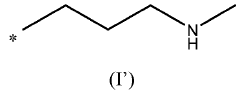
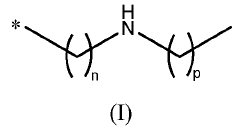
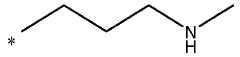
Sorbent material for co2 capture, uses thereof and methods for making same
PatentWO2025124872A1
Innovation
- A sorbent material composed of a mixture of 75-98 wt.% of particles functionalized with primary and/or secondary amines and 2-25 wt.% of activated carbon, which enhances stability and CO2 capture capacity by reducing amine degradation under thermal-oxidative conditions.


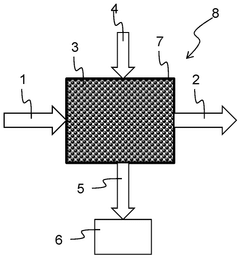
Validation Protocols and Benchmarking Standards
The validation of computational screening workflows for single-atom catalyst (SAC) discovery represents a critical challenge in the field. Establishing robust validation protocols and benchmarking standards is essential to ensure the reliability and reproducibility of computational predictions. Current validation approaches typically involve comparing computational results with experimental data, but this process lacks standardization across the research community.
Experimental validation of computationally predicted SAC properties requires careful consideration of multiple factors. Surface science techniques such as X-ray absorption spectroscopy (XAS), X-ray photoelectron spectroscopy (XPS), and scanning transmission electron microscopy (STEM) provide direct evidence of atomic dispersion and oxidation states. However, the correlation between these measurements and computational descriptors remains challenging due to differences in experimental conditions versus idealized computational models.
Benchmarking standards for SAC computational workflows should include reference datasets with well-characterized experimental properties. These datasets must cover diverse metal centers, support materials, and reaction conditions to ensure broad applicability. The development of community-accepted benchmark sets, similar to those established in molecular quantum chemistry (e.g., G2/G3 test sets), would significantly advance the field by providing common reference points for method validation.
Performance metrics for computational screening workflows must address both accuracy and computational efficiency. Key metrics include prediction accuracy for adsorption energies, activation barriers, and selectivity; computational cost scaling with system size; and transferability across different chemical environments. Statistical validation approaches such as cross-validation, uncertainty quantification, and sensitivity analysis should be systematically incorporated into screening protocols.
Round-robin testing among different research groups using identical input parameters represents another valuable validation approach. Such collaborative benchmarking efforts can identify method-dependent variations and establish confidence intervals for computational predictions. Several international initiatives have begun organizing such comparative studies, though more systematic efforts are needed.
The integration of machine learning validation techniques offers promising avenues for improving screening reliability. Techniques such as ensemble learning, Bayesian error estimation, and active learning can quantify prediction uncertainties and guide experimental validation efforts toward the most informative candidates. These approaches help bridge the gap between computational predictions and experimental reality.
Standardized reporting of computational details—including exchange-correlation functionals, basis sets, convergence criteria, and model system specifications—is essential for reproducibility. The development of automated validation workflows that incorporate these standards would accelerate progress in the field and enhance confidence in computational screening results for SAC discovery.
Experimental validation of computationally predicted SAC properties requires careful consideration of multiple factors. Surface science techniques such as X-ray absorption spectroscopy (XAS), X-ray photoelectron spectroscopy (XPS), and scanning transmission electron microscopy (STEM) provide direct evidence of atomic dispersion and oxidation states. However, the correlation between these measurements and computational descriptors remains challenging due to differences in experimental conditions versus idealized computational models.
Benchmarking standards for SAC computational workflows should include reference datasets with well-characterized experimental properties. These datasets must cover diverse metal centers, support materials, and reaction conditions to ensure broad applicability. The development of community-accepted benchmark sets, similar to those established in molecular quantum chemistry (e.g., G2/G3 test sets), would significantly advance the field by providing common reference points for method validation.
Performance metrics for computational screening workflows must address both accuracy and computational efficiency. Key metrics include prediction accuracy for adsorption energies, activation barriers, and selectivity; computational cost scaling with system size; and transferability across different chemical environments. Statistical validation approaches such as cross-validation, uncertainty quantification, and sensitivity analysis should be systematically incorporated into screening protocols.
Round-robin testing among different research groups using identical input parameters represents another valuable validation approach. Such collaborative benchmarking efforts can identify method-dependent variations and establish confidence intervals for computational predictions. Several international initiatives have begun organizing such comparative studies, though more systematic efforts are needed.
The integration of machine learning validation techniques offers promising avenues for improving screening reliability. Techniques such as ensemble learning, Bayesian error estimation, and active learning can quantify prediction uncertainties and guide experimental validation efforts toward the most informative candidates. These approaches help bridge the gap between computational predictions and experimental reality.
Standardized reporting of computational details—including exchange-correlation functionals, basis sets, convergence criteria, and model system specifications—is essential for reproducibility. The development of automated validation workflows that incorporate these standards would accelerate progress in the field and enhance confidence in computational screening results for SAC discovery.
Interdisciplinary Integration Opportunities
The integration of computational screening workflows for Single-Atom Catalyst (SAC) discovery presents significant opportunities for interdisciplinary collaboration across multiple scientific and engineering domains. Materials science, computational chemistry, data science, and catalysis engineering can converge to create more robust and efficient discovery platforms.
Machine learning and artificial intelligence methodologies from computer science can substantially enhance the predictive capabilities of SAC screening workflows. By incorporating advanced algorithms such as deep neural networks, random forests, and Bayesian optimization techniques, researchers can accelerate the identification of promising catalyst candidates while reducing computational costs. These AI-driven approaches enable more accurate property predictions and can uncover non-intuitive structure-property relationships that might be overlooked in traditional screening methods.
High-throughput experimentation techniques from chemical engineering provide valuable validation pathways for computationally identified SAC candidates. The integration of automated synthesis platforms with computational workflows creates a feedback loop that continuously improves prediction accuracy. This synergy between computational and experimental approaches represents a powerful paradigm for accelerating materials discovery beyond what either approach could achieve independently.
Quantum computing offers revolutionary potential for SAC discovery workflows. As quantum hardware continues to mature, quantum algorithms could tackle electronic structure calculations with unprecedented accuracy and efficiency. Hybrid quantum-classical approaches may provide near-term benefits for modeling complex catalyst-substrate interactions that remain challenging for conventional computational methods.
Environmental science and sustainability studies can inform screening criteria by incorporating lifecycle assessment metrics directly into computational workflows. This integration ensures that newly discovered SACs not only exhibit superior catalytic performance but also minimize environmental impacts throughout their production and utilization cycles.
Economic modeling and techno-economic analysis from business and engineering disciplines can be integrated to evaluate the commercial viability of computationally identified SACs. By incorporating manufacturing cost estimates, market demand projections, and regulatory considerations into screening workflows, researchers can prioritize candidates with the greatest potential for industrial implementation.
Cross-disciplinary education programs that train scientists in both computational and experimental techniques will be essential for maximizing these integration opportunities. Universities and research institutions should develop curriculum that bridges traditional disciplinary boundaries, preparing the next generation of researchers to work effectively at these interdisciplinary interfaces.
Machine learning and artificial intelligence methodologies from computer science can substantially enhance the predictive capabilities of SAC screening workflows. By incorporating advanced algorithms such as deep neural networks, random forests, and Bayesian optimization techniques, researchers can accelerate the identification of promising catalyst candidates while reducing computational costs. These AI-driven approaches enable more accurate property predictions and can uncover non-intuitive structure-property relationships that might be overlooked in traditional screening methods.
High-throughput experimentation techniques from chemical engineering provide valuable validation pathways for computationally identified SAC candidates. The integration of automated synthesis platforms with computational workflows creates a feedback loop that continuously improves prediction accuracy. This synergy between computational and experimental approaches represents a powerful paradigm for accelerating materials discovery beyond what either approach could achieve independently.
Quantum computing offers revolutionary potential for SAC discovery workflows. As quantum hardware continues to mature, quantum algorithms could tackle electronic structure calculations with unprecedented accuracy and efficiency. Hybrid quantum-classical approaches may provide near-term benefits for modeling complex catalyst-substrate interactions that remain challenging for conventional computational methods.
Environmental science and sustainability studies can inform screening criteria by incorporating lifecycle assessment metrics directly into computational workflows. This integration ensures that newly discovered SACs not only exhibit superior catalytic performance but also minimize environmental impacts throughout their production and utilization cycles.
Economic modeling and techno-economic analysis from business and engineering disciplines can be integrated to evaluate the commercial viability of computationally identified SACs. By incorporating manufacturing cost estimates, market demand projections, and regulatory considerations into screening workflows, researchers can prioritize candidates with the greatest potential for industrial implementation.
Cross-disciplinary education programs that train scientists in both computational and experimental techniques will be essential for maximizing these integration opportunities. Universities and research institutions should develop curriculum that bridges traditional disciplinary boundaries, preparing the next generation of researchers to work effectively at these interdisciplinary interfaces.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!