Designing Decision Engines For Self-Driving Labs: Bayesian Vs Reinforcement Learning
AUG 29, 202510 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Self-Driving Labs Decision Engine Background and Objectives
Self-Driving Labs (SDLs) represent a paradigm shift in scientific discovery, combining automation, robotics, and artificial intelligence to accelerate research processes. The concept emerged from the convergence of high-throughput experimentation and machine learning, with early implementations appearing in materials science and chemistry around 2015-2018. These autonomous laboratories aim to dramatically reduce the time and resources required for scientific discovery by removing human bottlenecks in the experimental cycle.
Decision engines serve as the cognitive core of SDLs, determining which experiments to perform next based on accumulated data. They embody the scientific method in algorithmic form, making decisions that maximize information gain while minimizing experimental costs. The evolution of these decision-making systems has progressed from simple grid searches to sophisticated machine learning approaches, with Bayesian optimization and reinforcement learning emerging as two dominant paradigms.
Bayesian approaches to experimental design have historical roots dating back to the 1950s but have gained renewed prominence with advances in computational capabilities. These methods excel at handling uncertainty and incorporating prior knowledge, making them particularly suitable for scientific discovery where data is often sparse and expensive to obtain. The Bayesian framework provides a principled way to balance exploration (investigating unknown regions) and exploitation (refining known promising areas).
Reinforcement learning (RL), meanwhile, represents a more recent addition to the SDL toolkit, drawing inspiration from how humans learn through trial and error. RL approaches frame the experimental design process as a sequential decision-making problem, where the algorithm learns to make better decisions through feedback from previous experiments. This approach has shown remarkable success in domains requiring long-term planning and complex decision sequences.
The technical objectives of this investigation are multifaceted: to comprehensively compare Bayesian and RL approaches for SDL decision engines across diverse scientific domains; to identify the strengths and limitations of each approach under varying experimental constraints; to explore hybrid architectures that leverage the complementary strengths of both paradigms; and to establish benchmarks and evaluation metrics that can guide future development in this rapidly evolving field.
As scientific challenges grow more complex and interdisciplinary, the sophistication of SDL decision engines must evolve accordingly. The ultimate goal is to develop decision systems capable of autonomous scientific reasoning that can navigate vast experimental spaces efficiently, adapt to changing objectives, and potentially discover solutions that human researchers might overlook due to cognitive biases or limited capacity for handling multidimensional data.
Decision engines serve as the cognitive core of SDLs, determining which experiments to perform next based on accumulated data. They embody the scientific method in algorithmic form, making decisions that maximize information gain while minimizing experimental costs. The evolution of these decision-making systems has progressed from simple grid searches to sophisticated machine learning approaches, with Bayesian optimization and reinforcement learning emerging as two dominant paradigms.
Bayesian approaches to experimental design have historical roots dating back to the 1950s but have gained renewed prominence with advances in computational capabilities. These methods excel at handling uncertainty and incorporating prior knowledge, making them particularly suitable for scientific discovery where data is often sparse and expensive to obtain. The Bayesian framework provides a principled way to balance exploration (investigating unknown regions) and exploitation (refining known promising areas).
Reinforcement learning (RL), meanwhile, represents a more recent addition to the SDL toolkit, drawing inspiration from how humans learn through trial and error. RL approaches frame the experimental design process as a sequential decision-making problem, where the algorithm learns to make better decisions through feedback from previous experiments. This approach has shown remarkable success in domains requiring long-term planning and complex decision sequences.
The technical objectives of this investigation are multifaceted: to comprehensively compare Bayesian and RL approaches for SDL decision engines across diverse scientific domains; to identify the strengths and limitations of each approach under varying experimental constraints; to explore hybrid architectures that leverage the complementary strengths of both paradigms; and to establish benchmarks and evaluation metrics that can guide future development in this rapidly evolving field.
As scientific challenges grow more complex and interdisciplinary, the sophistication of SDL decision engines must evolve accordingly. The ultimate goal is to develop decision systems capable of autonomous scientific reasoning that can navigate vast experimental spaces efficiently, adapt to changing objectives, and potentially discover solutions that human researchers might overlook due to cognitive biases or limited capacity for handling multidimensional data.
Market Analysis for Autonomous Scientific Discovery Systems
The autonomous scientific discovery systems market is experiencing rapid growth, driven by the convergence of artificial intelligence, robotics, and laboratory automation technologies. Current market estimates value this sector at approximately 2.3 billion USD in 2023, with projections indicating a compound annual growth rate of 28% through 2030. This acceleration is primarily fueled by increasing R&D expenditures across pharmaceutical, materials science, and chemical industries seeking to reduce discovery timelines and costs.
Demand for self-driving labs is particularly strong in pharmaceutical research, where drug discovery processes traditionally requiring 10-15 years can potentially be compressed to 3-5 years through autonomous systems. Materials science represents the second-largest market segment, with significant investments in developing novel materials for energy storage, semiconductors, and sustainable manufacturing applications.
Geographically, North America dominates the market with approximately 45% share, followed by Europe (30%) and Asia-Pacific (20%). The remaining 5% is distributed across other regions. The United States and China are engaged in strategic competition in this domain, with both countries significantly increasing government funding for autonomous research capabilities.
Key market drivers include escalating research costs, pressure to accelerate innovation cycles, reproducibility challenges in traditional research, and the exponential growth in potential experimental combinations that exceed human capacity to explore manually. The COVID-19 pandemic served as a catalyst, demonstrating the value of rapid scientific discovery systems during global health emergencies.
Customer segments include large pharmaceutical corporations, academic research institutions, government laboratories, contract research organizations, and an emerging group of specialized startups focused on specific scientific domains. Decision engines represent a critical component of these systems, with market analysis indicating growing demand for solutions that effectively balance exploration and exploitation in complex experimental spaces.
Market barriers include high initial investment costs, integration challenges with existing laboratory infrastructure, data standardization issues, and regulatory uncertainties regarding autonomous scientific systems. Additionally, there exists a significant skills gap, with demand for specialists who understand both domain science and advanced AI techniques far exceeding supply.
The market shows strong preference for modular, interoperable systems that can be customized for specific research domains rather than one-size-fits-all solutions. This trend favors platforms that can integrate different decision engine approaches, including both Bayesian optimization and reinforcement learning methodologies, depending on the specific research context.
Demand for self-driving labs is particularly strong in pharmaceutical research, where drug discovery processes traditionally requiring 10-15 years can potentially be compressed to 3-5 years through autonomous systems. Materials science represents the second-largest market segment, with significant investments in developing novel materials for energy storage, semiconductors, and sustainable manufacturing applications.
Geographically, North America dominates the market with approximately 45% share, followed by Europe (30%) and Asia-Pacific (20%). The remaining 5% is distributed across other regions. The United States and China are engaged in strategic competition in this domain, with both countries significantly increasing government funding for autonomous research capabilities.
Key market drivers include escalating research costs, pressure to accelerate innovation cycles, reproducibility challenges in traditional research, and the exponential growth in potential experimental combinations that exceed human capacity to explore manually. The COVID-19 pandemic served as a catalyst, demonstrating the value of rapid scientific discovery systems during global health emergencies.
Customer segments include large pharmaceutical corporations, academic research institutions, government laboratories, contract research organizations, and an emerging group of specialized startups focused on specific scientific domains. Decision engines represent a critical component of these systems, with market analysis indicating growing demand for solutions that effectively balance exploration and exploitation in complex experimental spaces.
Market barriers include high initial investment costs, integration challenges with existing laboratory infrastructure, data standardization issues, and regulatory uncertainties regarding autonomous scientific systems. Additionally, there exists a significant skills gap, with demand for specialists who understand both domain science and advanced AI techniques far exceeding supply.
The market shows strong preference for modular, interoperable systems that can be customized for specific research domains rather than one-size-fits-all solutions. This trend favors platforms that can integrate different decision engine approaches, including both Bayesian optimization and reinforcement learning methodologies, depending on the specific research context.
Current Challenges in Decision Engine Technologies
Despite significant advancements in decision engine technologies for self-driving labs, several critical challenges persist that impede optimal implementation and performance. The integration of Bayesian optimization and reinforcement learning approaches faces computational complexity barriers, particularly when dealing with high-dimensional experimental spaces. Current algorithms struggle to efficiently navigate these complex landscapes, often requiring prohibitive computational resources that limit real-time decision-making capabilities.
Data scarcity presents another formidable obstacle, as both Bayesian and reinforcement learning methods typically require substantial datasets to build accurate models. In scientific discovery domains, where experiments are costly and time-consuming, this creates a fundamental tension between the need for data-driven decisions and the practical limitations of data acquisition.
The exploration-exploitation dilemma remains inadequately resolved in existing decision engines. Bayesian approaches tend to be overly conservative in high-stakes experimental settings, while reinforcement learning methods may explore too aggressively, potentially wasting valuable resources on suboptimal experiments. Finding the appropriate balance for specific scientific discovery tasks continues to challenge researchers.
Transfer learning capabilities across different experimental domains are currently underdeveloped. Decision engines often perform well within narrowly defined problem spaces but fail to leverage knowledge from related experiments or domains. This limitation necessitates redundant learning processes when shifting between similar but distinct scientific inquiries.
Interpretability deficiencies plague many advanced decision algorithms, particularly deep reinforcement learning approaches. Scientists and lab operators require transparent decision rationales to build trust in automated systems and to integrate human expertise effectively. Current black-box models frequently fail to provide adequate explanations for their experimental recommendations.
Robustness issues emerge when decision engines encounter unexpected experimental outcomes or equipment failures. Most systems lack sophisticated error handling mechanisms and struggle to adapt their strategies when faced with noisy data or experimental anomalies.
Integration challenges with existing laboratory infrastructure create implementation barriers. Many decision engines are developed as standalone systems without standardized interfaces to laboratory automation equipment, requiring custom integration efforts that limit widespread adoption.
Human-AI collaboration frameworks remain primitive, with most systems designed either for full automation or human supervision rather than true collaborative intelligence. Developing decision engines that effectively combine human scientific intuition with algorithmic optimization represents a significant unmet need in the field.
Data scarcity presents another formidable obstacle, as both Bayesian and reinforcement learning methods typically require substantial datasets to build accurate models. In scientific discovery domains, where experiments are costly and time-consuming, this creates a fundamental tension between the need for data-driven decisions and the practical limitations of data acquisition.
The exploration-exploitation dilemma remains inadequately resolved in existing decision engines. Bayesian approaches tend to be overly conservative in high-stakes experimental settings, while reinforcement learning methods may explore too aggressively, potentially wasting valuable resources on suboptimal experiments. Finding the appropriate balance for specific scientific discovery tasks continues to challenge researchers.
Transfer learning capabilities across different experimental domains are currently underdeveloped. Decision engines often perform well within narrowly defined problem spaces but fail to leverage knowledge from related experiments or domains. This limitation necessitates redundant learning processes when shifting between similar but distinct scientific inquiries.
Interpretability deficiencies plague many advanced decision algorithms, particularly deep reinforcement learning approaches. Scientists and lab operators require transparent decision rationales to build trust in automated systems and to integrate human expertise effectively. Current black-box models frequently fail to provide adequate explanations for their experimental recommendations.
Robustness issues emerge when decision engines encounter unexpected experimental outcomes or equipment failures. Most systems lack sophisticated error handling mechanisms and struggle to adapt their strategies when faced with noisy data or experimental anomalies.
Integration challenges with existing laboratory infrastructure create implementation barriers. Many decision engines are developed as standalone systems without standardized interfaces to laboratory automation equipment, requiring custom integration efforts that limit widespread adoption.
Human-AI collaboration frameworks remain primitive, with most systems designed either for full automation or human supervision rather than true collaborative intelligence. Developing decision engines that effectively combine human scientific intuition with algorithmic optimization represents a significant unmet need in the field.
Comparative Analysis of Bayesian and RL Decision Frameworks
01 Machine learning-based decision engines
Decision engines can leverage machine learning algorithms to analyze large datasets and make predictions or recommendations. These systems can learn from historical data, identify patterns, and continuously improve their decision-making capabilities over time. Machine learning-based decision engines can significantly enhance efficiency by automating complex decision processes and adapting to changing conditions without requiring explicit reprogramming.- Machine learning algorithms for decision optimization: Decision engines can leverage machine learning algorithms to optimize decision-making processes. These systems analyze large datasets to identify patterns and make predictions, enabling more efficient and accurate decisions. By incorporating machine learning techniques, decision engines can continuously improve their performance through experience, adapting to new data and changing conditions. This approach enhances decision-making efficiency by automating complex analyses and reducing human bias in the decision process.
- Real-time data processing for decision engines: Real-time data processing capabilities enable decision engines to analyze information as it becomes available, allowing for immediate decision-making. These systems can process streaming data from multiple sources simultaneously, applying decision rules without significant delay. The ability to handle real-time data improves decision-making efficiency by reducing latency between data acquisition and action, which is particularly valuable in time-sensitive applications such as financial trading, network management, or emergency response systems.
- Distributed decision-making architectures: Distributed architectures for decision engines allow for parallel processing of decision tasks across multiple nodes or systems. This approach distributes computational load, enabling more efficient handling of complex decision problems. By leveraging distributed computing resources, these systems can process larger volumes of data and more intricate decision models while maintaining performance. Distributed decision-making architectures also provide redundancy and fault tolerance, ensuring continuous operation even when individual components fail.
- Automated rule-based decision systems: Rule-based decision systems automate decision-making by applying predefined rules to incoming data. These systems can efficiently process structured information according to business logic without human intervention. The rules can be updated and modified as needed to reflect changing requirements or conditions. By codifying decision criteria into explicit rules, these systems ensure consistency in decision-making while significantly increasing processing speed compared to manual methods. This approach is particularly effective for routine decisions with clear parameters.
- Decision optimization through predictive analytics: Decision engines incorporating predictive analytics can forecast outcomes of different decision paths, enabling selection of optimal choices. These systems analyze historical data to identify trends and relationships that inform future decisions. By simulating potential scenarios and their consequences, predictive analytics enhances decision-making efficiency by reducing uncertainty and focusing attention on the most promising options. This approach helps organizations allocate resources more effectively and respond proactively to anticipated changes in their operating environment.
02 Real-time data processing for decision-making
Decision engines that incorporate real-time data processing capabilities can significantly improve decision-making efficiency. These systems can analyze streaming data from multiple sources, apply predefined rules or algorithms, and generate immediate responses or recommendations. Real-time processing enables organizations to make timely decisions based on current conditions, reducing latency and improving operational efficiency.Expand Specific Solutions03 Rule-based decision automation systems
Rule-based decision engines apply predefined business rules to automate decision-making processes. These systems evaluate conditions against established criteria and execute corresponding actions based on the outcome. By codifying decision logic into explicit rules, organizations can ensure consistency in decision-making, reduce human error, and accelerate processing times for routine decisions, thereby improving overall efficiency.Expand Specific Solutions04 Distributed decision-making architectures
Distributed architectures for decision engines enable parallel processing of decision tasks across multiple nodes or systems. This approach allows for load balancing, fault tolerance, and scalability in decision-making processes. By distributing computational workload, these systems can handle larger volumes of decisions simultaneously, reducing bottlenecks and improving throughput for complex decision scenarios.Expand Specific Solutions05 Adaptive decision optimization techniques
Adaptive decision engines incorporate optimization techniques that continuously refine decision-making processes based on feedback and outcomes. These systems can adjust parameters, weights, or decision thresholds to maximize desired objectives such as accuracy, efficiency, or resource utilization. By implementing adaptive optimization, decision engines can evolve over time to address changing requirements and improve overall decision-making efficiency.Expand Specific Solutions
Leading Organizations in Self-Driving Lab Technologies
The self-driving lab decision engine landscape is currently in an early growth phase, with market size expanding rapidly as automation in scientific discovery gains traction. The technology maturity varies between Bayesian and reinforcement learning approaches, with companies demonstrating different specialization levels. IBM, Microsoft, and Huawei have established robust Bayesian optimization frameworks, while Toyota Research Institute and NEC are advancing reinforcement learning applications. Academic institutions like California Institute of Technology and Wuhan University of Technology are contributing fundamental research. Companies including Robert Bosch and ASML are implementing hybrid approaches for manufacturing applications. The competitive landscape remains fragmented with no dominant player, as both approaches continue to evolve with complementary strengths in exploration-exploitation balance and computational efficiency.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has developed Project Bonsai, a comprehensive decision engine platform that combines reinforcement learning with simulation-based training for industrial automation and self-driving labs. Their approach focuses on "machine teaching," where domain experts can impart their knowledge to guide reinforcement learning algorithms without requiring deep AI expertise. For self-driving labs, Microsoft's platform implements deep reinforcement learning techniques that can handle high-dimensional, continuous action spaces typical in experimental design scenarios[1]. Their system incorporates Bayesian optimization components for efficient exploration of parameter spaces, particularly useful in the initial phases of experimentation. Microsoft's decision engines feature a unique simulation-to-real transfer capability, allowing algorithms to be trained in simulated environments before deployment on physical laboratory equipment, significantly reducing development time and risk[2]. The platform includes specialized components for handling the inherent uncertainty in experimental outcomes, using probabilistic models to represent confidence levels in predictions and guide exploration strategies. Microsoft has demonstrated this technology in pharmaceutical applications, where their decision engines have accelerated drug formulation processes by intelligently navigating complex chemical spaces and prioritizing the most promising candidates for synthesis and testing[3].
Strengths: Microsoft's platform excels at making advanced AI techniques accessible to domain experts through their machine teaching approach, reducing the AI expertise barrier. Their simulation-to-real transfer capabilities allow for extensive algorithm training before deployment on expensive laboratory equipment. Weaknesses: The heavy reliance on simulation may introduce reality gaps when deployed in physical laboratories, potentially requiring significant calibration and adjustment.
International Business Machines Corp.
Technical Solution: IBM has developed a comprehensive decision engine framework for self-driving labs that integrates both Bayesian optimization and reinforcement learning approaches. Their platform, known as RXN for Chemistry, utilizes Bayesian optimization techniques for efficient exploration of chemical spaces with uncertainty quantification. The system employs Gaussian processes to model the relationship between molecular structures and their properties, enabling efficient navigation of vast chemical spaces with minimal experiments[1]. For more complex multi-step synthesis processes, IBM implements reinforcement learning algorithms that learn optimal reaction pathways through trial-and-error interactions with automated laboratory equipment. Their hybrid approach combines the sample efficiency of Bayesian methods with the sequential decision-making capabilities of reinforcement learning, particularly useful for multi-objective optimization scenarios in materials discovery[2]. IBM's decision engines incorporate active learning components that intelligently select the next experiments to maximize information gain, significantly reducing the number of experiments needed compared to traditional high-throughput approaches[3].
Strengths: IBM's hybrid approach leverages the sample efficiency of Bayesian methods for exploration while utilizing RL's sequential decision-making for complex multi-step processes. Their extensive cloud computing infrastructure enables handling computationally intensive modeling tasks. Weaknesses: The system requires significant computational resources and expertise to implement and maintain, potentially limiting accessibility for smaller research organizations.
Key Algorithms and Methodologies for Experimental Design
Action selection for reinforcement learning using influence diagrams
PatentInactiveUS20060224535A1
Innovation
- An online reinforcement learning system that employs the Thompson strategy to stochastically choose actions based on their optimality probability, updating parameters and structure using incremental supervised learning techniques, and providing a probability distribution for uncertainty management.
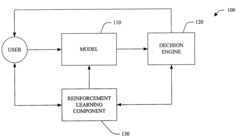
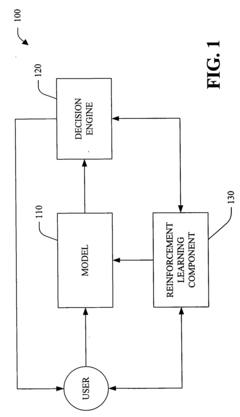
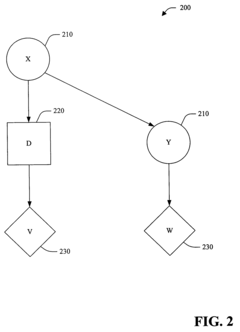
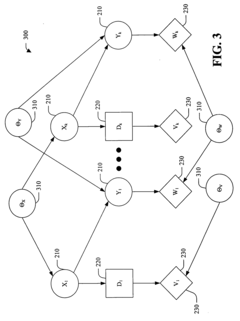
Method and system for optimizing reinforcement-learning-based autonomous driving according to user preferences
PatentWO2021080151A1
Innovation
- A deep reinforcement learning-based method that uses a neural network with fully-connected layers and gated recurrent units to learn autonomous driving parameters, allowing for simultaneous reinforcement learning across various environments and optimizing parameters using preference data through Bayesian neural networks and pairwise comparisons, enabling adaptation without retraining and with minimal preference data.
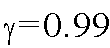
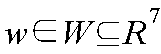
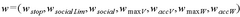
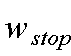
Hardware-Software Integration Considerations
The integration of decision engines with laboratory hardware represents a critical challenge in self-driving labs. When implementing Bayesian optimization or reinforcement learning approaches, the software architecture must accommodate real-time communication with diverse experimental equipment. This requires developing standardized interfaces that can translate algorithmic decisions into precise physical actions while handling the inherent latency between decision-making and experimental execution.
Hardware abstraction layers (HALs) serve as essential middleware components, providing a unified API that shields decision engines from the complexities of specific laboratory instruments. For Bayesian approaches, these interfaces must efficiently transmit uncertainty estimates and parameter spaces to experimental platforms. Reinforcement learning implementations demand additional considerations, as they typically require more frequent hardware interactions during training phases, potentially increasing wear on mechanical components.
Data acquisition systems present another integration challenge, as both decision methodologies rely on accurate, timely feedback. Bayesian systems typically require high-precision measurements to update posterior distributions effectively, while reinforcement learning algorithms may be more tolerant of noise but demand higher sampling rates. The hardware infrastructure must therefore include appropriate sensors, calibration protocols, and signal processing capabilities tailored to the selected decision engine's requirements.
Computational resource allocation represents a significant consideration in hardware-software integration. Bayesian optimization techniques often involve computationally intensive posterior updates that may benefit from dedicated processing units, while reinforcement learning models might require GPU acceleration for neural network training. The physical laboratory infrastructure must accommodate these computational demands without introducing bottlenecks in the experimental workflow.
Robustness to hardware failures constitutes a critical design consideration. Decision engines must incorporate fault detection mechanisms and graceful degradation protocols when laboratory equipment malfunctions. Bayesian approaches offer inherent advantages in this domain, as their probabilistic framework can incorporate equipment reliability metrics into experimental planning. Reinforcement learning systems typically require explicit training with simulated failures to develop similar robustness.
Scalability considerations must address how decision engines interact with multiple parallel experimental setups. Bayesian optimization naturally extends to batch experimentation through acquisition functions that balance exploration and exploitation across available resources. Reinforcement learning approaches may require specialized architectures, such as hierarchical or distributed agents, to effectively coordinate multiple experimental platforms while maintaining learning efficiency.
Hardware abstraction layers (HALs) serve as essential middleware components, providing a unified API that shields decision engines from the complexities of specific laboratory instruments. For Bayesian approaches, these interfaces must efficiently transmit uncertainty estimates and parameter spaces to experimental platforms. Reinforcement learning implementations demand additional considerations, as they typically require more frequent hardware interactions during training phases, potentially increasing wear on mechanical components.
Data acquisition systems present another integration challenge, as both decision methodologies rely on accurate, timely feedback. Bayesian systems typically require high-precision measurements to update posterior distributions effectively, while reinforcement learning algorithms may be more tolerant of noise but demand higher sampling rates. The hardware infrastructure must therefore include appropriate sensors, calibration protocols, and signal processing capabilities tailored to the selected decision engine's requirements.
Computational resource allocation represents a significant consideration in hardware-software integration. Bayesian optimization techniques often involve computationally intensive posterior updates that may benefit from dedicated processing units, while reinforcement learning models might require GPU acceleration for neural network training. The physical laboratory infrastructure must accommodate these computational demands without introducing bottlenecks in the experimental workflow.
Robustness to hardware failures constitutes a critical design consideration. Decision engines must incorporate fault detection mechanisms and graceful degradation protocols when laboratory equipment malfunctions. Bayesian approaches offer inherent advantages in this domain, as their probabilistic framework can incorporate equipment reliability metrics into experimental planning. Reinforcement learning systems typically require explicit training with simulated failures to develop similar robustness.
Scalability considerations must address how decision engines interact with multiple parallel experimental setups. Bayesian optimization naturally extends to batch experimentation through acquisition functions that balance exploration and exploitation across available resources. Reinforcement learning approaches may require specialized architectures, such as hierarchical or distributed agents, to effectively coordinate multiple experimental platforms while maintaining learning efficiency.
Data Management and Knowledge Transfer Strategies
Effective data management and knowledge transfer strategies are critical components in the development of decision engines for self-driving laboratories. The exponential growth of experimental data generated through automated experimentation platforms necessitates robust frameworks for data collection, storage, processing, and knowledge extraction. In self-driving labs utilizing either Bayesian optimization or reinforcement learning approaches, the quality of decision-making is directly proportional to the integrity and accessibility of experimental data.
For Bayesian optimization-based decision engines, structured databases with well-defined schemas are essential to maintain the probabilistic models that guide experimental design. These systems typically require comprehensive metadata tracking to establish clear correlations between experimental conditions and outcomes. Relational database management systems (RDBMS) with specialized extensions for handling uncertainty prove particularly valuable in this context, as they facilitate the continuous updating of prior distributions based on new experimental evidence.
Reinforcement learning approaches, conversely, benefit from more flexible data storage solutions that can accommodate diverse data types and varying levels of structure. NoSQL databases and distributed file systems have emerged as preferred options for RL-based self-driving labs, allowing for efficient storage and retrieval of high-dimensional state representations and complex reward signals. The ability to rapidly access historical trajectories of experiments enables more effective policy learning and adaptation.
Knowledge transfer between different experimental campaigns represents another crucial aspect of decision engine design. Transfer learning techniques allow decision engines to leverage insights gained from previous experiments, significantly reducing the exploration phase in new experimental domains. For Bayesian approaches, this often involves the transfer of prior distributions or kernel parameters, while reinforcement learning methods may transfer learned policies or value functions across related tasks.
Standardized data formats and communication protocols are increasingly important as self-driving labs become more collaborative and distributed. The development of domain-specific ontologies and semantic frameworks enables seamless knowledge sharing between different experimental platforms and decision engines. Open-source initiatives like the Materials Data Facility (MDF) and the Open Reaction Database (ORD) exemplify community efforts to establish shared data repositories that accelerate knowledge transfer in materials science and chemistry.
The integration of automated documentation systems with decision engines further enhances knowledge preservation and transfer. These systems capture not only experimental outcomes but also the reasoning behind experimental decisions, creating a valuable resource for future research and development efforts. Machine-readable experimental protocols and decision logs facilitate reproducibility and enable meta-analyses across multiple experimental campaigns.
For Bayesian optimization-based decision engines, structured databases with well-defined schemas are essential to maintain the probabilistic models that guide experimental design. These systems typically require comprehensive metadata tracking to establish clear correlations between experimental conditions and outcomes. Relational database management systems (RDBMS) with specialized extensions for handling uncertainty prove particularly valuable in this context, as they facilitate the continuous updating of prior distributions based on new experimental evidence.
Reinforcement learning approaches, conversely, benefit from more flexible data storage solutions that can accommodate diverse data types and varying levels of structure. NoSQL databases and distributed file systems have emerged as preferred options for RL-based self-driving labs, allowing for efficient storage and retrieval of high-dimensional state representations and complex reward signals. The ability to rapidly access historical trajectories of experiments enables more effective policy learning and adaptation.
Knowledge transfer between different experimental campaigns represents another crucial aspect of decision engine design. Transfer learning techniques allow decision engines to leverage insights gained from previous experiments, significantly reducing the exploration phase in new experimental domains. For Bayesian approaches, this often involves the transfer of prior distributions or kernel parameters, while reinforcement learning methods may transfer learned policies or value functions across related tasks.
Standardized data formats and communication protocols are increasingly important as self-driving labs become more collaborative and distributed. The development of domain-specific ontologies and semantic frameworks enables seamless knowledge sharing between different experimental platforms and decision engines. Open-source initiatives like the Materials Data Facility (MDF) and the Open Reaction Database (ORD) exemplify community efforts to establish shared data repositories that accelerate knowledge transfer in materials science and chemistry.
The integration of automated documentation systems with decision engines further enhances knowledge preservation and transfer. These systems capture not only experimental outcomes but also the reasoning behind experimental decisions, creating a valuable resource for future research and development efforts. Machine-readable experimental protocols and decision logs facilitate reproducibility and enable meta-analyses across multiple experimental campaigns.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!