

Quality Assurance And Versioning For MAP-Generated Datasets
AUG 29, 202510 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
MAP Dataset QA Background and Objectives
Machine-Assisted Programming (MAP) has emerged as a transformative approach in software development, leveraging AI capabilities to generate code and datasets that accelerate development cycles. As organizations increasingly adopt MAP technologies, the quality and versioning of MAP-generated datasets have become critical concerns that demand systematic attention. The evolution of MAP technologies has progressed from simple code completion tools to sophisticated systems capable of generating complex datasets for training, testing, and production environments.
The historical context of dataset quality assurance reveals a significant shift from manual inspection methods to automated validation frameworks. Traditional QA processes have proven inadequate for the volume, velocity, and variety of data produced through MAP systems. This technological evolution necessitates new approaches to ensure data integrity, consistency, and reliability across development lifecycles.
The primary objective of implementing robust QA and versioning systems for MAP-generated datasets is to establish trustworthy foundations for AI-driven development environments. These systems aim to detect anomalies, inconsistencies, and potential biases in generated datasets before they propagate through production systems. Additionally, they seek to maintain clear lineage and provenance information that enables traceability and reproducibility of results.
Current industry standards for dataset quality management remain fragmented, with organizations adopting varied approaches based on their specific needs and technological maturity. The absence of unified frameworks has created challenges in establishing benchmarks for dataset quality across different domains and applications. This fragmentation underscores the need for standardized methodologies that can be adapted across diverse technological contexts.
The technological trajectory indicates a convergence toward automated, continuous quality assurance pipelines integrated directly into MAP workflows. These pipelines incorporate statistical validation, semantic consistency checks, and bias detection algorithms that operate in real-time as datasets are generated. The evolution of these systems represents a critical advancement in ensuring that MAP technologies can be deployed responsibly in production environments.
Addressing the quality assurance challenges of MAP-generated datasets requires interdisciplinary approaches that combine expertise from data science, software engineering, and domain-specific knowledge. The integration of these perspectives enables comprehensive quality frameworks that can adapt to the evolving capabilities of MAP technologies while maintaining rigorous standards for dataset integrity and usability.
The historical context of dataset quality assurance reveals a significant shift from manual inspection methods to automated validation frameworks. Traditional QA processes have proven inadequate for the volume, velocity, and variety of data produced through MAP systems. This technological evolution necessitates new approaches to ensure data integrity, consistency, and reliability across development lifecycles.
The primary objective of implementing robust QA and versioning systems for MAP-generated datasets is to establish trustworthy foundations for AI-driven development environments. These systems aim to detect anomalies, inconsistencies, and potential biases in generated datasets before they propagate through production systems. Additionally, they seek to maintain clear lineage and provenance information that enables traceability and reproducibility of results.
Current industry standards for dataset quality management remain fragmented, with organizations adopting varied approaches based on their specific needs and technological maturity. The absence of unified frameworks has created challenges in establishing benchmarks for dataset quality across different domains and applications. This fragmentation underscores the need for standardized methodologies that can be adapted across diverse technological contexts.
The technological trajectory indicates a convergence toward automated, continuous quality assurance pipelines integrated directly into MAP workflows. These pipelines incorporate statistical validation, semantic consistency checks, and bias detection algorithms that operate in real-time as datasets are generated. The evolution of these systems represents a critical advancement in ensuring that MAP technologies can be deployed responsibly in production environments.
Addressing the quality assurance challenges of MAP-generated datasets requires interdisciplinary approaches that combine expertise from data science, software engineering, and domain-specific knowledge. The integration of these perspectives enables comprehensive quality frameworks that can adapt to the evolving capabilities of MAP technologies while maintaining rigorous standards for dataset integrity and usability.
Market Demand Analysis for High-Quality MAP Datasets
The market for high-quality MAP (Machine Assisted Processing) generated datasets is experiencing unprecedented growth, driven primarily by the expanding applications of artificial intelligence and machine learning across industries. Current market analysis indicates that organizations are increasingly recognizing the critical importance of dataset quality in determining AI model performance, with research showing that model accuracy can improve by up to 30% when trained on properly versioned and quality-assured datasets.
Financial services, healthcare, autonomous vehicles, and retail sectors demonstrate the strongest demand for high-quality MAP datasets. The financial industry requires meticulously validated datasets for fraud detection and algorithmic trading systems, where even minor data inconsistencies can result in significant financial losses. Healthcare organizations seek rigorously versioned datasets for patient diagnostics and treatment recommendation systems, where data quality directly impacts patient outcomes.
Market research reveals a significant gap between dataset supply and quality expectations. While the volume of available data continues to grow exponentially, organizations report persistent challenges in maintaining dataset quality, with 78% of enterprise AI projects citing data quality issues as a primary obstacle to successful implementation. This quality gap represents a substantial market opportunity for solutions that can ensure consistency, accuracy, and proper versioning of MAP-generated datasets.
The demand for specialized quality assurance tools for MAP datasets is projected to grow substantially as organizations move from experimental AI deployments to production environments. Enterprise customers increasingly require comprehensive audit trails, version control systems, and quality metrics specifically designed for large-scale datasets. This shift from basic data collection to sophisticated data governance represents a fundamental market evolution.
Regional analysis shows varying levels of market maturity. North American and European markets demonstrate more sophisticated requirements for dataset versioning and quality assurance, while Asia-Pacific regions show the fastest growth rate in adopting quality-focused data management practices. This regional variation suggests opportunities for tailored solutions addressing specific market needs.
Customer feedback indicates willingness to invest in quality assurance solutions that can demonstrate clear ROI through improved model performance, reduced development cycles, and minimized risks of model failures. Organizations increasingly view high-quality datasets not merely as technical requirements but as strategic assets that provide competitive advantages in their AI initiatives.
The subscription-based model for dataset quality assurance tools is gaining traction, with enterprises preferring ongoing quality monitoring rather than one-time verification processes. This shift reflects the understanding that dataset quality assurance is a continuous process rather than a discrete project milestone.
Financial services, healthcare, autonomous vehicles, and retail sectors demonstrate the strongest demand for high-quality MAP datasets. The financial industry requires meticulously validated datasets for fraud detection and algorithmic trading systems, where even minor data inconsistencies can result in significant financial losses. Healthcare organizations seek rigorously versioned datasets for patient diagnostics and treatment recommendation systems, where data quality directly impacts patient outcomes.
Market research reveals a significant gap between dataset supply and quality expectations. While the volume of available data continues to grow exponentially, organizations report persistent challenges in maintaining dataset quality, with 78% of enterprise AI projects citing data quality issues as a primary obstacle to successful implementation. This quality gap represents a substantial market opportunity for solutions that can ensure consistency, accuracy, and proper versioning of MAP-generated datasets.
The demand for specialized quality assurance tools for MAP datasets is projected to grow substantially as organizations move from experimental AI deployments to production environments. Enterprise customers increasingly require comprehensive audit trails, version control systems, and quality metrics specifically designed for large-scale datasets. This shift from basic data collection to sophisticated data governance represents a fundamental market evolution.
Regional analysis shows varying levels of market maturity. North American and European markets demonstrate more sophisticated requirements for dataset versioning and quality assurance, while Asia-Pacific regions show the fastest growth rate in adopting quality-focused data management practices. This regional variation suggests opportunities for tailored solutions addressing specific market needs.
Customer feedback indicates willingness to invest in quality assurance solutions that can demonstrate clear ROI through improved model performance, reduced development cycles, and minimized risks of model failures. Organizations increasingly view high-quality datasets not merely as technical requirements but as strategic assets that provide competitive advantages in their AI initiatives.
The subscription-based model for dataset quality assurance tools is gaining traction, with enterprises preferring ongoing quality monitoring rather than one-time verification processes. This shift reflects the understanding that dataset quality assurance is a continuous process rather than a discrete project milestone.
Technical Challenges in MAP Dataset Quality Assurance
The quality assurance of MAP-generated datasets presents significant technical challenges that must be addressed to ensure reliable and consistent data for downstream applications. The dynamic nature of these datasets, which are continuously updated through automated processes, creates complexity in maintaining data integrity throughout the generation pipeline.
Data validation mechanisms for MAP datasets face unique obstacles due to the heterogeneous nature of the source data. Traditional validation approaches often fail when confronted with the diverse data types, formats, and structures that comprise modern mapping datasets. This heterogeneity necessitates sophisticated validation frameworks capable of adapting to varying data characteristics while maintaining consistent quality standards.
Scalability emerges as a critical challenge as dataset sizes continue to grow exponentially. Quality assurance processes that function effectively for smaller datasets frequently encounter performance bottlenecks when applied to the massive volumes typical of comprehensive mapping applications. These bottlenecks can significantly delay release cycles and impede the timely delivery of updated map information.
Error propagation represents another substantial technical hurdle. In complex data processing pipelines, errors introduced at early stages can cascade through subsequent processing steps, becoming increasingly difficult to detect and correct. This propagation effect necessitates comprehensive monitoring systems capable of identifying anomalies at multiple processing stages.
Version control for MAP datasets introduces additional complexity beyond traditional software versioning approaches. The spatial and temporal dimensions of mapping data require specialized versioning strategies that can track changes across geographic regions while maintaining historical records of data evolution. Current versioning systems often struggle to efficiently manage the granular changes characteristic of map updates.
Automated anomaly detection presents technical challenges related to establishing appropriate baseline metrics for "normal" data patterns. The geographic variability inherent in mapping data means that anomalies may be context-dependent, requiring sophisticated machine learning approaches that can distinguish between genuine data errors and valid regional variations.
Integration testing across the entire MAP ecosystem poses significant challenges due to the interdependencies between dataset components. Changes in one data layer may have unforeseen consequences for dependent layers, necessitating comprehensive integration testing frameworks that can simulate real-world usage scenarios across the entire data stack.
Real-time quality monitoring introduces technical demands for systems that can perform continuous validation without impacting performance. The need to identify and address quality issues without disrupting ongoing data services requires carefully optimized monitoring architectures that balance thoroughness with computational efficiency.
Data validation mechanisms for MAP datasets face unique obstacles due to the heterogeneous nature of the source data. Traditional validation approaches often fail when confronted with the diverse data types, formats, and structures that comprise modern mapping datasets. This heterogeneity necessitates sophisticated validation frameworks capable of adapting to varying data characteristics while maintaining consistent quality standards.
Scalability emerges as a critical challenge as dataset sizes continue to grow exponentially. Quality assurance processes that function effectively for smaller datasets frequently encounter performance bottlenecks when applied to the massive volumes typical of comprehensive mapping applications. These bottlenecks can significantly delay release cycles and impede the timely delivery of updated map information.
Error propagation represents another substantial technical hurdle. In complex data processing pipelines, errors introduced at early stages can cascade through subsequent processing steps, becoming increasingly difficult to detect and correct. This propagation effect necessitates comprehensive monitoring systems capable of identifying anomalies at multiple processing stages.
Version control for MAP datasets introduces additional complexity beyond traditional software versioning approaches. The spatial and temporal dimensions of mapping data require specialized versioning strategies that can track changes across geographic regions while maintaining historical records of data evolution. Current versioning systems often struggle to efficiently manage the granular changes characteristic of map updates.
Automated anomaly detection presents technical challenges related to establishing appropriate baseline metrics for "normal" data patterns. The geographic variability inherent in mapping data means that anomalies may be context-dependent, requiring sophisticated machine learning approaches that can distinguish between genuine data errors and valid regional variations.
Integration testing across the entire MAP ecosystem poses significant challenges due to the interdependencies between dataset components. Changes in one data layer may have unforeseen consequences for dependent layers, necessitating comprehensive integration testing frameworks that can simulate real-world usage scenarios across the entire data stack.
Real-time quality monitoring introduces technical demands for systems that can perform continuous validation without impacting performance. The need to identify and address quality issues without disrupting ongoing data services requires carefully optimized monitoring architectures that balance thoroughness with computational efficiency.
Current QA Solutions for MAP-Generated Datasets
01 Quality assurance frameworks for MAP-generated datasets
Machine learning-assisted programming (MAP) datasets require robust quality assurance frameworks to ensure reliability. These frameworks include automated validation tools that check for data consistency, completeness, and accuracy. Quality metrics are established to evaluate dataset performance against predefined standards. Continuous monitoring systems detect anomalies and quality degradation over time, while feedback loops incorporate user input to improve dataset quality iteratively.- Quality assurance methodologies for MAP-generated datasets: Various methodologies are employed to ensure the quality of Machine-Assisted Processing (MAP) generated datasets. These include automated validation techniques, statistical analysis of data integrity, and implementation of quality control checkpoints throughout the dataset generation process. Quality assurance frameworks help identify anomalies, inconsistencies, and errors in the datasets, ensuring that the generated data meets predefined quality standards before being used in downstream applications.
- Version control systems for dataset management: Version control systems are crucial for managing MAP-generated datasets through their lifecycle. These systems track changes, maintain historical versions, and facilitate collaboration among team members working with the datasets. They provide mechanisms for branching, merging, and resolving conflicts in dataset versions, enabling teams to experiment with different dataset configurations while maintaining a reliable baseline. Advanced versioning approaches also include metadata tracking and change documentation for audit purposes.
- Automated validation and verification techniques: Automated validation and verification techniques are implemented to assess the reliability and accuracy of MAP-generated datasets. These techniques include consistency checks, boundary analysis, and comparison against reference datasets. Machine learning algorithms can be employed to detect patterns and anomalies that might indicate quality issues. Continuous validation pipelines ensure that datasets maintain their integrity throughout their lifecycle, with automated alerts for potential quality degradation.
- Dataset provenance and lineage tracking: Tracking the provenance and lineage of MAP-generated datasets involves documenting the complete history of data transformations, sources, and processing steps. This enables reproducibility and provides a clear audit trail for regulatory compliance. Lineage tracking systems capture metadata about dataset creation, modifications, and usage patterns, allowing organizations to understand how datasets evolve over time and facilitating root cause analysis when issues arise.
- Integration of dataset versioning with development workflows: Integrating dataset versioning with software development workflows ensures consistency between code and data throughout the development lifecycle. This integration enables synchronized updates of both code and datasets, facilitating continuous integration and deployment practices. Development environments can be configured to automatically use the appropriate dataset versions corresponding to specific code versions, reducing errors and improving reproducibility. This approach also supports feature branching and experimental development with specialized dataset variants.
02 Version control systems for dataset management
Specialized version control systems are essential for managing MAP-generated datasets throughout their lifecycle. These systems track changes between dataset versions, maintain comprehensive version histories, and enable rollback capabilities to previous states when needed. They also facilitate collaborative development by managing concurrent modifications from multiple contributors and implementing branching strategies for experimental dataset variations.Expand Specific Solutions03 Automated validation and verification techniques
Advanced validation techniques ensure MAP-generated datasets meet quality standards through automated processes. These include statistical analysis tools that identify outliers and anomalies, consistency checks that verify data integrity across the dataset, and reference comparisons against established benchmarks. Validation pipelines can be configured to run automatically when new versions are created, generating comprehensive reports on dataset quality.Expand Specific Solutions04 Dataset provenance and lineage tracking
Maintaining comprehensive provenance information for MAP-generated datasets ensures transparency and reproducibility. Lineage tracking systems record the complete history of dataset creation, including source data origins, transformation processes applied, and the specific algorithms or models used. This documentation enables users to understand how datasets were created, supports regulatory compliance, and facilitates troubleshooting when quality issues arise.Expand Specific Solutions05 Continuous integration and deployment for datasets
Applying continuous integration and deployment (CI/CD) principles to MAP-generated datasets ensures quality throughout the development lifecycle. Automated testing frameworks validate datasets against predefined criteria before release, while deployment pipelines manage the transition from development to production environments. This approach includes staged rollouts of dataset updates, monitoring systems that track performance in production, and automated rollback mechanisms when quality issues are detected.Expand Specific Solutions
Key Industry Players in MAP Dataset Management
The quality assurance and versioning for MAP-generated datasets market is currently in a growth phase, characterized by increasing demand for reliable geospatial data management solutions. The market size is expanding rapidly as autonomous driving technologies and location-based services proliferate, with projections indicating substantial growth over the next five years. Technologically, the field is approaching maturity with established players like HERE Global, TomTom International, and NVIDIA leading innovation in standardization and validation frameworks. Toyota, Mercedes-Benz, and BMW are driving automotive integration requirements, while technology companies such as Huawei and BlackBerry are enhancing security protocols. Emerging players like NavInfo and specialized firms including Aisin AW are developing niche solutions for quality control in high-definition mapping, creating a competitive landscape balanced between automotive incumbents and technology innovators.
HERE Global BV
Technical Solution: HERE Global BV has developed a comprehensive HD Live Map platform with advanced quality assurance and versioning systems for map-generated datasets. Their approach utilizes a "self-healing" map technology that automatically updates and maintains map accuracy through vehicle sensor data collection. The system employs a sophisticated versioning architecture that maintains multiple map versions simultaneously, allowing seamless transitions between updates while ensuring backward compatibility. HERE's QA framework incorporates automated validation pipelines that process over 28 terabytes of geographic data daily, applying more than 200 validation rules to ensure data integrity[1]. Their "Reality Index" technology creates a digital representation of the physical world by fusing data from multiple sources, including LiDAR, cameras, and IoT devices, with built-in versioning control that tracks changes over time and enables rollback capabilities when needed[2].
Strengths: Industry-leading automated validation systems that can process massive datasets efficiently; sophisticated version control allowing multiple concurrent map versions; extensive global coverage with high-precision mapping capabilities. Weaknesses: Heavy reliance on partner vehicle fleets for data collection may create dependencies; complex integration requirements for automotive clients; potential challenges in rapidly emerging markets with limited sensor coverage.
TomTom Global Content BV
Technical Solution: TomTom Global Content BV has implemented a robust MapMaker platform for quality assurance and versioning of map-generated datasets. Their system utilizes a distributed processing architecture that enables continuous integration of map updates while maintaining strict quality controls. TomTom's approach includes a "transactional map update" methodology where changes are processed as discrete transactions that can be individually verified, approved, and versioned. Their QA pipeline incorporates AI-powered anomaly detection that automatically identifies potential errors by comparing new map data against historical patterns and reference datasets. The company has developed a proprietary "Map Consistency Framework" that ensures logical consistency across different map elements and versions, with automated tests that verify road network connectivity, turn restrictions, and address point accuracy[3]. TomTom's versioning system supports both incremental updates and complete map replacements, with sophisticated delta-encoding to minimize data transfer requirements for updates.
Strengths: Advanced AI-powered validation tools that reduce manual QA efforts; efficient incremental update capabilities that minimize bandwidth requirements; strong focus on logical consistency across map elements. Weaknesses: Historically slower update cycles compared to some competitors; challenges in rapidly integrating crowdsourced data while maintaining quality standards; potential scalability limitations in handling extremely large datasets.
Core Technologies for MAP Dataset Validation
Method, apparatus, and system for providing quality assurance for map feature localization
PatentInactiveUS20200110817A1
Innovation
- A system that processes sensor data from multiple vehicles to aggregate features, cluster them, determine a consensus pattern, and automatically flag inaccurate data clusters, ensuring only accurate data is used for map updates, thereby reducing resource burden and increasing update frequency.
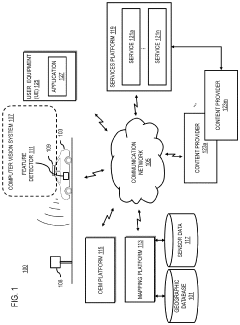
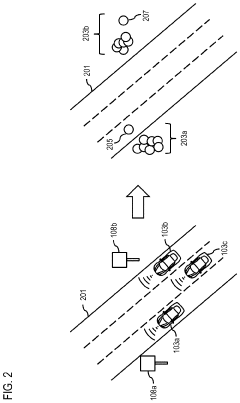
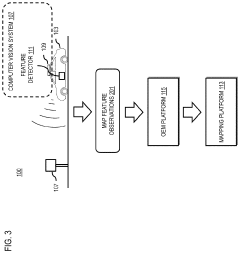
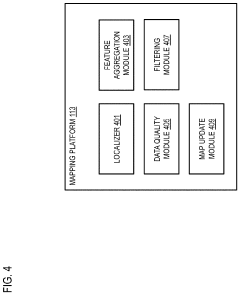
Layout-Aware Multimodal Pretraining for Multimodal Document Understanding
PatentActiveUS20230222285A1
Innovation
- A multimodal, layout-aware machine-learned document encoding model that partitions documents into blocks based on layout data, using both textual and image content, and employs a hierarchical framework with transformer models to generate document-level representations that consider spatial layout, style, and multimedia.
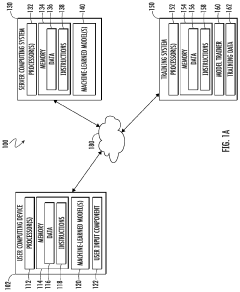
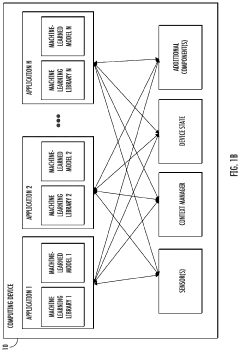
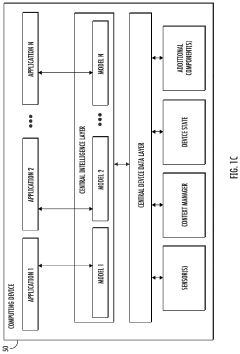
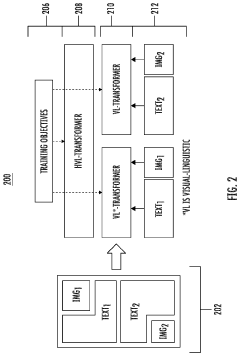
Data Governance and Compliance Framework
Effective data governance and compliance frameworks are essential for managing MAP-generated datasets, particularly as these datasets become increasingly integrated into critical business operations and decision-making processes. Organizations utilizing Machine-Assisted Processing (MAP) technologies must establish robust governance structures that address both quality assurance and versioning requirements while ensuring regulatory compliance across multiple jurisdictions.
The foundation of a comprehensive data governance framework for MAP-generated datasets begins with clear data ownership and stewardship policies. These policies must delineate responsibilities for data quality, integrity, and compliance throughout the entire data lifecycle. For MAP-generated datasets, this includes specific provisions for algorithmic transparency and explainability, ensuring that data transformations and processing steps are fully documented and traceable.
Regulatory compliance represents a significant challenge for organizations leveraging MAP technologies. The framework must incorporate mechanisms to address various regulations such as GDPR, CCPA, HIPAA, and industry-specific requirements. This includes implementing appropriate data protection measures, consent management systems, and privacy-by-design principles specifically tailored to the unique characteristics of MAP-generated datasets.
Version control systems within the governance framework must be designed to maintain comprehensive audit trails of all dataset modifications, transformations, and applications. These systems should capture metadata about processing algorithms, parameter settings, and quality metrics for each dataset version. Additionally, the framework should establish clear protocols for dataset deprecation, archiving, and retention that align with both business needs and regulatory requirements.
Data quality management processes constitute another critical component of the governance framework. These processes should define quality metrics specific to MAP-generated datasets, establish validation procedures, and implement continuous monitoring mechanisms. Organizations must develop standardized approaches for handling quality issues, including remediation workflows and escalation procedures when quality thresholds are not met.
Cross-functional governance committees with representation from data science, legal, IT, and business units should oversee the implementation and evolution of the framework. These committees are responsible for reviewing compliance reports, approving significant changes to governance policies, and ensuring alignment between data governance practices and organizational objectives. Regular compliance audits and assessments should be conducted to identify gaps and drive continuous improvement.
Training and awareness programs represent the final essential element of an effective governance framework. These programs ensure that all stakeholders understand their responsibilities regarding data quality, versioning, and compliance. For technical teams working directly with MAP-generated datasets, specialized training on quality assurance methodologies and version control best practices should be provided to maintain consistent standards across the organization.
The foundation of a comprehensive data governance framework for MAP-generated datasets begins with clear data ownership and stewardship policies. These policies must delineate responsibilities for data quality, integrity, and compliance throughout the entire data lifecycle. For MAP-generated datasets, this includes specific provisions for algorithmic transparency and explainability, ensuring that data transformations and processing steps are fully documented and traceable.
Regulatory compliance represents a significant challenge for organizations leveraging MAP technologies. The framework must incorporate mechanisms to address various regulations such as GDPR, CCPA, HIPAA, and industry-specific requirements. This includes implementing appropriate data protection measures, consent management systems, and privacy-by-design principles specifically tailored to the unique characteristics of MAP-generated datasets.
Version control systems within the governance framework must be designed to maintain comprehensive audit trails of all dataset modifications, transformations, and applications. These systems should capture metadata about processing algorithms, parameter settings, and quality metrics for each dataset version. Additionally, the framework should establish clear protocols for dataset deprecation, archiving, and retention that align with both business needs and regulatory requirements.
Data quality management processes constitute another critical component of the governance framework. These processes should define quality metrics specific to MAP-generated datasets, establish validation procedures, and implement continuous monitoring mechanisms. Organizations must develop standardized approaches for handling quality issues, including remediation workflows and escalation procedures when quality thresholds are not met.
Cross-functional governance committees with representation from data science, legal, IT, and business units should oversee the implementation and evolution of the framework. These committees are responsible for reviewing compliance reports, approving significant changes to governance policies, and ensuring alignment between data governance practices and organizational objectives. Regular compliance audits and assessments should be conducted to identify gaps and drive continuous improvement.
Training and awareness programs represent the final essential element of an effective governance framework. These programs ensure that all stakeholders understand their responsibilities regarding data quality, versioning, and compliance. For technical teams working directly with MAP-generated datasets, specialized training on quality assurance methodologies and version control best practices should be provided to maintain consistent standards across the organization.
Scalability Strategies for MAP Dataset Management
As MAP-generated datasets grow in volume and complexity, implementing effective scalability strategies becomes crucial for maintaining system performance and data integrity. Cloud-based distributed storage architectures offer significant advantages for MAP dataset management, enabling horizontal scaling across multiple servers to accommodate increasing data volumes without performance degradation.
Containerization technologies such as Docker and Kubernetes provide essential infrastructure for deploying MAP dataset management systems across diverse computing environments. These technologies facilitate consistent operation regardless of the underlying hardware, enabling seamless scaling of processing capabilities as dataset sizes increase.
Implementing data partitioning strategies represents another critical approach to scalability. By segmenting MAP datasets based on geographical regions, time periods, or data types, organizations can process and manage subsets independently, reducing computational overhead and improving query performance. This approach enables parallel processing workflows that can significantly accelerate data validation and quality assurance procedures.
Edge computing architectures offer compelling benefits for MAP dataset management, particularly for applications requiring real-time data processing. By distributing computation closer to data sources, organizations can reduce latency and bandwidth requirements while improving overall system responsiveness. This approach is particularly valuable for autonomous vehicle applications where rapid processing of MAP data is essential for safe operation.
Microservices architecture provides additional scalability advantages by decomposing MAP dataset management systems into discrete, independently deployable services. Each service can be scaled individually based on specific resource requirements, allowing organizations to allocate computing resources more efficiently. This approach also enhances system resilience by isolating failures to specific components rather than affecting the entire system.
Database sharding techniques offer another powerful strategy for managing large-scale MAP datasets. By distributing data across multiple database instances according to defined sharding keys, organizations can maintain query performance even as data volumes grow exponentially. This approach requires careful design of sharding strategies to ensure balanced data distribution and efficient query routing.
Implementing automated scaling policies based on resource utilization metrics enables dynamic adjustment of computing resources in response to changing workloads. This approach ensures optimal performance during peak processing periods while minimizing costs during periods of lower activity, making it particularly valuable for organizations with variable MAP dataset processing requirements.
Containerization technologies such as Docker and Kubernetes provide essential infrastructure for deploying MAP dataset management systems across diverse computing environments. These technologies facilitate consistent operation regardless of the underlying hardware, enabling seamless scaling of processing capabilities as dataset sizes increase.
Implementing data partitioning strategies represents another critical approach to scalability. By segmenting MAP datasets based on geographical regions, time periods, or data types, organizations can process and manage subsets independently, reducing computational overhead and improving query performance. This approach enables parallel processing workflows that can significantly accelerate data validation and quality assurance procedures.
Edge computing architectures offer compelling benefits for MAP dataset management, particularly for applications requiring real-time data processing. By distributing computation closer to data sources, organizations can reduce latency and bandwidth requirements while improving overall system responsiveness. This approach is particularly valuable for autonomous vehicle applications where rapid processing of MAP data is essential for safe operation.
Microservices architecture provides additional scalability advantages by decomposing MAP dataset management systems into discrete, independently deployable services. Each service can be scaled individually based on specific resource requirements, allowing organizations to allocate computing resources more efficiently. This approach also enhances system resilience by isolating failures to specific components rather than affecting the entire system.
Database sharding techniques offer another powerful strategy for managing large-scale MAP datasets. By distributing data across multiple database instances according to defined sharding keys, organizations can maintain query performance even as data volumes grow exponentially. This approach requires careful design of sharding strategies to ensure balanced data distribution and efficient query routing.
Implementing automated scaling policies based on resource utilization metrics enables dynamic adjustment of computing resources in response to changing workloads. This approach ensures optimal performance during peak processing periods while minimizing costs during periods of lower activity, making it particularly valuable for organizations with variable MAP dataset processing requirements.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!