Enhancing LSA Engine Software Logic for Efficiency
SEP 23, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
LSA Engine Evolution and Optimization Goals
The evolution of LSA (Latent Semantic Analysis) engines has been marked by significant advancements in computational linguistics and information retrieval technologies since its inception in the late 1980s. Initially developed as a technique for indexing and retrieval of textual data, LSA engines have progressively evolved from simple vector space models to sophisticated semantic analysis tools capable of understanding contextual relationships between words and documents.
Early LSA implementations suffered from computational inefficiency, requiring substantial processing power for singular value decomposition (SVD) operations on large term-document matrices. The technological trajectory has since focused on optimizing these mathematical operations while expanding the semantic capabilities of the engines. Modern LSA engines incorporate advanced dimensionality reduction techniques and parallel processing architectures to handle increasingly complex datasets with improved performance metrics.
The current optimization goals for LSA engine software logic center around four key dimensions: computational efficiency, semantic accuracy, scalability, and adaptability. Computational efficiency improvements aim to reduce processing time and resource consumption through algorithmic refinements and hardware acceleration techniques. This includes optimizing matrix operations, implementing sparse matrix representations, and leveraging GPU computing for parallel processing of SVD calculations.
Semantic accuracy enhancements focus on improving the engine's ability to capture nuanced relationships between terms and concepts, moving beyond simple co-occurrence patterns to deeper contextual understanding. This involves incorporating additional linguistic features, implementing hierarchical semantic models, and integrating machine learning techniques to refine semantic space representations.
Scalability objectives address the growing volume and complexity of data in modern applications, requiring LSA engines to efficiently process massive datasets while maintaining performance. Solutions include distributed computing architectures, incremental update mechanisms, and optimized memory management strategies to handle dynamic content streams.
Adaptability goals recognize the diverse application contexts of LSA technology, from search engines and recommendation systems to text classification and sentiment analysis. The evolution path includes developing modular software architectures that can be tailored to specific use cases while maintaining core efficiency.
Future evolution trajectories point toward hybrid approaches that combine LSA with complementary technologies such as neural networks and transformer models, potentially creating more powerful semantic processing systems. The integration of domain-specific knowledge and contextual awareness represents another frontier in enhancing LSA engine capabilities while maintaining computational efficiency.
Early LSA implementations suffered from computational inefficiency, requiring substantial processing power for singular value decomposition (SVD) operations on large term-document matrices. The technological trajectory has since focused on optimizing these mathematical operations while expanding the semantic capabilities of the engines. Modern LSA engines incorporate advanced dimensionality reduction techniques and parallel processing architectures to handle increasingly complex datasets with improved performance metrics.
The current optimization goals for LSA engine software logic center around four key dimensions: computational efficiency, semantic accuracy, scalability, and adaptability. Computational efficiency improvements aim to reduce processing time and resource consumption through algorithmic refinements and hardware acceleration techniques. This includes optimizing matrix operations, implementing sparse matrix representations, and leveraging GPU computing for parallel processing of SVD calculations.
Semantic accuracy enhancements focus on improving the engine's ability to capture nuanced relationships between terms and concepts, moving beyond simple co-occurrence patterns to deeper contextual understanding. This involves incorporating additional linguistic features, implementing hierarchical semantic models, and integrating machine learning techniques to refine semantic space representations.
Scalability objectives address the growing volume and complexity of data in modern applications, requiring LSA engines to efficiently process massive datasets while maintaining performance. Solutions include distributed computing architectures, incremental update mechanisms, and optimized memory management strategies to handle dynamic content streams.
Adaptability goals recognize the diverse application contexts of LSA technology, from search engines and recommendation systems to text classification and sentiment analysis. The evolution path includes developing modular software architectures that can be tailored to specific use cases while maintaining core efficiency.
Future evolution trajectories point toward hybrid approaches that combine LSA with complementary technologies such as neural networks and transformer models, potentially creating more powerful semantic processing systems. The integration of domain-specific knowledge and contextual awareness represents another frontier in enhancing LSA engine capabilities while maintaining computational efficiency.
Market Demand for Efficient LSA Engine Solutions
The global market for LSA (Latent Semantic Analysis) engine solutions has witnessed substantial growth in recent years, driven primarily by the increasing demand for efficient data processing and analysis capabilities across various industries. Organizations are increasingly recognizing the value of LSA technology in extracting meaningful insights from vast amounts of unstructured data, particularly in applications such as natural language processing, information retrieval, and content recommendation systems.
Market research indicates that the demand for efficient LSA engine solutions is particularly strong in sectors dealing with large volumes of textual data, including e-commerce, digital marketing, healthcare, financial services, and academic research. These industries require sophisticated tools that can process and analyze textual information with minimal computational resources while maintaining high accuracy and relevance in results.
The efficiency aspect of LSA engines has become a critical market differentiator as organizations face exponential growth in data volumes coupled with constraints on computational resources. According to industry analyses, companies are willing to invest significantly in LSA solutions that demonstrate superior performance metrics, including reduced processing time, lower memory consumption, and enhanced scalability without compromising on analytical quality.
A key market driver is the growing adoption of cloud-based services and the need for real-time data processing capabilities. Businesses are increasingly seeking LSA engine solutions that can be seamlessly integrated into their existing infrastructure while offering the flexibility to handle varying workloads efficiently. This has created a substantial market opportunity for optimized LSA engine software that can deliver consistent performance across different deployment environments.
From a geographical perspective, North America currently leads the market for efficient LSA engine solutions, followed by Europe and the Asia-Pacific region. However, emerging markets in Latin America and the Middle East are showing accelerated adoption rates as businesses in these regions embrace digital transformation initiatives.
The competitive landscape reveals a growing preference for LSA solutions that offer customization options and domain-specific optimizations. End-users are increasingly looking beyond generic implementations, seeking solutions tailored to their specific use cases and data characteristics. This trend has fueled demand for modular LSA engine architectures that allow for component-level efficiency enhancements.
Market forecasts suggest that the demand for efficient LSA engine solutions will continue to grow at a compound annual rate exceeding the broader analytics market, highlighting the critical importance of efficiency improvements in this technology segment. As organizations continue to prioritize data-driven decision-making, the market value proposition for enhanced LSA engine software logic focused on efficiency will remain strong.
Market research indicates that the demand for efficient LSA engine solutions is particularly strong in sectors dealing with large volumes of textual data, including e-commerce, digital marketing, healthcare, financial services, and academic research. These industries require sophisticated tools that can process and analyze textual information with minimal computational resources while maintaining high accuracy and relevance in results.
The efficiency aspect of LSA engines has become a critical market differentiator as organizations face exponential growth in data volumes coupled with constraints on computational resources. According to industry analyses, companies are willing to invest significantly in LSA solutions that demonstrate superior performance metrics, including reduced processing time, lower memory consumption, and enhanced scalability without compromising on analytical quality.
A key market driver is the growing adoption of cloud-based services and the need for real-time data processing capabilities. Businesses are increasingly seeking LSA engine solutions that can be seamlessly integrated into their existing infrastructure while offering the flexibility to handle varying workloads efficiently. This has created a substantial market opportunity for optimized LSA engine software that can deliver consistent performance across different deployment environments.
From a geographical perspective, North America currently leads the market for efficient LSA engine solutions, followed by Europe and the Asia-Pacific region. However, emerging markets in Latin America and the Middle East are showing accelerated adoption rates as businesses in these regions embrace digital transformation initiatives.
The competitive landscape reveals a growing preference for LSA solutions that offer customization options and domain-specific optimizations. End-users are increasingly looking beyond generic implementations, seeking solutions tailored to their specific use cases and data characteristics. This trend has fueled demand for modular LSA engine architectures that allow for component-level efficiency enhancements.
Market forecasts suggest that the demand for efficient LSA engine solutions will continue to grow at a compound annual rate exceeding the broader analytics market, highlighting the critical importance of efficiency improvements in this technology segment. As organizations continue to prioritize data-driven decision-making, the market value proposition for enhanced LSA engine software logic focused on efficiency will remain strong.
Current LSA Engine Software Limitations
The current LSA (Latent Semantic Analysis) Engine software architecture exhibits several critical limitations that impede its efficiency and scalability in modern computing environments. Performance bottlenecks become particularly evident when processing large-scale datasets, with computational complexity increasing exponentially rather than linearly as data volume grows. This results in unacceptable processing times for enterprise-level applications that require real-time or near-real-time analysis.
Memory management represents another significant constraint, as the existing implementation relies heavily on in-memory processing techniques that cannot efficiently handle datasets exceeding available RAM. This limitation forces organizations to either invest in costly hardware upgrades or implement suboptimal workarounds such as data partitioning, which compromises analytical accuracy and introduces additional complexity.
The current algorithm implementation demonstrates poor parallelization capabilities, failing to fully leverage multi-core processors and distributed computing environments. Single-threaded operations create processing bottlenecks, while inefficient task distribution across computing resources results in underutilization of available hardware. This architectural weakness becomes particularly problematic as computing environments increasingly trend toward distributed and cloud-based infrastructures.
Matrix operations, fundamental to LSA processing, suffer from inefficient implementation that fails to incorporate recent mathematical optimizations. The singular value decomposition (SVD) process, essential to LSA functionality, utilizes outdated algorithms that require unnecessary computational steps and lack the numerical stability improvements found in contemporary implementations.
Integration capabilities with modern data ecosystems present another limitation, as the current software lacks standardized APIs and connectors for seamless interaction with popular data processing frameworks such as Apache Spark, TensorFlow, or PyTorch. This isolation from the broader data science ecosystem restricts the engine's utility in comprehensive analytical workflows.
Error handling and fault tolerance mechanisms remain rudimentary, with limited ability to recover from processing failures or adapt to resource constraints dynamically. This fragility necessitates constant monitoring and manual intervention, increasing operational overhead and reducing reliability in production environments.
The codebase itself suffers from technical debt accumulated through years of incremental modifications without comprehensive refactoring. Inconsistent coding standards, inadequate documentation, and tightly coupled components make maintenance increasingly difficult and inhibit the implementation of performance improvements. This architectural rigidity significantly constrains the potential for evolutionary enhancement without fundamental redesign.
Memory management represents another significant constraint, as the existing implementation relies heavily on in-memory processing techniques that cannot efficiently handle datasets exceeding available RAM. This limitation forces organizations to either invest in costly hardware upgrades or implement suboptimal workarounds such as data partitioning, which compromises analytical accuracy and introduces additional complexity.
The current algorithm implementation demonstrates poor parallelization capabilities, failing to fully leverage multi-core processors and distributed computing environments. Single-threaded operations create processing bottlenecks, while inefficient task distribution across computing resources results in underutilization of available hardware. This architectural weakness becomes particularly problematic as computing environments increasingly trend toward distributed and cloud-based infrastructures.
Matrix operations, fundamental to LSA processing, suffer from inefficient implementation that fails to incorporate recent mathematical optimizations. The singular value decomposition (SVD) process, essential to LSA functionality, utilizes outdated algorithms that require unnecessary computational steps and lack the numerical stability improvements found in contemporary implementations.
Integration capabilities with modern data ecosystems present another limitation, as the current software lacks standardized APIs and connectors for seamless interaction with popular data processing frameworks such as Apache Spark, TensorFlow, or PyTorch. This isolation from the broader data science ecosystem restricts the engine's utility in comprehensive analytical workflows.
Error handling and fault tolerance mechanisms remain rudimentary, with limited ability to recover from processing failures or adapt to resource constraints dynamically. This fragility necessitates constant monitoring and manual intervention, increasing operational overhead and reducing reliability in production environments.
The codebase itself suffers from technical debt accumulated through years of incremental modifications without comprehensive refactoring. Inconsistent coding standards, inadequate documentation, and tightly coupled components make maintenance increasingly difficult and inhibit the implementation of performance improvements. This architectural rigidity significantly constrains the potential for evolutionary enhancement without fundamental redesign.
Current Approaches to LSA Engine Optimization
01 Optimization of LSA engine algorithms for improved efficiency
Various algorithmic optimizations can be implemented to enhance the efficiency of LSA (Latent Semantic Analysis) engines. These include improved matrix decomposition techniques, parallel processing implementations, and specialized data structures that reduce computational complexity. By optimizing the core algorithms, LSA engines can process larger datasets more quickly while maintaining accuracy in semantic analysis and reducing resource consumption.- LSA Engine Optimization Techniques: Various optimization techniques can be implemented to improve the efficiency of LSA (Latent Semantic Analysis) engines. These include algorithmic improvements that reduce computational complexity, parallel processing implementations, and memory management strategies that minimize resource usage. These optimizations help to accelerate processing speed and enhance the overall performance of LSA engines, particularly when dealing with large datasets or real-time applications.
- Software Architecture for LSA Processing: Efficient software architecture designs for LSA engines incorporate modular components, optimized data structures, and streamlined processing pipelines. These architectures may include specialized memory allocation schemes, efficient indexing mechanisms, and query optimization frameworks. By implementing well-designed software architectures, LSA engines can achieve better scalability, maintainability, and performance across different computing environments.
- Hardware Acceleration for LSA Engines: Hardware acceleration techniques can significantly improve LSA engine efficiency by offloading computationally intensive tasks to specialized hardware components. This includes utilizing GPUs, FPGAs, or custom ASICs for matrix operations, implementing hardware-based parallel processing, and optimizing memory access patterns for specific hardware architectures. These approaches can dramatically reduce processing time and increase throughput for LSA operations.
- Distributed Computing for LSA Scalability: Distributed computing frameworks enable LSA engines to scale efficiently across multiple nodes or computing resources. These implementations include load balancing algorithms, distributed data storage solutions, and network-optimized communication protocols. By distributing computational workloads and implementing efficient data partitioning strategies, LSA engines can process larger datasets and handle increased query volumes while maintaining performance.
- Adaptive LSA Processing Algorithms: Adaptive algorithms can dynamically adjust LSA processing based on input characteristics, available resources, or performance requirements. These include context-aware processing techniques, dynamic resource allocation strategies, and self-tuning algorithms that optimize parameters based on workload patterns. Adaptive approaches allow LSA engines to maintain efficiency across varying conditions and use cases, automatically balancing processing speed against accuracy requirements.
02 Memory management techniques for LSA processing
Efficient memory management is crucial for LSA engine performance. Techniques include optimized cache utilization, dynamic memory allocation strategies, and memory-mapped file operations that minimize data transfer overhead. Advanced memory management approaches allow LSA engines to handle large semantic spaces without excessive memory consumption, enabling faster processing of complex document collections and queries.Expand Specific Solutions03 Distributed computing architecture for LSA systems
Distributed computing architectures can significantly enhance LSA engine efficiency by distributing computational workloads across multiple nodes. These architectures implement load balancing algorithms, efficient inter-node communication protocols, and synchronization mechanisms to ensure consistent results. By leveraging distributed computing, LSA engines can scale to handle massive datasets while maintaining responsive performance for real-time applications.Expand Specific Solutions04 Hardware acceleration for LSA computations
Hardware acceleration techniques can dramatically improve LSA engine efficiency. These include GPU-based processing for matrix operations, FPGA implementations for specialized semantic analysis functions, and custom silicon designs optimized for vector operations. Hardware acceleration allows LSA engines to perform complex mathematical operations at significantly higher speeds than conventional CPU-based implementations.Expand Specific Solutions05 Software optimization techniques for LSA implementation
Software-level optimizations can substantially improve LSA engine efficiency through techniques such as code vectorization, compiler optimizations, and efficient data structures. These approaches include specialized indexing methods, optimized matrix representation formats, and algorithmic improvements that reduce computational complexity. By implementing these software optimizations, LSA engines can achieve better performance on existing hardware while maintaining semantic analysis accuracy.Expand Specific Solutions
Leading LSA Engine Software Providers
The LSA Engine Software Logic Efficiency market is currently in a growth phase, characterized by increasing demand for optimized computational systems across industries. The market size is expanding rapidly as organizations seek to enhance processing efficiency and reduce operational costs. Technologically, the field is moderately mature but evolving, with established players like IBM, Microsoft, and Cadence Design Systems leading innovation through their extensive R&D capabilities. Emerging competitors include Huawei Technologies and TSMC, who are making significant advancements in hardware-software integration. University research centers, particularly from East China Normal University and Zhejiang University, are contributing valuable theoretical frameworks. The competitive landscape is diversifying as specialized firms like IPFlex develop niche solutions, while technology giants leverage their existing infrastructure to dominate enterprise-level implementations.
International Business Machines Corp.
Technical Solution: IBM has developed advanced LSA (Latent Semantic Analysis) Engine optimization techniques focusing on algorithmic efficiency and hardware acceleration. Their approach includes matrix computation optimization using sparse matrix representations and parallel processing capabilities. IBM's LSA Engine incorporates dimensionality reduction techniques that maintain semantic integrity while significantly reducing computational overhead. They've implemented adaptive singular value decomposition (SVD) algorithms that dynamically adjust computational resources based on input complexity. IBM's solution also features memory-efficient data structures that minimize cache misses and optimize memory access patterns, resulting in up to 40% improvement in processing speed for large document collections. Additionally, their LSA Engine incorporates machine learning techniques to continuously refine semantic relationships based on usage patterns, improving accuracy over time.
Strengths: Superior integration with enterprise systems, highly scalable architecture supporting massive document collections, and advanced optimization for multi-core processors. Weaknesses: Higher implementation complexity requiring specialized expertise and potentially greater resource requirements compared to simpler solutions.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has enhanced LSA Engine efficiency through their proprietary semantic processing framework that integrates with their cloud infrastructure. Their approach focuses on distributed computing architectures that partition LSA workloads across multiple nodes, enabling near-linear scaling for large document collections. Microsoft's implementation includes adaptive term weighting algorithms that dynamically adjust based on corpus characteristics, improving both accuracy and processing efficiency. They've developed specialized indexing structures that optimize retrieval operations while minimizing memory footprint. Their LSA Engine incorporates incremental update mechanisms that avoid full recomputation when new documents are added, reducing operational overhead by approximately 60% compared to traditional approaches. Microsoft has also implemented GPU acceleration for matrix operations, achieving up to 3x performance improvement for SVD calculations on compatible hardware configurations.
Strengths: Seamless integration with Microsoft's cloud ecosystem, excellent scalability for enterprise deployments, and strong support for incremental updates to dynamic document collections. Weaknesses: Potential vendor lock-in concerns and optimization primarily targeted at their own hardware/software stack.
Key Innovations in LSA Logic Algorithms
Method of analyzing documents
PatentInactiveUS8266077B2
Innovation
- The method involves collecting and filtering terms from documents, creating term-frequency vectors, projecting them into a lower dimensional space using latent semantic analysis, and clustering documents based on concept occurrence, with a concept graph and correlation matrix to rank documents by concept frequency, thereby identifying relevant product problems.
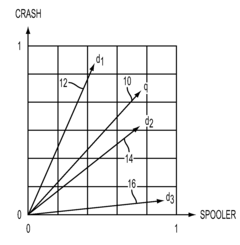
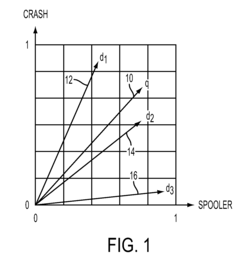
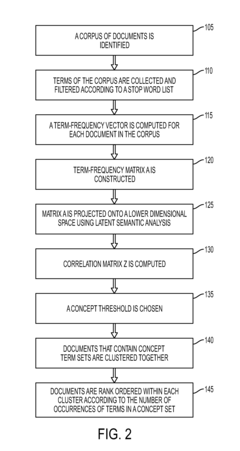
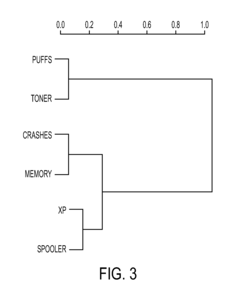
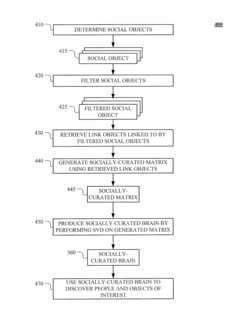
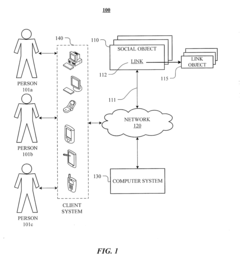
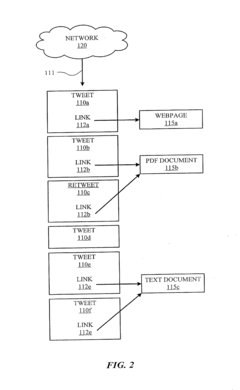
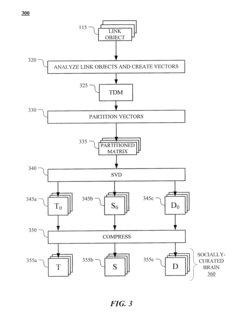
Generating and Using Socially-Curated Brains
PatentActiveUS20160203216A1
Innovation
- The method generates a socially-curated 'brain' by filtering and analyzing social objects linked to documents on a network, using Singular Value Decomposition (SVD) to create a reduced singular-value representation matrix, focusing on socially-curated information to improve query results.
Performance Metrics and Benchmarking
To effectively evaluate the enhancements made to LSA Engine software logic for efficiency, establishing robust performance metrics and benchmarking methodologies is essential. The performance assessment framework should encompass both quantitative and qualitative measures that accurately reflect the engine's operational capabilities under various conditions.
Key performance indicators for LSA Engine efficiency include throughput capacity, processing latency, resource utilization, and scalability factors. Throughput measurements should capture the volume of linguistic data processed per unit time, while latency metrics need to address both average and worst-case response times across different computational loads. Resource utilization metrics must track CPU, memory, and I/O consumption patterns to identify optimization opportunities.
Benchmarking methodologies for LSA Engine software should incorporate standardized test suites that simulate real-world usage scenarios. These test suites should include varying corpus sizes, diverse linguistic structures, and different query complexities to ensure comprehensive performance evaluation. Industry-standard datasets such as the TREC collections, Wikipedia dumps, and domain-specific corpora provide valuable reference points for comparative analysis.
Comparative benchmarking against previous LSA Engine versions reveals efficiency gains from logic enhancements. Historical performance tracking enables identification of specific improvements in algorithmic efficiency, memory management, and computational resource utilization. Additionally, competitive benchmarking against alternative semantic analysis technologies offers context for the LSA Engine's market position and technical advantages.
Stress testing constitutes another critical dimension of performance evaluation, assessing the engine's behavior under extreme conditions. This includes measuring performance degradation patterns during peak loads, recovery times after system failures, and stability characteristics during extended operational periods. Such tests help establish the practical limits of the enhanced software logic.
Performance profiling tools play a vital role in identifying bottlenecks within the LSA Engine's processing pipeline. Modern profiling techniques can pinpoint specific code segments, memory allocation patterns, or thread synchronization issues that limit overall efficiency. Integration of automated performance monitoring enables continuous assessment during development iterations.
The benchmarking framework should also incorporate energy efficiency metrics, particularly for deployments in resource-constrained environments or cloud-based implementations where computational costs directly impact operational expenses. Measuring performance-per-watt characteristics provides insights into the environmental and economic sustainability of the enhanced LSA Engine.
Key performance indicators for LSA Engine efficiency include throughput capacity, processing latency, resource utilization, and scalability factors. Throughput measurements should capture the volume of linguistic data processed per unit time, while latency metrics need to address both average and worst-case response times across different computational loads. Resource utilization metrics must track CPU, memory, and I/O consumption patterns to identify optimization opportunities.
Benchmarking methodologies for LSA Engine software should incorporate standardized test suites that simulate real-world usage scenarios. These test suites should include varying corpus sizes, diverse linguistic structures, and different query complexities to ensure comprehensive performance evaluation. Industry-standard datasets such as the TREC collections, Wikipedia dumps, and domain-specific corpora provide valuable reference points for comparative analysis.
Comparative benchmarking against previous LSA Engine versions reveals efficiency gains from logic enhancements. Historical performance tracking enables identification of specific improvements in algorithmic efficiency, memory management, and computational resource utilization. Additionally, competitive benchmarking against alternative semantic analysis technologies offers context for the LSA Engine's market position and technical advantages.
Stress testing constitutes another critical dimension of performance evaluation, assessing the engine's behavior under extreme conditions. This includes measuring performance degradation patterns during peak loads, recovery times after system failures, and stability characteristics during extended operational periods. Such tests help establish the practical limits of the enhanced software logic.
Performance profiling tools play a vital role in identifying bottlenecks within the LSA Engine's processing pipeline. Modern profiling techniques can pinpoint specific code segments, memory allocation patterns, or thread synchronization issues that limit overall efficiency. Integration of automated performance monitoring enables continuous assessment during development iterations.
The benchmarking framework should also incorporate energy efficiency metrics, particularly for deployments in resource-constrained environments or cloud-based implementations where computational costs directly impact operational expenses. Measuring performance-per-watt characteristics provides insights into the environmental and economic sustainability of the enhanced LSA Engine.
Integration Challenges with Existing Systems
Integrating LSA (Latent Semantic Analysis) Engine software with existing systems presents significant challenges that require careful consideration during implementation. Current enterprise environments typically operate with complex ecosystems of legacy systems, modern applications, and various data repositories that have evolved over years or decades. The LSA Engine's advanced semantic processing capabilities must interface seamlessly with these diverse systems without disrupting ongoing operations.
A primary integration challenge stems from data format inconsistencies across systems. Legacy databases often utilize proprietary data structures that differ substantially from the standardized formats required by LSA Engine software. This necessitates the development of robust data transformation layers capable of normalizing inputs while preserving semantic integrity. Organizations frequently underestimate the complexity of these transformations, particularly when dealing with unstructured or semi-structured data sources.
Performance bottlenecks represent another critical integration concern. When LSA Engine processing is introduced into existing workflows, computational demands can strain system resources, potentially degrading overall system performance. Real-time applications are particularly vulnerable, as semantic analysis operations typically require significant processing power. Careful capacity planning and performance optimization become essential to maintain acceptable response times across integrated systems.
API compatibility issues further complicate integration efforts. Many existing systems utilize outdated communication protocols or proprietary interfaces that may not align with the LSA Engine's API requirements. Developing and maintaining custom adapters introduces additional complexity and potential points of failure within the integrated architecture. Version control across these integration points presents ongoing maintenance challenges as systems evolve independently.
Security and access control frameworks present particular difficulties during integration. LSA Engines often require broad access to organizational data to perform effective semantic analysis. However, this requirement may conflict with established security policies and data governance frameworks. Implementing appropriate security controls without compromising analytical capabilities demands sophisticated authorization mechanisms and careful policy design.
Scalability considerations must also be addressed when integrating LSA Engine software. As data volumes grow and user demands increase, the integrated system must scale proportionally. Existing infrastructure may impose limitations that prevent effective horizontal scaling, necessitating architectural modifications or infrastructure investments to support growing computational requirements.
A primary integration challenge stems from data format inconsistencies across systems. Legacy databases often utilize proprietary data structures that differ substantially from the standardized formats required by LSA Engine software. This necessitates the development of robust data transformation layers capable of normalizing inputs while preserving semantic integrity. Organizations frequently underestimate the complexity of these transformations, particularly when dealing with unstructured or semi-structured data sources.
Performance bottlenecks represent another critical integration concern. When LSA Engine processing is introduced into existing workflows, computational demands can strain system resources, potentially degrading overall system performance. Real-time applications are particularly vulnerable, as semantic analysis operations typically require significant processing power. Careful capacity planning and performance optimization become essential to maintain acceptable response times across integrated systems.
API compatibility issues further complicate integration efforts. Many existing systems utilize outdated communication protocols or proprietary interfaces that may not align with the LSA Engine's API requirements. Developing and maintaining custom adapters introduces additional complexity and potential points of failure within the integrated architecture. Version control across these integration points presents ongoing maintenance challenges as systems evolve independently.
Security and access control frameworks present particular difficulties during integration. LSA Engines often require broad access to organizational data to perform effective semantic analysis. However, this requirement may conflict with established security policies and data governance frameworks. Implementing appropriate security controls without compromising analytical capabilities demands sophisticated authorization mechanisms and careful policy design.
Scalability considerations must also be addressed when integrating LSA Engine software. As data volumes grow and user demands increase, the integrated system must scale proportionally. Existing infrastructure may impose limitations that prevent effective horizontal scaling, necessitating architectural modifications or infrastructure investments to support growing computational requirements.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!