

Method and device for capturing webpage content
A webpage content and webpage technology, applied in the field of webpage content crawling, can solve the problems of low efficiency of webpage content crawling and high complexity of webpage content crawling, and achieve the effect of reducing complexity and improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
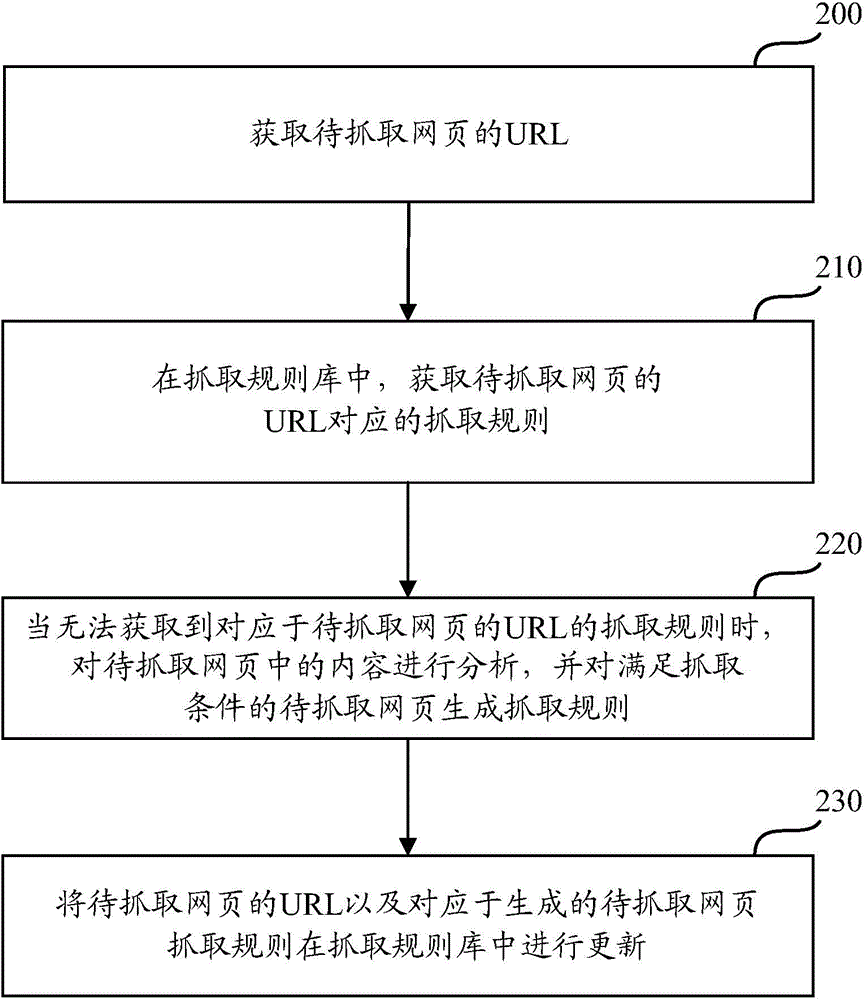
[0031] In order to solve the problems of high complexity and low efficiency of webpage content crawling in the current process of crawling different types of webpage content. In the embodiment of the present invention, when a webpage to be crawled is detected, the URL of the webpage to be crawled is searched from the preset crawling rule base, and when there is no crawling rule corresponding to the URL in the crawling rule base , analyzing content in the webpage to be crawled, and generating crawling rules for the webpage to be crawled that meet the conditions. By adopting the technical scheme of the present invention, the content in the webpage to be grabbed is analyzed, and the corresponding grabbing rules for the webpage to be grabbed are automatically generated according to the analysis results, and there is no need to manually set the grabbing rules, which effectively reduces the complexity of webpage content grabbing and improves Improve the efficiency of web content cra...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More