

Boosting Computational Speed in Neuromorphic Networks
SEP 8, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Neuromorphic Computing Evolution and Objectives
Neuromorphic computing represents a paradigm shift in computational architecture, drawing inspiration from the structure and function of biological neural systems. This field has evolved significantly since its conceptual inception in the late 1980s when Carver Mead first proposed using analog circuits to mimic neurobiological architectures. The evolution of neuromorphic computing has been characterized by progressive attempts to replicate the brain's efficiency in pattern recognition, sensory processing, and adaptive learning while consuming minimal power.
The early developmental phase focused primarily on hardware implementations using CMOS technology to create silicon neurons and synapses. By the early 2000s, research expanded to include spike-timing-dependent plasticity (STDP) and other biologically plausible learning mechanisms. The field gained significant momentum around 2014 with the emergence of large-scale neuromorphic projects such as IBM's TrueNorth and the European Human Brain Project's neuromorphic computing platforms.
Recent years have witnessed a convergence of neuromorphic principles with emerging technologies including memristive devices, photonic computing, and quantum systems. This integration has pushed the boundaries of what's possible in terms of computational speed, energy efficiency, and scalability. The current technological landscape features a diverse ecosystem of neuromorphic solutions ranging from digital implementations like Intel's Loihi to analog approaches and hybrid systems.
The primary objectives of neuromorphic computing research center on addressing the limitations of traditional von Neumann architectures, particularly for applications requiring real-time processing of unstructured data. Specific goals include achieving ultra-low power consumption comparable to biological systems, enabling on-chip learning and adaptation, and facilitating massively parallel computation with distributed memory.
In the context of boosting computational speed, neuromorphic networks aim to leverage event-driven processing and parallel architectures to achieve orders of magnitude improvements in specific tasks compared to conventional computing systems. This includes reducing latency for real-time applications, increasing throughput for data-intensive operations, and enabling complex temporal processing capabilities.
The field is now moving toward developing more sophisticated neuromorphic systems capable of complex cognitive functions while maintaining energy efficiency. Research objectives increasingly focus on scalable architectures that can support billions of neurons and trillions of synapses, improved learning algorithms that combine supervised and unsupervised approaches, and better integration with conventional computing infrastructure to create heterogeneous systems optimized for specific application domains.
The early developmental phase focused primarily on hardware implementations using CMOS technology to create silicon neurons and synapses. By the early 2000s, research expanded to include spike-timing-dependent plasticity (STDP) and other biologically plausible learning mechanisms. The field gained significant momentum around 2014 with the emergence of large-scale neuromorphic projects such as IBM's TrueNorth and the European Human Brain Project's neuromorphic computing platforms.
Recent years have witnessed a convergence of neuromorphic principles with emerging technologies including memristive devices, photonic computing, and quantum systems. This integration has pushed the boundaries of what's possible in terms of computational speed, energy efficiency, and scalability. The current technological landscape features a diverse ecosystem of neuromorphic solutions ranging from digital implementations like Intel's Loihi to analog approaches and hybrid systems.
The primary objectives of neuromorphic computing research center on addressing the limitations of traditional von Neumann architectures, particularly for applications requiring real-time processing of unstructured data. Specific goals include achieving ultra-low power consumption comparable to biological systems, enabling on-chip learning and adaptation, and facilitating massively parallel computation with distributed memory.
In the context of boosting computational speed, neuromorphic networks aim to leverage event-driven processing and parallel architectures to achieve orders of magnitude improvements in specific tasks compared to conventional computing systems. This includes reducing latency for real-time applications, increasing throughput for data-intensive operations, and enabling complex temporal processing capabilities.
The field is now moving toward developing more sophisticated neuromorphic systems capable of complex cognitive functions while maintaining energy efficiency. Research objectives increasingly focus on scalable architectures that can support billions of neurons and trillions of synapses, improved learning algorithms that combine supervised and unsupervised approaches, and better integration with conventional computing infrastructure to create heterogeneous systems optimized for specific application domains.
Market Analysis for High-Speed Neural Networks
The neuromorphic computing market is experiencing unprecedented growth, driven by the increasing demand for high-speed neural networks across various industries. Current market valuations place the global neuromorphic computing sector at approximately 3.2 billion USD in 2023, with projections indicating a compound annual growth rate of 23.7% through 2030. This remarkable expansion is primarily fueled by applications requiring real-time processing capabilities, including autonomous vehicles, advanced robotics, and edge computing devices.
The demand landscape for high-speed neural networks is segmented across multiple verticals. The automotive sector represents the largest market share at 28%, where neuromorphic systems enable faster decision-making in autonomous driving scenarios. Healthcare applications follow closely at 24%, with neuromorphic networks accelerating medical imaging analysis and patient monitoring systems. Industrial automation and consumer electronics account for 19% and 17% respectively, while emerging applications in aerospace and defense comprise the remaining 12%.
Geographic distribution of market demand shows North America leading with 42% market share, followed by Europe (27%), Asia-Pacific (23%), and rest of the world (8%). However, the Asia-Pacific region demonstrates the highest growth rate at 29.3%, primarily driven by substantial investments in AI infrastructure in China, Japan, and South Korea.
Customer requirements are increasingly focused on three key performance indicators: processing speed (measured in synaptic operations per second), energy efficiency (operations per watt), and integration capabilities with existing systems. Market surveys indicate that 76% of enterprise customers prioritize computational speed as their primary concern when adopting neuromorphic solutions, highlighting the critical importance of boosting computational performance in these networks.
The market is witnessing a significant shift from cloud-based neural network processing to edge computing implementations, with edge deployments growing at 34.2% annually compared to 18.9% for cloud solutions. This transition is creating new opportunities for neuromorphic computing architectures that can deliver high-speed processing with minimal power consumption at the network edge.
Industry analysts forecast that by 2025, over 60% of AI workloads will require neuromorphic or similar specialized computing architectures to meet performance demands. This trend is creating a substantial market opportunity for solutions that can significantly boost computational speed in neuromorphic networks while maintaining energy efficiency parameters that make them viable for widespread commercial deployment.
The demand landscape for high-speed neural networks is segmented across multiple verticals. The automotive sector represents the largest market share at 28%, where neuromorphic systems enable faster decision-making in autonomous driving scenarios. Healthcare applications follow closely at 24%, with neuromorphic networks accelerating medical imaging analysis and patient monitoring systems. Industrial automation and consumer electronics account for 19% and 17% respectively, while emerging applications in aerospace and defense comprise the remaining 12%.
Geographic distribution of market demand shows North America leading with 42% market share, followed by Europe (27%), Asia-Pacific (23%), and rest of the world (8%). However, the Asia-Pacific region demonstrates the highest growth rate at 29.3%, primarily driven by substantial investments in AI infrastructure in China, Japan, and South Korea.
Customer requirements are increasingly focused on three key performance indicators: processing speed (measured in synaptic operations per second), energy efficiency (operations per watt), and integration capabilities with existing systems. Market surveys indicate that 76% of enterprise customers prioritize computational speed as their primary concern when adopting neuromorphic solutions, highlighting the critical importance of boosting computational performance in these networks.
The market is witnessing a significant shift from cloud-based neural network processing to edge computing implementations, with edge deployments growing at 34.2% annually compared to 18.9% for cloud solutions. This transition is creating new opportunities for neuromorphic computing architectures that can deliver high-speed processing with minimal power consumption at the network edge.
Industry analysts forecast that by 2025, over 60% of AI workloads will require neuromorphic or similar specialized computing architectures to meet performance demands. This trend is creating a substantial market opportunity for solutions that can significantly boost computational speed in neuromorphic networks while maintaining energy efficiency parameters that make them viable for widespread commercial deployment.
Current Limitations in Neuromorphic Processing
Despite significant advancements in neuromorphic computing, several critical limitations continue to impede the computational speed and efficiency of neuromorphic networks. The von Neumann bottleneck remains a fundamental challenge, where the physical separation between processing units and memory creates data transfer delays that significantly impact computational throughput. This architectural constraint becomes particularly problematic as network complexity increases, resulting in exponential growth of communication overhead between neural components.
Energy efficiency, while improved compared to traditional computing paradigms, still falls short of biological neural systems by several orders of magnitude. Current neuromorphic hardware typically consumes 100-1000 times more energy per synaptic operation than the human brain, limiting deployment in power-constrained environments and mobile applications where computational speed must be balanced against energy consumption.
Scaling limitations present another significant barrier, as existing fabrication technologies struggle to maintain signal integrity and timing precision when implementing large-scale neuromorphic systems. As network size increases, signal degradation, crosstalk, and timing jitter introduce computational errors that compromise both speed and accuracy. These physical constraints have restricted most current implementations to relatively modest network sizes compared to biological counterparts.
The hardware-software interface presents additional challenges, with existing programming frameworks and algorithms often failing to fully exploit the parallel processing capabilities of neuromorphic hardware. The translation between conventional programming paradigms and spike-based neuromorphic computation introduces overhead that diminishes potential speed advantages. Current development tools lack the sophistication needed to optimize network topology and spike timing for maximum computational efficiency.
Temporal precision limitations further constrain performance, as existing neuromorphic systems struggle to maintain accurate timing of spike events across large networks. This timing imprecision directly impacts computational speed by necessitating additional error correction mechanisms or reduced operating frequencies to maintain accuracy. The trade-off between speed and precision remains unresolved in most current implementations.
Material and fabrication constraints also impose limitations, with current CMOS-based neuromorphic systems facing fundamental physical limits in terms of miniaturization and switching speed. While emerging materials like memristors offer theoretical advantages, their practical implementation faces challenges in reliability, reproducibility, and integration with existing semiconductor processes, limiting their current contribution to computational speed improvements.
Energy efficiency, while improved compared to traditional computing paradigms, still falls short of biological neural systems by several orders of magnitude. Current neuromorphic hardware typically consumes 100-1000 times more energy per synaptic operation than the human brain, limiting deployment in power-constrained environments and mobile applications where computational speed must be balanced against energy consumption.
Scaling limitations present another significant barrier, as existing fabrication technologies struggle to maintain signal integrity and timing precision when implementing large-scale neuromorphic systems. As network size increases, signal degradation, crosstalk, and timing jitter introduce computational errors that compromise both speed and accuracy. These physical constraints have restricted most current implementations to relatively modest network sizes compared to biological counterparts.
The hardware-software interface presents additional challenges, with existing programming frameworks and algorithms often failing to fully exploit the parallel processing capabilities of neuromorphic hardware. The translation between conventional programming paradigms and spike-based neuromorphic computation introduces overhead that diminishes potential speed advantages. Current development tools lack the sophistication needed to optimize network topology and spike timing for maximum computational efficiency.
Temporal precision limitations further constrain performance, as existing neuromorphic systems struggle to maintain accurate timing of spike events across large networks. This timing imprecision directly impacts computational speed by necessitating additional error correction mechanisms or reduced operating frequencies to maintain accuracy. The trade-off between speed and precision remains unresolved in most current implementations.
Material and fabrication constraints also impose limitations, with current CMOS-based neuromorphic systems facing fundamental physical limits in terms of miniaturization and switching speed. While emerging materials like memristors offer theoretical advantages, their practical implementation faces challenges in reliability, reproducibility, and integration with existing semiconductor processes, limiting their current contribution to computational speed improvements.
Existing Acceleration Techniques for Neural Networks
01 Hardware acceleration techniques for neuromorphic computing
Various hardware acceleration techniques can significantly improve the computational speed of neuromorphic networks. These include specialized neuromorphic processors, FPGA implementations, and custom ASICs designed specifically for neural network operations. These hardware solutions offer parallel processing capabilities that can dramatically reduce computation time compared to traditional computing architectures, enabling real-time processing for complex neuromorphic applications.- Hardware acceleration for neuromorphic computing: Specialized hardware architectures designed to accelerate neuromorphic computing operations can significantly improve computational speed. These designs include dedicated neuromorphic processors, FPGA implementations, and custom ASICs that optimize the parallel processing capabilities inherent in neural networks. By implementing neural computations directly in hardware rather than simulating them in software, these systems achieve orders of magnitude improvements in speed and energy efficiency.
- Spike-based processing techniques: Spike-based processing techniques mimic the brain's communication method using discrete events rather than continuous signals. This approach enables efficient event-driven computation where processing occurs only when needed, reducing computational overhead. Spike-timing-dependent plasticity (STDP) and other spiking neural network algorithms optimize information transmission and learning while minimizing energy consumption, resulting in faster processing for complex pattern recognition and temporal data analysis tasks.
- Memory-processing integration: Integrating memory and processing elements reduces the data transfer bottleneck that limits computational speed in traditional von Neumann architectures. By placing memory elements directly alongside neuromorphic processing units, these systems minimize the energy and time costs associated with moving data between separate memory and processing components. This approach enables in-memory computing where calculations occur directly within memory arrays, dramatically accelerating neural network operations.
- Parallel processing architectures: Neuromorphic networks leverage massively parallel processing architectures that distribute computational workloads across numerous simple processing elements operating simultaneously. This parallelism mirrors the brain's structure and enables efficient handling of complex neural network operations. By executing multiple operations concurrently rather than sequentially, these systems achieve significant speedups for tasks like pattern recognition, sensory processing, and real-time decision making.
- Optimization algorithms for neuromorphic computation: Advanced algorithms specifically designed for neuromorphic systems can substantially improve computational efficiency. These include sparse coding techniques, pruning methods that reduce unnecessary connections, and quantization approaches that lower precision requirements without sacrificing accuracy. Additionally, specialized training algorithms optimize network topologies and weight distributions to maximize information processing speed while minimizing computational resources needed for inference operations.
02 Spiking neural network optimization for speed enhancement
Spiking neural networks (SNNs) can be optimized for improved computational efficiency through various techniques. These include sparse coding, event-driven processing, and optimized spike timing mechanisms. By reducing unnecessary computations and focusing on information-carrying spikes, these networks can achieve significant speed improvements while maintaining computational accuracy, making them suitable for resource-constrained environments and real-time applications.Expand Specific Solutions03 Memory-processing integration for neuromorphic systems
Integrating memory and processing elements in neuromorphic architectures can substantially reduce data movement bottlenecks that typically limit computational speed. This approach includes in-memory computing, memristive devices, and crossbar arrays that enable parallel weight access. By minimizing the physical distance between memory storage and computation, these systems can achieve orders of magnitude improvement in energy efficiency and processing speed for neural network operations.Expand Specific Solutions04 Novel neuromorphic algorithms for computational efficiency
Advanced algorithms specifically designed for neuromorphic hardware can dramatically improve computational speed. These include approximate computing techniques, pruning methods, and quantization strategies that reduce computational complexity while maintaining acceptable accuracy. By optimizing the algorithmic approach to match the unique characteristics of neuromorphic hardware, these methods enable faster processing of neural network operations with minimal impact on overall performance.Expand Specific Solutions05 Parallel processing architectures for neuromorphic networks
Specialized parallel processing architectures can significantly enhance the computational speed of neuromorphic networks. These designs leverage distributed computing principles, multi-core processing, and scalable interconnect technologies to process neural network operations simultaneously. By enabling multiple computations to occur concurrently, these architectures can achieve substantial speedups for large-scale neuromorphic applications, particularly those requiring real-time processing of complex sensory data.Expand Specific Solutions
Leading Organizations in Neuromorphic Computing
The neuromorphic computing market is currently in a growth phase, with increasing investments from major tech players. The global market size is estimated to reach $8-10 billion by 2025, growing at a CAGR of approximately 20%. Technologically, the field is transitioning from research to commercial applications, with varying maturity levels across companies. Industry leaders like IBM and Huawei have developed advanced neuromorphic chips (TrueNorth, Ascend), while Samsung and NEC are making significant strides in hardware implementation. Academic institutions including Tsinghua University and KAIST are contributing fundamental research. Chinese companies like Cambricon and Baidu are rapidly advancing their capabilities, while startups are emerging with specialized solutions. The ecosystem shows a healthy balance between established players and new entrants, indicating a dynamic competitive landscape.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a comprehensive neuromorphic computing platform called "Ascend" that incorporates both hardware and software innovations to accelerate neural network processing. Their architecture employs a heterogeneous computing approach that combines traditional digital processing with neuromorphic principles. Huawei's Da Vinci architecture within the Ascend platform utilizes a unique "Cube" computing engine that performs matrix operations with extreme efficiency, achieving up to 256 TOPS/W for INT8 operations. The company has implemented specialized data flow mechanisms that minimize memory access and maximize computational throughput by keeping data local to processing elements. Huawei's neuromorphic solutions incorporate novel sparse computing techniques that dynamically adapt to neural network sparsity patterns, skipping unnecessary computations. Their architecture also features reconfigurable interconnects that can be optimized for different neural network topologies, providing flexibility while maintaining high performance. Huawei has demonstrated systems that achieve 50x performance improvement for certain neuromorphic workloads compared to conventional GPU implementations.
Strengths: Comprehensive software ecosystem integration; high computational efficiency; flexible architecture adaptable to different neural network models; production-ready technology with commercial deployment. Weaknesses: Higher power consumption than pure neuromorphic approaches; requires specialized hardware; potential geopolitical challenges affecting global adoption.
International Business Machines Corp.
Technical Solution: IBM's neuromorphic computing approach focuses on TrueNorth and subsequent architectures that fundamentally reimagine computing for neural networks. Their TrueNorth chip contains 1 million digital neurons and 256 million synapses organized into 4,096 neurosynaptic cores, consuming only 70mW during real-time operation. IBM has further advanced this technology with their second-generation neuromorphic chip that implements time-multiplexed neurons with in-memory computing capabilities. The architecture employs a novel digital spiking design that enables massively parallel operation while maintaining extremely low power consumption. IBM's neuromorphic systems utilize event-driven processing where computation occurs only when needed, dramatically reducing energy requirements compared to traditional von Neumann architectures. Their systems implement sparse coding techniques and specialized routing fabrics that minimize data movement, which is a primary computational bottleneck in conventional systems.
Strengths: Extremely low power consumption (orders of magnitude less than GPUs); true parallel processing capabilities; event-driven architecture eliminates idle power consumption; scalable architecture. Weaknesses: Programming complexity requires specialized knowledge; limited software ecosystem compared to traditional computing platforms; challenges in mapping conventional algorithms to spiking neural networks.
Key Innovations in Computational Efficiency
Neuromorphic system comprising waveguide extending into array
PatentWO2024172291A1
Innovation
- A neuromorphic system incorporating waveguides within a synapse array to transmit light pulses for weight adjustment and inference processes, enabling efficient computation through large-scale parallel connections and rapid weight adjustment using a passive optical matrix system.
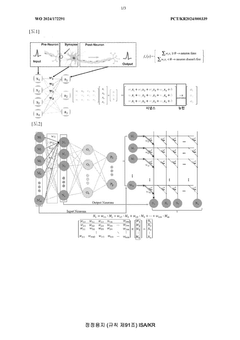
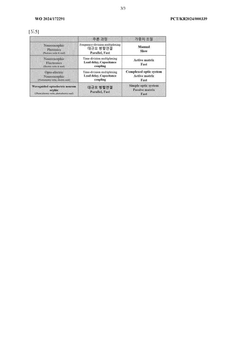

Neural network accelerating method and device
PatentWO2021143143A1
Innovation
- By reading the total memory size of the graphics processor, setting the size of the configurable level, and based on this, the optimal accelerated solution architecture is generated, and the genetic algorithm is used to iterate the state transfer equation to determine the optimal batch size and network layer configuration. Optimize the efficiency of convolution operations, convert it into a multiple knapsack problem, and adapt to any size of video memory environment.

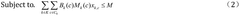


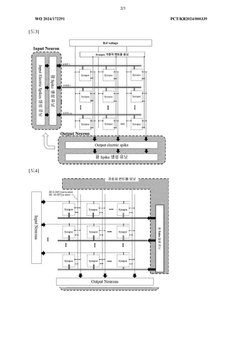
Hardware-Software Co-design Approaches
Hardware-Software Co-design Approaches represent a critical paradigm in accelerating neuromorphic computing systems. This methodology integrates hardware architecture design and software optimization simultaneously rather than treating them as separate development processes. In neuromorphic networks, where computational models attempt to mimic biological neural systems, this integrated approach has demonstrated significant performance improvements by addressing bottlenecks at both levels concurrently.
The co-design process typically begins with comprehensive workload characterization, identifying computational patterns specific to neuromorphic algorithms. This analysis reveals opportunities for specialized hardware acceleration while guiding software optimizations. For instance, spike-based processing in spiking neural networks (SNNs) exhibits sparse activation patterns that can be exploited through both custom hardware circuits and tailored software algorithms.
Memory-compute integration forms another cornerstone of effective co-design strategies. Traditional von Neumann architectures suffer from the "memory wall" problem, particularly detrimental to neural network performance. Co-design approaches address this through in-memory computing techniques, where processing elements are positioned closer to memory units, dramatically reducing data movement costs. Complementary software techniques then optimize memory access patterns and data layouts specifically for these architectures.
Dynamic resource allocation mechanisms represent an emerging trend in neuromorphic co-design. These systems adaptively distribute computational resources based on network activity, focusing processing power where needed most. Hardware implementations include configurable interconnects and variable precision units, while software frameworks provide runtime systems that monitor network activity and adjust resource allocation accordingly.
Energy efficiency considerations permeate successful co-design approaches. Hardware innovations like sub-threshold operation and approximate computing are paired with software techniques such as selective precision computation and activity-dependent processing. This synergy enables neuromorphic systems to maintain high performance while operating within strict power envelopes, particularly crucial for edge deployment scenarios.
Programming models specifically designed for neuromorphic hardware constitute another vital co-design element. These models abstract hardware complexities while exposing key optimization opportunities, allowing algorithm developers to leverage hardware capabilities without detailed low-level knowledge. Examples include event-driven programming frameworks that map efficiently to spike-based hardware and domain-specific languages that compile to optimized neuromorphic instruction sets.
The co-design process typically begins with comprehensive workload characterization, identifying computational patterns specific to neuromorphic algorithms. This analysis reveals opportunities for specialized hardware acceleration while guiding software optimizations. For instance, spike-based processing in spiking neural networks (SNNs) exhibits sparse activation patterns that can be exploited through both custom hardware circuits and tailored software algorithms.
Memory-compute integration forms another cornerstone of effective co-design strategies. Traditional von Neumann architectures suffer from the "memory wall" problem, particularly detrimental to neural network performance. Co-design approaches address this through in-memory computing techniques, where processing elements are positioned closer to memory units, dramatically reducing data movement costs. Complementary software techniques then optimize memory access patterns and data layouts specifically for these architectures.
Dynamic resource allocation mechanisms represent an emerging trend in neuromorphic co-design. These systems adaptively distribute computational resources based on network activity, focusing processing power where needed most. Hardware implementations include configurable interconnects and variable precision units, while software frameworks provide runtime systems that monitor network activity and adjust resource allocation accordingly.
Energy efficiency considerations permeate successful co-design approaches. Hardware innovations like sub-threshold operation and approximate computing are paired with software techniques such as selective precision computation and activity-dependent processing. This synergy enables neuromorphic systems to maintain high performance while operating within strict power envelopes, particularly crucial for edge deployment scenarios.
Programming models specifically designed for neuromorphic hardware constitute another vital co-design element. These models abstract hardware complexities while exposing key optimization opportunities, allowing algorithm developers to leverage hardware capabilities without detailed low-level knowledge. Examples include event-driven programming frameworks that map efficiently to spike-based hardware and domain-specific languages that compile to optimized neuromorphic instruction sets.
Energy Efficiency Considerations
Energy efficiency represents a critical dimension in the advancement of neuromorphic computing systems. Traditional von Neumann architectures face significant energy constraints when implementing neural network operations, consuming substantial power for data movement between memory and processing units. Neuromorphic networks, by contrast, offer promising pathways toward dramatically reduced energy consumption through their brain-inspired architectural principles. The co-location of memory and processing elements in these systems substantially decreases energy expenditure associated with data transfer, which typically accounts for up to 70% of energy consumption in conventional computing paradigms.
Current neuromorphic implementations demonstrate energy efficiency improvements of 2-3 orders of magnitude compared to traditional GPU-based neural network processing. For instance, IBM's TrueNorth architecture achieves approximately 400 billion synaptic operations per second per watt, while Intel's Loihi chip demonstrates similar efficiency metrics. These advancements stem from event-driven computation models that activate circuits only when necessary, mimicking the brain's sparse activation patterns.
The relationship between computational speed and energy consumption presents complex trade-offs in neuromorphic systems. While increasing clock frequencies can boost computational throughput, it typically results in quadratic energy consumption growth. Alternative approaches focus on parallelization and specialized hardware accelerators that maintain energy efficiency while enhancing computational capabilities. Recent innovations in materials science, particularly memristive devices and spintronic components, offer pathways to further reduce the energy footprint of neuromorphic operations.
Thermal management emerges as another crucial consideration, as heat dissipation directly impacts both system reliability and energy requirements. Advanced cooling solutions and three-dimensional integration techniques are being explored to address thermal challenges while maintaining computational density. Additionally, dynamic power management strategies that adapt energy allocation based on computational demands show promise for optimizing the energy-performance balance.
Looking forward, the convergence of ultra-low-power electronics, novel computing materials, and biologically plausible learning algorithms presents opportunities to approach the energy efficiency of biological neural systems. The human brain's remarkable capability to perform complex cognitive tasks at approximately 20 watts serves as an aspirational benchmark for neuromorphic engineering. Achieving comparable efficiency levels would revolutionize applications ranging from edge computing to autonomous systems, where energy constraints currently limit deployment possibilities.
Current neuromorphic implementations demonstrate energy efficiency improvements of 2-3 orders of magnitude compared to traditional GPU-based neural network processing. For instance, IBM's TrueNorth architecture achieves approximately 400 billion synaptic operations per second per watt, while Intel's Loihi chip demonstrates similar efficiency metrics. These advancements stem from event-driven computation models that activate circuits only when necessary, mimicking the brain's sparse activation patterns.
The relationship between computational speed and energy consumption presents complex trade-offs in neuromorphic systems. While increasing clock frequencies can boost computational throughput, it typically results in quadratic energy consumption growth. Alternative approaches focus on parallelization and specialized hardware accelerators that maintain energy efficiency while enhancing computational capabilities. Recent innovations in materials science, particularly memristive devices and spintronic components, offer pathways to further reduce the energy footprint of neuromorphic operations.
Thermal management emerges as another crucial consideration, as heat dissipation directly impacts both system reliability and energy requirements. Advanced cooling solutions and three-dimensional integration techniques are being explored to address thermal challenges while maintaining computational density. Additionally, dynamic power management strategies that adapt energy allocation based on computational demands show promise for optimizing the energy-performance balance.
Looking forward, the convergence of ultra-low-power electronics, novel computing materials, and biologically plausible learning algorithms presents opportunities to approach the energy efficiency of biological neural systems. The human brain's remarkable capability to perform complex cognitive tasks at approximately 20 watts serves as an aspirational benchmark for neuromorphic engineering. Achieving comparable efficiency levels would revolutionize applications ranging from edge computing to autonomous systems, where energy constraints currently limit deployment possibilities.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!