

How to Optimize Neuromorphic Computing for AI Tasks
SEP 5, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Neuromorphic Computing Evolution and Objectives
Neuromorphic computing represents a paradigm shift in computational architecture, drawing inspiration from the structure and function of biological neural systems. Since its conceptual inception in the late 1980s by Carver Mead, this field has evolved from theoretical frameworks to practical implementations that aim to mimic the brain's efficiency in processing information. The evolution trajectory has been marked by significant milestones, from early analog VLSI implementations to contemporary spiking neural networks (SNNs) and memristor-based systems.
The fundamental principle driving neuromorphic computing is the emulation of neurobiological architectures, utilizing parallel processing, event-driven computation, and co-located memory and processing units. This approach stands in stark contrast to traditional von Neumann architectures, which separate memory and processing functions, creating bottlenecks in data transfer and energy consumption.
Recent advancements have accelerated the field's development, with notable projects including IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida neuromorphic processors. These systems demonstrate remarkable energy efficiency, with power consumption orders of magnitude lower than conventional computing systems when performing certain AI tasks. The progression from first-generation static architectures to dynamic, learning-capable systems represents a critical evolutionary step.
The primary objectives of neuromorphic computing optimization for AI tasks encompass several dimensions. Energy efficiency stands as a paramount goal, with neuromorphic systems aiming to achieve brain-like computational efficiency of approximately 20 watts for complex cognitive tasks. Temporal processing capabilities represent another crucial objective, as neuromorphic systems excel at processing time-varying data streams, making them ideal for real-time applications like autonomous vehicles and robotics.
Adaptability and learning constitute additional key objectives, with research focused on implementing on-chip learning mechanisms that allow systems to adapt to new information without extensive retraining. This capability is particularly valuable for edge computing applications where continuous learning from environmental interactions is essential.
Scale and integration objectives focus on increasing the number of neurons and synapses while maintaining energy efficiency, with current systems scaling to millions of neurons but still falling short of the human brain's approximately 86 billion neurons. Finally, application-specific optimization aims to tailor neuromorphic architectures to particular AI tasks, recognizing that different applications may benefit from specialized neural circuit designs.
The trajectory of neuromorphic computing points toward increasingly sophisticated bio-inspired architectures that promise to revolutionize AI implementation, particularly for applications requiring real-time processing, energy efficiency, and adaptive learning capabilities.
The fundamental principle driving neuromorphic computing is the emulation of neurobiological architectures, utilizing parallel processing, event-driven computation, and co-located memory and processing units. This approach stands in stark contrast to traditional von Neumann architectures, which separate memory and processing functions, creating bottlenecks in data transfer and energy consumption.
Recent advancements have accelerated the field's development, with notable projects including IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida neuromorphic processors. These systems demonstrate remarkable energy efficiency, with power consumption orders of magnitude lower than conventional computing systems when performing certain AI tasks. The progression from first-generation static architectures to dynamic, learning-capable systems represents a critical evolutionary step.
The primary objectives of neuromorphic computing optimization for AI tasks encompass several dimensions. Energy efficiency stands as a paramount goal, with neuromorphic systems aiming to achieve brain-like computational efficiency of approximately 20 watts for complex cognitive tasks. Temporal processing capabilities represent another crucial objective, as neuromorphic systems excel at processing time-varying data streams, making them ideal for real-time applications like autonomous vehicles and robotics.
Adaptability and learning constitute additional key objectives, with research focused on implementing on-chip learning mechanisms that allow systems to adapt to new information without extensive retraining. This capability is particularly valuable for edge computing applications where continuous learning from environmental interactions is essential.
Scale and integration objectives focus on increasing the number of neurons and synapses while maintaining energy efficiency, with current systems scaling to millions of neurons but still falling short of the human brain's approximately 86 billion neurons. Finally, application-specific optimization aims to tailor neuromorphic architectures to particular AI tasks, recognizing that different applications may benefit from specialized neural circuit designs.
The trajectory of neuromorphic computing points toward increasingly sophisticated bio-inspired architectures that promise to revolutionize AI implementation, particularly for applications requiring real-time processing, energy efficiency, and adaptive learning capabilities.
AI Market Demands for Brain-Inspired Computing
The global AI market is experiencing unprecedented growth, with neuromorphic computing emerging as a critical technology to address the limitations of traditional computing architectures. Market research indicates that the neuromorphic computing market is projected to grow at a CAGR of 49.1% from 2021 to 2026, reaching $8.0 billion by 2026. This remarkable growth is driven by increasing demands for more efficient AI processing capabilities across multiple industries.
Energy efficiency has become a paramount concern in AI deployment, particularly for edge computing applications. Traditional von Neumann architectures consume excessive power when running complex AI workloads, creating a substantial market demand for neuromorphic solutions that can reduce energy consumption by up to 1000x for certain neural network operations. This efficiency gain is particularly attractive for battery-powered devices and data centers facing escalating energy costs.
Real-time processing requirements are intensifying across industries such as autonomous vehicles, industrial automation, and healthcare monitoring. These applications demand ultra-low latency processing of sensory data, creating a significant market opportunity for neuromorphic systems that can process information with biological-like speed and efficiency. The automotive sector alone is expected to invest over $5 billion in neuromorphic technologies by 2028 to enable advanced driver assistance systems and autonomous driving capabilities.
Edge AI deployment is rapidly expanding, with over 15 billion edge AI devices expected by 2025. This proliferation creates substantial demand for neuromorphic solutions that can operate efficiently within the power and size constraints of edge devices. Brain-inspired computing architectures offer the potential to run sophisticated AI models locally without requiring constant cloud connectivity, addressing growing privacy concerns and bandwidth limitations.
The healthcare sector represents another significant market opportunity, with neuromorphic computing enabling advanced medical imaging analysis, real-time patient monitoring, and brain-computer interfaces. The neuromorphic healthcare market segment is expected to reach $1.2 billion by 2027, driven by applications in early disease detection and personalized medicine.
Financial services and cybersecurity sectors are increasingly adopting AI for fraud detection, risk assessment, and threat identification. These applications require processing massive datasets in real-time with minimal latency, creating demand for neuromorphic systems that can efficiently handle temporal data patterns and anomaly detection tasks.
As AI models continue to grow in complexity, with some models exceeding hundreds of billions of parameters, there is mounting pressure to develop more sustainable computing approaches. This trend is driving investment in neuromorphic technologies that promise to deliver the computational power needed for advanced AI while significantly reducing the carbon footprint associated with AI training and inference.
Energy efficiency has become a paramount concern in AI deployment, particularly for edge computing applications. Traditional von Neumann architectures consume excessive power when running complex AI workloads, creating a substantial market demand for neuromorphic solutions that can reduce energy consumption by up to 1000x for certain neural network operations. This efficiency gain is particularly attractive for battery-powered devices and data centers facing escalating energy costs.
Real-time processing requirements are intensifying across industries such as autonomous vehicles, industrial automation, and healthcare monitoring. These applications demand ultra-low latency processing of sensory data, creating a significant market opportunity for neuromorphic systems that can process information with biological-like speed and efficiency. The automotive sector alone is expected to invest over $5 billion in neuromorphic technologies by 2028 to enable advanced driver assistance systems and autonomous driving capabilities.
Edge AI deployment is rapidly expanding, with over 15 billion edge AI devices expected by 2025. This proliferation creates substantial demand for neuromorphic solutions that can operate efficiently within the power and size constraints of edge devices. Brain-inspired computing architectures offer the potential to run sophisticated AI models locally without requiring constant cloud connectivity, addressing growing privacy concerns and bandwidth limitations.
The healthcare sector represents another significant market opportunity, with neuromorphic computing enabling advanced medical imaging analysis, real-time patient monitoring, and brain-computer interfaces. The neuromorphic healthcare market segment is expected to reach $1.2 billion by 2027, driven by applications in early disease detection and personalized medicine.
Financial services and cybersecurity sectors are increasingly adopting AI for fraud detection, risk assessment, and threat identification. These applications require processing massive datasets in real-time with minimal latency, creating demand for neuromorphic systems that can efficiently handle temporal data patterns and anomaly detection tasks.
As AI models continue to grow in complexity, with some models exceeding hundreds of billions of parameters, there is mounting pressure to develop more sustainable computing approaches. This trend is driving investment in neuromorphic technologies that promise to deliver the computational power needed for advanced AI while significantly reducing the carbon footprint associated with AI training and inference.
Current Neuromorphic Architectures and Limitations
Neuromorphic computing architectures have evolved significantly over the past decade, with several prominent designs emerging as frontrunners in the field. The IBM TrueNorth chip represents one of the earliest successful implementations, featuring a million digital neurons arranged in a crossbar architecture that enables efficient event-driven computation. Intel's Loihi chip has advanced this approach with self-learning capabilities and on-chip training, incorporating approximately 130,000 neurons and 130 million synapses in its second generation.
SpiNNaker, developed by the University of Manchester, takes a different approach by using ARM processors to simulate neural behavior, allowing for greater flexibility in neural models but with higher power consumption. BrainScaleS, from the University of Heidelberg, employs analog circuits operating at accelerated timescales, enabling faster simulation but introducing challenges in precision and reproducibility.
Despite these advancements, current neuromorphic architectures face significant limitations when optimizing for AI tasks. Scalability remains a primary challenge, as existing systems struggle to match the neuron count of even simple biological organisms, let alone approach human-level complexity. The human brain contains approximately 86 billion neurons with trillions of synapses, while current neuromorphic systems typically implement only millions of neurons.
Energy efficiency, while improved compared to traditional computing paradigms, still falls short of biological systems. The human brain operates at approximately 20 watts, whereas scaled neuromorphic systems would require substantially more power to achieve comparable computational capabilities. This efficiency gap limits deployment in edge computing scenarios where power constraints are critical.
Programming models and development tools for neuromorphic systems remain immature and fragmented. Unlike traditional computing platforms with standardized programming interfaces, neuromorphic computing lacks unified frameworks, creating significant barriers to adoption. Developers must often work with hardware-specific tools and models, limiting portability and increasing development complexity.
The hardware-software integration presents another substantial challenge. Translating conventional AI algorithms to spiking neural networks requires fundamental rethinking of computational approaches. Many deep learning techniques do not directly transfer to spike-based computation, necessitating new algorithmic paradigms that can leverage the temporal dynamics of neuromorphic systems.
Precision and reliability issues also plague current architectures. Analog implementations suffer from device variability and noise, while digital implementations face trade-offs between precision and efficiency. These challenges become particularly acute for applications requiring high accuracy, such as medical diagnostics or autonomous vehicle control, where performance inconsistencies could have serious consequences.
SpiNNaker, developed by the University of Manchester, takes a different approach by using ARM processors to simulate neural behavior, allowing for greater flexibility in neural models but with higher power consumption. BrainScaleS, from the University of Heidelberg, employs analog circuits operating at accelerated timescales, enabling faster simulation but introducing challenges in precision and reproducibility.
Despite these advancements, current neuromorphic architectures face significant limitations when optimizing for AI tasks. Scalability remains a primary challenge, as existing systems struggle to match the neuron count of even simple biological organisms, let alone approach human-level complexity. The human brain contains approximately 86 billion neurons with trillions of synapses, while current neuromorphic systems typically implement only millions of neurons.
Energy efficiency, while improved compared to traditional computing paradigms, still falls short of biological systems. The human brain operates at approximately 20 watts, whereas scaled neuromorphic systems would require substantially more power to achieve comparable computational capabilities. This efficiency gap limits deployment in edge computing scenarios where power constraints are critical.
Programming models and development tools for neuromorphic systems remain immature and fragmented. Unlike traditional computing platforms with standardized programming interfaces, neuromorphic computing lacks unified frameworks, creating significant barriers to adoption. Developers must often work with hardware-specific tools and models, limiting portability and increasing development complexity.
The hardware-software integration presents another substantial challenge. Translating conventional AI algorithms to spiking neural networks requires fundamental rethinking of computational approaches. Many deep learning techniques do not directly transfer to spike-based computation, necessitating new algorithmic paradigms that can leverage the temporal dynamics of neuromorphic systems.
Precision and reliability issues also plague current architectures. Analog implementations suffer from device variability and noise, while digital implementations face trade-offs between precision and efficiency. These challenges become particularly acute for applications requiring high accuracy, such as medical diagnostics or autonomous vehicle control, where performance inconsistencies could have serious consequences.
Current Optimization Approaches for Neuromorphic AI Systems
01 Hardware optimization for neuromorphic systems
Optimization of hardware components in neuromorphic computing systems to improve performance and efficiency. This includes specialized circuit designs, memory architectures, and integration techniques that mimic neural structures. These hardware optimizations enable faster processing, reduced power consumption, and better scalability for neuromorphic applications.- Hardware optimization for neuromorphic computing: Neuromorphic computing systems can be optimized through specialized hardware designs that mimic neural structures. These optimizations include developing memristor-based synaptic arrays, specialized neuromorphic processors, and energy-efficient circuit designs. Such hardware implementations enable more efficient processing of neural network operations while significantly reducing power consumption compared to traditional computing architectures.
- Algorithm optimization techniques: Various algorithm optimization techniques can enhance neuromorphic computing performance. These include spike-timing-dependent plasticity (STDP) implementations, efficient neural network training methods, and specialized learning algorithms designed for spiking neural networks. These algorithmic approaches help improve accuracy, reduce computational complexity, and enable more efficient processing of complex data patterns in neuromorphic systems.
- Energy efficiency improvements: Energy efficiency is a critical aspect of neuromorphic computing optimization. Techniques include low-power circuit designs, optimized spike encoding schemes, and event-driven processing architectures. These approaches significantly reduce power consumption while maintaining computational capabilities, making neuromorphic systems suitable for edge computing applications and battery-powered devices where energy constraints are important considerations.
- Integration with conventional computing systems: Optimizing the integration of neuromorphic computing with conventional computing architectures enables hybrid systems that leverage the strengths of both approaches. This includes developing interface protocols, memory management techniques, and co-processing strategies. Such integration allows neuromorphic components to handle pattern recognition and learning tasks while traditional processors manage precise calculations and control functions.
- Application-specific neuromorphic optimizations: Tailoring neuromorphic computing systems for specific applications can yield significant performance improvements. This includes optimizing neural network architectures for computer vision, natural language processing, or autonomous systems. Application-specific optimizations involve customizing network topologies, learning rules, and hardware configurations to match the unique requirements of target applications, resulting in better performance and efficiency.
02 Energy efficiency and power optimization techniques
Methods to reduce power consumption and improve energy efficiency in neuromorphic computing systems. These techniques include low-power circuit designs, optimized spike timing, and efficient data transfer mechanisms. Energy-efficient neuromorphic systems are crucial for edge computing applications and portable devices where power constraints are significant.Expand Specific Solutions03 Learning algorithms and training optimization
Advanced algorithms for training neuromorphic networks more efficiently, including spike-timing-dependent plasticity (STDP), backpropagation adaptations, and unsupervised learning methods. These optimized learning approaches improve the accuracy and convergence speed of neuromorphic systems while maintaining their biological plausibility and computational advantages.Expand Specific Solutions04 Architectural optimization for specific applications
Specialized neuromorphic architectures designed for particular application domains such as computer vision, natural language processing, and real-time control systems. These optimized architectures incorporate domain-specific features that enhance performance for targeted tasks while maintaining the core principles of neuromorphic computing.Expand Specific Solutions05 Integration with conventional computing systems
Methods for effectively integrating neuromorphic components with traditional computing architectures to create hybrid systems. These approaches leverage the strengths of both paradigms, using neuromorphic elements for pattern recognition and learning while utilizing conventional processors for precise calculations and control. The integration includes hardware interfaces, software frameworks, and data conversion techniques.Expand Specific Solutions
Leading Companies and Research Institutions in Neuromorphic AI
Neuromorphic computing for AI tasks is currently in an early growth phase, characterized by significant research momentum but limited commercial deployment. The market is projected to expand rapidly, driven by edge AI applications requiring energy-efficient processing. Among key players, Intel leads with its Loihi chips, while IBM's TrueNorth architecture demonstrates mature neuromorphic principles. Specialized startups like Syntiant and SilicoSapien are advancing application-specific implementations, while Huawei is integrating neuromorphic elements into its AI strategy. Academic institutions (Tsinghua, KAIST, NUS) are contributing fundamental research, creating a competitive landscape where hardware optimization and software compatibility represent critical differentiation factors for market adoption.
International Business Machines Corp.
Technical Solution: IBM's TrueNorth neuromorphic architecture represents one of the most advanced implementations for AI optimization. The system features a million programmable neurons and 256 million configurable synapses arranged in 4,096 neurosynaptic cores. IBM has specifically designed this architecture to mimic the brain's structure, with each core containing memory, computation, and communication components that operate in parallel. For AI tasks, TrueNorth achieves remarkable energy efficiency at 70mW per chip while delivering 46 giga-synaptic operations per second per watt. IBM has further enhanced this platform with specialized programming frameworks like Corelet that allow developers to map neural network algorithms directly to the neuromorphic hardware. Recent advancements include the integration of spike-timing-dependent plasticity (STDP) for on-chip learning capabilities and the development of convolutional networks optimized for neuromorphic implementation, achieving up to 80% energy reduction compared to traditional GPU implementations for specific AI inference tasks.
Strengths: Exceptional energy efficiency (20x better than conventional architectures for certain tasks), high scalability through modular design, and mature programming tools. Weaknesses: Limited flexibility for non-spiking neural network models, higher initial implementation complexity compared to standard platforms, and challenges in training complex deep learning models directly on neuromorphic hardware.
Syntiant Corp.
Technical Solution: Syntiant has developed the Neural Decision Processor (NDP), a specialized neuromorphic architecture optimized for edge AI applications with a focus on audio and speech processing tasks. Their NDP100 and NDP200 series chips implement a unique memory-centric computing approach where computation occurs directly within memory structures, dramatically reducing the energy costs associated with data movement. This architecture enables always-on AI capabilities while consuming less than 1mW of power during active processing. Syntiant's solution incorporates a hardware-based spiking neural network implementation that processes information asynchronously, similar to biological neural systems. For keyword spotting and audio event detection AI tasks, their chips achieve 100x better energy efficiency compared to traditional MCU implementations. The company has further enhanced their platform with the NDP120, which supports multi-modal sensor fusion by combining audio processing with image and motion sensing capabilities. Their proprietary TinyML development environment allows for efficient deployment of compressed neural networks optimized for their neuromorphic hardware, with models typically requiring less than 500KB of memory while maintaining high accuracy for targeted applications.
Strengths: Ultra-low power consumption enabling always-on AI applications, specialized optimization for audio processing tasks, and seamless integration with existing edge device architectures. Weaknesses: Limited application scope beyond audio/speech domains, less flexibility for general-purpose AI workloads, and higher per-unit costs compared to general-purpose processors for high-volume applications.
Key Innovations in Spiking Neural Networks and Hardware
Neuromorphic system comprising waveguide extending into array
PatentWO2024172291A1
Innovation
- A neuromorphic system incorporating waveguides within a synapse array to transmit light pulses for weight adjustment and inference processes, enabling efficient computation through large-scale parallel connections and rapid weight adjustment using a passive optical matrix system.
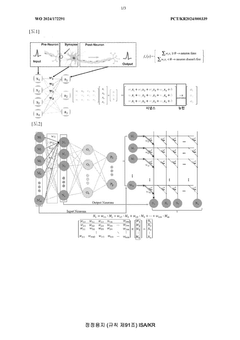
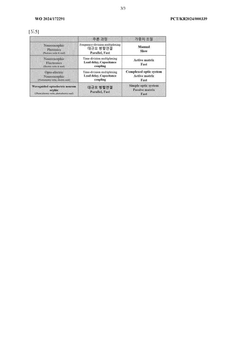
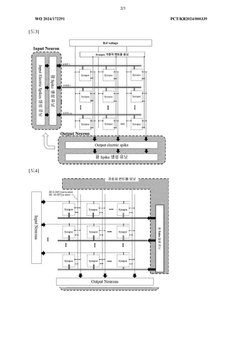

Neuromorphic computing: brain-inspired hardware for efficient ai processing
PatentPendingIN202411005149A
Innovation
- Neuromorphic computing systems mimic the brain's neural networks and synapses to enable parallel and adaptive processing, leveraging advances in neuroscience and hardware to create energy-efficient AI systems that can learn and adapt in real-time.
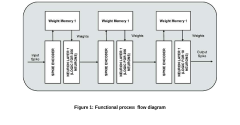
Energy Efficiency Benchmarks and Metrics
Energy efficiency has emerged as a critical benchmark in evaluating neuromorphic computing systems for AI applications. Traditional von Neumann architectures consume substantial power during data transfer between memory and processing units, creating a bottleneck known as the "memory wall." Neuromorphic systems address this challenge through their brain-inspired architecture, potentially offering orders of magnitude improvement in energy efficiency for specific AI workloads.
Current industry standards measure neuromorphic computing efficiency using metrics such as TOPS/W (Tera Operations Per Second per Watt), which quantifies computational throughput relative to power consumption. However, this metric alone proves insufficient for neuromorphic systems due to their fundamentally different computing paradigm. More specialized metrics include Synaptic Operations Per Second per Watt (SOPS/W) and energy per spike, which better capture the event-driven nature of neuromorphic computation.
Comparative benchmarking reveals significant advantages for neuromorphic hardware. Intel's Loihi chip demonstrates 1,000 times better energy efficiency than conventional GPUs for certain sparse network computations. IBM's TrueNorth architecture achieves remarkable power density at 20 mW/cm², operating at merely 0.1% of the power requirement of traditional processors for equivalent neural network implementations.
Application-specific energy metrics provide further insights into optimization opportunities. For instance, in edge computing scenarios, neuromorphic systems excel at always-on sensing tasks, consuming microwatts rather than milliwatts. For real-time image processing, SpiNNaker platforms demonstrate 10-100x energy improvements compared to GPU implementations, particularly for convolutional neural network operations.
Standardization efforts remain ongoing, with initiatives like the Neuromorphic Computing Benchmark Suite (NCBS) establishing consistent evaluation frameworks. These benchmarks incorporate diverse workloads including pattern recognition, anomaly detection, and temporal sequence learning—tasks where neuromorphic architectures demonstrate particular efficiency advantages.
Future optimization strategies must address the energy-accuracy tradeoff, as neuromorphic systems often sacrifice some computational precision for efficiency gains. Promising approaches include adaptive power management techniques that modulate spike thresholds based on task requirements, and hybrid architectures that selectively engage neuromorphic components for energy-intensive operations while utilizing conventional processors for precision-critical tasks.
Current industry standards measure neuromorphic computing efficiency using metrics such as TOPS/W (Tera Operations Per Second per Watt), which quantifies computational throughput relative to power consumption. However, this metric alone proves insufficient for neuromorphic systems due to their fundamentally different computing paradigm. More specialized metrics include Synaptic Operations Per Second per Watt (SOPS/W) and energy per spike, which better capture the event-driven nature of neuromorphic computation.
Comparative benchmarking reveals significant advantages for neuromorphic hardware. Intel's Loihi chip demonstrates 1,000 times better energy efficiency than conventional GPUs for certain sparse network computations. IBM's TrueNorth architecture achieves remarkable power density at 20 mW/cm², operating at merely 0.1% of the power requirement of traditional processors for equivalent neural network implementations.
Application-specific energy metrics provide further insights into optimization opportunities. For instance, in edge computing scenarios, neuromorphic systems excel at always-on sensing tasks, consuming microwatts rather than milliwatts. For real-time image processing, SpiNNaker platforms demonstrate 10-100x energy improvements compared to GPU implementations, particularly for convolutional neural network operations.
Standardization efforts remain ongoing, with initiatives like the Neuromorphic Computing Benchmark Suite (NCBS) establishing consistent evaluation frameworks. These benchmarks incorporate diverse workloads including pattern recognition, anomaly detection, and temporal sequence learning—tasks where neuromorphic architectures demonstrate particular efficiency advantages.
Future optimization strategies must address the energy-accuracy tradeoff, as neuromorphic systems often sacrifice some computational precision for efficiency gains. Promising approaches include adaptive power management techniques that modulate spike thresholds based on task requirements, and hybrid architectures that selectively engage neuromorphic components for energy-intensive operations while utilizing conventional processors for precision-critical tasks.
Integration Pathways with Traditional Computing Systems
The integration of neuromorphic computing with traditional computing architectures represents a critical pathway for maximizing the potential of brain-inspired computing in AI applications. Current integration approaches typically follow three main strategies: hybrid systems, accelerator models, and heterogeneous computing frameworks.
Hybrid systems combine neuromorphic processors with conventional CPUs and GPUs, allowing each architecture to handle the tasks it excels at. In these configurations, neuromorphic components typically manage pattern recognition, sensory processing, and other brain-like functions, while traditional processors handle precise mathematical operations and general-purpose computing. Intel's Loihi neuromorphic chip demonstrates this approach through its integration with x86 architectures, enabling seamless data exchange between neuromorphic and conventional computing domains.
Accelerator models position neuromorphic hardware as specialized co-processors within traditional computing environments. Similar to how GPUs accelerate graphics and parallel processing tasks, neuromorphic accelerators can be deployed for specific AI workloads such as real-time inference, continuous learning, and sparse data processing. This approach minimizes disruption to existing software ecosystems while providing significant energy efficiency gains for suitable workloads.
Heterogeneous computing frameworks provide the software infrastructure necessary for effective integration. These frameworks must address several challenges, including different programming paradigms, data format conversions, and synchronization between asynchronous neuromorphic operations and synchronous traditional computing. IBM's TrueNorth ecosystem exemplifies this approach with tools that facilitate the mapping of conventional deep learning models to neuromorphic architectures.
Communication interfaces between these disparate computing paradigms represent a significant technical challenge. Current solutions include specialized APIs, hardware bridges, and middleware layers that translate between spike-based neuromorphic representations and conventional binary data formats. The SpiNNaker platform demonstrates effective communication protocols that enable real-time interaction between neuromorphic systems and traditional computing environments.
Looking forward, the development of unified programming models presents perhaps the most promising path for seamless integration. These models abstract hardware differences, allowing developers to focus on algorithms rather than implementation details. The emergence of standards like PyNN and Nengo provides hardware-agnostic interfaces that can target both neuromorphic and conventional backends, potentially accelerating adoption across the computing spectrum.
Hybrid systems combine neuromorphic processors with conventional CPUs and GPUs, allowing each architecture to handle the tasks it excels at. In these configurations, neuromorphic components typically manage pattern recognition, sensory processing, and other brain-like functions, while traditional processors handle precise mathematical operations and general-purpose computing. Intel's Loihi neuromorphic chip demonstrates this approach through its integration with x86 architectures, enabling seamless data exchange between neuromorphic and conventional computing domains.
Accelerator models position neuromorphic hardware as specialized co-processors within traditional computing environments. Similar to how GPUs accelerate graphics and parallel processing tasks, neuromorphic accelerators can be deployed for specific AI workloads such as real-time inference, continuous learning, and sparse data processing. This approach minimizes disruption to existing software ecosystems while providing significant energy efficiency gains for suitable workloads.
Heterogeneous computing frameworks provide the software infrastructure necessary for effective integration. These frameworks must address several challenges, including different programming paradigms, data format conversions, and synchronization between asynchronous neuromorphic operations and synchronous traditional computing. IBM's TrueNorth ecosystem exemplifies this approach with tools that facilitate the mapping of conventional deep learning models to neuromorphic architectures.
Communication interfaces between these disparate computing paradigms represent a significant technical challenge. Current solutions include specialized APIs, hardware bridges, and middleware layers that translate between spike-based neuromorphic representations and conventional binary data formats. The SpiNNaker platform demonstrates effective communication protocols that enable real-time interaction between neuromorphic systems and traditional computing environments.
Looking forward, the development of unified programming models presents perhaps the most promising path for seamless integration. These models abstract hardware differences, allowing developers to focus on algorithms rather than implementation details. The emergence of standards like PyNN and Nengo provides hardware-agnostic interfaces that can target both neuromorphic and conventional backends, potentially accelerating adoption across the computing spectrum.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!