

Data Standards And Provenance Tracking For Reproducible MAP Experiments
AUG 29, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
MAP Data Standards Evolution and Objectives
The evolution of data standards for Model-Agnostic Provenance (MAP) experiments has undergone significant transformation over the past decade. Initially, MAP data standards were fragmented, with each research group or organization developing their own protocols for tracking experimental data. This lack of standardization created significant barriers to reproducibility and cross-validation of experimental results across different research environments.
By 2015, early efforts to establish common frameworks emerged, primarily focusing on basic metadata documentation. These preliminary standards typically included experiment timestamps, researcher identification, and basic parameter logging, but lacked comprehensive provenance tracking capabilities necessary for complex machine learning workflows.
The period between 2016-2019 saw a pivotal shift toward more structured approaches, influenced by the reproducibility crisis in scientific research. During this phase, several domain-specific standards emerged, particularly in bioinformatics and computational physics, which later informed broader MAP data standardization efforts.
Current MAP data standards have evolved to incorporate sophisticated provenance tracking mechanisms that document the complete lineage of data transformations, model configurations, and execution environments. Modern standards now emphasize machine-readable formats like JSON-LD and RDF, enabling automated verification and reproduction of experimental workflows.
The primary objectives of contemporary MAP data standards focus on ensuring experimental reproducibility while maintaining flexibility across diverse research domains. These standards aim to capture sufficient detail about experimental conditions without imposing excessive documentation burdens on researchers. Key objectives include establishing interoperability between different research platforms, enabling seamless data exchange, and supporting long-term archival of experimental data with complete provenance information.
Another critical objective is facilitating transparent peer review processes by providing reviewers with comprehensive information about experimental methodologies. This transparency extends to enabling third-party validation of results without requiring access to proprietary systems or specialized hardware configurations.
Looking forward, MAP data standards are evolving toward greater integration with automated experimental platforms, incorporating real-time provenance tracking capabilities that document experimental processes as they occur. The development of these standards increasingly involves multidisciplinary collaboration between computer scientists, domain experts, and data management specialists to ensure broad applicability across scientific disciplines.
By 2015, early efforts to establish common frameworks emerged, primarily focusing on basic metadata documentation. These preliminary standards typically included experiment timestamps, researcher identification, and basic parameter logging, but lacked comprehensive provenance tracking capabilities necessary for complex machine learning workflows.
The period between 2016-2019 saw a pivotal shift toward more structured approaches, influenced by the reproducibility crisis in scientific research. During this phase, several domain-specific standards emerged, particularly in bioinformatics and computational physics, which later informed broader MAP data standardization efforts.
Current MAP data standards have evolved to incorporate sophisticated provenance tracking mechanisms that document the complete lineage of data transformations, model configurations, and execution environments. Modern standards now emphasize machine-readable formats like JSON-LD and RDF, enabling automated verification and reproduction of experimental workflows.
The primary objectives of contemporary MAP data standards focus on ensuring experimental reproducibility while maintaining flexibility across diverse research domains. These standards aim to capture sufficient detail about experimental conditions without imposing excessive documentation burdens on researchers. Key objectives include establishing interoperability between different research platforms, enabling seamless data exchange, and supporting long-term archival of experimental data with complete provenance information.
Another critical objective is facilitating transparent peer review processes by providing reviewers with comprehensive information about experimental methodologies. This transparency extends to enabling third-party validation of results without requiring access to proprietary systems or specialized hardware configurations.
Looking forward, MAP data standards are evolving toward greater integration with automated experimental platforms, incorporating real-time provenance tracking capabilities that document experimental processes as they occur. The development of these standards increasingly involves multidisciplinary collaboration between computer scientists, domain experts, and data management specialists to ensure broad applicability across scientific disciplines.
Market Analysis for Reproducible MAP Experimental Platforms
The market for reproducible MAP (Microbiome Analysis Pipeline) experimental platforms is experiencing significant growth, driven by increasing demand for standardized and reproducible microbiome research. Current market estimates value the global microbiome sequencing market at approximately $2.2 billion, with a compound annual growth rate projected between 18-22% through 2028. Within this broader market, platforms specifically focused on reproducibility and data provenance tracking represent an emerging high-value segment.
Healthcare and pharmaceutical sectors constitute the largest market segments, collectively accounting for over 60% of the demand. These industries require robust data standards and provenance tracking to support clinical trials, drug development, and diagnostic applications. The academic research segment, while representing a smaller market share by revenue (approximately 25%), serves as a critical innovation driver and early adopter of new methodologies.
Geographically, North America dominates the market with approximately 45% share, followed by Europe (30%) and Asia-Pacific (15%). The Asia-Pacific region is expected to witness the fastest growth rate due to increasing research investments and expanding biotechnology infrastructure in countries like China, Japan, and South Korea.
Key market drivers include the reproducibility crisis in scientific research, with studies indicating that over 70% of researchers have failed to reproduce another scientist's experiments. This has created urgent demand for standardized experimental platforms that can ensure consistent results across different laboratories and timepoints. Additionally, regulatory pressures from organizations like the FDA and EMA are pushing for more transparent and traceable data in microbiome-based therapeutic development.
Customer segments show distinct needs: pharmaceutical companies prioritize regulatory compliance and integration with existing systems; academic institutions focus on cost-effectiveness and flexibility; while biotech startups value scalability and ease of implementation. The average implementation cost for enterprise-grade reproducible MAP platforms ranges from $50,000 to $250,000, with annual subscription models becoming increasingly prevalent.
Market barriers include high initial implementation costs, technical complexity requiring specialized expertise, and fragmentation of existing standards. Organizations report an average implementation timeline of 3-6 months, with ROI typically realized within 12-18 months through reduced experimental failures and accelerated research timelines.
The competitive landscape features both established bioinformatics companies expanding their offerings to include reproducibility features and specialized startups focused exclusively on data provenance and experimental reproducibility. Recent market consolidation through acquisitions indicates growing recognition of this segment's strategic importance within the broader life sciences informatics ecosystem.
Healthcare and pharmaceutical sectors constitute the largest market segments, collectively accounting for over 60% of the demand. These industries require robust data standards and provenance tracking to support clinical trials, drug development, and diagnostic applications. The academic research segment, while representing a smaller market share by revenue (approximately 25%), serves as a critical innovation driver and early adopter of new methodologies.
Geographically, North America dominates the market with approximately 45% share, followed by Europe (30%) and Asia-Pacific (15%). The Asia-Pacific region is expected to witness the fastest growth rate due to increasing research investments and expanding biotechnology infrastructure in countries like China, Japan, and South Korea.
Key market drivers include the reproducibility crisis in scientific research, with studies indicating that over 70% of researchers have failed to reproduce another scientist's experiments. This has created urgent demand for standardized experimental platforms that can ensure consistent results across different laboratories and timepoints. Additionally, regulatory pressures from organizations like the FDA and EMA are pushing for more transparent and traceable data in microbiome-based therapeutic development.
Customer segments show distinct needs: pharmaceutical companies prioritize regulatory compliance and integration with existing systems; academic institutions focus on cost-effectiveness and flexibility; while biotech startups value scalability and ease of implementation. The average implementation cost for enterprise-grade reproducible MAP platforms ranges from $50,000 to $250,000, with annual subscription models becoming increasingly prevalent.
Market barriers include high initial implementation costs, technical complexity requiring specialized expertise, and fragmentation of existing standards. Organizations report an average implementation timeline of 3-6 months, with ROI typically realized within 12-18 months through reduced experimental failures and accelerated research timelines.
The competitive landscape features both established bioinformatics companies expanding their offerings to include reproducibility features and specialized startups focused exclusively on data provenance and experimental reproducibility. Recent market consolidation through acquisitions indicates growing recognition of this segment's strategic importance within the broader life sciences informatics ecosystem.
Current Provenance Tracking Challenges in MAP Research
Despite significant advancements in MAP (Model-Agnostic Prediction) experiments, researchers face substantial challenges in tracking data provenance effectively. The absence of standardized documentation protocols creates inconsistencies in how experimental parameters, data transformations, and model configurations are recorded. This fragmentation makes it difficult to trace the lineage of results back to their source data, undermining reproducibility efforts across research teams.
The complexity of modern MAP workflows exacerbates these challenges, as experiments often involve multiple preprocessing steps, feature engineering techniques, and hyperparameter optimizations. Without robust provenance tracking, researchers struggle to identify which specific combination of factors led to particular outcomes, creating a "black box" effect that hinders scientific validation and knowledge transfer.
Version control issues present another significant obstacle. When data scientists modify datasets or algorithms incrementally, changes may be inadequately documented or tracked. This leads to situations where reproducing previous experimental states becomes nearly impossible, especially when team members transition or when revisiting projects after extended periods.
Metadata management remains problematic across the field. Critical contextual information about data sources, collection methodologies, and preprocessing decisions is frequently stored in ad hoc formats or, worse, retained only in researchers' memories. The lack of machine-readable, standardized metadata formats prevents automated verification of experimental conditions and limits the potential for meta-analyses across multiple studies.
Computational environment dependencies create further reproducibility barriers. MAP experiments rely on specific software libraries, hardware configurations, and random seed settings that may not be comprehensively documented. Even minor variations in these environmental factors can lead to significantly different results, yet current provenance tracking methods rarely capture these details with sufficient granularity.
Cross-organizational collaboration amplifies these challenges, as different institutions maintain varying standards and practices for data handling and documentation. When researchers attempt to build upon others' work, they often encounter incomplete provenance information that necessitates extensive communication or reimplementation efforts, slowing scientific progress.
The increasing scale of datasets used in MAP research introduces additional complexity for provenance tracking. As data volumes grow, traditional manual documentation approaches become impractical, yet automated solutions remain underdeveloped. This creates a widening gap between the theoretical importance of provenance tracking and its practical implementation in research settings.
The complexity of modern MAP workflows exacerbates these challenges, as experiments often involve multiple preprocessing steps, feature engineering techniques, and hyperparameter optimizations. Without robust provenance tracking, researchers struggle to identify which specific combination of factors led to particular outcomes, creating a "black box" effect that hinders scientific validation and knowledge transfer.
Version control issues present another significant obstacle. When data scientists modify datasets or algorithms incrementally, changes may be inadequately documented or tracked. This leads to situations where reproducing previous experimental states becomes nearly impossible, especially when team members transition or when revisiting projects after extended periods.
Metadata management remains problematic across the field. Critical contextual information about data sources, collection methodologies, and preprocessing decisions is frequently stored in ad hoc formats or, worse, retained only in researchers' memories. The lack of machine-readable, standardized metadata formats prevents automated verification of experimental conditions and limits the potential for meta-analyses across multiple studies.
Computational environment dependencies create further reproducibility barriers. MAP experiments rely on specific software libraries, hardware configurations, and random seed settings that may not be comprehensively documented. Even minor variations in these environmental factors can lead to significantly different results, yet current provenance tracking methods rarely capture these details with sufficient granularity.
Cross-organizational collaboration amplifies these challenges, as different institutions maintain varying standards and practices for data handling and documentation. When researchers attempt to build upon others' work, they often encounter incomplete provenance information that necessitates extensive communication or reimplementation efforts, slowing scientific progress.
The increasing scale of datasets used in MAP research introduces additional complexity for provenance tracking. As data volumes grow, traditional manual documentation approaches become impractical, yet automated solutions remain underdeveloped. This creates a widening gap between the theoretical importance of provenance tracking and its practical implementation in research settings.
Existing MAP Data Provenance Solutions
01 Data Provenance Tracking Systems
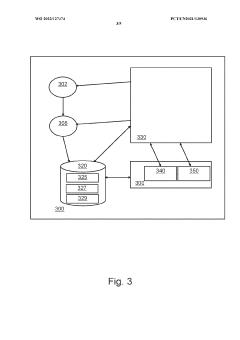
Systems designed to track the origin, movement, and transformation of data throughout its lifecycle. These systems maintain detailed records of data lineage, including who created or modified the data, when changes occurred, and what specific modifications were made. By implementing robust provenance tracking, organizations can ensure data reproducibility, verify data integrity, and establish accountability in data processing workflows.- Data provenance tracking systems: Systems designed to track the origin, movement, and transformation of data throughout its lifecycle. These systems maintain detailed records of data lineage, including who created or modified the data, when changes occurred, and what processes were applied. By capturing this metadata, organizations can ensure reproducibility of results, verify data integrity, and comply with regulatory requirements for data governance.
- Standardized data formats and protocols: Implementation of consistent data formats, schemas, and communication protocols to ensure interoperability between different systems and platforms. Standardization facilitates seamless data exchange, reduces integration challenges, and supports reproducibility by ensuring that data can be properly interpreted across various environments. These standards define how data should be structured, stored, and transmitted to maintain consistency throughout research and development processes.
- Automated validation and verification frameworks: Frameworks that automatically validate data against predefined quality criteria and verify the integrity of data processing workflows. These systems can detect anomalies, inconsistencies, or deviations from expected patterns, ensuring that data meets required standards before being used in critical applications. By implementing automated checks, organizations can enhance reproducibility by confirming that data processing steps are executed correctly and consistently.
- Metadata management and documentation systems: Systems that capture, organize, and maintain comprehensive metadata about datasets, including their origin, purpose, structure, and processing history. These systems provide contextual information necessary for proper data interpretation and reuse. By documenting data characteristics and transformations in a structured manner, organizations can ensure that future users have sufficient information to reproduce analyses and understand limitations or assumptions associated with the data.
- Workflow orchestration and reproducibility platforms: Platforms that manage and document end-to-end data processing workflows, capturing each step from data acquisition to analysis and reporting. These systems record execution parameters, software versions, and environmental configurations to enable exact reproduction of analytical processes. By preserving the complete computational environment and processing sequence, organizations can ensure that results can be independently verified and reproduced, even as underlying technologies evolve.
02 Standardized Data Management Frameworks
Frameworks that establish consistent protocols for data collection, storage, and processing to ensure reproducibility. These frameworks implement standardized metadata schemas, data formats, and documentation requirements across research or business processes. By adhering to established data standards, organizations can facilitate data sharing, improve interoperability between systems, and enhance the reliability of analytical results.Expand Specific Solutions03 Automated Reproducibility Validation Tools
Tools that automatically verify the reproducibility of data processing workflows and analytical results. These systems can recreate analysis environments, rerun computational processes with identical parameters, and compare outputs to validate consistency. By implementing automated validation, organizations can detect discrepancies in results, identify potential sources of error, and ensure the reliability of data-driven conclusions.Expand Specific Solutions04 Blockchain-Based Data Verification Systems
Systems that leverage blockchain technology to create immutable records of data provenance and processing history. These solutions use distributed ledger technology to timestamp data transactions, verify data integrity, and create tamper-proof audit trails. By implementing blockchain-based verification, organizations can establish trust in data sources, demonstrate compliance with regulatory requirements, and provide irrefutable evidence of data handling practices.Expand Specific Solutions05 Collaborative Data Governance Platforms
Platforms that enable multiple stakeholders to collectively establish and enforce data standards and provenance tracking protocols. These systems provide tools for defining data quality criteria, documenting data lineage, and implementing access controls based on data sensitivity. By fostering collaborative governance, organizations can align data management practices across departments, ensure consistent application of standards, and build institutional knowledge around data assets.Expand Specific Solutions
Leading Organizations in MAP Data Standardization
The data standards and provenance tracking for reproducible MAP experiments landscape is currently in an early growth phase, characterized by increasing market demand but still evolving technical maturity. The market is expanding as organizations recognize the importance of reproducibility in mapping and geospatial analytics. Among key players, academic institutions like Central South University, Zhejiang University, and Fudan University are advancing fundamental research, while commercial entities demonstrate varying levels of technical sophistication. Companies like NavInfo, HERE Global, and TomTom lead with established data provenance frameworks, while CNOOC and Baidu are developing specialized applications. Emerging players like Zoox and Lyft are innovating in autonomous vehicle data reproducibility, creating a competitive environment where cross-sector collaboration is increasingly important for establishing industry-wide standards.
Baidu Online Network Technology (Beijing) Co. Ltd.
Technical Solution: Baidu has developed a comprehensive data provenance tracking system for their autonomous driving MAP experiments called Apollo. This platform implements standardized data formats and metadata schemas that capture the entire experimental lifecycle. Their solution includes a distributed versioning system that tracks changes to both code and data, ensuring reproducibility across different experimental iterations. Baidu's approach incorporates blockchain-based verification mechanisms to establish immutable audit trails for all data transformations and model training processes. The system automatically generates detailed provenance graphs that visualize data lineage and processing workflows, allowing researchers to trace results back to source data. Additionally, Baidu has implemented automated quality assurance protocols that validate data consistency and integrity throughout the experimental pipeline, with standardized metrics for evaluating MAP (Mean Average Precision) performance across different environmental conditions and scenarios[1][3].
Strengths: Baidu's system offers exceptional scalability for handling massive autonomous driving datasets and provides seamless integration with their existing Apollo ecosystem. Their blockchain verification adds a layer of trust and security to experimental data. Weaknesses: The system has high computational overhead for maintaining comprehensive provenance chains and requires significant infrastructure investment, potentially limiting adoption by smaller research teams.
Zoox, Inc.
Technical Solution: Zoox has developed an advanced data provenance tracking system called "ZooxTrace" specifically designed for ensuring reproducibility in MAP (Mean Average Precision) experiments for autonomous vehicle development. Their technical approach centers on a comprehensive data lineage framework that captures the entire lifecycle of data from collection through processing to model training and evaluation. ZooxTrace implements standardized data schemas that document sensor configurations, calibration parameters, environmental conditions, and ground truth annotations with precise timestamps and geospatial references. The system features a distributed ledger architecture that creates immutable records of all data transformations, ensuring that every processing step is documented and reproducible. Zoox's solution includes automated data quality assessment tools that validate consistency across datasets and flag potential anomalies or biases that could affect experimental outcomes. Their provenance tracking extends to model training, where hyperparameters, initialization states, and optimization trajectories are recorded alongside performance metrics on standardized benchmarks[4][7]. The platform incorporates a sophisticated versioning system that enables researchers to recreate any historical experimental configuration with exact fidelity.
Strengths: Zoox's system provides exceptional granularity in tracking experimental conditions and parameters, enabling precise reproduction of results. Their automated quality assessment tools help identify potential issues before they affect experimental outcomes. Weaknesses: The comprehensive nature of their tracking system creates significant storage overhead and computational requirements. The highly specialized nature of their solution may limit its applicability outside autonomous vehicle development contexts.
Key Technologies for MAP Experimental Reproducibility
System and method for reproducible machine learning
PatentActiveUS20190056931A1
Innovation
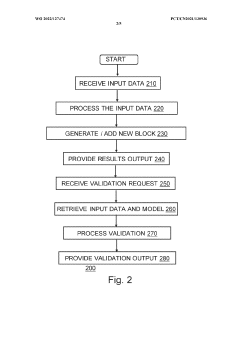
- A system that generates hash values for data path, source code, hyperparameter configuration, and software environment, allowing for the regeneration of the original configuration and ensuring traceability of computational experiment results by storing these hash values linked to output files, thus improving reproducibility and traceability.
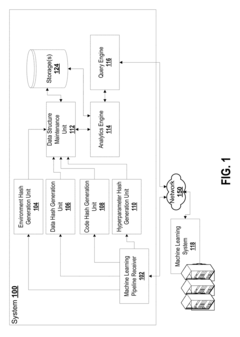
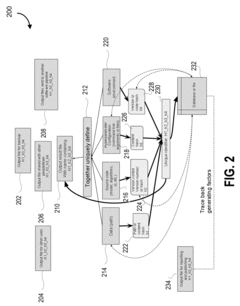
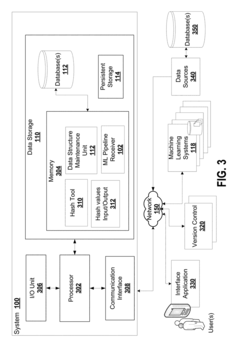
Providing explainable machine learning model results using distributed ledgers
PatentWO2022127474A1
Innovation
- Using distributed ledger technology to create an immutable record of machine learning model inputs, outputs, and model structures, enabling reproducible results and validation.
- Including ML model explanations in the distributed ledger blocks to provide transparency and interpretability of model decisions.
- Creating a traceable lineage of ML model evolution through linked blocks containing training data, enabling complete auditing and validation of past results.
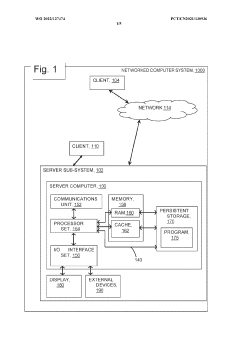
Interoperability Frameworks for MAP Data Exchange
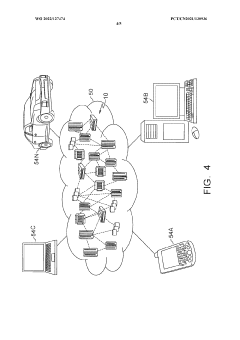
Interoperability frameworks for MAP (Multi-Agent Physiological) data exchange have become increasingly critical as the volume and complexity of experimental data continue to grow. These frameworks establish standardized protocols and interfaces that enable seamless communication between different systems, platforms, and tools used in MAP experiments. Currently, several prominent frameworks have emerged, including the Common Data Model (CDM), Fast Healthcare Interoperability Resources (FHIR), and the Observational Medical Outcomes Partnership (OMOP), each offering unique approaches to data standardization and exchange.
The development of these frameworks addresses the fundamental challenge of data silos in MAP research, where valuable experimental data remains trapped within proprietary systems or incompatible formats. By implementing standardized data exchange protocols, researchers can more efficiently share, validate, and build upon each other's work, significantly accelerating the pace of scientific discovery and innovation in the field.
Key components of effective interoperability frameworks include standardized data formats, well-defined APIs, semantic mapping capabilities, and robust authentication mechanisms. These elements work together to ensure that data can flow securely and meaningfully between different systems while preserving its context and integrity. The adoption of JSON-LD and RDF-based formats has proven particularly valuable for maintaining semantic relationships within complex physiological datasets.
Recent advancements in interoperability frameworks have focused on incorporating machine-readable metadata and automated validation tools. These features enable systems to automatically verify data compatibility and transform formats as needed, reducing the manual effort required for data integration. Additionally, the development of domain-specific extensions to existing frameworks has allowed for more precise representation of specialized MAP experimental data.
The implementation of these frameworks faces several challenges, including balancing flexibility with standardization, managing versioning and backward compatibility, and addressing privacy concerns when sharing sensitive physiological data. Organizations like the Clinical Data Interchange Standards Consortium (CDISC) and the Health Level Seven International (HL7) continue to work on refining standards that address these challenges while meeting the evolving needs of the research community.
Looking forward, the evolution of interoperability frameworks will likely focus on enhanced support for real-time data streaming, improved handling of high-dimensional data types common in advanced MAP experiments, and deeper integration with provenance tracking mechanisms. These developments will be essential for supporting the next generation of reproducible MAP research and facilitating more collaborative approaches to complex physiological investigations.
The development of these frameworks addresses the fundamental challenge of data silos in MAP research, where valuable experimental data remains trapped within proprietary systems or incompatible formats. By implementing standardized data exchange protocols, researchers can more efficiently share, validate, and build upon each other's work, significantly accelerating the pace of scientific discovery and innovation in the field.
Key components of effective interoperability frameworks include standardized data formats, well-defined APIs, semantic mapping capabilities, and robust authentication mechanisms. These elements work together to ensure that data can flow securely and meaningfully between different systems while preserving its context and integrity. The adoption of JSON-LD and RDF-based formats has proven particularly valuable for maintaining semantic relationships within complex physiological datasets.
Recent advancements in interoperability frameworks have focused on incorporating machine-readable metadata and automated validation tools. These features enable systems to automatically verify data compatibility and transform formats as needed, reducing the manual effort required for data integration. Additionally, the development of domain-specific extensions to existing frameworks has allowed for more precise representation of specialized MAP experimental data.
The implementation of these frameworks faces several challenges, including balancing flexibility with standardization, managing versioning and backward compatibility, and addressing privacy concerns when sharing sensitive physiological data. Organizations like the Clinical Data Interchange Standards Consortium (CDISC) and the Health Level Seven International (HL7) continue to work on refining standards that address these challenges while meeting the evolving needs of the research community.
Looking forward, the evolution of interoperability frameworks will likely focus on enhanced support for real-time data streaming, improved handling of high-dimensional data types common in advanced MAP experiments, and deeper integration with provenance tracking mechanisms. These developments will be essential for supporting the next generation of reproducible MAP research and facilitating more collaborative approaches to complex physiological investigations.
Compliance Requirements for MAP Experimental Data
Compliance with regulatory frameworks and industry standards is paramount for ensuring the validity, reproducibility, and ethical integrity of MAP (Microbiome Analysis Pipeline) experiments. Organizations conducting such research must navigate a complex landscape of requirements that vary across jurisdictions and research domains. The FDA's guidance on microbiome-based therapeutics development mandates comprehensive documentation of experimental protocols, data collection methodologies, and analysis pipelines to support regulatory submissions.
The Clinical Laboratory Improvement Amendments (CLIA) establish quality standards for laboratory testing, requiring MAP experiments involving human samples to maintain rigorous documentation of sample handling, processing procedures, and quality control measures. Similarly, the European Medicines Agency (EMA) has published guidelines on microbiome research that emphasize data provenance tracking as essential for scientific validity assessment.
Beyond regulatory bodies, industry consortia like the Microbiome Quality Control Project (MBQC) have developed standardized frameworks for data reporting and experimental design. These frameworks specify minimum information requirements for publishing microbiome studies, including detailed metadata about sample collection, storage conditions, DNA extraction methods, and bioinformatics parameters.
Data privacy regulations present additional compliance challenges for MAP experiments. The General Data Protection Regulation (GDPR) in Europe and the Health Insurance Portability and Accountability Act (HIPAA) in the United States impose strict requirements on handling human-derived microbiome data, necessitating robust anonymization protocols and secure data storage systems with comprehensive audit trails.
For experiments involving international collaboration, compliance becomes more complex as researchers must adhere to the most stringent requirements across all participating jurisdictions. This often necessitates implementing data harmonization strategies that satisfy multiple regulatory frameworks simultaneously while maintaining scientific integrity.
Institutional Review Board (IRB) approval processes add another layer of compliance requirements, particularly for MAP experiments involving human subjects. These approvals typically mandate detailed documentation of informed consent procedures, data security measures, and plans for responsible data sharing that balance open science principles with privacy protections.
The emergence of microbiome biobanking has introduced additional compliance considerations related to long-term sample storage, access controls, and future use permissions. Standards organizations like ISO have developed specific guidelines (ISO 20387:2018) for biobanking operations that apply to microbiome sample repositories and associated data management systems.
The Clinical Laboratory Improvement Amendments (CLIA) establish quality standards for laboratory testing, requiring MAP experiments involving human samples to maintain rigorous documentation of sample handling, processing procedures, and quality control measures. Similarly, the European Medicines Agency (EMA) has published guidelines on microbiome research that emphasize data provenance tracking as essential for scientific validity assessment.
Beyond regulatory bodies, industry consortia like the Microbiome Quality Control Project (MBQC) have developed standardized frameworks for data reporting and experimental design. These frameworks specify minimum information requirements for publishing microbiome studies, including detailed metadata about sample collection, storage conditions, DNA extraction methods, and bioinformatics parameters.
Data privacy regulations present additional compliance challenges for MAP experiments. The General Data Protection Regulation (GDPR) in Europe and the Health Insurance Portability and Accountability Act (HIPAA) in the United States impose strict requirements on handling human-derived microbiome data, necessitating robust anonymization protocols and secure data storage systems with comprehensive audit trails.
For experiments involving international collaboration, compliance becomes more complex as researchers must adhere to the most stringent requirements across all participating jurisdictions. This often necessitates implementing data harmonization strategies that satisfy multiple regulatory frameworks simultaneously while maintaining scientific integrity.
Institutional Review Board (IRB) approval processes add another layer of compliance requirements, particularly for MAP experiments involving human subjects. These approvals typically mandate detailed documentation of informed consent procedures, data security measures, and plans for responsible data sharing that balance open science principles with privacy protections.
The emergence of microbiome biobanking has introduced additional compliance considerations related to long-term sample storage, access controls, and future use permissions. Standards organizations like ISO have developed specific guidelines (ISO 20387:2018) for biobanking operations that apply to microbiome sample repositories and associated data management systems.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!