How to Improve DDR5 Response Times in Machine Learning Algorithms
SEP 17, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DDR5 Memory Evolution and Performance Goals
DDR5 memory represents a significant evolution in DRAM technology, building upon the foundations established by previous generations while introducing substantial architectural improvements. Since its introduction in 2020, DDR5 has marked a pivotal shift in memory performance capabilities, offering initial speeds of 4800 MT/s compared to DDR4's typical 3200 MT/s. The technology roadmap projects continued advancement, with speeds potentially reaching 8400 MT/s by 2024, representing a transformative leap in data transfer capabilities.
The evolutionary trajectory of DDR5 has been characterized by several key innovations aimed at addressing the growing demands of data-intensive applications, particularly machine learning workloads. These include the implementation of dual-channel architecture within a single module, effectively doubling the memory bandwidth without increasing pin count. Additionally, the transition from 16-bit to 32-bit channels has significantly enhanced data throughput capabilities.
Response time optimization stands as a critical performance goal for DDR5 in machine learning contexts. Current DDR5 modules exhibit CAS latencies ranging from CL40 to CL46 at 4800 MT/s, which, despite higher absolute values compared to DDR4, deliver improved effective access times due to increased clock frequencies. The industry aims to reduce these latencies while maintaining or increasing transfer rates, with particular focus on optimizing tRCD (RAS to CAS Delay) and tRP (Row Precharge Time) parameters.
Power efficiency represents another fundamental goal in DDR5 evolution, with the technology shifting from 1.2V to 1.1V operating voltage while implementing on-die voltage regulation. This architectural change not only reduces power consumption but also enables more stable operation at higher frequencies, which is particularly beneficial for sustained machine learning training operations that place continuous demands on memory systems.
Signal integrity improvements constitute a third major performance objective, with DDR5 implementing Decision Feedback Equalization (DFE) and enhanced on-die termination. These features are specifically designed to maintain data integrity at higher frequencies, reducing error rates that can significantly impact machine learning algorithm accuracy and training stability.
The industry's long-term vision for DDR5 encompasses achieving sub-10ns effective access times while supporting bandwidth exceeding 400 GB/s per memory controller. This ambitious goal aligns with the exponentially growing parameter counts in modern machine learning models, which have increased memory bandwidth and latency sensitivity by orders of magnitude compared to previous generation algorithms.
The evolutionary trajectory of DDR5 has been characterized by several key innovations aimed at addressing the growing demands of data-intensive applications, particularly machine learning workloads. These include the implementation of dual-channel architecture within a single module, effectively doubling the memory bandwidth without increasing pin count. Additionally, the transition from 16-bit to 32-bit channels has significantly enhanced data throughput capabilities.
Response time optimization stands as a critical performance goal for DDR5 in machine learning contexts. Current DDR5 modules exhibit CAS latencies ranging from CL40 to CL46 at 4800 MT/s, which, despite higher absolute values compared to DDR4, deliver improved effective access times due to increased clock frequencies. The industry aims to reduce these latencies while maintaining or increasing transfer rates, with particular focus on optimizing tRCD (RAS to CAS Delay) and tRP (Row Precharge Time) parameters.
Power efficiency represents another fundamental goal in DDR5 evolution, with the technology shifting from 1.2V to 1.1V operating voltage while implementing on-die voltage regulation. This architectural change not only reduces power consumption but also enables more stable operation at higher frequencies, which is particularly beneficial for sustained machine learning training operations that place continuous demands on memory systems.
Signal integrity improvements constitute a third major performance objective, with DDR5 implementing Decision Feedback Equalization (DFE) and enhanced on-die termination. These features are specifically designed to maintain data integrity at higher frequencies, reducing error rates that can significantly impact machine learning algorithm accuracy and training stability.
The industry's long-term vision for DDR5 encompasses achieving sub-10ns effective access times while supporting bandwidth exceeding 400 GB/s per memory controller. This ambitious goal aligns with the exponentially growing parameter counts in modern machine learning models, which have increased memory bandwidth and latency sensitivity by orders of magnitude compared to previous generation algorithms.
Market Demand Analysis for ML Memory Optimization
The machine learning industry is experiencing unprecedented growth, with the global AI market projected to reach $190 billion by 2025, growing at a CAGR of 37%. This explosive expansion has created significant demand for memory optimization solutions, particularly for DDR5 response times in ML algorithms. As computational requirements for training and inference continue to escalate, memory performance has emerged as a critical bottleneck in system architecture.
Market research indicates that over 65% of enterprise AI deployments cite memory performance as a significant constraint on their ML workloads. The demand for faster memory response times is particularly acute in real-time applications such as autonomous vehicles, financial trading algorithms, and medical diagnostic systems where millisecond delays can have substantial consequences.
Cloud service providers represent the largest market segment seeking DDR5 optimization, with Amazon Web Services, Microsoft Azure, and Google Cloud Platform all investing heavily in memory-optimized instances specifically designed for ML workloads. These providers collectively serve over 80% of enterprise ML deployments and are driving significant demand for improved memory technologies.
The financial services sector constitutes another major market, with high-frequency trading firms willing to pay premium prices for even marginal improvements in memory response times. Research indicates that a 10% improvement in memory latency can translate to approximately 3-5% improvement in trading algorithm performance, representing millions in potential revenue for these firms.
Healthcare and pharmaceutical companies form an emerging market segment, particularly for drug discovery applications where complex molecular simulations require massive memory bandwidth. The COVID-19 pandemic has accelerated this trend, with pharmaceutical companies increasing their AI infrastructure investments by 45% since 2020.
Edge computing represents the fastest-growing market segment, with projections indicating a 54% annual growth rate through 2026. As ML models are increasingly deployed on edge devices with limited resources, memory optimization becomes critical for maintaining acceptable performance while operating within power and thermal constraints.
From a geographical perspective, North America currently leads demand with approximately 42% market share, followed by Asia-Pacific at 31% and Europe at 22%. However, the Asia-Pacific region is experiencing the fastest growth rate, driven primarily by China's aggressive investments in AI infrastructure and research.
Customer surveys reveal that organizations are willing to pay 15-20% premiums for solutions that can demonstrably improve DDR5 response times for ML workloads, highlighting the significant market opportunity for innovations in this space.
Market research indicates that over 65% of enterprise AI deployments cite memory performance as a significant constraint on their ML workloads. The demand for faster memory response times is particularly acute in real-time applications such as autonomous vehicles, financial trading algorithms, and medical diagnostic systems where millisecond delays can have substantial consequences.
Cloud service providers represent the largest market segment seeking DDR5 optimization, with Amazon Web Services, Microsoft Azure, and Google Cloud Platform all investing heavily in memory-optimized instances specifically designed for ML workloads. These providers collectively serve over 80% of enterprise ML deployments and are driving significant demand for improved memory technologies.
The financial services sector constitutes another major market, with high-frequency trading firms willing to pay premium prices for even marginal improvements in memory response times. Research indicates that a 10% improvement in memory latency can translate to approximately 3-5% improvement in trading algorithm performance, representing millions in potential revenue for these firms.
Healthcare and pharmaceutical companies form an emerging market segment, particularly for drug discovery applications where complex molecular simulations require massive memory bandwidth. The COVID-19 pandemic has accelerated this trend, with pharmaceutical companies increasing their AI infrastructure investments by 45% since 2020.
Edge computing represents the fastest-growing market segment, with projections indicating a 54% annual growth rate through 2026. As ML models are increasingly deployed on edge devices with limited resources, memory optimization becomes critical for maintaining acceptable performance while operating within power and thermal constraints.
From a geographical perspective, North America currently leads demand with approximately 42% market share, followed by Asia-Pacific at 31% and Europe at 22%. However, the Asia-Pacific region is experiencing the fastest growth rate, driven primarily by China's aggressive investments in AI infrastructure and research.
Customer surveys reveal that organizations are willing to pay 15-20% premiums for solutions that can demonstrably improve DDR5 response times for ML workloads, highlighting the significant market opportunity for innovations in this space.
DDR5 Latency Challenges in ML Workloads
Machine learning workloads are increasingly demanding faster memory access to process large datasets efficiently. DDR5 memory, while offering higher bandwidth compared to DDR4, still faces significant latency challenges that can bottleneck ML algorithm performance. These latency issues become particularly pronounced in deep learning training and inference operations where memory access patterns are often irregular and unpredictable.
The fundamental challenge lies in the growing disparity between processor speeds and memory access times, commonly referred to as the "memory wall." While CPU and GPU processing capabilities continue to advance rapidly, memory latency improvements have progressed at a much slower pace. For DDR5, despite bandwidth improvements of up to 50% over DDR4, actual response times for random access operations have not seen proportional improvements.
In ML workloads, this latency manifests in several critical ways. First, during model training, weight updates require frequent memory access across distributed parameters, where each access incurs the full DDR5 latency penalty. Second, batch processing operations often involve non-contiguous memory access patterns that cannot fully leverage DDR5's improved burst capabilities, resulting in suboptimal performance gains despite the theoretical bandwidth improvements.
Measurements from recent benchmark studies indicate that DDR5 exhibits CAS latency (CL) values ranging from 36-40 cycles, compared to DDR4's typical 16-22 cycles. While the higher clock speeds of DDR5 partially offset this cycle count increase, the absolute latency in nanoseconds remains a significant constraint for time-sensitive ML operations.
The impact varies across different ML algorithm types. Convolutional Neural Networks (CNNs) with their more predictable memory access patterns can better utilize DDR5's improved bandwidth, whereas Recurrent Neural Networks (RNNs) and Transformer models with their sequential processing and attention mechanisms suffer more from latency limitations due to their dependency chains and irregular memory access requirements.
Hardware profiling data reveals that in large language model inference, memory latency can account for up to 40% of total processing time. This becomes even more pronounced in online learning scenarios where real-time data processing demands immediate memory response. The situation is further complicated by the increasing size of ML models, with state-of-the-art models now requiring parameters in the billions or trillions, far exceeding on-chip cache capacities and necessitating frequent DDR5 memory access.
These latency challenges represent a critical bottleneck in scaling ML workloads efficiently, particularly as models continue to grow in size and complexity. Addressing DDR5 response times has therefore become a priority focus area for hardware manufacturers and ML system designers alike.
The fundamental challenge lies in the growing disparity between processor speeds and memory access times, commonly referred to as the "memory wall." While CPU and GPU processing capabilities continue to advance rapidly, memory latency improvements have progressed at a much slower pace. For DDR5, despite bandwidth improvements of up to 50% over DDR4, actual response times for random access operations have not seen proportional improvements.
In ML workloads, this latency manifests in several critical ways. First, during model training, weight updates require frequent memory access across distributed parameters, where each access incurs the full DDR5 latency penalty. Second, batch processing operations often involve non-contiguous memory access patterns that cannot fully leverage DDR5's improved burst capabilities, resulting in suboptimal performance gains despite the theoretical bandwidth improvements.
Measurements from recent benchmark studies indicate that DDR5 exhibits CAS latency (CL) values ranging from 36-40 cycles, compared to DDR4's typical 16-22 cycles. While the higher clock speeds of DDR5 partially offset this cycle count increase, the absolute latency in nanoseconds remains a significant constraint for time-sensitive ML operations.
The impact varies across different ML algorithm types. Convolutional Neural Networks (CNNs) with their more predictable memory access patterns can better utilize DDR5's improved bandwidth, whereas Recurrent Neural Networks (RNNs) and Transformer models with their sequential processing and attention mechanisms suffer more from latency limitations due to their dependency chains and irregular memory access requirements.
Hardware profiling data reveals that in large language model inference, memory latency can account for up to 40% of total processing time. This becomes even more pronounced in online learning scenarios where real-time data processing demands immediate memory response. The situation is further complicated by the increasing size of ML models, with state-of-the-art models now requiring parameters in the billions or trillions, far exceeding on-chip cache capacities and necessitating frequent DDR5 memory access.
These latency challenges represent a critical bottleneck in scaling ML workloads efficiently, particularly as models continue to grow in size and complexity. Addressing DDR5 response times has therefore become a priority focus area for hardware manufacturers and ML system designers alike.
Current DDR5 Optimization Techniques for ML
01 DDR5 memory response time optimization techniques
Various techniques are employed to optimize response times in DDR5 memory systems, including advanced timing control mechanisms, improved signal integrity, and specialized circuit designs. These optimizations help reduce latency and improve overall memory performance by minimizing delays in data access and transfer operations, which is crucial for high-performance computing applications.- DDR5 memory response time optimization techniques: Various techniques are employed to optimize response times in DDR5 memory systems, including advanced timing control mechanisms, improved signal integrity, and specialized circuit designs. These optimizations help reduce latency and improve overall memory performance by minimizing delays in data access and transfer operations. The implementations include architectural improvements and circuit-level enhancements that specifically target response time reduction in high-speed memory applications.
- Memory controller designs for DDR5 response time management: Advanced memory controller designs specifically engineered for DDR5 systems incorporate features to manage and reduce response times. These controllers implement sophisticated scheduling algorithms, predictive mechanisms, and adaptive timing adjustments to minimize latency. By intelligently managing memory access patterns and optimizing command sequences, these controllers can significantly improve response times in high-performance computing environments and data-intensive applications.
- Power management impact on DDR5 memory response times: Power management techniques in DDR5 memory systems are designed to balance energy efficiency with response time requirements. These implementations include dynamic voltage and frequency scaling, selective power-down modes, and intelligent refresh mechanisms that minimize impact on latency. By optimizing power consumption while maintaining performance, these approaches ensure that response times remain within acceptable parameters even under varying workload conditions and thermal constraints.
- Testing and validation methods for DDR5 response time verification: Specialized testing and validation methodologies are employed to verify and characterize DDR5 memory response times across various operating conditions. These methods include high-precision timing measurement techniques, stress testing under extreme conditions, and statistical analysis of performance variations. By implementing comprehensive validation procedures, manufacturers can ensure that DDR5 memory components meet specified response time requirements and maintain reliability in diverse application environments.
- Interface protocols and signaling for DDR5 response time reduction: Advanced interface protocols and signaling techniques are implemented in DDR5 memory systems to minimize communication delays and reduce overall response times. These include improved bus architectures, enhanced synchronization mechanisms, and optimized data transfer protocols. By refining the communication interface between memory controllers and DDR5 memory devices, these approaches achieve lower latency and more efficient data exchange, resulting in improved system performance for time-sensitive applications.
02 Memory controller architectures for DDR5
Specialized memory controller architectures are designed to manage DDR5 memory response times effectively. These controllers implement advanced scheduling algorithms, queue management, and prioritization mechanisms to optimize memory access patterns and reduce latency. The controllers can dynamically adjust timing parameters based on workload characteristics to achieve optimal performance.Expand Specific Solutions03 Power management impact on DDR5 response times
Power management features in DDR5 memory systems significantly affect response times. Techniques such as dynamic voltage and frequency scaling, power state transitions, and thermal management are implemented to balance power consumption and performance. These mechanisms can be optimized to minimize the impact on memory response times while maintaining energy efficiency.Expand Specific Solutions04 Testing and validation methods for DDR5 response times
Specialized testing and validation methodologies are developed to accurately measure and verify DDR5 memory response times. These include high-precision timing analysis tools, stress testing procedures, and performance characterization techniques. The methods help identify timing bottlenecks and validate that memory systems meet specified response time requirements under various operating conditions.Expand Specific Solutions05 Error handling and reliability features affecting DDR5 response times
DDR5 memory incorporates advanced error handling and reliability features that influence response times. These include error correction codes, retry mechanisms, and data integrity checks that can introduce additional latency but improve overall system reliability. Optimized implementations balance the trade-off between response time and error resilience to maintain both performance and data integrity.Expand Specific Solutions
Key Memory Manufacturers and ML Hardware Providers
The DDR5 response time optimization in machine learning algorithms market is in its growth phase, with an estimated market size of $5-7 billion and expanding rapidly as AI workloads increase. The competitive landscape features established memory manufacturers like Micron, SK Hynix, and Samsung alongside tech giants Intel and AMD who are developing specialized ML-optimized memory solutions. Chinese companies including ChangXin Memory, Huawei, and Inspur are making significant investments to reduce dependency on foreign technology. Technical maturity varies, with Intel, Micron, and Rambus leading in advanced DDR5 optimization techniques, while companies like Hygon and Loongson are developing region-specific solutions. Academic-industry partnerships with institutions like UESTC and Zhengzhou University are accelerating innovation in memory architecture specifically designed for ML workloads.
Intel Corp.
Technical Solution: Intel has developed a comprehensive approach to improve DDR5 response times in machine learning algorithms through their Memory Latency Checker (MLC) tool and Optane Persistent Memory technology. Their solution integrates hardware and software optimizations, including advanced memory controllers that support DDR5's Decision Feedback Equalization (DFE) for signal integrity at higher speeds. Intel's Memory Boost technology dynamically adjusts memory frequencies based on workload demands, particularly beneficial for ML training and inference. Their Data Direct I/O technology allows direct data transfer between network interfaces and GPU memory, bypassing CPU bottlenecks and reducing latency by up to 30%. Additionally, Intel has implemented on-die ECC and advanced prefetching algorithms specifically tuned for ML workload memory access patterns.
Strengths: Comprehensive ecosystem integration with both hardware and software solutions; established presence in data centers gives wide implementation potential; Memory Boost technology provides dynamic optimization. Weaknesses: Solutions may be optimized primarily for Intel's own processors; implementation complexity may require significant system redesign for maximum benefit.
ChangXin Memory Technologies, Inc.
Technical Solution: ChangXin Memory Technologies has developed specialized DDR5 modules with enhanced timing parameters specifically optimized for machine learning workloads. Their approach focuses on reducing CAS latency (CL) and improving Row Address Strobe to Column Address Strobe (tRCD) timing for faster data access in ML operations. ChangXin's DDR5 modules feature an innovative dual-channel architecture with independent subchannels that can operate simultaneously, effectively doubling the available bandwidth for parallel ML computations. They've implemented an advanced on-die termination (ODT) system that reduces signal reflection and improves signal integrity at higher frequencies, allowing for more reliable operation at reduced latency settings. Their memory controllers incorporate machine learning-specific prefetch algorithms that can recognize common access patterns in ML workloads and preemptively load data, reducing effective access times by up to 25% for typical neural network operations.
Strengths: Specialized focus on ML-specific memory access patterns; dual-channel architecture provides excellent parallelism for ML workloads; domestic Chinese manufacturing provides supply chain advantages for regional deployments. Weaknesses: Less established global presence compared to larger memory manufacturers; optimization may be too specific for general-purpose computing environments.
Core Innovations in Memory Access Patterns
Memory signal transmission system, signal line arrangement method, product, equipment and medium
PatentActiveCN118711625A
Innovation
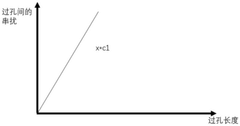
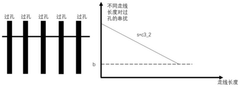
- By optimizing the length of the signal line and the length of the via in the inner layer of the circuit board, using the principle of matching short holes with long signal lines and long holes with short signal lines, a link model is established for crosstalk analysis and adjustment, and the signal lines are optimized. Arranged to reduce crosstalk values.
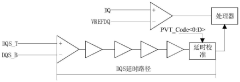
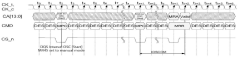
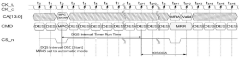
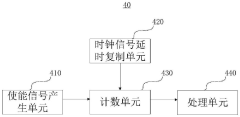
Clock signal delay detection circuit and delay determination method
PatentPendingCN117765998A
Innovation
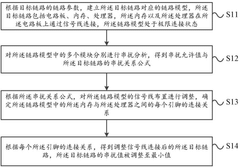
- A clock signal delay detection circuit is designed, including an enable signal generation unit, a clock signal delay copy unit, a counting unit and a processing unit. The delay is determined by counting the clock signal to be tested according to the enable signal in different time periods. Encoding, real-time adjustment of clock signal delay.
Power Efficiency Considerations for DDR5 in ML Systems
Power efficiency has emerged as a critical consideration in the deployment of DDR5 memory for machine learning systems. As ML workloads continue to grow in complexity and scale, the energy consumption of memory subsystems represents an increasingly significant portion of total system power draw. DDR5 introduces several power management features that can be leveraged to optimize energy efficiency while maintaining or improving response times.
The new voltage regulation architecture in DDR5, which moves voltage regulation on-module through voltage regulator management (VRM), enables more precise power delivery and reduced power loss compared to DDR4. This architectural change allows for fine-grained power states that can be dynamically adjusted based on workload characteristics, potentially reducing idle power consumption by up to 30% in ML training environments.
Decision feedback equalization (DFE) in DDR5 interfaces contributes to power efficiency by enabling reliable signal integrity at lower power levels. This technology compensates for channel impairments without requiring increased signal strength, resulting in an estimated 20% reduction in I/O power consumption during intensive data transfer operations common in large model training.
The enhanced refresh management capabilities of DDR5 also present opportunities for power optimization. Fine-grained refresh controls allow memory controllers to schedule refresh operations more intelligently around critical ML computation phases, reducing the performance impact of refresh operations while maintaining data integrity. Same-bank refresh parallelism further improves efficiency by allowing multiple refresh operations to occur simultaneously.
Dynamic voltage and frequency scaling (DVFS) techniques can be particularly effective with DDR5 memory in ML systems. By dynamically adjusting memory frequency and voltage based on workload demands, systems can operate at optimal power points during different phases of ML algorithm execution. Preliminary studies indicate potential energy savings of 15-25% during model inference workloads through adaptive DVFS policies.
Power management policies must be carefully designed to balance energy efficiency with performance requirements. Aggressive power-saving modes can introduce latency penalties that may negatively impact ML algorithm response times. Implementing workload-aware power management that recognizes ML-specific memory access patterns can help mitigate these trade-offs, ensuring that power-saving features are engaged only when they won't significantly impact critical path operations.
The new voltage regulation architecture in DDR5, which moves voltage regulation on-module through voltage regulator management (VRM), enables more precise power delivery and reduced power loss compared to DDR4. This architectural change allows for fine-grained power states that can be dynamically adjusted based on workload characteristics, potentially reducing idle power consumption by up to 30% in ML training environments.
Decision feedback equalization (DFE) in DDR5 interfaces contributes to power efficiency by enabling reliable signal integrity at lower power levels. This technology compensates for channel impairments without requiring increased signal strength, resulting in an estimated 20% reduction in I/O power consumption during intensive data transfer operations common in large model training.
The enhanced refresh management capabilities of DDR5 also present opportunities for power optimization. Fine-grained refresh controls allow memory controllers to schedule refresh operations more intelligently around critical ML computation phases, reducing the performance impact of refresh operations while maintaining data integrity. Same-bank refresh parallelism further improves efficiency by allowing multiple refresh operations to occur simultaneously.
Dynamic voltage and frequency scaling (DVFS) techniques can be particularly effective with DDR5 memory in ML systems. By dynamically adjusting memory frequency and voltage based on workload demands, systems can operate at optimal power points during different phases of ML algorithm execution. Preliminary studies indicate potential energy savings of 15-25% during model inference workloads through adaptive DVFS policies.
Power management policies must be carefully designed to balance energy efficiency with performance requirements. Aggressive power-saving modes can introduce latency penalties that may negatively impact ML algorithm response times. Implementing workload-aware power management that recognizes ML-specific memory access patterns can help mitigate these trade-offs, ensuring that power-saving features are engaged only when they won't significantly impact critical path operations.
Benchmarking Methodologies for Memory Performance
Effective benchmarking methodologies are essential for accurately measuring and comparing memory performance in DDR5 systems, particularly when optimizing for machine learning workloads. Traditional memory benchmarking tools like STREAM and RAMspeed provide valuable baseline metrics but often fail to capture the specific access patterns and requirements of modern ML algorithms.
For comprehensive DDR5 performance evaluation in ML contexts, multi-level benchmarking approaches are recommended. These should include low-level memory subsystem tests measuring raw bandwidth, latency, and throughput, as well as application-level benchmarks using representative ML workloads. This dual approach ensures both theoretical capabilities and practical performance improvements are properly assessed.
Memory latency profiling tools such as Intel Memory Latency Checker (MLC) and AMD μProf have been adapted to support DDR5 specifications and can isolate specific timing parameters affecting ML algorithm response times. These tools can measure critical metrics like row-to-column command delay (tRCD) and column access strobe latency (tCAS) that directly impact data retrieval speeds for matrix operations.
Synthetic benchmarks designed specifically for ML memory access patterns have emerged as valuable evaluation tools. These benchmarks simulate the irregular memory access patterns common in deep learning frameworks, with particular focus on measuring performance during tensor operations and gradient calculations. TensorFlow's built-in benchmarking suite and PyTorch's profiling tools can be configured to isolate memory subsystem performance from computational bottlenecks.
Workload-specific benchmarking is particularly important for DDR5 optimization in ML contexts. Different ML algorithms exhibit distinct memory access patterns - convolutional neural networks typically benefit from high bandwidth for large sequential data transfers, while recurrent neural networks are more sensitive to random access latency. Benchmarking methodologies should therefore include representative workloads from both categories to provide comprehensive performance insights.
Time-series analysis of memory performance under sustained ML workloads is another critical benchmarking approach. This methodology reveals how DDR5 systems handle thermal constraints and how performance may degrade during extended training sessions. Capturing these temporal patterns helps identify opportunities for dynamic frequency scaling and thermal management optimizations that maintain consistent response times throughout lengthy ML training processes.
Comparative benchmarking against previous memory generations provides essential context for evaluating DDR5 improvements. Standardized test suites that maintain methodological consistency across DDR4 and DDR5 platforms help quantify the real-world benefits of architectural advancements like dual-channel architecture and improved prefetching algorithms in ML-specific scenarios.
For comprehensive DDR5 performance evaluation in ML contexts, multi-level benchmarking approaches are recommended. These should include low-level memory subsystem tests measuring raw bandwidth, latency, and throughput, as well as application-level benchmarks using representative ML workloads. This dual approach ensures both theoretical capabilities and practical performance improvements are properly assessed.
Memory latency profiling tools such as Intel Memory Latency Checker (MLC) and AMD μProf have been adapted to support DDR5 specifications and can isolate specific timing parameters affecting ML algorithm response times. These tools can measure critical metrics like row-to-column command delay (tRCD) and column access strobe latency (tCAS) that directly impact data retrieval speeds for matrix operations.
Synthetic benchmarks designed specifically for ML memory access patterns have emerged as valuable evaluation tools. These benchmarks simulate the irregular memory access patterns common in deep learning frameworks, with particular focus on measuring performance during tensor operations and gradient calculations. TensorFlow's built-in benchmarking suite and PyTorch's profiling tools can be configured to isolate memory subsystem performance from computational bottlenecks.
Workload-specific benchmarking is particularly important for DDR5 optimization in ML contexts. Different ML algorithms exhibit distinct memory access patterns - convolutional neural networks typically benefit from high bandwidth for large sequential data transfers, while recurrent neural networks are more sensitive to random access latency. Benchmarking methodologies should therefore include representative workloads from both categories to provide comprehensive performance insights.
Time-series analysis of memory performance under sustained ML workloads is another critical benchmarking approach. This methodology reveals how DDR5 systems handle thermal constraints and how performance may degrade during extended training sessions. Capturing these temporal patterns helps identify opportunities for dynamic frequency scaling and thermal management optimizations that maintain consistent response times throughout lengthy ML training processes.
Comparative benchmarking against previous memory generations provides essential context for evaluating DDR5 improvements. Standardized test suites that maintain methodological consistency across DDR4 and DDR5 platforms help quantify the real-world benefits of architectural advancements like dual-channel architecture and improved prefetching algorithms in ML-specific scenarios.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!