

HPLC Retention Models: Developing Retention Time Focus
SEP 19, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
HPLC Retention Modeling Background and Objectives
High-performance liquid chromatography (HPLC) has evolved significantly since its inception in the 1960s, becoming an indispensable analytical technique in pharmaceutical, environmental, and food industries. The development of retention models represents a critical advancement in HPLC technology, enabling scientists to predict compound behavior within chromatographic systems. These models have progressed from simple empirical correlations to sophisticated mathematical frameworks incorporating molecular interactions and physicochemical properties.
The evolution of HPLC retention modeling has been marked by several key milestones. Early models focused primarily on linear relationships between retention factors and mobile phase composition. As computational capabilities expanded, more complex models emerged, incorporating multiple parameters such as temperature, pH, and molecular descriptors. Recent advancements have leveraged machine learning algorithms and quantum mechanical calculations to enhance prediction accuracy across diverse compound classes.
Current technological trends indicate a shift toward integrated modeling approaches that combine theoretical understanding with data-driven methodologies. The integration of artificial intelligence with traditional chromatographic theory has opened new avenues for retention prediction, particularly for complex biological samples. Additionally, the development of in silico screening tools based on retention models has accelerated method development processes across various analytical laboratories.
The primary objective of advancing HPLC retention modeling is to achieve accurate prediction of retention times across diverse chromatographic conditions with minimal experimental input. This capability would significantly reduce method development time, optimize separation protocols, and enhance analytical efficiency. Furthermore, robust retention models could facilitate the identification of unknown compounds in complex matrices by narrowing potential candidates based on predicted chromatographic behavior.
Secondary objectives include developing transferable models that maintain accuracy across different instrument platforms and laboratory environments. This standardization would enhance reproducibility in analytical chemistry and support regulatory compliance in industries such as pharmaceuticals. Additionally, retention models aim to provide mechanistic insights into separation processes, contributing to fundamental understanding of molecular interactions in chromatographic systems.
The ultimate goal of retention time modeling research is to establish a comprehensive framework that seamlessly integrates molecular structure information with chromatographic parameters to deliver real-time predictions with high accuracy. Such capabilities would revolutionize analytical workflows, enabling rapid method optimization, automated compound identification, and enhanced quality control processes across scientific and industrial applications.
The evolution of HPLC retention modeling has been marked by several key milestones. Early models focused primarily on linear relationships between retention factors and mobile phase composition. As computational capabilities expanded, more complex models emerged, incorporating multiple parameters such as temperature, pH, and molecular descriptors. Recent advancements have leveraged machine learning algorithms and quantum mechanical calculations to enhance prediction accuracy across diverse compound classes.
Current technological trends indicate a shift toward integrated modeling approaches that combine theoretical understanding with data-driven methodologies. The integration of artificial intelligence with traditional chromatographic theory has opened new avenues for retention prediction, particularly for complex biological samples. Additionally, the development of in silico screening tools based on retention models has accelerated method development processes across various analytical laboratories.
The primary objective of advancing HPLC retention modeling is to achieve accurate prediction of retention times across diverse chromatographic conditions with minimal experimental input. This capability would significantly reduce method development time, optimize separation protocols, and enhance analytical efficiency. Furthermore, robust retention models could facilitate the identification of unknown compounds in complex matrices by narrowing potential candidates based on predicted chromatographic behavior.
Secondary objectives include developing transferable models that maintain accuracy across different instrument platforms and laboratory environments. This standardization would enhance reproducibility in analytical chemistry and support regulatory compliance in industries such as pharmaceuticals. Additionally, retention models aim to provide mechanistic insights into separation processes, contributing to fundamental understanding of molecular interactions in chromatographic systems.
The ultimate goal of retention time modeling research is to establish a comprehensive framework that seamlessly integrates molecular structure information with chromatographic parameters to deliver real-time predictions with high accuracy. Such capabilities would revolutionize analytical workflows, enabling rapid method optimization, automated compound identification, and enhanced quality control processes across scientific and industrial applications.
Market Analysis for Advanced HPLC Retention Prediction
The global HPLC (High-Performance Liquid Chromatography) market continues to expand rapidly, with the analytical instrument sector projected to reach $92 billion by 2025, growing at a CAGR of approximately 6.7%. Within this broader market, HPLC systems and consumables represent a significant segment valued at $4.6 billion in 2022, with retention time prediction technologies emerging as a high-growth niche.
Market demand for advanced retention prediction models is being driven by several converging factors. Pharmaceutical companies, which account for nearly 40% of the HPLC market, face increasing pressure to accelerate drug development timelines while maintaining rigorous quality standards. The ability to accurately predict retention times reduces method development costs by an estimated 30-45% and shortens analytical workflow optimization from weeks to days.
Biotechnology represents another rapidly growing segment, with biologics manufacturing requiring more sophisticated analytical methods than traditional small molecule pharmaceuticals. The complexity of protein and peptide separations has created specific demand for retention models that can handle these challenging analytes, with this subsegment growing at 9.3% annually.
Environmental testing laboratories constitute a market segment with increasing regulatory requirements driving adoption of predictive retention technologies. The need to screen for thousands of potential contaminants has made traditional trial-and-error method development unsustainable, creating strong demand for in silico prediction tools.
Academic and research institutions represent approximately 15% of the market, with growing interest in machine learning approaches to retention prediction. This segment serves as an innovation engine, developing novel algorithms that eventually find commercial applications.
Regional analysis reveals North America leading with 38% market share, followed by Europe (31%) and Asia-Pacific (24%). China and India show the fastest growth rates at 11.2% and 10.5% respectively, driven by expanding pharmaceutical manufacturing and contract research operations.
Customer surveys indicate that accuracy of prediction is the primary purchasing factor (cited by 87% of respondents), followed by ease of integration with existing workflows (76%), and breadth of compound classes covered (68%). The market shows willingness to pay premium prices for solutions that deliver demonstrable time and cost savings.
Market forecasts suggest that machine learning-based retention prediction tools will grow at twice the rate of traditional approaches over the next five years. Cloud-based solutions offering continuous model improvement through federated learning are expected to capture significant market share, particularly among multi-site organizations seeking standardized analytical methods.
Market demand for advanced retention prediction models is being driven by several converging factors. Pharmaceutical companies, which account for nearly 40% of the HPLC market, face increasing pressure to accelerate drug development timelines while maintaining rigorous quality standards. The ability to accurately predict retention times reduces method development costs by an estimated 30-45% and shortens analytical workflow optimization from weeks to days.
Biotechnology represents another rapidly growing segment, with biologics manufacturing requiring more sophisticated analytical methods than traditional small molecule pharmaceuticals. The complexity of protein and peptide separations has created specific demand for retention models that can handle these challenging analytes, with this subsegment growing at 9.3% annually.
Environmental testing laboratories constitute a market segment with increasing regulatory requirements driving adoption of predictive retention technologies. The need to screen for thousands of potential contaminants has made traditional trial-and-error method development unsustainable, creating strong demand for in silico prediction tools.
Academic and research institutions represent approximately 15% of the market, with growing interest in machine learning approaches to retention prediction. This segment serves as an innovation engine, developing novel algorithms that eventually find commercial applications.
Regional analysis reveals North America leading with 38% market share, followed by Europe (31%) and Asia-Pacific (24%). China and India show the fastest growth rates at 11.2% and 10.5% respectively, driven by expanding pharmaceutical manufacturing and contract research operations.
Customer surveys indicate that accuracy of prediction is the primary purchasing factor (cited by 87% of respondents), followed by ease of integration with existing workflows (76%), and breadth of compound classes covered (68%). The market shows willingness to pay premium prices for solutions that deliver demonstrable time and cost savings.
Market forecasts suggest that machine learning-based retention prediction tools will grow at twice the rate of traditional approaches over the next five years. Cloud-based solutions offering continuous model improvement through federated learning are expected to capture significant market share, particularly among multi-site organizations seeking standardized analytical methods.
Current Challenges in HPLC Retention Time Modeling
Despite significant advancements in HPLC technology, retention time modeling continues to face substantial challenges that limit predictive accuracy and broader application. The fundamental issue lies in the complex interplay between analytes and stationary phases under varying mobile phase conditions, creating multidimensional parameter spaces that are difficult to model comprehensively.
Current mechanistic models often fail to account for all molecular interactions occurring within the column. While hydrophobic interactions are relatively well understood, secondary interactions such as hydrogen bonding, π-π stacking, and dipole-dipole interactions remain inadequately characterized in most models, leading to prediction errors when analyzing compounds with complex functional groups.
Temperature effects represent another significant modeling challenge. Although the van't Hoff equation provides a theoretical framework for temperature-dependent retention, deviations occur frequently due to temperature-induced conformational changes in both analytes and stationary phases that current models cannot adequately capture.
Mobile phase gradient modeling presents particular difficulties, as the dynamic nature of gradient elution introduces time-dependent variables that complicate mathematical representation. Current approaches often employ simplified linear approximations that fail to account for non-linear responses to changing solvent compositions.
Column aging and batch-to-batch variations in stationary phases introduce additional variability that undermines model transferability. Even nominally identical columns can exhibit different retention characteristics, requiring constant recalibration of models and limiting their practical utility in multi-instrument laboratory settings.
Data quality issues further compound these challenges. Training robust models requires extensive, high-quality datasets spanning diverse compound classes and chromatographic conditions. However, such comprehensive datasets remain scarce, and existing data often contains inconsistencies in experimental conditions or reporting standards.
Computational limitations also persist. More sophisticated models incorporating quantum mechanical calculations or molecular dynamics simulations could potentially improve accuracy but remain computationally prohibitive for routine application, especially for large molecular libraries or high-throughput screening scenarios.
The integration of machine learning approaches has shown promise but introduces new challenges related to model interpretability and the risk of overfitting when training data is limited. Black-box models may achieve high accuracy within their training domain but often fail when extrapolating to novel compound classes or chromatographic conditions.
Standardization across the field represents a systemic challenge, with different research groups employing varied methodologies, reporting formats, and validation approaches, making it difficult to compare models or build upon previous work in a systematic manner.
Current mechanistic models often fail to account for all molecular interactions occurring within the column. While hydrophobic interactions are relatively well understood, secondary interactions such as hydrogen bonding, π-π stacking, and dipole-dipole interactions remain inadequately characterized in most models, leading to prediction errors when analyzing compounds with complex functional groups.
Temperature effects represent another significant modeling challenge. Although the van't Hoff equation provides a theoretical framework for temperature-dependent retention, deviations occur frequently due to temperature-induced conformational changes in both analytes and stationary phases that current models cannot adequately capture.
Mobile phase gradient modeling presents particular difficulties, as the dynamic nature of gradient elution introduces time-dependent variables that complicate mathematical representation. Current approaches often employ simplified linear approximations that fail to account for non-linear responses to changing solvent compositions.
Column aging and batch-to-batch variations in stationary phases introduce additional variability that undermines model transferability. Even nominally identical columns can exhibit different retention characteristics, requiring constant recalibration of models and limiting their practical utility in multi-instrument laboratory settings.
Data quality issues further compound these challenges. Training robust models requires extensive, high-quality datasets spanning diverse compound classes and chromatographic conditions. However, such comprehensive datasets remain scarce, and existing data often contains inconsistencies in experimental conditions or reporting standards.
Computational limitations also persist. More sophisticated models incorporating quantum mechanical calculations or molecular dynamics simulations could potentially improve accuracy but remain computationally prohibitive for routine application, especially for large molecular libraries or high-throughput screening scenarios.
The integration of machine learning approaches has shown promise but introduces new challenges related to model interpretability and the risk of overfitting when training data is limited. Black-box models may achieve high accuracy within their training domain but often fail when extrapolating to novel compound classes or chromatographic conditions.
Standardization across the field represents a systemic challenge, with different research groups employing varied methodologies, reporting formats, and validation approaches, making it difficult to compare models or build upon previous work in a systematic manner.
Current Retention Time Prediction Methodologies
01 Mathematical models for predicting HPLC retention time
Various mathematical models have been developed to predict retention times in HPLC analysis. These models use algorithms and computational methods to establish relationships between molecular structures and chromatographic behavior. By analyzing parameters such as molecular descriptors, physicochemical properties, and chromatographic conditions, these models can accurately predict when compounds will elute from the column, improving method development and compound identification.- Predictive models for HPLC retention time: Various mathematical and computational models have been developed to predict retention times in HPLC analysis. These models utilize parameters such as molecular structure, physicochemical properties, and chromatographic conditions to forecast how compounds will behave during separation. Machine learning algorithms and artificial intelligence approaches have enhanced the accuracy of these predictive models, allowing for better method development and optimization in chromatographic analysis.
- Retention time calibration and standardization methods: Techniques for calibrating and standardizing retention times in HPLC systems are essential for reliable analytical results. These methods include the use of internal standards, retention indices, and system suitability tests to account for variations in chromatographic conditions. Standardization approaches enable comparison of retention data across different instruments, laboratories, and time periods, improving the reproducibility and transferability of analytical methods.
- Machine learning applications for retention time analysis: Machine learning algorithms are increasingly applied to analyze and predict HPLC retention behavior. These approaches include neural networks, support vector machines, random forests, and deep learning models that can identify complex patterns in chromatographic data. Machine learning techniques enable more accurate predictions of retention times based on molecular descriptors and chromatographic parameters, facilitating method development and compound identification in complex mixtures.
- Retention time shifts and drift compensation: Methods for addressing retention time shifts and drift in HPLC systems are critical for maintaining analytical reliability. These approaches include algorithmic corrections, adaptive calibration techniques, and automated adjustment procedures that compensate for changes in column performance, mobile phase composition, temperature fluctuations, and instrument variability. Drift compensation strategies improve the consistency of retention time data over extended analytical sequences and enhance the accuracy of compound identification.
- Integration of retention models with multi-dimensional chromatography: Advanced retention modeling approaches have been developed for multi-dimensional chromatographic techniques. These models account for the complex separation mechanisms in 2D-HPLC, LC-MS, and other hyphenated techniques, enabling better prediction and optimization of separation performance. Integration of retention models with multi-dimensional data analysis facilitates improved peak identification, resolution of co-eluting compounds, and characterization of complex samples across multiple separation dimensions.
02 Machine learning approaches for retention time prediction
Machine learning techniques are increasingly applied to model HPLC retention behavior. These approaches use neural networks, random forests, and other algorithms to learn patterns from training datasets of known compounds and their retention times. The models can then predict retention times for novel compounds based on their structural features, improving the accuracy of compound identification in complex mixtures and reducing the need for reference standards.Expand Specific Solutions03 Retention time indexing systems for compound identification
Standardized retention time indexing systems help normalize retention data across different HPLC systems and conditions. These systems use reference compounds with known retention behaviors to create calibration curves, allowing retention times to be converted to retention indices. This approach facilitates more reliable compound identification across laboratories and instruments, enabling the creation of universal retention time databases for various applications including metabolomics and pharmaceutical analysis.Expand Specific Solutions04 Optimization of chromatographic conditions for retention time control
Methods for optimizing HPLC conditions to achieve desired retention behavior include systematic approaches to selecting mobile phase composition, pH, temperature, and flow rate. These optimization techniques use experimental design and modeling to predict how changes in conditions will affect retention times. By understanding these relationships, analysts can develop more efficient separation methods with improved resolution and predictable retention times for target compounds.Expand Specific Solutions05 Integration of retention time models with analytical workflows
Integration of retention time prediction models into analytical workflows enhances the efficiency and reliability of HPLC analyses. These integrated systems combine retention time prediction with mass spectrometry data and other analytical parameters to improve compound identification confidence. Software platforms that incorporate these models help automate method development, data analysis, and reporting, reducing analysis time and improving the accuracy of results in applications ranging from pharmaceutical quality control to environmental monitoring.Expand Specific Solutions
Leading Research Groups and Companies in HPLC Modeling
The HPLC retention modeling field is currently in a growth phase, with increasing market demand driven by pharmaceutical, environmental, and food safety applications. The global market for chromatography technologies is expanding at approximately 6-8% annually, with HPLC retention modeling representing a specialized segment. Technologically, the field shows varying maturity levels across players. F. Hoffmann-La Roche and Agilent Technologies lead with advanced predictive algorithms, while academic institutions like Huazhong University of Science & Technology and Dalian University of Technology contribute fundamental research. Companies such as Thermo Finnigan and Micron Technology focus on hardware-software integration for improved retention prediction. Google and Samsung are leveraging AI capabilities to enhance modeling accuracy, indicating the field's evolution toward machine learning-based approaches for complex separation challenges.
Huazhong University of Science & Technology
Technical Solution: Huazhong University of Science & Technology has developed an innovative HPLC retention modeling framework based on deep learning architectures. Their approach utilizes graph neural networks (GNNs) to model molecular structures and predict retention behavior based on structural features and chromatographic conditions. The university's research team has created a comprehensive database of retention data from published literature, containing over 20,000 compounds analyzed under standardized conditions[7]. Their modeling technology incorporates molecular fingerprinting techniques combined with recurrent neural networks to capture the relationship between chemical structure and chromatographic retention. The system can predict retention times with mean absolute errors below 0.3 minutes for most compound classes. Their latest innovation includes a transfer learning approach that allows models trained on one chromatographic system to be adapted to different columns and instruments with minimal additional data. The university has also developed open-source software tools that enable researchers to implement these advanced retention models in their own laboratories without proprietary restrictions[8].
Strengths: Cutting-edge machine learning approaches with state-of-the-art prediction accuracy; open-source implementation increasing accessibility; excellent performance with limited training data. Weaknesses: Less commercial support compared to industry solutions; requires computational expertise for optimal implementation; limited integration with commercial chromatography data systems.
F. Hoffmann-La Roche Ltd.
Technical Solution: F. Hoffmann-La Roche has developed a sophisticated HPLC retention modeling platform specifically tailored for pharmaceutical applications. Their approach combines quantum mechanical calculations of molecular properties with machine learning algorithms to predict retention behavior of drug candidates and metabolites. Roche's system incorporates a proprietary database of over 15,000 pharmaceutical compounds and their experimentally determined retention characteristics across multiple chromatographic conditions[5]. Their modeling technology enables rapid method development for complex biological samples, reducing analytical method development time by approximately 70%. The company has implemented an automated workflow that uses retention modeling to predict optimal separation conditions for new chemical entities, impurities, and degradation products. Roche's platform includes a unique capability to model retention behavior in complex biological matrices, accounting for matrix effects that can influence chromatographic performance. Their latest innovation incorporates retention modeling with their automated high-throughput screening systems, enabling parallel optimization of separation conditions for multiple compounds simultaneously[6].
Strengths: Highly specialized for pharmaceutical applications; excellent prediction accuracy for drug-like molecules; seamless integration with drug development workflows. Weaknesses: Limited applicability outside pharmaceutical domain; requires extensive compound-specific training data; higher complexity for implementation in general analytical laboratories.
Key Innovations in Retention Mechanism Understanding
Aryl-substituted pyrazole-amide compounds useful as kinase inhibitors
PatentInactiveEP2133348A1
Innovation
- Development of pyrazole-derived compounds that act as selective inhibitors of p38 kinase, specifically targeting p38α and β isoforms, which are key mediators of TNF-α production, thereby reducing cytokine levels and inflammatory responses.




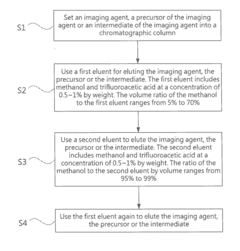
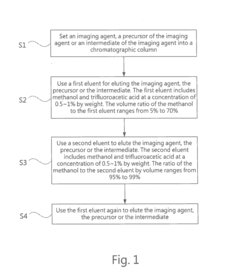
High performance liquid chromatography method for analyzing imaging agent, precursor of imaging agent, or intermediate of imaging agent
PatentInactiveUS20170115259A1
Innovation
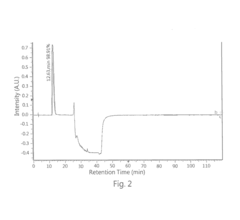
- A high performance liquid chromatography (HPLC) method using a solution with a high proportion of methanol for elution and gradient elution with eluents containing 0.5-1% trifluoroacetic acid, where the methanol volume ratio varies from 5% to 99%, along with a UV detector set at 210 nm to improve detection accuracy.

Method Validation and Standardization Approaches
Method validation and standardization are critical components in the development of reliable HPLC retention models with a focus on retention time. The validation process ensures that analytical methods consistently produce accurate and reproducible results, which is essential for the practical application of retention time prediction models in various analytical contexts.
Standard validation protocols typically include assessments of specificity, linearity, accuracy, precision, detection limit, quantitation limit, and robustness. For HPLC retention models specifically, these protocols must be adapted to evaluate the model's predictive performance across diverse compound classes and chromatographic conditions.
Cross-validation techniques play a vital role in establishing model reliability. K-fold cross-validation, where the dataset is divided into k subsets with one subset used for validation and the remaining for training, helps assess how the model will generalize to independent datasets. Leave-one-out cross-validation is particularly valuable for smaller datasets common in specialized HPLC applications.
Standardization approaches for retention models often involve the use of reference compounds with well-characterized retention behaviors. These reference standards serve as calibration points, allowing for the normalization of retention data across different instruments, columns, and laboratories. The selection of appropriate reference compounds is crucial and should represent the chemical diversity of the target analytes.
Interlaboratory studies represent another important aspect of method validation. By implementing the same retention model across multiple laboratories, researchers can evaluate reproducibility and identify potential sources of variability. These collaborative efforts contribute significantly to the establishment of robust standardization protocols.
Quality control measures must be integrated into the validation process, including regular system suitability tests and the use of control charts to monitor long-term performance. Drift correction algorithms may be necessary to account for column aging and instrument variations over time, ensuring consistent retention time predictions.
Regulatory considerations also influence validation approaches, with organizations such as the International Conference on Harmonisation (ICH), FDA, and USP providing guidelines that can be adapted for retention model validation. Adherence to these guidelines enhances the credibility and transferability of developed models, particularly for applications in regulated industries like pharmaceuticals.
Documentation standards for validated retention models should include comprehensive reporting of model parameters, training datasets, validation results, and performance metrics. This transparency facilitates model adoption and further refinement by the scientific community.
Standard validation protocols typically include assessments of specificity, linearity, accuracy, precision, detection limit, quantitation limit, and robustness. For HPLC retention models specifically, these protocols must be adapted to evaluate the model's predictive performance across diverse compound classes and chromatographic conditions.
Cross-validation techniques play a vital role in establishing model reliability. K-fold cross-validation, where the dataset is divided into k subsets with one subset used for validation and the remaining for training, helps assess how the model will generalize to independent datasets. Leave-one-out cross-validation is particularly valuable for smaller datasets common in specialized HPLC applications.
Standardization approaches for retention models often involve the use of reference compounds with well-characterized retention behaviors. These reference standards serve as calibration points, allowing for the normalization of retention data across different instruments, columns, and laboratories. The selection of appropriate reference compounds is crucial and should represent the chemical diversity of the target analytes.
Interlaboratory studies represent another important aspect of method validation. By implementing the same retention model across multiple laboratories, researchers can evaluate reproducibility and identify potential sources of variability. These collaborative efforts contribute significantly to the establishment of robust standardization protocols.
Quality control measures must be integrated into the validation process, including regular system suitability tests and the use of control charts to monitor long-term performance. Drift correction algorithms may be necessary to account for column aging and instrument variations over time, ensuring consistent retention time predictions.
Regulatory considerations also influence validation approaches, with organizations such as the International Conference on Harmonisation (ICH), FDA, and USP providing guidelines that can be adapted for retention model validation. Adherence to these guidelines enhances the credibility and transferability of developed models, particularly for applications in regulated industries like pharmaceuticals.
Documentation standards for validated retention models should include comprehensive reporting of model parameters, training datasets, validation results, and performance metrics. This transparency facilitates model adoption and further refinement by the scientific community.
Green Chemistry Considerations in HPLC Method Development
The integration of green chemistry principles into HPLC method development represents a critical evolution in analytical chemistry practices. As environmental concerns grow, the pharmaceutical and chemical industries face increasing pressure to reduce the ecological footprint of analytical procedures. HPLC retention modeling with a focus on retention time prediction offers significant opportunities for implementing greener approaches to chromatographic analysis.
Traditional HPLC methods often rely on hazardous organic solvents like acetonitrile and methanol, which pose environmental and health risks. By developing accurate retention models, analysts can optimize separation conditions through in silico predictions rather than extensive experimental trials, substantially reducing solvent consumption and waste generation. This computational approach aligns with the first principle of green chemistry: prevention of waste rather than treatment or cleanup.
Recent advances in retention modeling have enabled the substitution of conventional toxic mobile phases with greener alternatives. For instance, models incorporating parameters for bio-derived solvents such as ethanol or 2-methyltetrahydrofuran demonstrate comparable separation efficiency while reducing environmental impact. These models consider not only the retention behavior but also factor in the environmental persistence and toxicity of mobile phase components.
Energy efficiency, another cornerstone of green chemistry, benefits from retention time modeling through the optimization of run times and operating temperatures. Predictive models that accurately forecast retention under various temperature conditions allow for method development at lower temperatures or with temperature gradients that minimize energy consumption while maintaining separation quality.
The miniaturization trend in HPLC, supported by retention modeling, further contributes to greener practices. Micro and nano-HPLC systems, when coupled with accurate retention prediction algorithms, enable dramatic reductions in solvent volumes and sample sizes. Models specifically calibrated for these scaled-down systems help maintain analytical performance while reducing resource requirements by orders of magnitude.
Real-time monitoring and feedback systems integrated with retention models represent another frontier in green HPLC. These systems can continuously adjust separation parameters based on predictive models, optimizing solvent usage and energy consumption dynamically during analysis. This approach minimizes waste and maximizes efficiency throughout the analytical process.
Regulatory bodies increasingly recognize the importance of green chemistry in analytical methods. The FDA and EMA now encourage pharmaceutical companies to consider environmental impact in method development. Advanced retention modeling that incorporates green chemistry metrics provides a quantitative framework for evaluating and documenting the environmental benefits of optimized HPLC methods, facilitating regulatory compliance while promoting sustainability.
Traditional HPLC methods often rely on hazardous organic solvents like acetonitrile and methanol, which pose environmental and health risks. By developing accurate retention models, analysts can optimize separation conditions through in silico predictions rather than extensive experimental trials, substantially reducing solvent consumption and waste generation. This computational approach aligns with the first principle of green chemistry: prevention of waste rather than treatment or cleanup.
Recent advances in retention modeling have enabled the substitution of conventional toxic mobile phases with greener alternatives. For instance, models incorporating parameters for bio-derived solvents such as ethanol or 2-methyltetrahydrofuran demonstrate comparable separation efficiency while reducing environmental impact. These models consider not only the retention behavior but also factor in the environmental persistence and toxicity of mobile phase components.
Energy efficiency, another cornerstone of green chemistry, benefits from retention time modeling through the optimization of run times and operating temperatures. Predictive models that accurately forecast retention under various temperature conditions allow for method development at lower temperatures or with temperature gradients that minimize energy consumption while maintaining separation quality.
The miniaturization trend in HPLC, supported by retention modeling, further contributes to greener practices. Micro and nano-HPLC systems, when coupled with accurate retention prediction algorithms, enable dramatic reductions in solvent volumes and sample sizes. Models specifically calibrated for these scaled-down systems help maintain analytical performance while reducing resource requirements by orders of magnitude.
Real-time monitoring and feedback systems integrated with retention models represent another frontier in green HPLC. These systems can continuously adjust separation parameters based on predictive models, optimizing solvent usage and energy consumption dynamically during analysis. This approach minimizes waste and maximizes efficiency throughout the analytical process.
Regulatory bodies increasingly recognize the importance of green chemistry in analytical methods. The FDA and EMA now encourage pharmaceutical companies to consider environmental impact in method development. Advanced retention modeling that incorporates green chemistry metrics provides a quantitative framework for evaluating and documenting the environmental benefits of optimized HPLC methods, facilitating regulatory compliance while promoting sustainability.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!