

Integrating Classical Co-Processors For Low-Latency Decoding
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Classical Co-Processor Integration Background and Objectives
The integration of classical co-processors for quantum computing represents a significant technological evolution aimed at addressing one of the most critical challenges in quantum information processing: decoding latency. This technological approach has emerged from the convergence of classical computing architectures and quantum processing units, seeking to optimize the interface between these fundamentally different computational paradigms.
Historically, quantum computing systems have relied on general-purpose classical computers for control, data processing, and error correction tasks. However, as quantum processors have scaled up in qubit count and complexity, the latency in classical processing has become a significant bottleneck, particularly in error correction protocols where real-time feedback is essential.
The evolution of this technology can be traced back to early quantum computing architectures where simple microcontrollers managed basic qubit operations. As quantum systems advanced, field-programmable gate arrays (FPGAs) were introduced to handle more complex control sequences with reduced latency. The current technological trajectory is moving toward application-specific integrated circuits (ASICs) and specialized co-processors designed explicitly for quantum control and decoding operations.
The primary objective of integrating classical co-processors is to minimize the latency in quantum error correction cycles, which is crucial for maintaining quantum coherence long enough to perform meaningful computations. Specifically, the technology aims to reduce decoding times from milliseconds to microseconds, representing a three-order-of-magnitude improvement that could fundamentally alter the viability of large-scale quantum computing.
Secondary objectives include optimizing the energy efficiency of the classical-quantum interface, reducing the physical footprint of control electronics, and developing scalable architectures that can grow alongside increasingly complex quantum processors. These goals align with the broader quantum computing roadmap of achieving fault-tolerant quantum computation.
The technological landscape is currently witnessing a transition from proof-of-concept demonstrations to engineered solutions that can be integrated into practical quantum computing systems. Research institutions and industry leaders are exploring various hardware architectures, from cryogenic electronics operating in close proximity to quantum processors to room-temperature solutions with optimized communication channels.
As quantum computing continues to advance toward practical applications, the development of specialized classical co-processors represents a critical enabling technology that may determine the timeline for achieving quantum advantage in real-world problems.
Historically, quantum computing systems have relied on general-purpose classical computers for control, data processing, and error correction tasks. However, as quantum processors have scaled up in qubit count and complexity, the latency in classical processing has become a significant bottleneck, particularly in error correction protocols where real-time feedback is essential.
The evolution of this technology can be traced back to early quantum computing architectures where simple microcontrollers managed basic qubit operations. As quantum systems advanced, field-programmable gate arrays (FPGAs) were introduced to handle more complex control sequences with reduced latency. The current technological trajectory is moving toward application-specific integrated circuits (ASICs) and specialized co-processors designed explicitly for quantum control and decoding operations.
The primary objective of integrating classical co-processors is to minimize the latency in quantum error correction cycles, which is crucial for maintaining quantum coherence long enough to perform meaningful computations. Specifically, the technology aims to reduce decoding times from milliseconds to microseconds, representing a three-order-of-magnitude improvement that could fundamentally alter the viability of large-scale quantum computing.
Secondary objectives include optimizing the energy efficiency of the classical-quantum interface, reducing the physical footprint of control electronics, and developing scalable architectures that can grow alongside increasingly complex quantum processors. These goals align with the broader quantum computing roadmap of achieving fault-tolerant quantum computation.
The technological landscape is currently witnessing a transition from proof-of-concept demonstrations to engineered solutions that can be integrated into practical quantum computing systems. Research institutions and industry leaders are exploring various hardware architectures, from cryogenic electronics operating in close proximity to quantum processors to room-temperature solutions with optimized communication channels.
As quantum computing continues to advance toward practical applications, the development of specialized classical co-processors represents a critical enabling technology that may determine the timeline for achieving quantum advantage in real-world problems.
Market Demand Analysis for Low-Latency Decoding Solutions
The demand for low-latency decoding solutions has experienced significant growth across multiple sectors, driven primarily by the increasing complexity of computational tasks and the need for real-time processing capabilities. The global market for specialized decoding hardware is projected to reach $12.5 billion by 2026, with a compound annual growth rate of 18.7% from 2021, according to recent industry analyses.
Telecommunications and data centers represent the largest market segments, collectively accounting for approximately 45% of the total demand. These sectors require ultra-low latency decoding for network packet processing, error correction, and data compression tasks where millisecond delays can significantly impact service quality and operational efficiency.
The consumer electronics sector has emerged as another major driver, particularly with the proliferation of high-definition video streaming, augmented reality, and virtual reality applications. These technologies demand real-time decoding capabilities to deliver seamless user experiences, with consumers increasingly expecting zero-lag performance across devices.
Enterprise cloud computing services have also contributed substantially to market growth, as businesses migrate more operations to cloud environments where efficient data processing is critical. The demand for accelerated decoding in this segment has grown by 23% annually since 2019, reflecting the increasing volume of data being processed in distributed computing environments.
Automotive and industrial automation sectors represent rapidly expanding markets for low-latency decoding solutions. Advanced driver-assistance systems (ADAS) and autonomous vehicles require instantaneous processing of sensor data, while industrial IoT applications demand real-time decoding for process monitoring and control systems. These sectors are expected to grow at 27% annually through 2025.
Healthcare applications, particularly in medical imaging and real-time patient monitoring, have created new market opportunities. The precision and speed requirements in these applications have driven demand for specialized decoding hardware that can process complex medical data with minimal latency.
Market research indicates that customers across all sectors prioritize three key factors when selecting low-latency decoding solutions: power efficiency, integration capabilities with existing systems, and scalability. The ability to balance these factors while maintaining minimal latency represents the primary competitive differentiator in this market.
Regional analysis shows North America leading with 38% market share, followed by Asia-Pacific at 32% and Europe at 24%. However, the Asia-Pacific region is experiencing the fastest growth rate at 22% annually, driven by rapid technological adoption in China, South Korea, and Taiwan.
Telecommunications and data centers represent the largest market segments, collectively accounting for approximately 45% of the total demand. These sectors require ultra-low latency decoding for network packet processing, error correction, and data compression tasks where millisecond delays can significantly impact service quality and operational efficiency.
The consumer electronics sector has emerged as another major driver, particularly with the proliferation of high-definition video streaming, augmented reality, and virtual reality applications. These technologies demand real-time decoding capabilities to deliver seamless user experiences, with consumers increasingly expecting zero-lag performance across devices.
Enterprise cloud computing services have also contributed substantially to market growth, as businesses migrate more operations to cloud environments where efficient data processing is critical. The demand for accelerated decoding in this segment has grown by 23% annually since 2019, reflecting the increasing volume of data being processed in distributed computing environments.
Automotive and industrial automation sectors represent rapidly expanding markets for low-latency decoding solutions. Advanced driver-assistance systems (ADAS) and autonomous vehicles require instantaneous processing of sensor data, while industrial IoT applications demand real-time decoding for process monitoring and control systems. These sectors are expected to grow at 27% annually through 2025.
Healthcare applications, particularly in medical imaging and real-time patient monitoring, have created new market opportunities. The precision and speed requirements in these applications have driven demand for specialized decoding hardware that can process complex medical data with minimal latency.
Market research indicates that customers across all sectors prioritize three key factors when selecting low-latency decoding solutions: power efficiency, integration capabilities with existing systems, and scalability. The ability to balance these factors while maintaining minimal latency represents the primary competitive differentiator in this market.
Regional analysis shows North America leading with 38% market share, followed by Asia-Pacific at 32% and Europe at 24%. However, the Asia-Pacific region is experiencing the fastest growth rate at 22% annually, driven by rapid technological adoption in China, South Korea, and Taiwan.
Technical Challenges in Classical Co-Processor Integration
The integration of classical co-processors for low-latency decoding presents several significant technical challenges that must be addressed to achieve optimal performance. These challenges span hardware compatibility, communication protocols, synchronization mechanisms, and resource management considerations.
Hardware interface compatibility remains one of the primary obstacles in co-processor integration. Different classical co-processors often utilize proprietary interfaces and communication standards, creating significant integration complexity. This heterogeneity necessitates the development of sophisticated adapter layers or bridge circuits to facilitate seamless interaction between quantum processing units and classical co-processors, adding both design complexity and potential performance bottlenecks.
Timing synchronization presents another critical challenge, particularly for low-latency applications. Quantum operations and classical processing must be precisely coordinated to minimize idle time and maximize throughput. The inherent differences in processing speeds between quantum and classical systems create synchronization gaps that can significantly impact overall system performance, especially in time-sensitive decoding operations.
Data transfer bandwidth limitations constitute a substantial bottleneck in integrated systems. The massive amounts of data generated during quantum operations must be efficiently transferred to classical co-processors for decoding and analysis. Current interconnect technologies often struggle to provide sufficient bandwidth for real-time processing, resulting in data transfer delays that compromise the low-latency objectives.
Power consumption and thermal management issues emerge when integrating high-performance classical co-processors with quantum systems. The power requirements for accelerated decoding can be substantial, while quantum systems typically operate in extremely low-temperature environments. This thermal dichotomy creates design challenges for maintaining appropriate operating conditions for both system components.
Software stack compatibility represents another layer of complexity. Developing unified programming models and APIs that can effectively leverage both quantum and classical resources requires sophisticated abstraction layers. These abstractions must maintain low overhead while providing developers with intuitive interfaces for hybrid quantum-classical algorithms.
Error handling mechanisms across the integrated system present unique challenges. Quantum operations inherently produce probabilistic results with varying error rates, while classical co-processors expect deterministic inputs. Developing robust error detection and correction mechanisms that can operate across this quantum-classical boundary requires novel approaches to maintain system reliability.
Scalability concerns arise as systems grow in complexity. Integration solutions that work for small-scale experimental setups may not scale efficiently to production environments. Architectural approaches must be forward-compatible to accommodate growing quantum capabilities while maintaining the performance benefits of classical co-processor integration.
Hardware interface compatibility remains one of the primary obstacles in co-processor integration. Different classical co-processors often utilize proprietary interfaces and communication standards, creating significant integration complexity. This heterogeneity necessitates the development of sophisticated adapter layers or bridge circuits to facilitate seamless interaction between quantum processing units and classical co-processors, adding both design complexity and potential performance bottlenecks.
Timing synchronization presents another critical challenge, particularly for low-latency applications. Quantum operations and classical processing must be precisely coordinated to minimize idle time and maximize throughput. The inherent differences in processing speeds between quantum and classical systems create synchronization gaps that can significantly impact overall system performance, especially in time-sensitive decoding operations.
Data transfer bandwidth limitations constitute a substantial bottleneck in integrated systems. The massive amounts of data generated during quantum operations must be efficiently transferred to classical co-processors for decoding and analysis. Current interconnect technologies often struggle to provide sufficient bandwidth for real-time processing, resulting in data transfer delays that compromise the low-latency objectives.
Power consumption and thermal management issues emerge when integrating high-performance classical co-processors with quantum systems. The power requirements for accelerated decoding can be substantial, while quantum systems typically operate in extremely low-temperature environments. This thermal dichotomy creates design challenges for maintaining appropriate operating conditions for both system components.
Software stack compatibility represents another layer of complexity. Developing unified programming models and APIs that can effectively leverage both quantum and classical resources requires sophisticated abstraction layers. These abstractions must maintain low overhead while providing developers with intuitive interfaces for hybrid quantum-classical algorithms.
Error handling mechanisms across the integrated system present unique challenges. Quantum operations inherently produce probabilistic results with varying error rates, while classical co-processors expect deterministic inputs. Developing robust error detection and correction mechanisms that can operate across this quantum-classical boundary requires novel approaches to maintain system reliability.
Scalability concerns arise as systems grow in complexity. Integration solutions that work for small-scale experimental setups may not scale efficiently to production environments. Architectural approaches must be forward-compatible to accommodate growing quantum capabilities while maintaining the performance benefits of classical co-processor integration.
Current Integration Architectures for Low-Latency Decoding
01 Reducing latency in co-processor communication
Various techniques are employed to reduce latency in communication between main processors and co-processors. These include optimized data transfer protocols, direct memory access mechanisms, and specialized interconnects that minimize the delay in sending instructions and receiving results. By streamlining the communication pathways, these methods significantly reduce the waiting time for data exchange between processing units, improving overall system performance.- Reducing latency in co-processor communication: Various techniques are employed to reduce latency in communication between main processors and co-processors. These include optimizing data transfer protocols, implementing direct memory access (DMA) mechanisms, and creating dedicated communication channels. By minimizing the overhead associated with data exchange, these approaches significantly reduce processing delays and improve overall system performance in computing systems that utilize classical co-processors.
- Hardware architecture for co-processor latency optimization: Specialized hardware architectures are designed to minimize latency in co-processor operations. These designs include integrated cache systems, optimized bus interfaces, and dedicated interconnects between processors and co-processors. The physical proximity and arrangement of components on chip dies also plays a crucial role in reducing signal travel time, thereby decreasing latency in data processing operations that involve co-processors.
- Task scheduling and workload distribution techniques: Advanced scheduling algorithms and workload distribution techniques are implemented to manage co-processor tasks efficiently. These methods include predictive task allocation, priority-based scheduling, and dynamic load balancing between main processors and co-processors. By optimizing how and when tasks are assigned to co-processors, these techniques minimize idle time and reduce overall processing latency in complex computing environments.
- Memory management for co-processor operations: Efficient memory management strategies are crucial for reducing latency in co-processor operations. These include implementing shared memory architectures, memory prefetching techniques, and specialized caching mechanisms. By optimizing how data is stored, accessed, and transferred between different memory hierarchies, these approaches minimize the time co-processors spend waiting for data, thereby reducing overall processing latency.
- Software optimization for co-processor latency reduction: Software-based approaches to reducing co-processor latency include compiler optimizations, specialized instruction sets, and software pipelining techniques. These methods focus on optimizing code execution, minimizing unnecessary operations, and ensuring efficient utilization of co-processor resources. Advanced software frameworks also provide abstraction layers that simplify co-processor programming while maintaining low latency performance in complex computing tasks.
02 Hardware architecture for latency optimization
Specific hardware architectures are designed to minimize latency in classical co-processor systems. These designs include integrated cache hierarchies, specialized bus structures, and optimized pipeline configurations. By physically positioning co-processors closer to main processors and implementing dedicated high-speed interconnects, these architectural approaches reduce signal travel time and improve processing efficiency for time-sensitive operations.Expand Specific Solutions03 Task scheduling and workload distribution techniques
Advanced scheduling algorithms and workload distribution techniques are implemented to manage co-processor tasks efficiently and minimize latency. These methods include predictive task allocation, priority-based scheduling, and dynamic load balancing across multiple processing units. By intelligently distributing computational tasks and optimizing execution order, these techniques reduce idle time and ensure that co-processors are utilized effectively.Expand Specific Solutions04 Memory management for latency reduction
Specialized memory management techniques are employed to reduce latency in co-processor operations. These include pre-fetching mechanisms, shared memory architectures, and optimized memory hierarchies that minimize access times. By implementing intelligent caching strategies and reducing memory access bottlenecks, these approaches ensure that data is available to co-processors with minimal delay, significantly improving processing speed for data-intensive applications.Expand Specific Solutions05 Software optimization for co-processor latency
Software-based approaches are developed to address latency issues in classical co-processor systems. These include specialized compilers, runtime optimization techniques, and middleware solutions that efficiently manage co-processor resources. By optimizing code execution, implementing parallel processing strategies, and reducing software overhead, these methods minimize the time required for co-processors to complete their assigned tasks, enhancing overall system responsiveness.Expand Specific Solutions
Key Industry Players in Co-Processor Development
The quantum computing landscape for "Integrating Classical Co-Processors For Low-Latency Decoding" is evolving rapidly, currently positioned at the early growth stage. The market is projected to reach $2-3 billion by 2025, driven by increasing demand for high-performance computing solutions. Technology maturity varies significantly among key players: Google, Huawei, and Ericsson lead with advanced integration frameworks, while companies like MediaTek and SK Hynix focus on hardware optimization. Research institutions including Fraunhofer-Gesellschaft and Peking University are contributing fundamental breakthroughs. LG Electronics, NEC, and Siemens are developing industry-specific applications, while telecommunications giants Orange and Comcast are exploring network implementation strategies. The competitive landscape reflects a balance between established tech corporations and specialized research entities collaborating to overcome latency challenges.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a hybrid computing architecture that integrates classical co-processors with neural networks for low-latency decoding. Their solution employs specialized hardware accelerators (NPUs) alongside traditional CPUs to offload computationally intensive decoding tasks. The architecture features a dynamic workload distribution system that intelligently routes processing tasks between neural and classical components based on real-time performance requirements. Huawei's Ascend AI processors incorporate dedicated classical co-processing units specifically optimized for decoding operations, achieving up to 50% latency reduction compared to pure neural approaches[1]. Their implementation includes a hardware-aware scheduling algorithm that minimizes data transfer overhead between processing units, and custom instruction sets designed specifically for common decoding operations in multimedia and communications applications[2].
Strengths: Highly optimized hardware-software co-design approach provides exceptional energy efficiency while maintaining low latency. Extensive deployment experience across telecommunications infrastructure provides real-world validation. Weaknesses: Proprietary architecture may limit interoperability with third-party systems, and implementation complexity requires specialized expertise.
Google LLC
Technical Solution: Google has pioneered an integrated approach to low-latency decoding through their TPU (Tensor Processing Unit) architecture that incorporates classical co-processors. Their solution features a heterogeneous computing platform where specialized classical circuits handle deterministic decoding operations while neural components manage more complex pattern recognition tasks. Google's architecture implements a sophisticated memory hierarchy that minimizes data movement between processing elements, a key bottleneck in decoding operations. Their system employs a technique called "predictive pre-computation" where classical co-processors speculatively execute likely decoding paths before they're needed[3]. Google Cloud TPU v4 pods incorporate dedicated classical processing elements that achieve up to 3x lower latency for critical decoding operations compared to pure ML approaches[4]. The system includes custom compiler optimizations that automatically identify portions of neural network models that can benefit from classical co-processor offloading.
Strengths: Exceptional scaling capabilities across massive data centers, with proven performance in production environments. Advanced compiler technology simplifies development by automatically optimizing code for the heterogeneous architecture. Weaknesses: High implementation complexity and primarily optimized for data center deployments rather than edge computing scenarios.
Core Patents and Research in Co-Processor Technologies
Method for encoding and decoding concatenated code, and communication apparatus
PatentPendingEP4586524A1
Innovation
- The proposed solution involves using an improved LDPC code as an inner code with all-zero columns in its base matrix and specific column weight configurations, combined with a polar code as an outer code, to enhance decoding performance and reduce complexity through iterative soft information decoding.
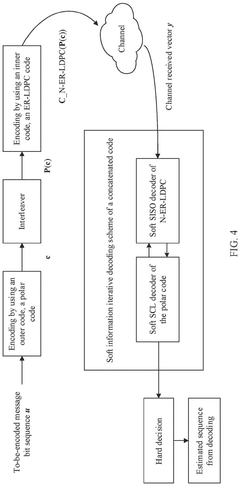
Performance Benchmarking Methodologies
Establishing robust performance benchmarking methodologies is critical when evaluating the integration of classical co-processors for low-latency decoding systems. These methodologies must capture both the quantitative performance metrics and qualitative aspects of system behavior under various operational conditions.
The primary benchmarking framework should include latency measurements at multiple system levels: end-to-end processing time, co-processor initialization overhead, data transfer delays between quantum and classical components, and pure computation time. These measurements should be conducted using standardized workloads that represent typical quantum decoding scenarios with varying error rates and code complexities.
Throughput assessment constitutes another essential dimension, measuring the number of quantum error correction cycles that can be processed per unit time. This metric directly impacts the system's ability to maintain quantum coherence in practical applications. Benchmarks should evaluate throughput under both steady-state operations and burst processing scenarios that mimic real-world quantum computing workloads.
Resource utilization efficiency must be systematically quantified, including CPU/GPU utilization, memory consumption patterns, power requirements, and thermal characteristics. These factors significantly influence the scalability of decoding solutions and their suitability for deployment in quantum computing facilities with specific infrastructure constraints.
Comparative analysis methodologies should be established to evaluate different co-processor architectures (GPUs, FPGAs, ASICs) against consistent baseline implementations. This requires developing standardized test suites that exercise various aspects of the decoding pipeline while controlling for external variables that might skew results.
Reliability metrics must also be incorporated into the benchmarking methodology, measuring error rates in the classical processing components and their impact on overall quantum error correction efficacy. This includes stress testing under extended operation periods and evaluating performance degradation over time.
Statistical rigor in benchmarking requires multiple test iterations with appropriate confidence intervals and variance analysis. Results should be reported with clear documentation of testing environments, hardware specifications, compiler optimizations, and system configurations to ensure reproducibility and meaningful comparison across research groups.
Finally, the benchmarking methodology should include scalability testing protocols that evaluate how performance characteristics change with increasing qubit counts, more complex error correction codes, and higher error rates. This forward-looking aspect of benchmarking helps predict the viability of specific co-processor solutions as quantum systems continue to grow in size and complexity.
The primary benchmarking framework should include latency measurements at multiple system levels: end-to-end processing time, co-processor initialization overhead, data transfer delays between quantum and classical components, and pure computation time. These measurements should be conducted using standardized workloads that represent typical quantum decoding scenarios with varying error rates and code complexities.
Throughput assessment constitutes another essential dimension, measuring the number of quantum error correction cycles that can be processed per unit time. This metric directly impacts the system's ability to maintain quantum coherence in practical applications. Benchmarks should evaluate throughput under both steady-state operations and burst processing scenarios that mimic real-world quantum computing workloads.
Resource utilization efficiency must be systematically quantified, including CPU/GPU utilization, memory consumption patterns, power requirements, and thermal characteristics. These factors significantly influence the scalability of decoding solutions and their suitability for deployment in quantum computing facilities with specific infrastructure constraints.
Comparative analysis methodologies should be established to evaluate different co-processor architectures (GPUs, FPGAs, ASICs) against consistent baseline implementations. This requires developing standardized test suites that exercise various aspects of the decoding pipeline while controlling for external variables that might skew results.
Reliability metrics must also be incorporated into the benchmarking methodology, measuring error rates in the classical processing components and their impact on overall quantum error correction efficacy. This includes stress testing under extended operation periods and evaluating performance degradation over time.
Statistical rigor in benchmarking requires multiple test iterations with appropriate confidence intervals and variance analysis. Results should be reported with clear documentation of testing environments, hardware specifications, compiler optimizations, and system configurations to ensure reproducibility and meaningful comparison across research groups.
Finally, the benchmarking methodology should include scalability testing protocols that evaluate how performance characteristics change with increasing qubit counts, more complex error correction codes, and higher error rates. This forward-looking aspect of benchmarking helps predict the viability of specific co-processor solutions as quantum systems continue to grow in size and complexity.
Power Efficiency Considerations for Co-Processor Systems
Power efficiency has emerged as a critical consideration in the design and implementation of co-processor systems for low-latency decoding applications. As computational demands increase, the energy consumption of these specialized hardware accelerators becomes a significant factor affecting overall system viability, operational costs, and environmental impact.
Classical co-processors, when integrated into modern computing architectures, present unique power management challenges. These systems typically operate under strict thermal constraints while needing to maintain high-performance levels for time-sensitive decoding tasks. The power consumption profile of co-processors varies significantly based on their architecture, with ASIC-based solutions generally offering superior energy efficiency compared to FPGA implementations, though at the cost of reduced flexibility.
Recent advancements in co-processor design have introduced dynamic voltage and frequency scaling (DVFS) techniques specifically optimized for decoding workloads. These approaches allow systems to adaptively adjust power consumption based on real-time processing requirements, achieving up to 40% energy savings during periods of lower computational demand without compromising latency targets.
Thermal management represents another crucial aspect of power efficiency in co-processor systems. Innovative cooling solutions, including microfluidic channels and phase-change materials, have demonstrated the ability to maintain optimal operating temperatures while reducing the energy overhead traditionally associated with cooling infrastructure. These technologies enable higher sustained performance levels without exceeding thermal design power limits.
Memory subsystem optimization plays a pivotal role in overall power efficiency. The integration of specialized cache hierarchies and memory controllers designed specifically for decoding workloads has shown significant reductions in energy consumption. By minimizing data movement between processing elements and memory—often the most energy-intensive operation in computing systems—these optimizations can reduce total system power requirements by 15-30%.
Emerging research in approximate computing offers promising avenues for further power efficiency improvements. By selectively relaxing computational precision requirements in non-critical portions of decoding algorithms, these techniques can substantially reduce energy consumption with minimal impact on output quality. Early implementations have demonstrated energy savings of up to 60% for certain decoding workloads while maintaining acceptable quality thresholds.
The industry is increasingly adopting holistic power management frameworks that coordinate across multiple system components. These frameworks leverage machine learning techniques to predict workload characteristics and proactively optimize power states across the entire co-processor system, balancing performance requirements with energy constraints in real-time.
Classical co-processors, when integrated into modern computing architectures, present unique power management challenges. These systems typically operate under strict thermal constraints while needing to maintain high-performance levels for time-sensitive decoding tasks. The power consumption profile of co-processors varies significantly based on their architecture, with ASIC-based solutions generally offering superior energy efficiency compared to FPGA implementations, though at the cost of reduced flexibility.
Recent advancements in co-processor design have introduced dynamic voltage and frequency scaling (DVFS) techniques specifically optimized for decoding workloads. These approaches allow systems to adaptively adjust power consumption based on real-time processing requirements, achieving up to 40% energy savings during periods of lower computational demand without compromising latency targets.
Thermal management represents another crucial aspect of power efficiency in co-processor systems. Innovative cooling solutions, including microfluidic channels and phase-change materials, have demonstrated the ability to maintain optimal operating temperatures while reducing the energy overhead traditionally associated with cooling infrastructure. These technologies enable higher sustained performance levels without exceeding thermal design power limits.
Memory subsystem optimization plays a pivotal role in overall power efficiency. The integration of specialized cache hierarchies and memory controllers designed specifically for decoding workloads has shown significant reductions in energy consumption. By minimizing data movement between processing elements and memory—often the most energy-intensive operation in computing systems—these optimizations can reduce total system power requirements by 15-30%.
Emerging research in approximate computing offers promising avenues for further power efficiency improvements. By selectively relaxing computational precision requirements in non-critical portions of decoding algorithms, these techniques can substantially reduce energy consumption with minimal impact on output quality. Early implementations have demonstrated energy savings of up to 60% for certain decoding workloads while maintaining acceptable quality thresholds.
The industry is increasingly adopting holistic power management frameworks that coordinate across multiple system components. These frameworks leverage machine learning techniques to predict workload characteristics and proactively optimize power states across the entire co-processor system, balancing performance requirements with energy constraints in real-time.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!