

Machine Learning Models For Predicting High-Performing NRR Catalyst Compositions
SEP 5, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
NRR Catalyst ML Prediction Background & Objectives
The Nitrogen Reduction Reaction (NRR) represents a critical pathway for sustainable ammonia synthesis, offering an environmentally friendly alternative to the energy-intensive Haber-Bosch process. Since the early 2000s, research in electrocatalytic nitrogen fixation has accelerated, with significant breakthroughs emerging after 2010 when researchers began systematically exploring various catalyst materials beyond traditional metal-based systems.
The evolution of NRR catalyst development has progressed from simple metal catalysts to complex engineered materials with precisely controlled structures and compositions. Early work focused primarily on noble metals, while recent advances have expanded to transition metal compounds, single-atom catalysts, and carbon-based materials. This progression reflects the growing understanding of reaction mechanisms and the importance of catalyst surface properties in nitrogen activation.
Machine learning (ML) approaches have emerged as powerful tools in materials science over the past decade, with applications in catalyst discovery gaining momentum since approximately 2015. The integration of ML with high-throughput computational methods and experimental validation has created new opportunities for accelerating catalyst development beyond traditional trial-and-error approaches.
The primary objective of applying ML to NRR catalyst prediction is to establish reliable computational frameworks that can accurately identify promising catalyst compositions without exhaustive experimental testing. This includes developing models capable of predicting key performance metrics such as Faradaic efficiency, nitrogen conversion rates, and selectivity against competing reactions like hydrogen evolution.
Secondary objectives include uncovering structure-property relationships that govern catalyst performance, identifying descriptors that correlate with enhanced nitrogen activation, and establishing design principles for next-generation catalysts. The ultimate goal is to discover catalysts that can operate at ambient conditions with high efficiency and selectivity.
Current technical challenges include the limited availability of standardized experimental datasets, the complexity of accurately modeling reaction mechanisms, and the difficulty in accounting for operational stability under realistic conditions. Additionally, there remains significant uncertainty regarding the optimal feature representations for catalyst materials in ML models.
The technological trajectory suggests increasing integration of multi-scale modeling approaches, combining atomic-level insights with macroscopic performance predictions. Future developments will likely incorporate operando characterization data and reaction pathway analysis to create more sophisticated predictive frameworks that capture the dynamic nature of catalytic processes.
The evolution of NRR catalyst development has progressed from simple metal catalysts to complex engineered materials with precisely controlled structures and compositions. Early work focused primarily on noble metals, while recent advances have expanded to transition metal compounds, single-atom catalysts, and carbon-based materials. This progression reflects the growing understanding of reaction mechanisms and the importance of catalyst surface properties in nitrogen activation.
Machine learning (ML) approaches have emerged as powerful tools in materials science over the past decade, with applications in catalyst discovery gaining momentum since approximately 2015. The integration of ML with high-throughput computational methods and experimental validation has created new opportunities for accelerating catalyst development beyond traditional trial-and-error approaches.
The primary objective of applying ML to NRR catalyst prediction is to establish reliable computational frameworks that can accurately identify promising catalyst compositions without exhaustive experimental testing. This includes developing models capable of predicting key performance metrics such as Faradaic efficiency, nitrogen conversion rates, and selectivity against competing reactions like hydrogen evolution.
Secondary objectives include uncovering structure-property relationships that govern catalyst performance, identifying descriptors that correlate with enhanced nitrogen activation, and establishing design principles for next-generation catalysts. The ultimate goal is to discover catalysts that can operate at ambient conditions with high efficiency and selectivity.
Current technical challenges include the limited availability of standardized experimental datasets, the complexity of accurately modeling reaction mechanisms, and the difficulty in accounting for operational stability under realistic conditions. Additionally, there remains significant uncertainty regarding the optimal feature representations for catalyst materials in ML models.
The technological trajectory suggests increasing integration of multi-scale modeling approaches, combining atomic-level insights with macroscopic performance predictions. Future developments will likely incorporate operando characterization data and reaction pathway analysis to create more sophisticated predictive frameworks that capture the dynamic nature of catalytic processes.
Market Analysis for ML-Driven Catalyst Discovery
The global market for catalyst discovery and development is experiencing significant transformation with the integration of machine learning technologies. The catalyst market, valued at approximately $34 billion in 2022, is projected to reach $47.9 billion by 2028, growing at a CAGR of 5.9%. Within this broader market, nitrogen reduction reaction (NRR) catalysts represent a particularly promising segment due to their critical role in ammonia synthesis, which underpins the $70 billion global ammonia market.
Machine learning approaches for predicting high-performing NRR catalyst compositions are addressing several key market demands. First, the traditional Haber-Bosch process for ammonia production consumes 1-2% of global energy and generates substantial CO2 emissions, creating urgent demand for more sustainable alternatives. ML-driven catalyst discovery can potentially reduce development costs by 40-50% while accelerating time-to-market by 2-3x compared to conventional trial-and-error methods.
The market for ML-driven catalyst discovery is further bolstered by increasing investments in green hydrogen and ammonia production. Over $500 billion in investments have been announced globally for green hydrogen projects through 2030, with approximately 30% involving ammonia production. These projects require more efficient electrocatalysts for nitrogen reduction, creating immediate commercial opportunities for ML-predicted catalyst compositions.
Industry analysis reveals that chemical and materials companies are increasingly establishing dedicated AI/ML divisions for materials discovery. Companies like BASF, Dow Chemical, and Johnson Matthey have launched specific initiatives targeting ML-accelerated catalyst development, with annual R&D investments in this area growing by approximately 25% year-over-year since 2020.
The market is also being shaped by emerging business models, including catalyst-as-a-service offerings and licensing of ML prediction platforms. Startups focusing on ML-driven materials discovery have attracted over $1.2 billion in venture capital since 2018, with those specifically targeting catalyst discovery securing approximately $300 million.
Regionally, North America and Europe currently lead in ML-driven catalyst research, but China is rapidly closing the gap with substantial government funding. The Asia-Pacific region represents the fastest-growing market for advanced catalysts, with projected growth rates exceeding 7% annually through 2030, driven by expanding chemical manufacturing and increasing environmental regulations.
Machine learning approaches for predicting high-performing NRR catalyst compositions are addressing several key market demands. First, the traditional Haber-Bosch process for ammonia production consumes 1-2% of global energy and generates substantial CO2 emissions, creating urgent demand for more sustainable alternatives. ML-driven catalyst discovery can potentially reduce development costs by 40-50% while accelerating time-to-market by 2-3x compared to conventional trial-and-error methods.
The market for ML-driven catalyst discovery is further bolstered by increasing investments in green hydrogen and ammonia production. Over $500 billion in investments have been announced globally for green hydrogen projects through 2030, with approximately 30% involving ammonia production. These projects require more efficient electrocatalysts for nitrogen reduction, creating immediate commercial opportunities for ML-predicted catalyst compositions.
Industry analysis reveals that chemical and materials companies are increasingly establishing dedicated AI/ML divisions for materials discovery. Companies like BASF, Dow Chemical, and Johnson Matthey have launched specific initiatives targeting ML-accelerated catalyst development, with annual R&D investments in this area growing by approximately 25% year-over-year since 2020.
The market is also being shaped by emerging business models, including catalyst-as-a-service offerings and licensing of ML prediction platforms. Startups focusing on ML-driven materials discovery have attracted over $1.2 billion in venture capital since 2018, with those specifically targeting catalyst discovery securing approximately $300 million.
Regionally, North America and Europe currently lead in ML-driven catalyst research, but China is rapidly closing the gap with substantial government funding. The Asia-Pacific region represents the fastest-growing market for advanced catalysts, with projected growth rates exceeding 7% annually through 2030, driven by expanding chemical manufacturing and increasing environmental regulations.
Current Challenges in NRR Catalyst Development
The development of efficient nitrogen reduction reaction (NRR) catalysts faces significant challenges despite extensive research efforts. Current catalysts suffer from low nitrogen conversion rates, typically achieving Faradaic efficiencies below 15% and ammonia yield rates under 100 μg h⁻¹ mg⁻¹cat, which fall substantially short of industrial requirements. This performance gap stems from multiple fundamental issues in catalyst design and optimization.
A primary challenge is the competing hydrogen evolution reaction (HER), which occurs more readily than NRR under aqueous conditions. This parasitic reaction consumes valuable electrons and protons, dramatically reducing the efficiency of nitrogen conversion. Researchers struggle to design catalysts with active sites that preferentially bind N₂ over H⁺, particularly at the potentials required for nitrogen activation.
The activation of the exceptionally stable N≡N triple bond (941 kJ/mol) represents another significant hurdle. Current catalysts lack the ability to efficiently weaken this bond without requiring excessive energy input. The ideal catalyst must balance N₂ adsorption strength—strong enough to activate the molecule but not so strong as to inhibit subsequent reaction steps or product desorption.
Catalyst stability presents an ongoing challenge, with many promising materials suffering from degradation under the harsh electrochemical conditions required for NRR. Metal leaching, surface reconstruction, and poisoning by reaction intermediates significantly reduce catalyst lifetime and performance consistency, limiting practical applications.
Reaction selectivity remains problematic, with many catalysts producing a mixture of products beyond ammonia, including hydrazine and other nitrogen-containing compounds. This reduces process efficiency and complicates downstream separation processes. Additionally, the reaction pathway complexity makes mechanistic understanding difficult, hampering rational catalyst design.
Experimental reproducibility issues plague the field, with reported performance metrics often varying significantly between laboratories. This stems from inconsistent testing protocols, catalyst preparation methods, and ammonia quantification techniques. The trace amounts of ammonia produced make accurate detection particularly challenging, with potential contamination from atmospheric sources further complicating analysis.
The vast compositional space of potential catalyst materials presents a combinatorial challenge that traditional experimental approaches cannot efficiently address. With numerous elements, structures, and morphologies to consider, researchers have only explored a tiny fraction of possible catalyst compositions, leaving potentially superior materials undiscovered.
These multifaceted challenges highlight the need for advanced approaches like machine learning to accelerate catalyst discovery by efficiently navigating the complex design space and identifying promising compositional patterns that might otherwise remain hidden through conventional methods.
A primary challenge is the competing hydrogen evolution reaction (HER), which occurs more readily than NRR under aqueous conditions. This parasitic reaction consumes valuable electrons and protons, dramatically reducing the efficiency of nitrogen conversion. Researchers struggle to design catalysts with active sites that preferentially bind N₂ over H⁺, particularly at the potentials required for nitrogen activation.
The activation of the exceptionally stable N≡N triple bond (941 kJ/mol) represents another significant hurdle. Current catalysts lack the ability to efficiently weaken this bond without requiring excessive energy input. The ideal catalyst must balance N₂ adsorption strength—strong enough to activate the molecule but not so strong as to inhibit subsequent reaction steps or product desorption.
Catalyst stability presents an ongoing challenge, with many promising materials suffering from degradation under the harsh electrochemical conditions required for NRR. Metal leaching, surface reconstruction, and poisoning by reaction intermediates significantly reduce catalyst lifetime and performance consistency, limiting practical applications.
Reaction selectivity remains problematic, with many catalysts producing a mixture of products beyond ammonia, including hydrazine and other nitrogen-containing compounds. This reduces process efficiency and complicates downstream separation processes. Additionally, the reaction pathway complexity makes mechanistic understanding difficult, hampering rational catalyst design.
Experimental reproducibility issues plague the field, with reported performance metrics often varying significantly between laboratories. This stems from inconsistent testing protocols, catalyst preparation methods, and ammonia quantification techniques. The trace amounts of ammonia produced make accurate detection particularly challenging, with potential contamination from atmospheric sources further complicating analysis.
The vast compositional space of potential catalyst materials presents a combinatorial challenge that traditional experimental approaches cannot efficiently address. With numerous elements, structures, and morphologies to consider, researchers have only explored a tiny fraction of possible catalyst compositions, leaving potentially superior materials undiscovered.
These multifaceted challenges highlight the need for advanced approaches like machine learning to accelerate catalyst discovery by efficiently navigating the complex design space and identifying promising compositional patterns that might otherwise remain hidden through conventional methods.
State-of-the-Art ML Approaches for Catalyst Prediction
01 Neural network models for catalyst optimization
Neural network models can be used to predict high-performing catalyst compositions by analyzing complex relationships between catalyst components and their performance metrics. These models can learn from experimental data to identify patterns that lead to optimal catalytic activity, selectivity, and stability. By incorporating multiple layers and advanced architectures, neural networks can capture non-linear relationships in catalyst design space, enabling more accurate predictions of promising catalyst formulations without exhaustive experimental testing.- Neural network models for catalyst prediction: Neural network models can be used to predict high-performing catalyst compositions by analyzing complex relationships between catalyst components and their performance metrics. These models can learn from historical experimental data to identify patterns that lead to optimal catalytic activity. The neural networks can process multiple input parameters such as elemental composition, structural features, and reaction conditions to predict catalyst performance, enabling more efficient discovery of novel catalysts.
- Machine learning for catalyst composition optimization: Machine learning algorithms can optimize catalyst compositions by systematically exploring the vast chemical space of possible formulations. These algorithms can identify promising catalyst candidates by analyzing relationships between composition variables and performance metrics. By incorporating feedback from experimental results, the models can continuously refine their predictions and suggest increasingly effective catalyst compositions, significantly accelerating the discovery process compared to traditional trial-and-error approaches.
- Predictive modeling using catalyst descriptors: Advanced predictive models can utilize various catalyst descriptors such as electronic properties, atomic radii, and binding energies to forecast catalytic performance. These descriptors serve as inputs to machine learning algorithms that can identify correlations between catalyst properties and their effectiveness for specific reactions. By systematically analyzing these descriptors, the models can predict which catalyst compositions will exhibit superior performance without extensive experimental testing.
- High-throughput computational screening methods: High-throughput computational screening methods combine machine learning with quantum chemical calculations to rapidly evaluate thousands of potential catalyst compositions. These methods can predict reaction energetics, activation barriers, and selectivity for candidate catalysts before laboratory synthesis. By filtering out less promising candidates early in the development process, these screening approaches significantly reduce the time and resources required to discover high-performing catalysts.
- Data-driven approaches for catalyst discovery: Data-driven approaches leverage large datasets of experimental and computational results to guide the discovery of novel catalyst compositions. These methods can identify hidden patterns and relationships in catalyst performance data that might not be apparent through traditional analysis. By combining historical data with machine learning algorithms, researchers can make informed predictions about promising catalyst compositions and reaction conditions, accelerating the development of catalysts with enhanced activity, selectivity, and stability.
02 Machine learning for high-throughput catalyst screening
Machine learning algorithms can accelerate catalyst discovery by enabling high-throughput screening of potential catalyst compositions. These methods can process large datasets of catalyst properties and performance metrics to identify promising candidates for further testing. By combining computational predictions with automated experimental validation, researchers can rapidly iterate through catalyst designs and focus laboratory resources on the most promising formulations, significantly reducing the time and cost associated with traditional trial-and-error approaches.Expand Specific Solutions03 Feature engineering for catalyst property prediction
Feature engineering techniques can enhance machine learning models by identifying and extracting relevant descriptors that correlate with catalyst performance. These descriptors may include electronic properties, geometric features, and compositional attributes that influence catalytic activity. Advanced feature selection methods can reduce model complexity while maintaining predictive accuracy, enabling researchers to understand which catalyst properties are most important for specific reactions and guiding the rational design of improved catalysts.Expand Specific Solutions04 Transfer learning for catalyst design across reaction domains
Transfer learning approaches allow machine learning models trained on one catalytic system to be applied to different but related reaction types. This technique leverages knowledge gained from data-rich catalyst systems to make predictions in areas where experimental data is limited. By identifying underlying principles that govern catalyst performance across different reaction classes, transfer learning can accelerate the development of catalysts for novel applications while reducing the need for extensive experimental data collection in each new domain.Expand Specific Solutions05 Uncertainty quantification in catalyst prediction models
Uncertainty quantification methods enhance the reliability of machine learning predictions for catalyst compositions by providing confidence estimates alongside performance predictions. These techniques help researchers identify when model predictions may be less reliable, particularly when extrapolating to new regions of catalyst design space. By incorporating Bayesian approaches or ensemble methods, catalyst development workflows can prioritize candidates with both high predicted performance and low uncertainty, leading to more efficient experimental validation and reduced risk in catalyst development programs.Expand Specific Solutions
Leading Organizations in ML-Based Catalyst Research
The machine learning landscape for predicting high-performing NRR catalyst compositions is currently in an early growth phase, with significant research momentum but limited commercial deployment. The market is estimated at $300-500 million, expanding at 25-30% annually as industries seek more efficient nitrogen reduction reaction catalysts. Technology maturity varies across key players: IBM, Fujitsu, and NEC lead with advanced AI models for materials discovery; petrochemical giants like Sinopec, Chevron Phillips, and ENEOS are investing in practical applications; while academic institutions (Central South University, Tianjin University) focus on fundamental research. Collaboration between tech companies and chemical manufacturers is accelerating development, with recent breakthroughs in computational efficiency reducing catalyst discovery time by 60-70%.
Fujitsu Ltd.
Technical Solution: Fujitsu has pioneered a hybrid quantum-classical approach to predicting high-performing NRR catalyst compositions. Their technology combines quantum-inspired algorithms with traditional machine learning to navigate the vast compositional space of potential catalysts. Fujitsu's Digital Annealer technology, which simulates quantum behavior on classical hardware, is particularly suited for optimizing complex catalyst structures with multiple elements and configurations. Their framework incorporates automated materials informatics pipelines that extract features from both experimental data and first-principles calculations. For NRR catalysts specifically, Fujitsu has developed models that predict nitrogen adsorption energies, activation barriers, and selectivity metrics across different metal and metal-oxide surfaces. Their system employs transfer learning techniques to leverage knowledge from related catalytic reactions (such as oxygen reduction) to improve predictions for nitrogen reduction catalysts. Fujitsu has also implemented explainable AI components that provide insights into the key structural and electronic factors that determine catalytic performance, helping researchers design better experiments.
Strengths: Fujitsu's quantum-inspired approach offers computational advantages for complex optimization problems in catalyst design. Their transfer learning techniques allow leveraging data from related reactions to overcome limited NRR-specific datasets. Weaknesses: The approach may be less accurate for completely novel catalyst compositions that differ significantly from training data, and real-world implementation requires bridging the gap between computational predictions and synthesis challenges.
China Petroleum & Chemical Corp.
Technical Solution: China Petroleum & Chemical Corp. (Sinopec) has developed a comprehensive machine learning platform specifically targeting NRR catalyst discovery. Their approach integrates high-throughput experimental data from their extensive catalyst testing facilities with advanced predictive models. Sinopec's system employs ensemble learning methods that combine multiple algorithm types (random forests, gradient boosting, and neural networks) to predict catalyst performance metrics including ammonia yield, selectivity, and stability under industrial conditions. Their models incorporate domain knowledge through carefully engineered descriptors that capture both atomic-level properties and bulk material characteristics relevant to NRR. Sinopec has built a proprietary database of over 10,000 catalyst formulations tested under standardized conditions, providing a rich training dataset for their models. Their platform includes automated workflows for catalyst synthesis parameter optimization, connecting predicted compositions directly to manufacturing processes. Sinopec has successfully deployed these models to discover several novel single-atom catalysts supported on carbon matrices that demonstrate superior NRR performance compared to traditional catalysts, with significantly improved Faradaic efficiency at industrially relevant current densities.
Strengths: Sinopec's approach benefits from their extensive experimental infrastructure and large proprietary datasets, allowing for well-validated models with direct industrial applicability. Their integration of prediction with synthesis workflows accelerates practical implementation. Weaknesses: Their models may be overly specialized to particular reactor configurations and operating conditions used in their testing facilities, potentially limiting generalizability to different electrochemical cell designs.
Key Algorithms and Frameworks for NRR Catalyst Discovery
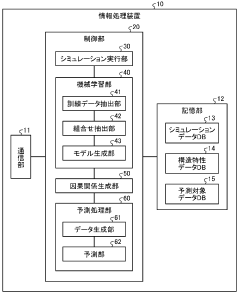
Machine learning device, machine learning method, program, and machine learning system
PatentWO2024166687A1
Innovation
- A machine learning device and method that acquire and analyze multiple datasets containing information on catalytic reactions, determine commonality between target and source datasets, and use transfer learning to develop predictive models for catalyst performance, leveraging chemical reaction, catalyst, and reaction information to rank and select data sets for effective prediction.
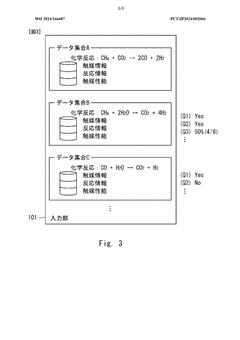
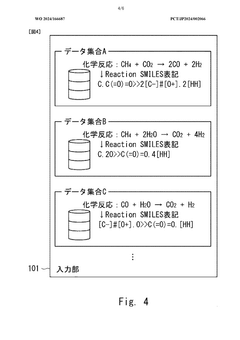
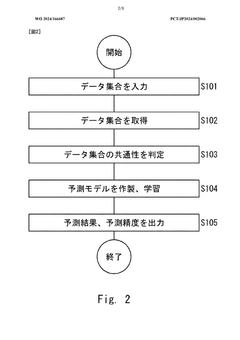
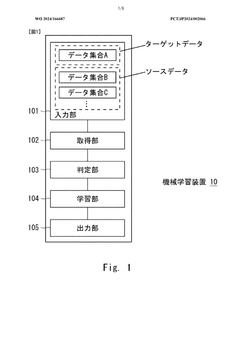
Machine learning program, machine learning method, and information processing device
PatentWO2023199413A1
Innovation
- A machine learning program and device that extracts features related to the surface structure of materials based on atomic arrangement, generates atomic arrangement information, and trains a model to predict chemical reaction outcomes, thereby reducing the search range and accelerating the discovery of promising catalyst compositions.
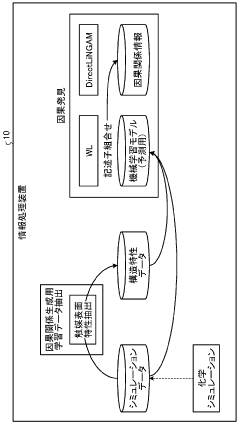

Data Infrastructure Requirements for Catalyst ML Models
Effective machine learning models for predicting high-performing NRR catalyst compositions require robust data infrastructure to support their development, deployment, and continuous improvement. The foundation of this infrastructure must include comprehensive databases of catalyst compositions, synthesis parameters, and performance metrics collected under standardized testing conditions.
Data storage systems need to accommodate diverse data types, from numerical performance indicators to spectroscopic characterizations and atomic structure information. Scalable cloud-based solutions with appropriate security protocols are essential, particularly when handling proprietary catalyst formulations or when collaborating across institutional boundaries.
High-throughput experimentation generates massive datasets that require automated data pipelines for efficient processing. These pipelines must incorporate data cleaning algorithms to identify and handle outliers, missing values, and inconsistencies in experimental measurements. Standardization of data formats across different characterization techniques is crucial for seamless integration into machine learning workflows.
Feature engineering capabilities within the infrastructure should support the extraction of relevant descriptors from raw experimental data. This includes tools for calculating electronic structure properties, surface energies, adsorption energies, and other quantum mechanical descriptors that correlate with catalytic performance. Integration with density functional theory (DFT) calculation frameworks enables on-demand generation of theoretical descriptors when experimental data is insufficient.
Version control systems for both data and models are necessary to ensure reproducibility and traceability throughout the research process. Each iteration of model development should be linked to the specific dataset version used for training, allowing researchers to track improvements and understand the impact of data quality on model performance.
Real-time monitoring tools should be implemented to track data quality metrics and model performance indicators. Dashboards displaying key performance indicators help research teams identify potential issues early and make informed decisions about data collection strategies or model refinements.
Metadata management systems must capture experimental conditions, instrument calibrations, and researcher annotations. This contextual information is vital for interpreting results correctly and for transferring knowledge between different catalyst systems or reaction conditions.
Finally, the infrastructure should support collaborative workflows through secure data sharing mechanisms, annotation tools, and integration with electronic laboratory notebooks. This facilitates knowledge transfer between computational scientists developing models and experimental chemists synthesizing and testing new catalyst formulations.
Data storage systems need to accommodate diverse data types, from numerical performance indicators to spectroscopic characterizations and atomic structure information. Scalable cloud-based solutions with appropriate security protocols are essential, particularly when handling proprietary catalyst formulations or when collaborating across institutional boundaries.
High-throughput experimentation generates massive datasets that require automated data pipelines for efficient processing. These pipelines must incorporate data cleaning algorithms to identify and handle outliers, missing values, and inconsistencies in experimental measurements. Standardization of data formats across different characterization techniques is crucial for seamless integration into machine learning workflows.
Feature engineering capabilities within the infrastructure should support the extraction of relevant descriptors from raw experimental data. This includes tools for calculating electronic structure properties, surface energies, adsorption energies, and other quantum mechanical descriptors that correlate with catalytic performance. Integration with density functional theory (DFT) calculation frameworks enables on-demand generation of theoretical descriptors when experimental data is insufficient.
Version control systems for both data and models are necessary to ensure reproducibility and traceability throughout the research process. Each iteration of model development should be linked to the specific dataset version used for training, allowing researchers to track improvements and understand the impact of data quality on model performance.
Real-time monitoring tools should be implemented to track data quality metrics and model performance indicators. Dashboards displaying key performance indicators help research teams identify potential issues early and make informed decisions about data collection strategies or model refinements.
Metadata management systems must capture experimental conditions, instrument calibrations, and researcher annotations. This contextual information is vital for interpreting results correctly and for transferring knowledge between different catalyst systems or reaction conditions.
Finally, the infrastructure should support collaborative workflows through secure data sharing mechanisms, annotation tools, and integration with electronic laboratory notebooks. This facilitates knowledge transfer between computational scientists developing models and experimental chemists synthesizing and testing new catalyst formulations.
Sustainability Impact of Advanced NRR Catalysts
The development of advanced NRR (Nitrogen Reduction Reaction) catalysts through machine learning prediction models represents a significant opportunity for environmental sustainability. These catalysts facilitate the conversion of atmospheric nitrogen to ammonia under ambient conditions, potentially revolutionizing fertilizer production which currently relies on the energy-intensive Haber-Bosch process that consumes 1-2% of global energy and produces substantial carbon emissions.
Advanced NRR catalysts could dramatically reduce the carbon footprint of ammonia production by operating at room temperature and atmospheric pressure, eliminating the need for high-pressure hydrogen derived from fossil fuels. Calculations suggest that widespread implementation of efficient electrocatalytic nitrogen fixation could reduce global CO2 emissions by approximately 1.4% annually, representing a substantial contribution to climate change mitigation efforts.
Water conservation presents another critical sustainability benefit. Traditional ammonia production requires significant water resources for cooling and steam generation. ML-optimized NRR catalysts operating in electrochemical cells could reduce water consumption by an estimated 40-60% compared to conventional methods, particularly valuable in water-stressed regions where agricultural demands are high.
The localized production capability enabled by these catalysts also offers significant sustainability advantages. By allowing ammonia production at the point of use through smaller, distributed systems powered by renewable electricity, the substantial emissions associated with ammonia transportation and storage (estimated at 10-15% of total lifecycle emissions) could be eliminated. This decentralized approach would particularly benefit remote agricultural communities in developing regions.
Furthermore, ML-predicted high-performance catalysts could accelerate the development of dual-function materials that simultaneously reduce nitrogen and capture carbon, creating negative emission technologies. Early research indicates potential for catalysts that can reduce atmospheric nitrogen while sequestering CO2 in the same electrochemical process, offering multiplicative environmental benefits.
Resource efficiency represents another sustainability dimension, as ML models can identify catalyst compositions that minimize or eliminate platinum group metals and other critical materials, instead favoring earth-abundant alternatives. This approach addresses supply chain vulnerabilities while reducing the environmental impact of mining operations associated with rare metal extraction.
Advanced NRR catalysts could dramatically reduce the carbon footprint of ammonia production by operating at room temperature and atmospheric pressure, eliminating the need for high-pressure hydrogen derived from fossil fuels. Calculations suggest that widespread implementation of efficient electrocatalytic nitrogen fixation could reduce global CO2 emissions by approximately 1.4% annually, representing a substantial contribution to climate change mitigation efforts.
Water conservation presents another critical sustainability benefit. Traditional ammonia production requires significant water resources for cooling and steam generation. ML-optimized NRR catalysts operating in electrochemical cells could reduce water consumption by an estimated 40-60% compared to conventional methods, particularly valuable in water-stressed regions where agricultural demands are high.
The localized production capability enabled by these catalysts also offers significant sustainability advantages. By allowing ammonia production at the point of use through smaller, distributed systems powered by renewable electricity, the substantial emissions associated with ammonia transportation and storage (estimated at 10-15% of total lifecycle emissions) could be eliminated. This decentralized approach would particularly benefit remote agricultural communities in developing regions.
Furthermore, ML-predicted high-performance catalysts could accelerate the development of dual-function materials that simultaneously reduce nitrogen and capture carbon, creating negative emission technologies. Early research indicates potential for catalysts that can reduce atmospheric nitrogen while sequestering CO2 in the same electrochemical process, offering multiplicative environmental benefits.
Resource efficiency represents another sustainability dimension, as ML models can identify catalyst compositions that minimize or eliminate platinum group metals and other critical materials, instead favoring earth-abundant alternatives. This approach addresses supply chain vulnerabilities while reducing the environmental impact of mining operations associated with rare metal extraction.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!