

Voice recognition device and voice recognition method, language model generating device and language model generating method, and computer program
A language model, speech recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as laborious, difficult to specify intention, difficulty, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0062] The present invention relates to speech recognition technology, and has main features of focusing on a specific task, accurately estimating the intention in what a speaker utters, thereby solving the following two points.
[0063] (1) Simply and appropriately collect a corpus with what a speaker might say for each intent.
[0064] (2) Matching arbitrary intentions to utterances (which are inconsistent with the task) is not enforced, but rather ignored.
[0065] Embodiments for solving these two points will be described in detail below with reference to the accompanying drawings.
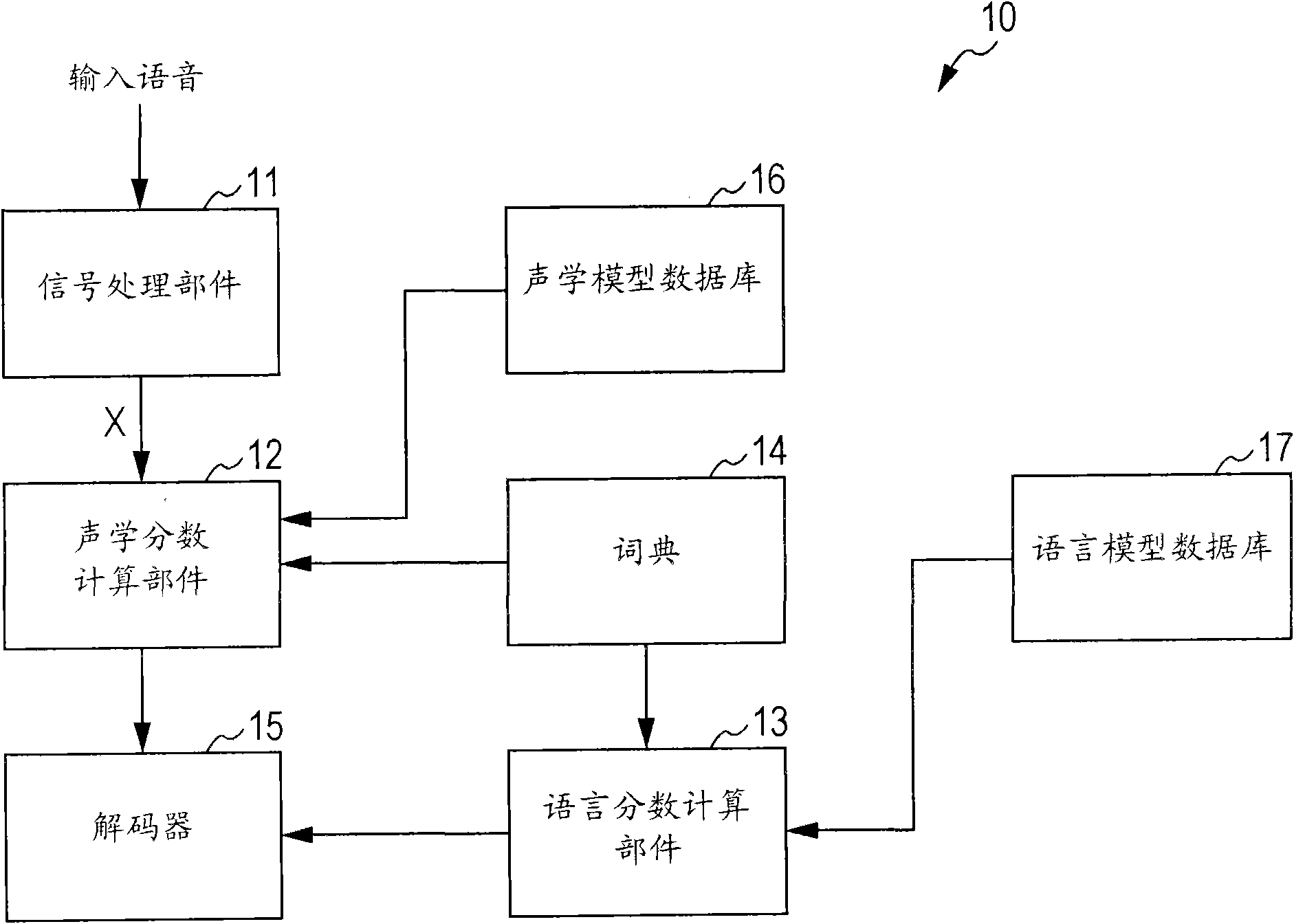
[0066] figure 1 The functional structure of the speech recognition device according to the embodiment of the present invention is schematically shown. The voice recognition device 10 in the drawing is equipped with a signal processing section 11 , an acoustic score calculation section 12 , a language score calculation section 13 , a dictionary 14 and a decoder 15 . The speech recognition d...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More