

Information extraction method of news webpage and terminal
An information extraction and web page technology, applied in the direction of network data retrieval, network data indexing, and other database retrieval, etc., can solve the problems affecting the efficiency and accuracy of information extraction of news web pages, and achieve the goal of improving information extraction efficiency, accuracy, and improvement. The effect of efficiency and accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
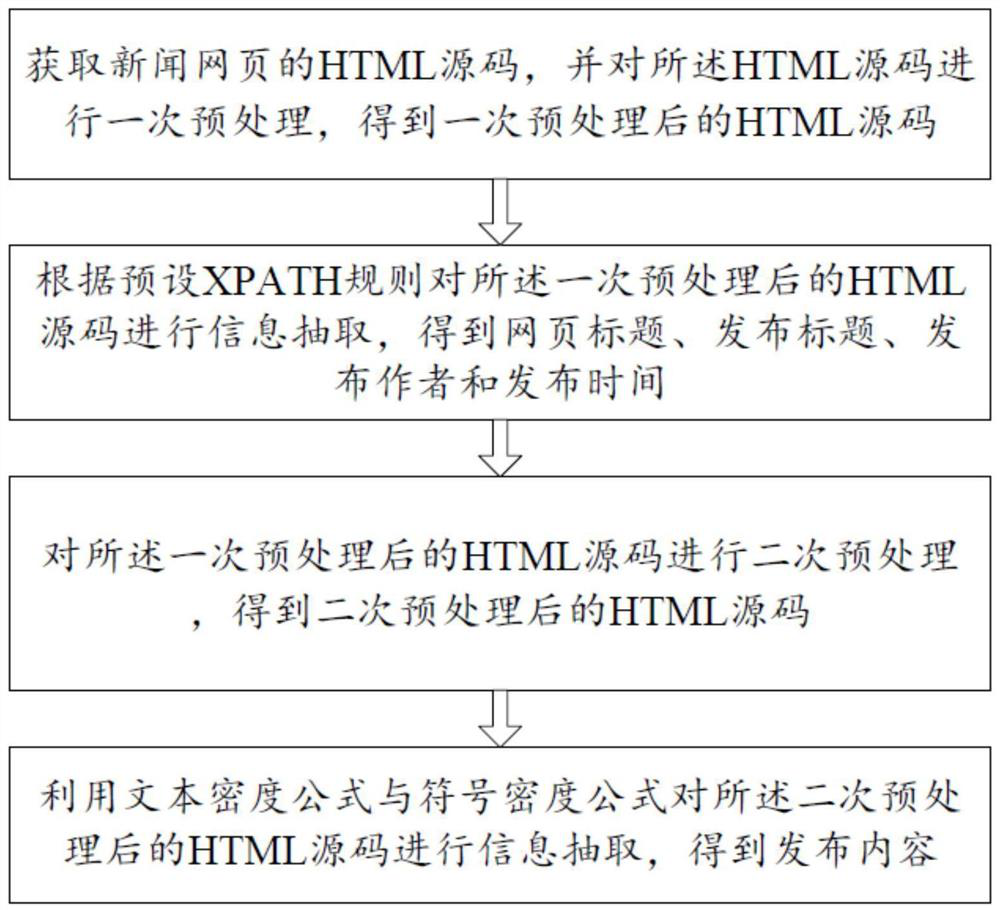
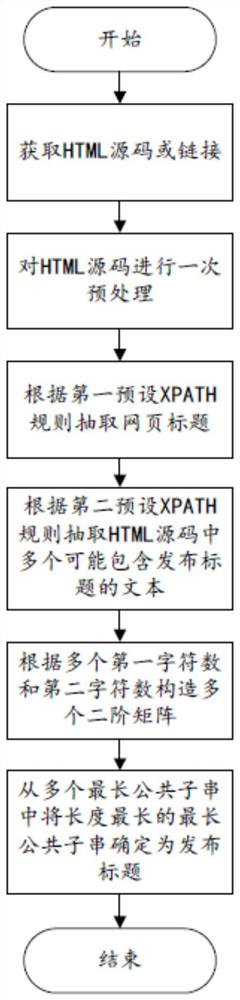
[0092] Please refer to figure 1 , 3 -5, the information extraction method of a kind of news webpage of the present embodiment, comprises:
[0093] S1. Obtain the HTML source code of the news web page, and perform a preprocessing on the HTML source code to obtain a preprocessed HTML source code, including:
[0094] S11. Obtain the HTML source code of the news web page;
[0095] In another optional implementation manner, a link to a news webpage is obtained;
[0096] If the link to the news web page is obtained, the HTML source code corresponding to the link will be automatically downloaded;
[0097] S12. Obtain preset keywords, the source code of the first preset tag and the source code of the first preset sub-tag;
[0098] Wherein, the preset keywords include disclaimer and advertisement service;
[0099] S13. Perform a screening of the text-level tags or texts containing the preset keywords in the HTML source code to obtain the HTML source code after the screening;
[0...
Embodiment 2
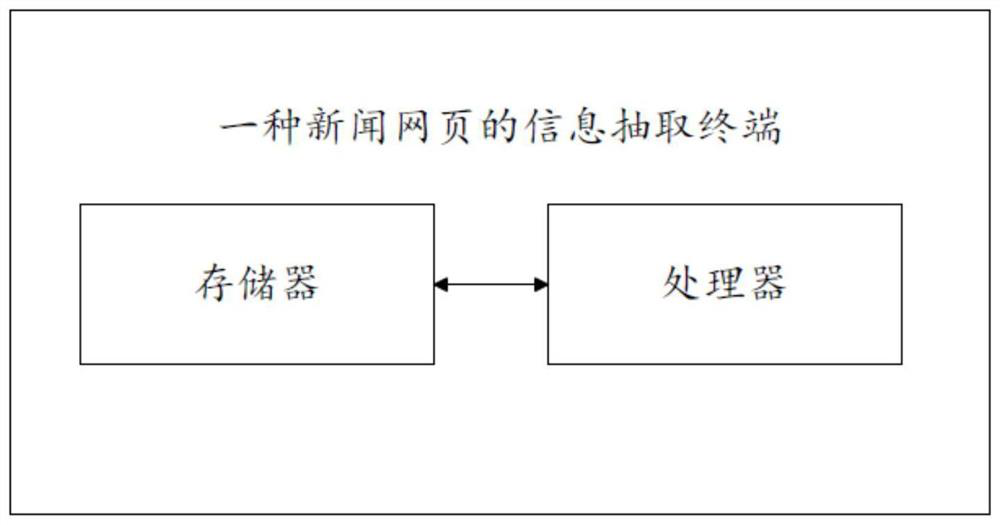
[0150] Please refer to figure 2 , an information extraction terminal for a news webpage, comprising a memory, a processor, and a computer program stored on the memory and operable on the processor, and the news in Embodiment 1 is realized when the processor executes the computer program Each step in the information extraction method of the webpage.
[0151] In summary, the information extraction method and terminal of a news webpage provided by the present invention obtains the HTML source code of the news webpage, and performs a preprocessing on the HTML source code to obtain the preprocessed HTML source code; according to the preset The XPATH rule extracts information from the HTML source code after the first preprocessing to obtain the title of the webpage, the published title, the published author and the published time, which realizes automatic information extraction, and can quickly and accurately extract the title of the webpage in the news webpage, Publishing th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More