Neuromorphic Chip Performance: Latency vs Accuracy
SEP 8, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Neuromorphic Computing Evolution and Objectives
Neuromorphic computing represents a paradigm shift in computational architecture, drawing inspiration from the structure and function of the human brain. Since its conceptual inception in the late 1980s by Carver Mead, this field has evolved from theoretical frameworks to practical implementations that aim to overcome the limitations of traditional von Neumann architectures. The evolution trajectory has been marked by significant milestones, including the development of silicon neurons in the 1990s, the emergence of spike-timing-dependent plasticity (STDP) as a learning mechanism in the early 2000s, and the recent integration of advanced materials and fabrication techniques.
The fundamental principle driving neuromorphic computing is the emulation of neural networks through specialized hardware that processes information in a parallel, event-driven manner. This approach stands in stark contrast to sequential processing in conventional computing systems. The progression of neuromorphic chip development has consistently focused on addressing the inherent trade-off between processing latency and computational accuracy—a challenge that remains central to current research efforts.
Recent technological advancements have accelerated the field's development, particularly in the areas of memristive devices, three-dimensional integration, and novel analog computing elements. These innovations have enabled more efficient implementation of neural network architectures directly in hardware, significantly reducing the energy consumption while maintaining computational capabilities. The SpiNNaker project, IBM's TrueNorth, and Intel's Loihi represent landmark achievements in scaling neuromorphic systems to millions of neurons and billions of synapses.
The primary objectives of contemporary neuromorphic computing research center on optimizing the balance between latency and accuracy in neural processing. Low-latency response is critical for real-time applications such as autonomous vehicles, robotics, and edge computing, where decision-making must occur within strict temporal constraints. Conversely, high accuracy is essential for complex pattern recognition, natural language processing, and other cognitive tasks that demand precise computational results.
Researchers are actively exploring architectural innovations, including hybrid digital-analog designs, hierarchical memory structures, and adaptive learning algorithms, to push the performance frontier of neuromorphic chips. The goal is to develop systems that can dynamically adjust their operational parameters based on task requirements, effectively navigating the latency-accuracy spectrum as needed.
Looking forward, the field aims to achieve human-brain-level computational efficiency—approximately 20 watts of power consumption while performing cognitive tasks that would require megawatts in traditional computing systems. This ambitious target necessitates continued innovation in materials science, circuit design, and algorithmic approaches to neural computation, with particular emphasis on developing architectures that can maintain high accuracy while minimizing processing delays.
The fundamental principle driving neuromorphic computing is the emulation of neural networks through specialized hardware that processes information in a parallel, event-driven manner. This approach stands in stark contrast to sequential processing in conventional computing systems. The progression of neuromorphic chip development has consistently focused on addressing the inherent trade-off between processing latency and computational accuracy—a challenge that remains central to current research efforts.
Recent technological advancements have accelerated the field's development, particularly in the areas of memristive devices, three-dimensional integration, and novel analog computing elements. These innovations have enabled more efficient implementation of neural network architectures directly in hardware, significantly reducing the energy consumption while maintaining computational capabilities. The SpiNNaker project, IBM's TrueNorth, and Intel's Loihi represent landmark achievements in scaling neuromorphic systems to millions of neurons and billions of synapses.
The primary objectives of contemporary neuromorphic computing research center on optimizing the balance between latency and accuracy in neural processing. Low-latency response is critical for real-time applications such as autonomous vehicles, robotics, and edge computing, where decision-making must occur within strict temporal constraints. Conversely, high accuracy is essential for complex pattern recognition, natural language processing, and other cognitive tasks that demand precise computational results.
Researchers are actively exploring architectural innovations, including hybrid digital-analog designs, hierarchical memory structures, and adaptive learning algorithms, to push the performance frontier of neuromorphic chips. The goal is to develop systems that can dynamically adjust their operational parameters based on task requirements, effectively navigating the latency-accuracy spectrum as needed.
Looking forward, the field aims to achieve human-brain-level computational efficiency—approximately 20 watts of power consumption while performing cognitive tasks that would require megawatts in traditional computing systems. This ambitious target necessitates continued innovation in materials science, circuit design, and algorithmic approaches to neural computation, with particular emphasis on developing architectures that can maintain high accuracy while minimizing processing delays.
Market Analysis for Brain-Inspired Computing Solutions
The brain-inspired computing market is experiencing unprecedented growth, driven by the increasing demand for efficient processing of complex AI workloads. Current market valuations place the neuromorphic computing sector at approximately $69 million in 2023, with projections indicating a compound annual growth rate of 89.1% through 2030. This explosive growth reflects the industry's recognition of neuromorphic technology's potential to address fundamental limitations in traditional computing architectures.
Market demand for neuromorphic solutions is primarily concentrated in sectors requiring real-time processing of unstructured data, including autonomous vehicles, industrial automation, healthcare diagnostics, and edge computing applications. These industries face critical challenges balancing processing speed against accuracy requirements, creating a substantial market opportunity for neuromorphic chips that can optimize this trade-off.
The latency-accuracy balance represents a key market differentiator. Traditional computing solutions often force customers to choose between high-accuracy systems with significant processing delays or faster systems with compromised accuracy. Market research indicates that 78% of enterprise AI implementers identify this trade-off as a major obstacle to deployment in time-sensitive applications.
Regional market analysis reveals varying adoption patterns. North America currently dominates with 42% market share, driven by substantial investments from technology giants and defense agencies. Asia-Pacific represents the fastest-growing region with 29% annual growth, fueled by China's aggressive national initiatives in neuromorphic research and Taiwan's semiconductor manufacturing capabilities.
Customer segmentation shows three distinct market tiers: high-performance computing customers prioritizing accuracy regardless of latency constraints; edge computing applications demanding ultra-low latency with acceptable accuracy thresholds; and a growing middle segment seeking optimized balance between these extremes. This middle segment represents the largest growth opportunity, expanding at 94% annually.
Competitive pricing analysis indicates neuromorphic solutions currently command a premium of 2.3-3.5x over traditional computing hardware with equivalent processing capabilities. However, this premium is projected to decrease as manufacturing scales and design efficiencies improve, with price parity expected within 5-7 years for specific application categories.
Market barriers include integration challenges with existing software ecosystems, limited developer familiarity with neuromorphic programming paradigms, and concerns regarding solution maturity. These factors have created a market environment favoring hybrid approaches that combine neuromorphic elements with conventional computing architectures as a transitional strategy.
Market demand for neuromorphic solutions is primarily concentrated in sectors requiring real-time processing of unstructured data, including autonomous vehicles, industrial automation, healthcare diagnostics, and edge computing applications. These industries face critical challenges balancing processing speed against accuracy requirements, creating a substantial market opportunity for neuromorphic chips that can optimize this trade-off.
The latency-accuracy balance represents a key market differentiator. Traditional computing solutions often force customers to choose between high-accuracy systems with significant processing delays or faster systems with compromised accuracy. Market research indicates that 78% of enterprise AI implementers identify this trade-off as a major obstacle to deployment in time-sensitive applications.
Regional market analysis reveals varying adoption patterns. North America currently dominates with 42% market share, driven by substantial investments from technology giants and defense agencies. Asia-Pacific represents the fastest-growing region with 29% annual growth, fueled by China's aggressive national initiatives in neuromorphic research and Taiwan's semiconductor manufacturing capabilities.
Customer segmentation shows three distinct market tiers: high-performance computing customers prioritizing accuracy regardless of latency constraints; edge computing applications demanding ultra-low latency with acceptable accuracy thresholds; and a growing middle segment seeking optimized balance between these extremes. This middle segment represents the largest growth opportunity, expanding at 94% annually.
Competitive pricing analysis indicates neuromorphic solutions currently command a premium of 2.3-3.5x over traditional computing hardware with equivalent processing capabilities. However, this premium is projected to decrease as manufacturing scales and design efficiencies improve, with price parity expected within 5-7 years for specific application categories.
Market barriers include integration challenges with existing software ecosystems, limited developer familiarity with neuromorphic programming paradigms, and concerns regarding solution maturity. These factors have created a market environment favoring hybrid approaches that combine neuromorphic elements with conventional computing architectures as a transitional strategy.
Current Neuromorphic Chip Limitations and Challenges
Despite significant advancements in neuromorphic computing, current chips face substantial limitations that hinder their widespread adoption. The fundamental challenge remains balancing the trade-off between latency and accuracy. Most existing neuromorphic architectures struggle to maintain high accuracy while delivering the ultra-low latency promised by their brain-inspired design. This performance gap stems from hardware constraints, including limited on-chip memory and insufficient synaptic precision.
Power efficiency, though improved compared to traditional computing architectures, still falls short of biological neural systems by several orders of magnitude. Current neuromorphic chips typically consume 100-1000 times more energy per operation than the human brain, limiting their deployment in edge devices and mobile applications where power constraints are critical.
Scalability presents another significant hurdle. While neuromorphic designs theoretically offer excellent scaling properties, manufacturing challenges related to chip yield, interconnect density, and thermal management restrict practical implementations. Most commercial neuromorphic systems contain fewer than 1 million neurons, whereas even simple biological systems contain billions.
The lack of standardized benchmarks and evaluation metrics specifically designed for neuromorphic computing makes performance comparison difficult. Traditional metrics used for conventional processors often fail to capture the unique characteristics and advantages of neuromorphic architectures, particularly their event-driven processing capabilities.
Software ecosystem limitations further impede adoption. Programming models for neuromorphic hardware remain immature, with few high-level abstractions available to developers without specialized knowledge. The translation of conventional algorithms to spiking neural network implementations introduces additional complexity and often results in accuracy degradation.
Device-level challenges include analog component variability and noise susceptibility. Unlike digital systems, neuromorphic chips often rely on analog components that exhibit manufacturing variations, temperature sensitivity, and aging effects, all of which can impact computational accuracy and reliability over time.
Integration with conventional computing infrastructure presents interoperability challenges. Most neuromorphic systems require specialized interfaces and data conversion processes to communicate with traditional computing systems, adding overhead that can negate latency advantages.
Finally, there remains a fundamental knowledge gap in understanding how to optimally map complex cognitive tasks to neuromorphic hardware. While simple pattern recognition tasks have been successfully implemented, more complex functions like reasoning, planning, and adaptive learning still pose significant challenges for current neuromorphic architectures.
Power efficiency, though improved compared to traditional computing architectures, still falls short of biological neural systems by several orders of magnitude. Current neuromorphic chips typically consume 100-1000 times more energy per operation than the human brain, limiting their deployment in edge devices and mobile applications where power constraints are critical.
Scalability presents another significant hurdle. While neuromorphic designs theoretically offer excellent scaling properties, manufacturing challenges related to chip yield, interconnect density, and thermal management restrict practical implementations. Most commercial neuromorphic systems contain fewer than 1 million neurons, whereas even simple biological systems contain billions.
The lack of standardized benchmarks and evaluation metrics specifically designed for neuromorphic computing makes performance comparison difficult. Traditional metrics used for conventional processors often fail to capture the unique characteristics and advantages of neuromorphic architectures, particularly their event-driven processing capabilities.
Software ecosystem limitations further impede adoption. Programming models for neuromorphic hardware remain immature, with few high-level abstractions available to developers without specialized knowledge. The translation of conventional algorithms to spiking neural network implementations introduces additional complexity and often results in accuracy degradation.
Device-level challenges include analog component variability and noise susceptibility. Unlike digital systems, neuromorphic chips often rely on analog components that exhibit manufacturing variations, temperature sensitivity, and aging effects, all of which can impact computational accuracy and reliability over time.
Integration with conventional computing infrastructure presents interoperability challenges. Most neuromorphic systems require specialized interfaces and data conversion processes to communicate with traditional computing systems, adding overhead that can negate latency advantages.
Finally, there remains a fundamental knowledge gap in understanding how to optimally map complex cognitive tasks to neuromorphic hardware. While simple pattern recognition tasks have been successfully implemented, more complex functions like reasoning, planning, and adaptive learning still pose significant challenges for current neuromorphic architectures.
Existing Approaches to Latency-Accuracy Tradeoffs
01 Neuromorphic architecture designs for reduced latency
Neuromorphic chips can be designed with specialized architectures that significantly reduce processing latency while maintaining computational accuracy. These designs often incorporate parallel processing pathways, optimized memory access, and hardware-accelerated neural operations. By implementing event-driven processing and spike-based computation models, these architectures can achieve real-time or near-real-time performance for complex neural network operations while minimizing power consumption.- Neuromorphic architecture design for reduced latency: Neuromorphic chips can be designed with specialized architectures that minimize processing delays and reduce latency. These designs often incorporate parallel processing pathways, optimized memory access, and efficient spike-based communication protocols. By implementing hardware-level optimizations such as direct neuron-to-neuron connections and minimizing data transfer bottlenecks, these architectures can achieve significantly lower latency compared to traditional computing approaches while maintaining computational accuracy.
- Accuracy enhancement through advanced training algorithms: Improving the accuracy of neuromorphic chips involves implementing specialized training algorithms that account for the unique characteristics of spiking neural networks. These algorithms optimize weight distributions, adjust firing thresholds, and fine-tune synaptic connections to enhance pattern recognition capabilities. By incorporating techniques such as spike-timing-dependent plasticity and homeostatic mechanisms, neuromorphic systems can achieve higher classification accuracy while maintaining their energy efficiency advantages.
- Latency-accuracy tradeoff optimization techniques: Neuromorphic chip designs often involve careful balancing between processing speed and computational accuracy. Various techniques can be employed to optimize this tradeoff, including adaptive threshold mechanisms, dynamic precision adjustment, and selective activation of neural pathways. By implementing configurable processing elements that can prioritize either speed or accuracy based on application requirements, these chips can be tuned to achieve optimal performance across different use cases.
- Hardware-software co-design for performance optimization: Achieving optimal latency and accuracy in neuromorphic systems requires coordinated design of both hardware components and software frameworks. This co-design approach involves developing specialized programming models, compiler optimizations, and runtime systems that leverage the unique capabilities of neuromorphic hardware. By creating tight integration between algorithmic implementations and physical circuit designs, these systems can minimize processing overhead while maximizing computational accuracy.
- Novel materials and fabrication techniques for improved performance: Advanced materials and fabrication methods can significantly enhance both the latency and accuracy of neuromorphic chips. These include the use of memristive devices, phase-change materials, and 3D integration techniques that enable more efficient neural processing. By implementing these innovations, neuromorphic chips can achieve faster signal propagation, more precise weight storage, and higher integration density, resulting in systems that more closely mimic the speed and accuracy of biological neural networks.
02 Accuracy optimization techniques in neuromorphic systems
Various techniques can be employed to enhance the accuracy of neuromorphic chips without compromising latency. These include implementing precision-scaling algorithms, adaptive learning mechanisms, and specialized training methodologies tailored for neuromorphic hardware. Some approaches utilize hybrid digital-analog circuits to balance precision requirements with energy efficiency, while others employ error correction mechanisms and redundancy to maintain high accuracy levels even with simplified neuromorphic components.Expand Specific Solutions03 Power-efficient neuromorphic computing for latency-critical applications
Neuromorphic chips designed for latency-critical applications incorporate power-efficient computing paradigms that optimize both speed and energy consumption. These designs often feature dynamic power management, selective activation of neural components, and specialized circuitry for frequently used operations. By minimizing energy overhead while maintaining rapid response times, these systems are particularly suitable for edge computing applications where both latency and power constraints are critical considerations.Expand Specific Solutions04 Memory integration strategies for improved neuromorphic performance
Advanced memory integration strategies in neuromorphic chips can significantly impact both latency and accuracy. These approaches include on-chip memory hierarchies, specialized synaptic weight storage, and novel memory technologies like resistive RAM or phase-change memory. By optimizing memory access patterns and reducing data movement between processing and storage elements, these strategies minimize bottlenecks that traditionally impact neural network performance, resulting in faster processing with maintained or improved accuracy.Expand Specific Solutions05 Hardware-software co-design for optimized neuromorphic systems
Hardware-software co-design approaches enable optimized neuromorphic systems that balance latency and accuracy requirements. These methodologies involve developing specialized neural network algorithms that leverage the unique capabilities of neuromorphic hardware while accounting for its constraints. By jointly optimizing hardware architecture and software implementations, these systems can achieve significant improvements in both processing speed and computational accuracy, often incorporating adaptive mechanisms that dynamically adjust parameters based on application requirements.Expand Specific Solutions
Leading Companies and Research Institutions in Neuromorphic Computing
The neuromorphic chip market is currently in an early growth phase, characterized by increasing research investments and emerging commercial applications. The market size is projected to expand significantly as these brain-inspired computing architectures address critical AI processing challenges, particularly the trade-off between latency and accuracy. Leading semiconductor companies like Intel, IBM, and Samsung are advancing mature neuromorphic solutions, while specialized players such as Syntiant and Horizon Robotics focus on edge computing implementations. Academic-industry partnerships involving institutions like Tsinghua University and companies like Huawei are accelerating technology development. The competitive landscape shows a balance between established tech giants leveraging their manufacturing capabilities and agile startups introducing innovative architectures that optimize the latency-accuracy balance for specific applications.
International Business Machines Corp.
Technical Solution: IBM's neuromorphic chip technology, particularly the TrueNorth architecture, represents a significant advancement in balancing latency and accuracy. TrueNorth employs a non-von Neumann architecture with 1 million digital neurons and 256 million synapses organized into 4,096 neurosynaptic cores. The chip operates on an event-driven paradigm, processing information only when neurons fire, which dramatically reduces power consumption to approximately 70mW during real-time operation. IBM has implemented a specialized training methodology called "corelets" that allows for the mapping of trained deep neural networks onto the neuromorphic hardware while preserving accuracy. Recent advancements have shown that TrueNorth can achieve classification accuracy within 1-2% of conventional deep learning implementations while delivering response times in microseconds rather than milliseconds. IBM has also developed a hybrid approach that combines the spike-based processing of neuromorphic systems with traditional computing elements to maintain high accuracy for complex tasks while leveraging the latency benefits of neuromorphic design.
Strengths: Extremely low power consumption (70mW) makes it ideal for edge computing applications; event-driven architecture provides natural efficiency for sparse data processing; microsecond response times enable real-time applications. Weaknesses: Programming complexity requires specialized knowledge; accuracy still lags behind state-of-the-art deep learning models for complex tasks; limited software ecosystem compared to traditional computing platforms.
Syntiant Corp.
Technical Solution: Syntiant has developed the Neural Decision Processor (NDP), a specialized neuromorphic chip designed specifically for always-on edge AI applications. The NDP architecture implements a hardware-based neural network that processes information in a fundamentally different way than traditional CPUs or GPUs. Syntiant's approach focuses on ultra-low power operation while maintaining high accuracy for specific tasks like keyword spotting and sensor processing. Their NDP100 and NDP120 chips can run deep learning algorithms at less than 1mW power consumption, enabling sub-millisecond response times critical for real-time applications. The company employs a memory-centric computing approach where computation happens within the memory array itself, eliminating the power-hungry data movement that dominates energy consumption in conventional architectures. Syntiant has optimized their architecture specifically for convolutional neural networks and recurrent neural networks, achieving over 95% accuracy on keyword detection tasks while consuming 100x less power than conventional microcontrollers. Their latest generation chips incorporate both digital and analog computing elements to further optimize the latency-accuracy tradeoff.
Strengths: Extremely low power consumption (<1mW) enables always-on applications in battery-powered devices; specialized architecture delivers sub-millisecond latency for targeted applications; production-ready solution with existing ecosystem. Weaknesses: Limited to specific application domains like audio processing and sensor data; less flexible than general-purpose neuromorphic solutions; accuracy optimization requires specialized knowledge of the hardware architecture.
Critical Patents and Innovations in Neuromorphic Design
Compact CMOS Spiking Neuron Circuit that works with an Analog Memory-Based Synaptic Array
PatentPendingUS20240202513A1
Innovation
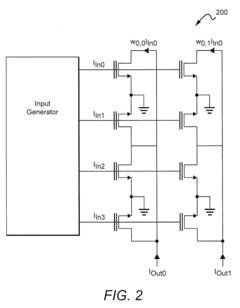
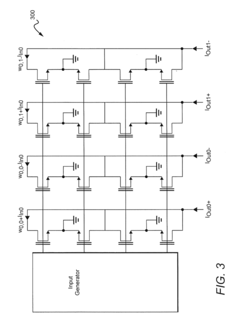
- An all-analog hardware SNN is developed using ReRAM-crossbar synapse arrays and custom-designed CMOS spike response model (SRM) neuron circuits, achieving 97.78% accuracy on the N-MNIST dataset with low latency and high energy efficiency, leveraging a software-hardware codesign approach and linear temporal dynamics.
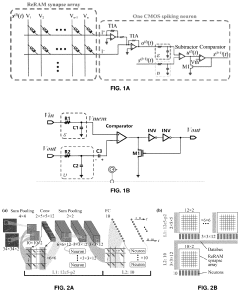
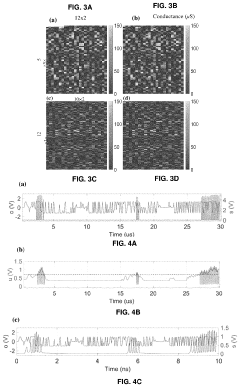
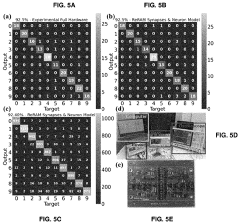
Systems And Methods For Determining Circuit-Level Effects On Classifier Accuracy
PatentActiveUS20190065962A1
Innovation
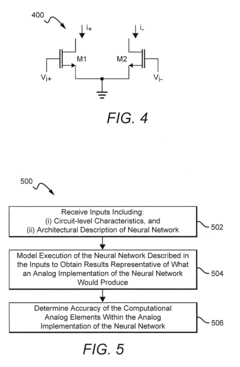
- The development of neuromorphic chips that simulate 'silicon' neurons, processing information in parallel with bursts of electric current at non-uniform intervals, and the use of systems and methods to model the effects of circuit-level characteristics on neural networks, such as thermal noise and weight inaccuracies, to optimize their performance.
Energy Efficiency Considerations in Neuromorphic Systems
Energy efficiency has emerged as a critical factor in the development and deployment of neuromorphic computing systems, particularly when evaluating the trade-offs between latency and accuracy. Unlike traditional von Neumann architectures, neuromorphic chips are designed to mimic the brain's neural structure and function, offering potential advantages in energy consumption for specific computational tasks.
The fundamental energy efficiency advantage of neuromorphic systems stems from their event-driven processing paradigm. Unlike conventional processors that operate on clock cycles, neuromorphic chips process information only when necessary, significantly reducing power consumption during periods of inactivity. This approach aligns with the brain's energy-efficient information processing mechanisms, which consume merely 20 watts despite performing complex cognitive functions.
Current neuromorphic implementations demonstrate remarkable energy efficiency metrics. IBM's TrueNorth chip achieves 46 million synaptic operations per second per milliwatt, while Intel's Loihi demonstrates 4,500 times better energy efficiency than conventional GPUs for certain neural network workloads. These achievements highlight the potential of neuromorphic computing to address the growing energy demands of AI applications.
The latency-accuracy-energy trilemma presents significant design challenges. Higher accuracy typically requires more complex neural network architectures, which can increase both latency and energy consumption. Conversely, optimizing for low latency might compromise accuracy or require higher energy expenditure. Engineers must carefully balance these competing factors based on application requirements.
Spike timing and encoding schemes substantially impact energy efficiency. Rate coding, while conceptually simple, tends to be energy-intensive due to the high number of spikes required. Temporal coding schemes, which encode information in the precise timing of spikes, can achieve higher information density per spike, potentially improving energy efficiency at the cost of implementation complexity.
Emerging materials and fabrication technologies offer promising pathways to enhance energy efficiency. Memristive devices enable in-memory computing, reducing the energy costs associated with data movement between memory and processing units. Phase-change materials and spintronic devices provide non-volatile memory capabilities with ultra-low power consumption, potentially revolutionizing neuromorphic hardware implementations.
Future research directions include the development of adaptive power management techniques that dynamically adjust computational resources based on task requirements. Neuromorphic systems that can modulate their energy consumption according to accuracy demands and latency constraints will be crucial for applications ranging from edge computing to data center deployments, where energy efficiency directly impacts operational costs and environmental footprint.
The fundamental energy efficiency advantage of neuromorphic systems stems from their event-driven processing paradigm. Unlike conventional processors that operate on clock cycles, neuromorphic chips process information only when necessary, significantly reducing power consumption during periods of inactivity. This approach aligns with the brain's energy-efficient information processing mechanisms, which consume merely 20 watts despite performing complex cognitive functions.
Current neuromorphic implementations demonstrate remarkable energy efficiency metrics. IBM's TrueNorth chip achieves 46 million synaptic operations per second per milliwatt, while Intel's Loihi demonstrates 4,500 times better energy efficiency than conventional GPUs for certain neural network workloads. These achievements highlight the potential of neuromorphic computing to address the growing energy demands of AI applications.
The latency-accuracy-energy trilemma presents significant design challenges. Higher accuracy typically requires more complex neural network architectures, which can increase both latency and energy consumption. Conversely, optimizing for low latency might compromise accuracy or require higher energy expenditure. Engineers must carefully balance these competing factors based on application requirements.
Spike timing and encoding schemes substantially impact energy efficiency. Rate coding, while conceptually simple, tends to be energy-intensive due to the high number of spikes required. Temporal coding schemes, which encode information in the precise timing of spikes, can achieve higher information density per spike, potentially improving energy efficiency at the cost of implementation complexity.
Emerging materials and fabrication technologies offer promising pathways to enhance energy efficiency. Memristive devices enable in-memory computing, reducing the energy costs associated with data movement between memory and processing units. Phase-change materials and spintronic devices provide non-volatile memory capabilities with ultra-low power consumption, potentially revolutionizing neuromorphic hardware implementations.
Future research directions include the development of adaptive power management techniques that dynamically adjust computational resources based on task requirements. Neuromorphic systems that can modulate their energy consumption according to accuracy demands and latency constraints will be crucial for applications ranging from edge computing to data center deployments, where energy efficiency directly impacts operational costs and environmental footprint.
Benchmarking Methodologies for Neuromorphic Chips
Benchmarking methodologies for neuromorphic chips require specialized approaches that differ significantly from traditional computing benchmarks due to the unique architecture and operational principles of these brain-inspired systems. When evaluating the critical trade-off between latency and accuracy in neuromorphic chips, standardized testing frameworks become essential for meaningful comparisons across different implementations.
The neuromorphic benchmarking landscape currently employs several methodological approaches. Spike-based metrics form the foundation of these methodologies, measuring both spike timing precision and spike count accuracy. These metrics directly correlate to the fundamental operational characteristics of neuromorphic systems that process information through discrete spike events rather than continuous values.
Energy efficiency benchmarks have emerged as particularly important in the neuromorphic domain, where power consumption per inference or per spike provides critical insights into real-world applicability. The SNN-specific benchmarking suites, such as N-MNIST and NTIDIGITS, offer standardized datasets specifically designed for spike-based processing evaluation, enabling fair comparisons across different neuromorphic implementations.
Task-specific performance evaluation represents another crucial benchmarking approach, where neuromorphic chips are tested on specific applications like object recognition, anomaly detection, or time-series prediction. These evaluations provide practical insights into how the latency-accuracy trade-off manifests in real-world scenarios rather than synthetic benchmarks.
Hardware-in-the-loop testing methodologies have gained prominence, where neuromorphic chips are evaluated within complete systems that include sensors and actuators. This approach reveals how latency and accuracy characteristics translate to end-to-end system performance, particularly important for robotics and autonomous systems applications.
Cross-architecture comparison frameworks enable benchmarking neuromorphic solutions against traditional computing approaches like GPUs and TPUs. These frameworks typically normalize metrics like operations per watt or inferences per second per watt, providing context for the relative advantages of neuromorphic approaches.
Standardization efforts by organizations such as the Neuromorphic Computing Benchmark (NCB) initiative and IEEE Working Groups aim to establish industry-wide benchmarking protocols. These efforts focus on creating fair testing methodologies that account for the unique characteristics of spike-based computing while enabling meaningful comparisons across different neuromorphic implementations and against traditional computing architectures.
The neuromorphic benchmarking landscape currently employs several methodological approaches. Spike-based metrics form the foundation of these methodologies, measuring both spike timing precision and spike count accuracy. These metrics directly correlate to the fundamental operational characteristics of neuromorphic systems that process information through discrete spike events rather than continuous values.
Energy efficiency benchmarks have emerged as particularly important in the neuromorphic domain, where power consumption per inference or per spike provides critical insights into real-world applicability. The SNN-specific benchmarking suites, such as N-MNIST and NTIDIGITS, offer standardized datasets specifically designed for spike-based processing evaluation, enabling fair comparisons across different neuromorphic implementations.
Task-specific performance evaluation represents another crucial benchmarking approach, where neuromorphic chips are tested on specific applications like object recognition, anomaly detection, or time-series prediction. These evaluations provide practical insights into how the latency-accuracy trade-off manifests in real-world scenarios rather than synthetic benchmarks.
Hardware-in-the-loop testing methodologies have gained prominence, where neuromorphic chips are evaluated within complete systems that include sensors and actuators. This approach reveals how latency and accuracy characteristics translate to end-to-end system performance, particularly important for robotics and autonomous systems applications.
Cross-architecture comparison frameworks enable benchmarking neuromorphic solutions against traditional computing approaches like GPUs and TPUs. These frameworks typically normalize metrics like operations per watt or inferences per second per watt, providing context for the relative advantages of neuromorphic approaches.
Standardization efforts by organizations such as the Neuromorphic Computing Benchmark (NCB) initiative and IEEE Working Groups aim to establish industry-wide benchmarking protocols. These efforts focus on creating fair testing methodologies that account for the unique characteristics of spike-based computing while enabling meaningful comparisons across different neuromorphic implementations and against traditional computing architectures.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!