Unit selection voice synthetic method based on acoustics statistical model
A statistical model and speech synthesis technology, applied in speech synthesis, speech analysis, instruments, etc., can solve the problem of unsatisfactory sound quality of restored speech
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

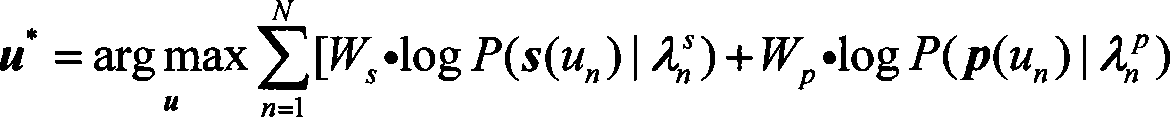
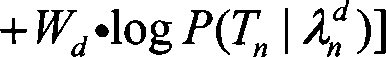
Examples
Embodiment Construction
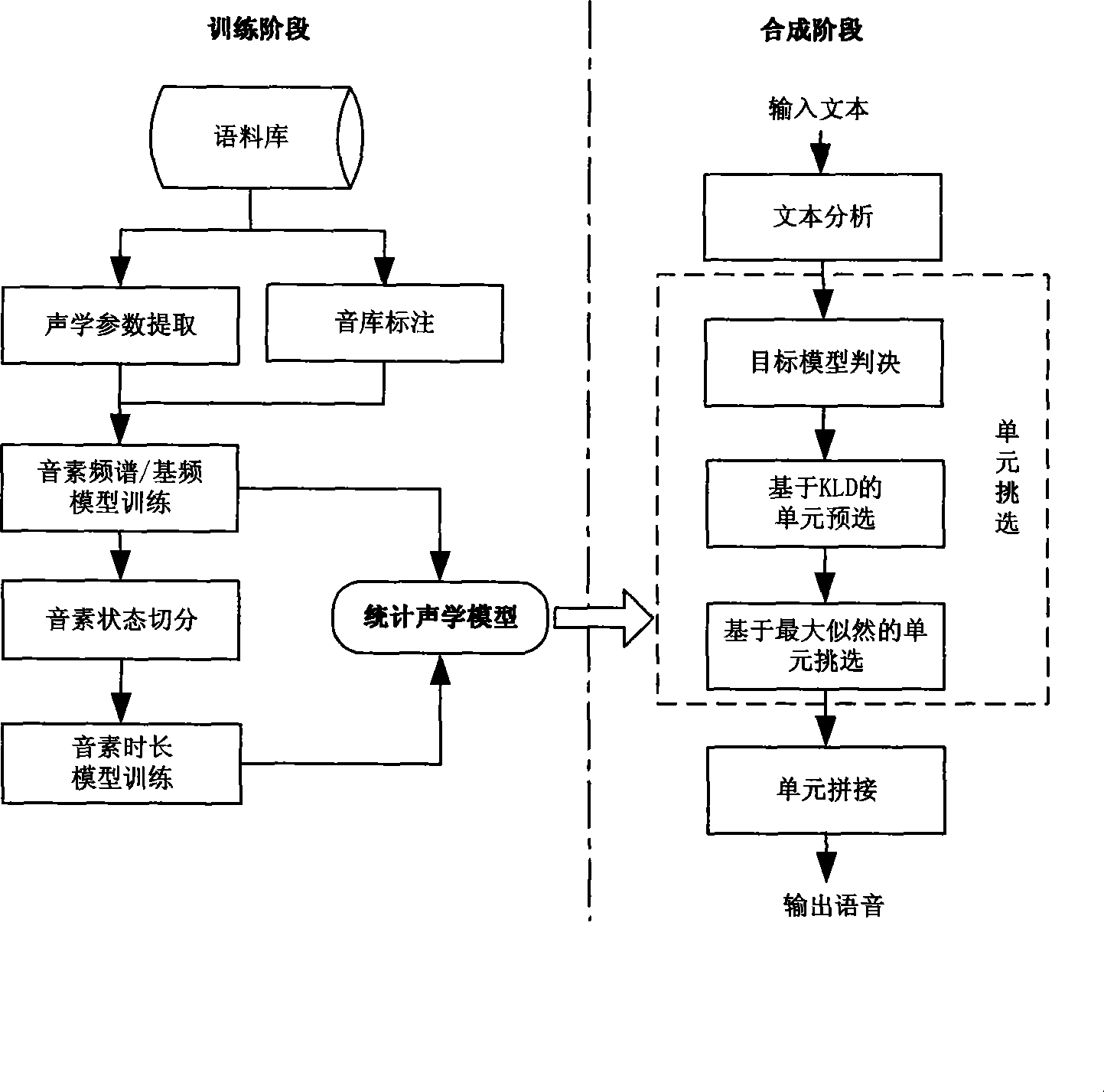
[0037] See attached picture. The unit selection speech synthesis method based on the acoustic statistical model, its implementation method comprises the following steps:
[0038] (1). Extract the acoustic features of the training corpus
[0039] The acoustic features we extract here include the frequency spectrum and fundamental frequency characteristic parameters corresponding to each frame. The spectral parameters we use here are mel-cepstrum parameters, and the fundamental frequency parameters are logarithmic F0 values. Dynamic parameters for frame parameter changes. Take the spectral feature s of the i-th frame of the phoneme n n,i For example,
[0040] s n , i = [ c n , i T , Δ ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More