

Active Learning Pipelines Using Synthetic Data For Faster Discovery
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Active Learning and Synthetic Data Evolution
Active learning and synthetic data technologies have evolved significantly over the past decade, transforming from academic concepts to practical tools deployed across multiple industries. The integration of these two approaches has created powerful synergies that address fundamental challenges in machine learning development cycles.
The evolution began with simple uncertainty-based active learning methods in the early 2000s, which selectively queried examples based on model confidence. By 2010, more sophisticated query strategies emerged, incorporating diversity and representativeness metrics alongside uncertainty. The introduction of deep learning architectures around 2015 dramatically expanded active learning capabilities, enabling more nuanced selection criteria based on feature representations in high-dimensional spaces.
Synthetic data generation has undergone parallel advancement, progressing from basic augmentation techniques to sophisticated generative models. Early approaches relied on simple transformations and rule-based systems, while modern methods leverage GANs, VAEs, and diffusion models to create increasingly realistic and diverse synthetic datasets that preserve statistical properties of real data.
The convergence of these technologies occurred around 2018-2020, when researchers began systematically exploring how synthetic data could address active learning's cold-start problem and class imbalance issues. This integration created a virtuous cycle: active learning identifies knowledge gaps, while synthetic data generation fills those gaps with artificial but informative examples.
Recent developments have focused on self-improving pipelines where models iteratively generate synthetic data, train on combined real and synthetic datasets, identify weaknesses through active learning, and then generate targeted synthetic examples to address those specific weaknesses. This approach has demonstrated particular success in computer vision, drug discovery, and anomaly detection applications.
The technical evolution has been accompanied by important advances in evaluation metrics and theoretical frameworks. Traditional active learning metrics focused on accuracy gains per labeled example, while newer approaches consider the quality and diversity of synthetic data alongside computational efficiency of the entire pipeline.
Looking forward, the field is moving toward more autonomous systems that can continuously improve with minimal human intervention. Emerging research explores meta-learning approaches that optimize active learning strategies and synthetic data generation parameters simultaneously, creating systems that adapt to new domains with increasing efficiency.
The evolution began with simple uncertainty-based active learning methods in the early 2000s, which selectively queried examples based on model confidence. By 2010, more sophisticated query strategies emerged, incorporating diversity and representativeness metrics alongside uncertainty. The introduction of deep learning architectures around 2015 dramatically expanded active learning capabilities, enabling more nuanced selection criteria based on feature representations in high-dimensional spaces.
Synthetic data generation has undergone parallel advancement, progressing from basic augmentation techniques to sophisticated generative models. Early approaches relied on simple transformations and rule-based systems, while modern methods leverage GANs, VAEs, and diffusion models to create increasingly realistic and diverse synthetic datasets that preserve statistical properties of real data.
The convergence of these technologies occurred around 2018-2020, when researchers began systematically exploring how synthetic data could address active learning's cold-start problem and class imbalance issues. This integration created a virtuous cycle: active learning identifies knowledge gaps, while synthetic data generation fills those gaps with artificial but informative examples.
Recent developments have focused on self-improving pipelines where models iteratively generate synthetic data, train on combined real and synthetic datasets, identify weaknesses through active learning, and then generate targeted synthetic examples to address those specific weaknesses. This approach has demonstrated particular success in computer vision, drug discovery, and anomaly detection applications.
The technical evolution has been accompanied by important advances in evaluation metrics and theoretical frameworks. Traditional active learning metrics focused on accuracy gains per labeled example, while newer approaches consider the quality and diversity of synthetic data alongside computational efficiency of the entire pipeline.
Looking forward, the field is moving toward more autonomous systems that can continuously improve with minimal human intervention. Emerging research explores meta-learning approaches that optimize active learning strategies and synthetic data generation parameters simultaneously, creating systems that adapt to new domains with increasing efficiency.
Market Demand Analysis for AI Discovery Acceleration
The market for AI discovery acceleration technologies, particularly those leveraging active learning pipelines with synthetic data, is experiencing unprecedented growth driven by multiple converging factors. Organizations across pharmaceutical, materials science, and chemical industries are increasingly recognizing the potential of these technologies to dramatically reduce research timelines and costs while expanding discovery capabilities.
Current market analysis indicates that the AI-driven drug discovery segment alone is projected to grow at a CAGR of 40.8% through 2030, with the broader AI in life sciences discovery market expected to reach $4.1 billion by 2025. This rapid expansion is fueled by the escalating costs of traditional discovery methods, with pharmaceutical companies now spending an average of $2.6 billion and 10-15 years to bring a single drug to market.
The demand for active learning pipelines using synthetic data is particularly acute in pharmaceutical research, where high-throughput screening methods generate massive datasets that require intelligent processing. Companies report that implementing these advanced AI pipelines can reduce discovery cycles by 30-50% while simultaneously increasing the number of viable candidates identified.
Materials science represents another high-growth segment, with manufacturers seeking novel materials with specific properties for applications ranging from renewable energy to aerospace. The synthetic data approach addresses a critical market need by overcoming the limited availability of experimental data in emerging materials categories.
Geographically, North America currently dominates market demand, accounting for approximately 45% of global spending on AI discovery acceleration technologies. However, Asia-Pacific markets, particularly China and Singapore, are demonstrating the fastest growth rates as government initiatives increasingly support AI-driven scientific research.
From an end-user perspective, large pharmaceutical companies currently represent the largest market segment, but mid-sized biotech firms are adopting these technologies at a faster rate, recognizing them as strategic differentiators that can level the competitive landscape against larger rivals with more extensive research resources.
The market is further stimulated by the growing integration of active learning pipelines with other emerging technologies, including quantum computing and automated laboratory systems. This convergence is creating new market opportunities for comprehensive discovery acceleration platforms that combine multiple AI approaches with physical automation.
Customer pain points driving adoption include data scarcity in novel research areas, computational inefficiency when screening vast chemical spaces, and the need for more targeted experimental design to reduce laboratory costs. Active learning pipelines using synthetic data directly address these challenges by optimizing the exploration of possibility spaces while minimizing required physical experimentation.
Current market analysis indicates that the AI-driven drug discovery segment alone is projected to grow at a CAGR of 40.8% through 2030, with the broader AI in life sciences discovery market expected to reach $4.1 billion by 2025. This rapid expansion is fueled by the escalating costs of traditional discovery methods, with pharmaceutical companies now spending an average of $2.6 billion and 10-15 years to bring a single drug to market.
The demand for active learning pipelines using synthetic data is particularly acute in pharmaceutical research, where high-throughput screening methods generate massive datasets that require intelligent processing. Companies report that implementing these advanced AI pipelines can reduce discovery cycles by 30-50% while simultaneously increasing the number of viable candidates identified.
Materials science represents another high-growth segment, with manufacturers seeking novel materials with specific properties for applications ranging from renewable energy to aerospace. The synthetic data approach addresses a critical market need by overcoming the limited availability of experimental data in emerging materials categories.
Geographically, North America currently dominates market demand, accounting for approximately 45% of global spending on AI discovery acceleration technologies. However, Asia-Pacific markets, particularly China and Singapore, are demonstrating the fastest growth rates as government initiatives increasingly support AI-driven scientific research.
From an end-user perspective, large pharmaceutical companies currently represent the largest market segment, but mid-sized biotech firms are adopting these technologies at a faster rate, recognizing them as strategic differentiators that can level the competitive landscape against larger rivals with more extensive research resources.
The market is further stimulated by the growing integration of active learning pipelines with other emerging technologies, including quantum computing and automated laboratory systems. This convergence is creating new market opportunities for comprehensive discovery acceleration platforms that combine multiple AI approaches with physical automation.
Customer pain points driving adoption include data scarcity in novel research areas, computational inefficiency when screening vast chemical spaces, and the need for more targeted experimental design to reduce laboratory costs. Active learning pipelines using synthetic data directly address these challenges by optimizing the exploration of possibility spaces while minimizing required physical experimentation.
Technical Challenges in Active Learning Pipelines
Active learning pipelines face several significant technical challenges that can impede their effectiveness and efficiency. One primary challenge is the selection strategy for unlabeled data points. Traditional methods often rely on uncertainty sampling, which may not always identify the most informative instances, particularly in high-dimensional spaces or when dealing with complex data distributions. This can lead to suboptimal model improvement trajectories and slower convergence rates.
The integration of synthetic data introduces additional complexities. While synthetic data offers the promise of expanding training datasets without manual labeling costs, ensuring its quality and relevance presents substantial difficulties. Synthetic data generators must accurately capture the underlying distribution of real data while introducing meaningful variations. The gap between synthetic and real data distributions, commonly referred to as the "reality gap," can significantly impact model performance when trained on synthetic data but deployed on real-world inputs.
Computational efficiency represents another major hurdle. Active learning pipelines require frequent model retraining as new labeled data becomes available. This iterative process becomes computationally expensive, especially for deep learning models with millions of parameters. When incorporating synthetic data generation, the computational burden increases further, as generating high-quality synthetic samples often involves complex generative models like GANs or diffusion models that are resource-intensive.
Balancing exploration versus exploitation presents a fundamental challenge in active learning. Systems must decide whether to select samples that help explore uncertain regions of the feature space or to exploit known informative regions. This balance becomes more nuanced when synthetic data is introduced, as the system must additionally determine when to generate synthetic samples versus when to query real unlabeled data.
Evaluation metrics for active learning pipelines lack standardization, making it difficult to compare different approaches objectively. Traditional metrics like accuracy or F1-score fail to capture the efficiency of the learning process itself. When synthetic data is involved, evaluation becomes even more complex, requiring metrics that assess both the quality of synthetic data and its contribution to model improvement.
Lastly, domain adaptation challenges arise when active learning pipelines trained in one domain are applied to slightly different target domains. This challenge is amplified when synthetic data is generated based on one domain but needs to generalize to others. Ensuring transferability across domains while maintaining performance remains an open research question in active learning pipelines using synthetic data.
The integration of synthetic data introduces additional complexities. While synthetic data offers the promise of expanding training datasets without manual labeling costs, ensuring its quality and relevance presents substantial difficulties. Synthetic data generators must accurately capture the underlying distribution of real data while introducing meaningful variations. The gap between synthetic and real data distributions, commonly referred to as the "reality gap," can significantly impact model performance when trained on synthetic data but deployed on real-world inputs.
Computational efficiency represents another major hurdle. Active learning pipelines require frequent model retraining as new labeled data becomes available. This iterative process becomes computationally expensive, especially for deep learning models with millions of parameters. When incorporating synthetic data generation, the computational burden increases further, as generating high-quality synthetic samples often involves complex generative models like GANs or diffusion models that are resource-intensive.
Balancing exploration versus exploitation presents a fundamental challenge in active learning. Systems must decide whether to select samples that help explore uncertain regions of the feature space or to exploit known informative regions. This balance becomes more nuanced when synthetic data is introduced, as the system must additionally determine when to generate synthetic samples versus when to query real unlabeled data.
Evaluation metrics for active learning pipelines lack standardization, making it difficult to compare different approaches objectively. Traditional metrics like accuracy or F1-score fail to capture the efficiency of the learning process itself. When synthetic data is involved, evaluation becomes even more complex, requiring metrics that assess both the quality of synthetic data and its contribution to model improvement.
Lastly, domain adaptation challenges arise when active learning pipelines trained in one domain are applied to slightly different target domains. This challenge is amplified when synthetic data is generated based on one domain but needs to generalize to others. Ensuring transferability across domains while maintaining performance remains an open research question in active learning pipelines using synthetic data.
Current Active Learning Pipeline Solutions
01 Machine learning for accelerated discovery
Active learning pipelines can significantly accelerate the discovery process by using machine learning algorithms to identify patterns and make predictions. These systems can analyze large datasets, prioritize experiments, and suggest promising research directions. By automating parts of the discovery workflow, researchers can focus on high-value activities while the system continuously learns and improves from new data inputs, ultimately reducing the time and resources needed for scientific breakthroughs.- Machine learning for accelerated discovery: Active learning pipelines can significantly accelerate the discovery process by using machine learning algorithms to identify patterns and make predictions. These systems can analyze large datasets, prioritize experiments, and suggest promising research directions. By automating parts of the discovery workflow, researchers can focus on high-value activities while the system continuously learns and improves from new data inputs, ultimately reducing the time and resources needed for scientific breakthroughs.
- Automated experimental design and optimization: Active learning pipelines incorporate automated experimental design techniques that optimize the discovery process. These systems can design experiments that maximize information gain, determine optimal parameters, and adapt testing protocols based on real-time results. By intelligently selecting experiments that provide the most valuable information, these pipelines reduce the number of iterations required to reach conclusions, enabling faster discovery cycles and more efficient use of laboratory resources.
- Integrated data processing and analysis frameworks: Active learning pipelines integrate sophisticated data processing and analysis frameworks that handle complex, multi-dimensional datasets. These frameworks can preprocess raw data, extract meaningful features, and apply advanced statistical methods to identify significant patterns. By combining multiple analytical techniques within a unified pipeline, researchers can rapidly transform experimental results into actionable insights, accelerating the discovery process across various scientific domains.
- Collaborative and distributed discovery systems: Modern active learning pipelines leverage collaborative and distributed computing architectures to accelerate discovery. These systems enable multiple researchers or institutions to contribute data and insights to a shared learning framework. By distributing computational tasks across networks and facilitating knowledge sharing between teams, these pipelines can tackle more complex problems and explore larger solution spaces than traditional approaches, significantly reducing discovery timelines.
- Domain-specific active learning applications: Active learning pipelines are being tailored for specific scientific and industrial domains to accelerate discovery in targeted fields. These specialized systems incorporate domain knowledge, relevant constraints, and field-specific algorithms to focus the discovery process on practical solutions. By customizing the learning approach to particular applications such as drug discovery, materials science, or chemical synthesis, these pipelines can more efficiently navigate complex search spaces and identify innovations that might be missed by general-purpose systems.
02 Automated experimental design and optimization
Active learning pipelines incorporate automated experimental design techniques that optimize the discovery process. These systems can design experiments that maximize information gain, determine optimal parameters, and adapt testing protocols based on real-time results. By intelligently selecting experiments that provide the most valuable information, these pipelines reduce the number of iterations required to reach conclusions, enabling faster discovery cycles and more efficient use of laboratory resources.Expand Specific Solutions03 Integrated data processing and analysis frameworks
Modern active learning pipelines integrate sophisticated data processing and analysis frameworks that handle diverse data types from multiple sources. These frameworks incorporate feature extraction, data normalization, and advanced statistical methods to prepare data for machine learning algorithms. By creating unified data environments that connect previously siloed information, these systems enable researchers to gain comprehensive insights and identify non-obvious relationships, accelerating the discovery process across scientific domains.Expand Specific Solutions04 Feedback loops and continuous learning systems
Active learning pipelines implement feedback loops that continuously improve performance through iterative learning. These systems evaluate outcomes, incorporate new data, and refine their models with minimal human intervention. By constantly updating their knowledge base and adapting to new information, these pipelines become increasingly accurate and efficient over time. This self-improving capability enables faster discovery by progressively reducing uncertainty and focusing resources on the most promising research directions.Expand Specific Solutions05 Cross-domain knowledge transfer and collaboration tools
Advanced active learning pipelines facilitate knowledge transfer across different scientific domains and enable collaborative discovery. These systems can identify relevant insights from one field that may apply to another, suggest potential collaborations, and integrate expertise from multiple disciplines. By breaking down traditional research silos and enabling cross-pollination of ideas, these tools accelerate discovery through collective intelligence and shared resources, leading to novel approaches and unexpected breakthroughs.Expand Specific Solutions
Key Industry Players in Active Learning
Active Learning Pipelines Using Synthetic Data For Faster Discovery is evolving rapidly in a market transitioning from early adoption to growth phase. The global market is expanding significantly, driven by pharmaceutical and tech sectors seeking to accelerate drug discovery and reduce R&D costs. Technologically, the field shows varying maturity levels across players. Recursion Pharmaceuticals leads with advanced AI-driven drug discovery platforms, while tech giants like IBM, NVIDIA, and Microsoft contribute robust computational frameworks. Palantir and Cogniac offer specialized data analytics solutions, and academic institutions (Fudan University, Nanjing University) provide research foundations. Pharmaceutical applications are most mature, with Recursion's platform demonstrating commercial viability, while broader applications in other industries remain in earlier development stages, creating a competitive landscape balancing established leaders and innovative newcomers.
Recursion Pharmaceuticals, Inc.
Technical Solution: Recursion Pharmaceuticals has developed a comprehensive Active Learning Pipeline using synthetic data for drug discovery. Their platform combines high-content cellular imaging with machine learning to create what they call the "Recursion OS." This system generates vast amounts of biological and chemical data, creating over 8 petabytes of proprietary biological images. The pipeline employs active learning algorithms that intelligently select which experiments to run next based on previous results, significantly reducing the search space in drug discovery. Their approach uses cellular phenotypic models to generate synthetic biological data, which is then used to train machine learning models that can predict compound efficacy and toxicity profiles. The system continuously improves as it incorporates new experimental results, creating a feedback loop that accelerates the identification of novel therapeutic candidates for various diseases.
Strengths: Massive proprietary biological image dataset provides unique training material; integrated wet-lab automation allows rapid experimental validation of predictions. Weaknesses: Highly specialized for pharmaceutical applications; requires significant computational and laboratory infrastructure to implement effectively.
International Business Machines Corp.
Technical Solution: IBM has developed an advanced Active Learning Pipeline framework that integrates synthetic data generation with their enterprise AI solutions. Their approach leverages IBM Watson's capabilities to identify knowledge gaps in existing datasets and strategically generate synthetic data to address these gaps. The pipeline employs a query-by-committee approach where multiple models vote on which data points would be most valuable to synthesize next. IBM's system incorporates federated learning techniques that allow organizations to build robust models while maintaining data privacy, particularly valuable in regulated industries like healthcare and finance. Their synthetic data generation capabilities include advanced techniques like variational autoencoders and differential privacy mechanisms to ensure synthetic data maintains statistical properties of real data without exposing sensitive information. IBM's active learning pipeline has demonstrated particular effectiveness in natural language processing applications, where their system can generate synthetic text samples that help models understand rare linguistic patterns or domain-specific terminology.
Strengths: Enterprise-grade solutions with strong security and governance features; extensive integration capabilities with existing business systems. Weaknesses: Implementation often requires significant consulting services; solutions may be less cutting-edge than specialized startups in specific domains.
Core Innovations in Synthetic Data Generation
Elimination capability for active machine learning
PatentPendingUS20250029007A1
Innovation
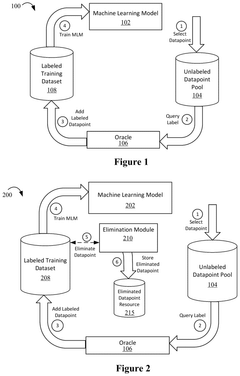
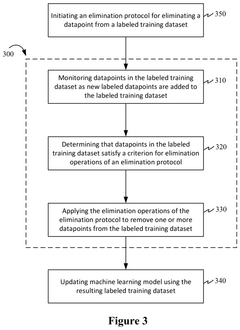
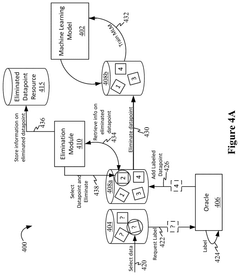
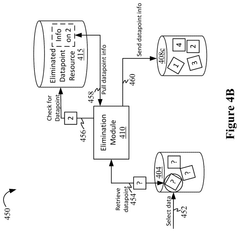
- The implementation of an elimination capability within active machine learning systems that monitors datapoints in the labeled training dataset, determines which datapoints satisfy criteria for elimination operations, and applies these operations to remove less useful or erroneous datapoints, thereby updating the machine learning model with a refined dataset.
Synthetic dataset generator
PatentPendingUS20240127075A1
Innovation
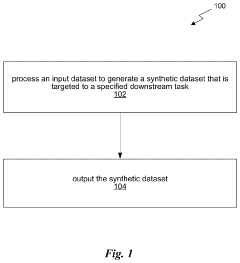
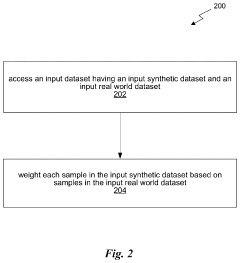
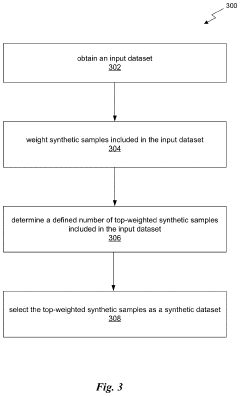
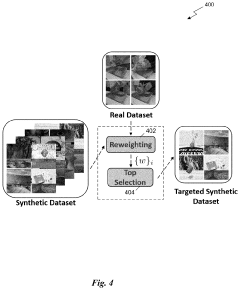
- A method for generating a synthetic dataset that targets a specific downstream task by processing an input dataset, which includes both synthetic and real-world data, using meta-learning algorithms to reweight samples and curate or synthesize data to optimize it for the downstream task, thereby reducing costs and improving model performance.
Data Quality and Validation Frameworks
In the context of Active Learning Pipelines using Synthetic Data, establishing robust Data Quality and Validation Frameworks is essential for ensuring the reliability and effectiveness of the discovery process. These frameworks serve as the foundation for maintaining high standards throughout the synthetic data generation and active learning workflow.
The quality of synthetic data directly impacts the performance of active learning models. A comprehensive data quality framework must address multiple dimensions: accuracy, completeness, consistency, timeliness, and relevance. For synthetic data specifically, this means ensuring that generated samples accurately represent the statistical properties of real-world data while maintaining sufficient diversity to support model generalization.
Validation mechanisms must be implemented at various stages of the pipeline. Initial validation occurs during synthetic data generation, where statistical tests compare distributions between synthetic and reference datasets. Techniques such as Kolmogorov-Smirnov tests, Jensen-Shannon divergence measurements, and visual inspection through dimensionality reduction methods like t-SNE or UMAP have proven effective for this purpose.
Cross-validation strategies tailored for active learning scenarios form another critical component. Traditional k-fold cross-validation may be insufficient due to the iterative nature of active learning. Instead, progressive validation approaches that account for the sequential data acquisition process are more appropriate, such as time-series-aware validation or uncertainty-based validation schemes.
Drift detection mechanisms must be integrated to identify when synthetic data no longer represents the target domain adequately. This becomes particularly important in dynamic environments where underlying data distributions evolve over time. Statistical process control methods and distribution comparison techniques can be employed to trigger alerts when significant drift is detected.
Performance metrics specific to active learning with synthetic data should be tracked continuously. These include not only standard machine learning metrics (accuracy, precision, recall) but also efficiency metrics like label reduction ratio, convergence speed, and computational resource utilization. The framework should also measure the "synthetic data utility" - how effectively synthetic samples contribute to model improvement compared to real samples.
Automated quality assurance pipelines represent the operational implementation of these frameworks. These pipelines execute validation tests automatically at predetermined intervals or trigger points, generating reports and alerting stakeholders when quality thresholds are not met. Modern implementations leverage containerization and orchestration technologies to ensure consistent execution across different environments.
The quality of synthetic data directly impacts the performance of active learning models. A comprehensive data quality framework must address multiple dimensions: accuracy, completeness, consistency, timeliness, and relevance. For synthetic data specifically, this means ensuring that generated samples accurately represent the statistical properties of real-world data while maintaining sufficient diversity to support model generalization.
Validation mechanisms must be implemented at various stages of the pipeline. Initial validation occurs during synthetic data generation, where statistical tests compare distributions between synthetic and reference datasets. Techniques such as Kolmogorov-Smirnov tests, Jensen-Shannon divergence measurements, and visual inspection through dimensionality reduction methods like t-SNE or UMAP have proven effective for this purpose.
Cross-validation strategies tailored for active learning scenarios form another critical component. Traditional k-fold cross-validation may be insufficient due to the iterative nature of active learning. Instead, progressive validation approaches that account for the sequential data acquisition process are more appropriate, such as time-series-aware validation or uncertainty-based validation schemes.
Drift detection mechanisms must be integrated to identify when synthetic data no longer represents the target domain adequately. This becomes particularly important in dynamic environments where underlying data distributions evolve over time. Statistical process control methods and distribution comparison techniques can be employed to trigger alerts when significant drift is detected.
Performance metrics specific to active learning with synthetic data should be tracked continuously. These include not only standard machine learning metrics (accuracy, precision, recall) but also efficiency metrics like label reduction ratio, convergence speed, and computational resource utilization. The framework should also measure the "synthetic data utility" - how effectively synthetic samples contribute to model improvement compared to real samples.
Automated quality assurance pipelines represent the operational implementation of these frameworks. These pipelines execute validation tests automatically at predetermined intervals or trigger points, generating reports and alerting stakeholders when quality thresholds are not met. Modern implementations leverage containerization and orchestration technologies to ensure consistent execution across different environments.
Computational Resource Requirements
Active learning pipelines utilizing synthetic data for discovery applications demand substantial computational resources that scale with the complexity of the tasks. The infrastructure requirements typically include high-performance computing clusters with multiple GPUs or TPUs to handle the intensive machine learning workloads. For instance, training deep learning models on synthetic datasets often requires NVIDIA A100 or V100 GPUs with at least 32GB of memory per unit, or equivalent TPU configurations, particularly when working with high-dimensional data representations.
Memory requirements are equally significant, with most active learning systems needing 128GB to 512GB of RAM to efficiently process large synthetic datasets without excessive disk swapping. Storage considerations are also critical, as synthetic data generation can produce terabytes of information that must be readily accessible. High-speed NVMe storage arrays with at least 10TB capacity are recommended, supplemented by larger archival storage systems.
Network infrastructure becomes a bottleneck when distributed computing is employed, necessitating high-bandwidth, low-latency connections (minimum 100Gbps) between compute nodes. Many organizations implement specialized data centers or leverage cloud services like AWS, GCP, or Azure with customized machine learning instance types to meet these demands.
The computational complexity increases exponentially with the dimensionality of the problem space. For molecular discovery applications, quantum mechanical simulations within active learning loops may require specialized hardware accelerators or quantum computing resources. Similarly, materials science applications often necessitate integration with high-performance simulation software that has its own substantial resource requirements.
Cost considerations are significant, with typical enterprise implementations ranging from $100,000 to several million dollars in hardware investments alone. Cloud-based alternatives offer flexibility but can accumulate substantial operational expenses, often exceeding $10,000 monthly for production-scale implementations. Organizations must carefully balance on-premises versus cloud deployments based on their specific discovery workflows and budget constraints.
Energy consumption presents another challenge, with large-scale active learning systems potentially consuming 50-200 kW of power during peak operation. This necessitates appropriate cooling infrastructure and raises sustainability concerns that organizations increasingly need to address through efficiency optimizations and carbon offset strategies.
Memory requirements are equally significant, with most active learning systems needing 128GB to 512GB of RAM to efficiently process large synthetic datasets without excessive disk swapping. Storage considerations are also critical, as synthetic data generation can produce terabytes of information that must be readily accessible. High-speed NVMe storage arrays with at least 10TB capacity are recommended, supplemented by larger archival storage systems.
Network infrastructure becomes a bottleneck when distributed computing is employed, necessitating high-bandwidth, low-latency connections (minimum 100Gbps) between compute nodes. Many organizations implement specialized data centers or leverage cloud services like AWS, GCP, or Azure with customized machine learning instance types to meet these demands.
The computational complexity increases exponentially with the dimensionality of the problem space. For molecular discovery applications, quantum mechanical simulations within active learning loops may require specialized hardware accelerators or quantum computing resources. Similarly, materials science applications often necessitate integration with high-performance simulation software that has its own substantial resource requirements.
Cost considerations are significant, with typical enterprise implementations ranging from $100,000 to several million dollars in hardware investments alone. Cloud-based alternatives offer flexibility but can accumulate substantial operational expenses, often exceeding $10,000 monthly for production-scale implementations. Organizations must carefully balance on-premises versus cloud deployments based on their specific discovery workflows and budget constraints.
Energy consumption presents another challenge, with large-scale active learning systems potentially consuming 50-200 kW of power during peak operation. This necessitates appropriate cooling infrastructure and raises sustainability concerns that organizations increasingly need to address through efficiency optimizations and carbon offset strategies.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!