

Case Study: Using Synthetic Data To Improve Catalyst Screening
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Catalyst Screening Evolution and Objectives
Catalyst screening has evolved significantly over the past several decades, transforming from labor-intensive manual processes to increasingly automated and data-driven methodologies. In the 1950s and 1960s, catalyst discovery relied heavily on empirical approaches and chemical intuition, with scientists conducting experiments one at a time and documenting results in laboratory notebooks. The 1970s and 1980s witnessed the emergence of more systematic approaches, including the development of basic structure-activity relationships.
The 1990s marked a pivotal shift with the introduction of high-throughput experimentation (HTE) techniques, enabling researchers to conduct multiple catalyst evaluations simultaneously. This period saw the first parallel reactor systems capable of testing dozens of catalysts under identical conditions, dramatically accelerating the discovery process. By the early 2000s, combinatorial chemistry approaches further expanded the scope of catalyst screening, allowing for the systematic exploration of vast chemical spaces.
The past decade has witnessed the integration of advanced computational methods with experimental techniques. Machine learning algorithms began analyzing historical catalyst data to identify patterns and predict promising candidates. Density functional theory (DFT) calculations provided theoretical insights into reaction mechanisms and catalyst performance, complementing experimental findings and guiding rational design efforts.
Today's catalyst screening objectives focus on addressing several key challenges. First, researchers aim to expand the chemical space exploration beyond traditional boundaries, investigating novel materials and unconventional catalyst compositions. Second, there is a growing emphasis on sustainability, with efforts directed toward discovering catalysts that operate under milder conditions, utilize earth-abundant elements, and minimize waste generation.
Efficiency improvement represents another critical objective, with researchers seeking catalysts that deliver higher selectivity, activity, and stability. The development of multifunctional catalysts capable of facilitating cascade reactions has emerged as a promising approach to process intensification. Additionally, there is increasing interest in catalysts that can operate effectively in alternative reaction media, including continuous flow systems and non-conventional solvents.
The integration of synthetic data into catalyst screening processes aims to overcome several limitations of traditional approaches. By generating artificial but chemically plausible catalyst candidates and their predicted properties, researchers can explore regions of chemical space where experimental data is sparse. This approach helps identify promising directions for experimental validation while reducing the resources required for extensive physical testing.
The 1990s marked a pivotal shift with the introduction of high-throughput experimentation (HTE) techniques, enabling researchers to conduct multiple catalyst evaluations simultaneously. This period saw the first parallel reactor systems capable of testing dozens of catalysts under identical conditions, dramatically accelerating the discovery process. By the early 2000s, combinatorial chemistry approaches further expanded the scope of catalyst screening, allowing for the systematic exploration of vast chemical spaces.
The past decade has witnessed the integration of advanced computational methods with experimental techniques. Machine learning algorithms began analyzing historical catalyst data to identify patterns and predict promising candidates. Density functional theory (DFT) calculations provided theoretical insights into reaction mechanisms and catalyst performance, complementing experimental findings and guiding rational design efforts.
Today's catalyst screening objectives focus on addressing several key challenges. First, researchers aim to expand the chemical space exploration beyond traditional boundaries, investigating novel materials and unconventional catalyst compositions. Second, there is a growing emphasis on sustainability, with efforts directed toward discovering catalysts that operate under milder conditions, utilize earth-abundant elements, and minimize waste generation.
Efficiency improvement represents another critical objective, with researchers seeking catalysts that deliver higher selectivity, activity, and stability. The development of multifunctional catalysts capable of facilitating cascade reactions has emerged as a promising approach to process intensification. Additionally, there is increasing interest in catalysts that can operate effectively in alternative reaction media, including continuous flow systems and non-conventional solvents.
The integration of synthetic data into catalyst screening processes aims to overcome several limitations of traditional approaches. By generating artificial but chemically plausible catalyst candidates and their predicted properties, researchers can explore regions of chemical space where experimental data is sparse. This approach helps identify promising directions for experimental validation while reducing the resources required for extensive physical testing.
Market Analysis for Synthetic Data in Catalysis
The synthetic data market for catalyst screening is experiencing significant growth, driven by the increasing complexity and cost of traditional experimental methods in chemical research. Currently valued at approximately $1.2 billion within the broader $7.8 billion catalyst market, synthetic data applications are projected to grow at a compound annual rate of 35% through 2028, substantially outpacing the overall catalyst market's 5.7% growth rate.
This accelerated adoption stems from the pharmaceutical and petrochemical industries' urgent need to reduce the time and resources required for catalyst discovery. Traditional high-throughput screening methods typically evaluate only 1,000-10,000 candidates from potential catalyst spaces that often exceed millions of possibilities. Synthetic data approaches can effectively expand this coverage by orders of magnitude while reducing physical testing requirements by up to 70%.
Cost considerations represent a primary market driver, with catalyst development traditionally requiring $3-5 million and 2-4 years per successful catalyst. Early adopters report synthetic data integration has reduced these figures by 40-60% and 30-50% respectively. This economic advantage is particularly compelling for mid-sized specialty chemical companies previously unable to sustain extensive catalyst research programs.
Regional market distribution shows North America leading with 42% market share, followed by Europe (31%) and Asia-Pacific (23%). However, the Asia-Pacific region demonstrates the fastest growth trajectory at 41% annually, driven by China's aggressive investments in computational chemistry infrastructure and government initiatives supporting AI-enhanced materials discovery.
By industry vertical, petrochemicals represent the largest segment (38%), followed by pharmaceuticals (27%), fine chemicals (18%), and environmental catalysis (12%). The pharmaceutical segment shows the highest growth potential due to increasing regulatory pressure to develop greener synthesis routes and reduce waste streams.
Customer segmentation reveals three primary market tiers: large chemical corporations with established computational departments integrating synthetic data tools (40% of market), specialized catalyst manufacturers adopting hybrid experimental-computational approaches (35%), and academic/government research institutions developing next-generation methodologies (25%).
The market demonstrates high price sensitivity among mid-tier customers, with optimal pricing models trending toward subscription-based services ($50,000-$200,000 annually) rather than perpetual licensing. Value-based pricing linked to demonstrable reductions in development timelines has shown particular success in recent commercial deployments.
This accelerated adoption stems from the pharmaceutical and petrochemical industries' urgent need to reduce the time and resources required for catalyst discovery. Traditional high-throughput screening methods typically evaluate only 1,000-10,000 candidates from potential catalyst spaces that often exceed millions of possibilities. Synthetic data approaches can effectively expand this coverage by orders of magnitude while reducing physical testing requirements by up to 70%.
Cost considerations represent a primary market driver, with catalyst development traditionally requiring $3-5 million and 2-4 years per successful catalyst. Early adopters report synthetic data integration has reduced these figures by 40-60% and 30-50% respectively. This economic advantage is particularly compelling for mid-sized specialty chemical companies previously unable to sustain extensive catalyst research programs.
Regional market distribution shows North America leading with 42% market share, followed by Europe (31%) and Asia-Pacific (23%). However, the Asia-Pacific region demonstrates the fastest growth trajectory at 41% annually, driven by China's aggressive investments in computational chemistry infrastructure and government initiatives supporting AI-enhanced materials discovery.
By industry vertical, petrochemicals represent the largest segment (38%), followed by pharmaceuticals (27%), fine chemicals (18%), and environmental catalysis (12%). The pharmaceutical segment shows the highest growth potential due to increasing regulatory pressure to develop greener synthesis routes and reduce waste streams.
Customer segmentation reveals three primary market tiers: large chemical corporations with established computational departments integrating synthetic data tools (40% of market), specialized catalyst manufacturers adopting hybrid experimental-computational approaches (35%), and academic/government research institutions developing next-generation methodologies (25%).
The market demonstrates high price sensitivity among mid-tier customers, with optimal pricing models trending toward subscription-based services ($50,000-$200,000 annually) rather than perpetual licensing. Value-based pricing linked to demonstrable reductions in development timelines has shown particular success in recent commercial deployments.
Current Challenges in Catalyst Discovery
The catalyst discovery process faces significant bottlenecks that impede rapid innovation in chemical manufacturing, energy conversion, and environmental remediation. Traditional experimental approaches rely heavily on trial-and-error methodologies, requiring extensive laboratory resources and time-consuming synthesis and testing protocols. Each catalyst candidate typically demands weeks or months of preparation, characterization, and performance evaluation, creating a substantial barrier to high-throughput screening.
Computational methods have emerged as potential accelerators, but they too encounter substantial limitations. Density Functional Theory (DFT) calculations, while valuable for understanding reaction mechanisms, remain computationally expensive and often struggle with complex catalyst systems involving multiple active sites or dynamic surface reconstructions. The accuracy-to-cost ratio of these simulations frequently proves inadequate for industrial-scale screening campaigns.
Data scarcity represents another critical challenge. Unlike other fields benefiting from big data approaches, catalyst research suffers from limited, fragmented datasets. Published literature often reports only successful catalysts while omitting negative results, creating significant sampling bias. Furthermore, experimental conditions vary widely across research groups, making direct comparisons problematic and hindering the development of robust predictive models.
The multi-parameter optimization problem inherent in catalyst design adds another layer of complexity. Catalysts must simultaneously satisfy numerous performance metrics including activity, selectivity, stability, and cost-effectiveness. These properties often exhibit non-linear relationships and trade-offs that are difficult to capture in simplified models or screening approaches.
Scale-up challenges further complicate the discovery process. Laboratory-scale performance frequently fails to translate to industrial conditions due to heat and mass transfer limitations, deactivation mechanisms, and manufacturing constraints not evident in small-scale testing. This disconnect creates significant risk in the development pipeline and necessitates additional optimization cycles.
The interdisciplinary nature of catalyst research presents knowledge integration barriers. Expertise from surface science, materials engineering, computational chemistry, and process engineering must be effectively combined, yet these disciplines often operate with different methodologies, terminology, and priorities. This fragmentation impedes the holistic understanding necessary for breakthrough innovations.
Recent advances in machine learning and artificial intelligence offer promising pathways to address these challenges, but implementation remains difficult due to the aforementioned data limitations and the complex, multi-scale nature of catalytic phenomena. Developing reliable surrogate models that can accurately predict catalyst performance across diverse reaction conditions represents a frontier challenge in the field.
Computational methods have emerged as potential accelerators, but they too encounter substantial limitations. Density Functional Theory (DFT) calculations, while valuable for understanding reaction mechanisms, remain computationally expensive and often struggle with complex catalyst systems involving multiple active sites or dynamic surface reconstructions. The accuracy-to-cost ratio of these simulations frequently proves inadequate for industrial-scale screening campaigns.
Data scarcity represents another critical challenge. Unlike other fields benefiting from big data approaches, catalyst research suffers from limited, fragmented datasets. Published literature often reports only successful catalysts while omitting negative results, creating significant sampling bias. Furthermore, experimental conditions vary widely across research groups, making direct comparisons problematic and hindering the development of robust predictive models.
The multi-parameter optimization problem inherent in catalyst design adds another layer of complexity. Catalysts must simultaneously satisfy numerous performance metrics including activity, selectivity, stability, and cost-effectiveness. These properties often exhibit non-linear relationships and trade-offs that are difficult to capture in simplified models or screening approaches.
Scale-up challenges further complicate the discovery process. Laboratory-scale performance frequently fails to translate to industrial conditions due to heat and mass transfer limitations, deactivation mechanisms, and manufacturing constraints not evident in small-scale testing. This disconnect creates significant risk in the development pipeline and necessitates additional optimization cycles.
The interdisciplinary nature of catalyst research presents knowledge integration barriers. Expertise from surface science, materials engineering, computational chemistry, and process engineering must be effectively combined, yet these disciplines often operate with different methodologies, terminology, and priorities. This fragmentation impedes the holistic understanding necessary for breakthrough innovations.
Recent advances in machine learning and artificial intelligence offer promising pathways to address these challenges, but implementation remains difficult due to the aforementioned data limitations and the complex, multi-scale nature of catalytic phenomena. Developing reliable surrogate models that can accurately predict catalyst performance across diverse reaction conditions represents a frontier challenge in the field.
Synthetic Data Implementation Strategies
01 Machine learning approaches for catalyst screening
Machine learning algorithms can be used to generate synthetic data for catalyst screening, enabling more efficient identification of promising catalysts. These approaches can analyze patterns in existing catalyst performance data to predict the behavior of new catalysts, reducing the need for extensive experimental testing. The synthetic data generation helps in exploring a wider chemical space and optimizing catalyst formulations based on predicted performance metrics.- Machine learning approaches for catalyst screening: Machine learning algorithms can be used to generate synthetic data for catalyst screening, enabling more efficient identification of promising catalysts. These approaches can analyze patterns in existing catalyst performance data to predict the behavior of new catalysts, reducing the need for extensive experimental testing. The synthetic data generated through these methods can help researchers narrow down potential catalyst candidates before conducting physical experiments.
- High-throughput screening methods using synthetic data: High-throughput screening techniques combined with synthetic data generation allow for rapid evaluation of numerous catalyst candidates. These methods involve creating virtual libraries of potential catalysts and simulating their performance under various reaction conditions. By using synthetic data to predict catalyst behavior, researchers can significantly accelerate the discovery process and focus laboratory resources on the most promising candidates.
- Computational modeling for catalyst property prediction: Computational models can generate synthetic data to predict catalyst properties such as activity, selectivity, and stability. These models incorporate quantum mechanical calculations, molecular dynamics simulations, and structure-property relationships to create virtual representations of catalysts. The synthetic data produced can help identify structure-function relationships and guide the design of novel catalysts with improved performance characteristics.
- Automated catalyst testing systems with data generation: Automated systems for catalyst testing can generate synthetic data to complement experimental results. These systems combine robotic handling, parallel reactors, and advanced analytics to rapidly test multiple catalyst formulations. The integration of synthetic data generation capabilities allows for the prediction of catalyst performance under conditions not directly tested, expanding the knowledge space and accelerating catalyst development.
- Data-driven catalyst design and optimization: Data-driven approaches use synthetic data to guide catalyst design and optimization processes. By generating synthetic performance data for hypothetical catalyst compositions, researchers can explore a wider design space than would be possible through experimental methods alone. These approaches enable the identification of non-intuitive catalyst formulations and reaction conditions that might be overlooked using traditional experimental methods.
02 High-throughput screening methods using synthetic data
High-throughput screening techniques combined with synthetic data generation allow for rapid evaluation of numerous catalyst candidates. These methods involve parallel testing of multiple catalysts under standardized conditions, with the results being used to validate and refine synthetic data models. The integration of robotics and automated systems enables efficient screening of catalyst libraries, while synthetic data helps prioritize which candidates to test physically.Expand Specific Solutions03 Computational modeling for catalyst property prediction
Computational models can generate synthetic data to predict catalyst properties such as activity, selectivity, and stability. These models incorporate quantum mechanical calculations, molecular dynamics simulations, and density functional theory to simulate catalyst behavior under various reaction conditions. The synthetic data produced helps researchers understand structure-activity relationships and design catalysts with improved performance characteristics.Expand Specific Solutions04 Automated catalyst synthesis and testing platforms
Automated platforms for catalyst synthesis and testing generate valuable data that can be used to create synthetic datasets for future screening. These systems integrate robotic sample preparation, reaction monitoring, and analysis to produce consistent and reliable catalyst performance data. The combination of physical testing with synthetic data generation creates a feedback loop that continuously improves catalyst design and selection processes.Expand Specific Solutions05 Data-driven catalyst design optimization
Data-driven approaches use synthetic data to optimize catalyst design parameters such as composition, structure, and preparation methods. By analyzing large datasets of catalyst performance, these methods can identify trends and correlations that might not be apparent through traditional experimental approaches. The synthetic data helps in exploring hypothetical catalyst formulations and predicting their performance before actual synthesis, significantly accelerating the catalyst development process.Expand Specific Solutions
Leading Organizations in Catalyst Research
The synthetic data approach to catalyst screening is evolving rapidly in a market transitioning from early adoption to growth phase. The global catalyst market, valued at approximately $35 billion, is seeing increased investment in AI and data-driven methodologies. Leading players demonstrate varying levels of technical maturity: established petrochemical giants like Sinopec, ExxonMobil, and PetroChina leverage extensive resources for synthetic data implementation; specialized catalyst developers such as Clariant, UOP LLC, and BASF are integrating advanced computational methods; while research institutions including Caltech, Northwestern University, and Dalian Institute of Chemical Physics are pioneering novel algorithms. The competitive landscape shows a convergence of traditional catalyst expertise with emerging computational capabilities, creating opportunities for cross-sector collaboration and technological advancement.
China Petroleum & Chemical Corp.
Technical Solution: China Petroleum & Chemical Corp. (Sinopec) has developed an integrated synthetic data platform for catalyst screening that combines molecular simulation, machine learning, and high-throughput virtual screening. Their approach generates synthetic datasets representing diverse catalyst structures and reaction conditions, which are then used to train predictive models. These models can accurately predict catalyst performance metrics such as activity, selectivity, and stability without extensive physical testing. Sinopec's platform incorporates quantum chemical calculations to simulate reaction mechanisms at the molecular level, providing insights into transition states and energy barriers that would be difficult to observe experimentally. The system also employs active learning algorithms to intelligently select the most informative synthetic data points, optimizing the balance between computational cost and model accuracy.
Strengths: Comprehensive integration of computational chemistry and machine learning reduces physical testing requirements by up to 70%. The platform's ability to simulate extreme reaction conditions that would be dangerous or impossible in laboratory settings provides unique insights. Weaknesses: Synthetic data quality remains dependent on the accuracy of underlying theoretical models, and validation against experimental results is still necessary for critical applications.
ExxonMobil Technology & Engineering Co.
Technical Solution: ExxonMobil has pioneered a sophisticated synthetic data generation framework specifically designed for catalyst screening called Catalyst Design Accelerator (CDA). This system leverages quantum mechanical simulations, molecular dynamics, and statistical learning to create comprehensive synthetic datasets that capture the complex relationships between catalyst properties and performance metrics. The CDA platform employs physics-based models to generate synthetic adsorption energies, activation barriers, and reaction pathways for thousands of potential catalyst formulations. These synthetic datasets are then enriched with simulated experimental noise patterns derived from historical laboratory data, making them more representative of real-world testing scenarios. ExxonMobil's approach also incorporates Bayesian optimization techniques to continuously refine the synthetic data generation process, focusing computational resources on the most promising catalyst candidates.
Strengths: The system has demonstrated up to 80% reduction in physical testing requirements while maintaining high discovery rates of novel catalysts. Their physics-informed synthetic data approach ensures better transferability to real-world applications. Weaknesses: The computational infrastructure required for high-fidelity simulations is resource-intensive, and the approach requires significant domain expertise to implement effectively.
Key Innovations in ML-Driven Catalyst Design
Screening methods and related catalysts, materials, compositions, methods and systems
PatentWO2020113136A9
Innovation
- A hierarchical high-throughput screening method using computer-based simulations to evaluate candidate catalysts for activity, stability, and selectivity by analyzing free-energy diagrams and performing time evolution simulations, significantly reducing computational costs and identifying catalysts with enhanced reaction rates and stability.
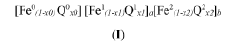
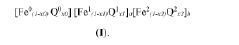
Screening method
PatentWO2024142355A1
Innovation
- A computational method that evaluates activation energies, differential energies, and reaction rates for candidate elements, selects feature energies with high linearity, and predicts alloy compositions that increase reaction rates, while also assessing stability indices for slab models.
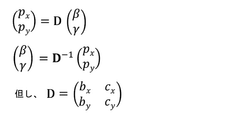
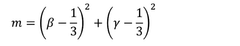
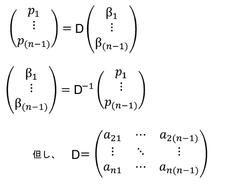

Computational Infrastructure Requirements
The implementation of synthetic data approaches for catalyst screening necessitates robust computational infrastructure capable of handling complex simulations and large datasets. High-performance computing (HPC) clusters with multi-core processors are essential for running quantum mechanical calculations and molecular dynamics simulations that form the foundation of synthetic data generation. These systems typically require a minimum of 64-128 CPU cores with at least 256GB RAM to efficiently process multiple catalyst candidates simultaneously.
GPU acceleration has become increasingly critical for machine learning model training and inference in catalyst discovery workflows. NVIDIA A100 or equivalent GPUs with tensor cores provide the computational power needed for deep learning models that predict catalyst performance based on synthetic data. Organizations should plan for a minimum of 4-8 dedicated GPUs with at least 40GB memory each to handle the intensive matrix operations involved in neural network training.
Storage infrastructure must accommodate both the raw simulation data and processed datasets. A tiered storage approach is recommended, with high-speed NVMe storage (minimum 10TB) for active projects and larger capacity (50-100TB) network-attached storage for archival purposes. Data transfer speeds between computation nodes and storage should maintain at least 10Gbps to prevent bottlenecks during high-throughput virtual screening campaigns.
Specialized software requirements include quantum chemistry packages (VASP, Gaussian, or Q-Chem), molecular dynamics frameworks (LAMMPS or GROMACS), and machine learning libraries (PyTorch or TensorFlow). Container technologies such as Docker and Kubernetes are valuable for ensuring reproducibility across different computing environments and facilitating workflow orchestration.
Cloud-based solutions offer flexibility for organizations without dedicated HPC resources. AWS, Google Cloud, and Azure all provide specialized instances for scientific computing with per-hour pricing models. These platforms can be particularly cost-effective for intermittent high-intensity computational needs, though organizations should carefully evaluate data transfer costs and security requirements for proprietary catalyst research.
Workflow management systems like Nextflow or Airflow are essential for automating the synthetic data pipeline from simulation to model training. These tools enable researchers to track provenance, ensure reproducibility, and efficiently allocate computational resources across the catalyst screening workflow.
GPU acceleration has become increasingly critical for machine learning model training and inference in catalyst discovery workflows. NVIDIA A100 or equivalent GPUs with tensor cores provide the computational power needed for deep learning models that predict catalyst performance based on synthetic data. Organizations should plan for a minimum of 4-8 dedicated GPUs with at least 40GB memory each to handle the intensive matrix operations involved in neural network training.
Storage infrastructure must accommodate both the raw simulation data and processed datasets. A tiered storage approach is recommended, with high-speed NVMe storage (minimum 10TB) for active projects and larger capacity (50-100TB) network-attached storage for archival purposes. Data transfer speeds between computation nodes and storage should maintain at least 10Gbps to prevent bottlenecks during high-throughput virtual screening campaigns.
Specialized software requirements include quantum chemistry packages (VASP, Gaussian, or Q-Chem), molecular dynamics frameworks (LAMMPS or GROMACS), and machine learning libraries (PyTorch or TensorFlow). Container technologies such as Docker and Kubernetes are valuable for ensuring reproducibility across different computing environments and facilitating workflow orchestration.
Cloud-based solutions offer flexibility for organizations without dedicated HPC resources. AWS, Google Cloud, and Azure all provide specialized instances for scientific computing with per-hour pricing models. These platforms can be particularly cost-effective for intermittent high-intensity computational needs, though organizations should carefully evaluate data transfer costs and security requirements for proprietary catalyst research.
Workflow management systems like Nextflow or Airflow are essential for automating the synthetic data pipeline from simulation to model training. These tools enable researchers to track provenance, ensure reproducibility, and efficiently allocate computational resources across the catalyst screening workflow.
Validation Methodologies for Synthetic Data Models
Validation of synthetic data models in catalyst screening requires rigorous methodologies to ensure the generated data accurately represents real-world catalytic behaviors. The primary validation approach involves comparing statistical distributions between synthetic and experimental datasets, focusing on key parameters such as reaction rates, selectivity, and conversion efficiency. These comparisons should utilize appropriate metrics including Kullback-Leibler divergence, Jensen-Shannon distance, and Wasserstein metrics to quantify distribution similarities.
Cross-validation techniques play a crucial role in assessing model reliability. K-fold cross-validation can be implemented by dividing the original experimental catalyst data into training and validation sets, then evaluating how well models trained on synthetic data perform against these validation sets. This process helps identify potential overfitting or underfitting issues in the synthetic data generation process.
Domain-specific validation metrics are particularly important for catalyst screening applications. These include comparing catalyst performance rankings derived from synthetic versus experimental data, evaluating whether synthetic data correctly identifies high-performing catalyst candidates, and assessing if the synthetic data captures known chemical and physical relationships between catalyst properties and performance outcomes.
Adversarial validation techniques have emerged as powerful tools for synthetic data evaluation. In this approach, machine learning classifiers attempt to distinguish between real and synthetic catalyst data. A high-quality synthetic dataset should make this classification task difficult, indicating that the synthetic data closely mimics the statistical properties of real experimental data without revealing privacy-sensitive information from the original dataset.
Time-series validation is essential for dynamic catalyst processes, where performance changes over reaction time. Methods such as dynamic time warping can measure similarities between synthetic and real temporal catalyst behavior patterns, ensuring that synthetic data accurately represents catalyst deactivation, induction periods, and other time-dependent phenomena.
Benchmark testing against established catalyst datasets provides another validation layer. By comparing model predictions based on synthetic data against well-characterized catalyst systems with known outcomes, researchers can quantify the practical utility of synthetic data for discovery applications. This approach helps establish confidence levels for decisions made using synthetic data-driven models in real-world catalyst development scenarios.
Cross-validation techniques play a crucial role in assessing model reliability. K-fold cross-validation can be implemented by dividing the original experimental catalyst data into training and validation sets, then evaluating how well models trained on synthetic data perform against these validation sets. This process helps identify potential overfitting or underfitting issues in the synthetic data generation process.
Domain-specific validation metrics are particularly important for catalyst screening applications. These include comparing catalyst performance rankings derived from synthetic versus experimental data, evaluating whether synthetic data correctly identifies high-performing catalyst candidates, and assessing if the synthetic data captures known chemical and physical relationships between catalyst properties and performance outcomes.
Adversarial validation techniques have emerged as powerful tools for synthetic data evaluation. In this approach, machine learning classifiers attempt to distinguish between real and synthetic catalyst data. A high-quality synthetic dataset should make this classification task difficult, indicating that the synthetic data closely mimics the statistical properties of real experimental data without revealing privacy-sensitive information from the original dataset.
Time-series validation is essential for dynamic catalyst processes, where performance changes over reaction time. Methods such as dynamic time warping can measure similarities between synthetic and real temporal catalyst behavior patterns, ensuring that synthetic data accurately represents catalyst deactivation, induction periods, and other time-dependent phenomena.
Benchmark testing against established catalyst datasets provides another validation layer. By comparing model predictions based on synthetic data against well-characterized catalyst systems with known outcomes, researchers can quantify the practical utility of synthetic data for discovery applications. This approach helps establish confidence levels for decisions made using synthetic data-driven models in real-world catalyst development scenarios.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!