

How To Evaluate Synthetic Materials Data For Downstream Modeling
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Synthetic Materials Data Evaluation Background and Objectives
The field of synthetic materials data generation and evaluation has evolved significantly over the past decade, driven by advancements in computational methods, machine learning algorithms, and the increasing demand for accelerated materials discovery. Traditional materials development typically requires extensive laboratory experimentation, which is both time-consuming and resource-intensive. The emergence of synthetic data approaches offers a promising alternative by generating artificial datasets that mimic real-world materials properties and behaviors.
Synthetic materials data encompasses computationally generated information about material properties, structures, and performance characteristics. This includes data from molecular dynamics simulations, density functional theory calculations, machine learning generative models, and other computational techniques. The primary objective of evaluating such synthetic data is to determine its fidelity, reliability, and utility for downstream modeling applications that can accelerate materials innovation cycles.
The evolution of this field has been marked by several key developments, including the Materials Genome Initiative launched in 2011, which emphasized computational approaches to materials discovery, and the subsequent rise of materials informatics as a discipline. More recently, generative models such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) have been adapted specifically for materials science applications, enabling the creation of increasingly sophisticated synthetic datasets.
Current technical objectives in synthetic materials data evaluation focus on establishing robust validation frameworks that can quantify the quality and usefulness of generated data. These objectives include developing metrics for assessing data fidelity, creating benchmarks for comparing different synthetic data generation methods, and establishing protocols for determining when synthetic data is suitable for specific modeling tasks.
A critical goal is to understand the limitations and biases inherent in synthetic materials data, particularly how these might propagate through downstream modeling pipelines. This includes evaluating how well synthetic data captures the complex relationships between material structure and properties, and whether models trained on synthetic data can generalize to real-world scenarios.
Looking forward, the field aims to develop standardized evaluation methodologies that can be applied across different materials domains, from polymers to metals to ceramics. There is also growing interest in hybrid approaches that combine synthetic and experimental data to leverage the strengths of both while mitigating their respective weaknesses. The ultimate technical objective remains accelerating materials discovery and development through reliable computational methods that reduce dependence on costly and time-consuming experimental work.
Synthetic materials data encompasses computationally generated information about material properties, structures, and performance characteristics. This includes data from molecular dynamics simulations, density functional theory calculations, machine learning generative models, and other computational techniques. The primary objective of evaluating such synthetic data is to determine its fidelity, reliability, and utility for downstream modeling applications that can accelerate materials innovation cycles.
The evolution of this field has been marked by several key developments, including the Materials Genome Initiative launched in 2011, which emphasized computational approaches to materials discovery, and the subsequent rise of materials informatics as a discipline. More recently, generative models such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) have been adapted specifically for materials science applications, enabling the creation of increasingly sophisticated synthetic datasets.
Current technical objectives in synthetic materials data evaluation focus on establishing robust validation frameworks that can quantify the quality and usefulness of generated data. These objectives include developing metrics for assessing data fidelity, creating benchmarks for comparing different synthetic data generation methods, and establishing protocols for determining when synthetic data is suitable for specific modeling tasks.
A critical goal is to understand the limitations and biases inherent in synthetic materials data, particularly how these might propagate through downstream modeling pipelines. This includes evaluating how well synthetic data captures the complex relationships between material structure and properties, and whether models trained on synthetic data can generalize to real-world scenarios.
Looking forward, the field aims to develop standardized evaluation methodologies that can be applied across different materials domains, from polymers to metals to ceramics. There is also growing interest in hybrid approaches that combine synthetic and experimental data to leverage the strengths of both while mitigating their respective weaknesses. The ultimate technical objective remains accelerating materials discovery and development through reliable computational methods that reduce dependence on costly and time-consuming experimental work.
Market Demand Analysis for Synthetic Materials Data
The synthetic materials data market is experiencing significant growth driven by the increasing adoption of machine learning and AI in materials science and engineering. Current market analysis indicates that materials informatics is becoming a critical component in accelerating materials discovery and development, with synthetic data playing a pivotal role in this transformation. The global materials informatics market, which encompasses synthetic data generation and utilization, is projected to grow substantially over the next five years as industries seek to reduce the time and cost associated with traditional materials development cycles.
Primary demand for synthetic materials data comes from several key sectors. The pharmaceutical and chemical industries represent the largest market segments, where high-throughput virtual screening using synthetic data can dramatically reduce the need for expensive laboratory experiments. Aerospace, automotive, and electronics manufacturers are increasingly turning to synthetic materials data to develop lighter, stronger, and more efficient components while meeting stringent regulatory requirements.
Research institutions and academic laboratories constitute another significant market segment, utilizing synthetic materials data to overcome limitations in experimental datasets and explore theoretical material properties that may be difficult or impossible to measure directly. This academic demand is further fueled by government funding initiatives focused on materials genome projects and digital materials innovation.
The market demand is particularly strong for high-quality synthetic data that accurately represents real-world material behaviors. End users require synthetic datasets that maintain statistical fidelity to physical principles while offering sufficient diversity to train robust predictive models. There is a growing premium on synthetic data that can effectively capture rare events or edge cases that might be underrepresented in experimental datasets.
Regional analysis shows North America leading the market for synthetic materials data applications, followed by Europe and rapidly growing adoption in Asia-Pacific regions, particularly in China, Japan, and South Korea. This geographic distribution aligns with centers of advanced manufacturing and materials research excellence.
Market surveys indicate that companies are willing to invest substantially in synthetic data solutions that demonstrably improve model performance and reduce development cycles. The return on investment is particularly compelling when synthetic data can help avoid costly experimental failures or identify promising material candidates that might otherwise be overlooked.
Emerging trends in the market include increasing demand for synthetic data that can bridge multiple scales (from atomic to macroscopic properties), integration capabilities with existing materials databases, and solutions that provide uncertainty quantification for downstream modeling applications. There is also growing interest in synthetic data platforms that offer customization options for specific industry applications rather than generic materials datasets.
Primary demand for synthetic materials data comes from several key sectors. The pharmaceutical and chemical industries represent the largest market segments, where high-throughput virtual screening using synthetic data can dramatically reduce the need for expensive laboratory experiments. Aerospace, automotive, and electronics manufacturers are increasingly turning to synthetic materials data to develop lighter, stronger, and more efficient components while meeting stringent regulatory requirements.
Research institutions and academic laboratories constitute another significant market segment, utilizing synthetic materials data to overcome limitations in experimental datasets and explore theoretical material properties that may be difficult or impossible to measure directly. This academic demand is further fueled by government funding initiatives focused on materials genome projects and digital materials innovation.
The market demand is particularly strong for high-quality synthetic data that accurately represents real-world material behaviors. End users require synthetic datasets that maintain statistical fidelity to physical principles while offering sufficient diversity to train robust predictive models. There is a growing premium on synthetic data that can effectively capture rare events or edge cases that might be underrepresented in experimental datasets.
Regional analysis shows North America leading the market for synthetic materials data applications, followed by Europe and rapidly growing adoption in Asia-Pacific regions, particularly in China, Japan, and South Korea. This geographic distribution aligns with centers of advanced manufacturing and materials research excellence.
Market surveys indicate that companies are willing to invest substantially in synthetic data solutions that demonstrably improve model performance and reduce development cycles. The return on investment is particularly compelling when synthetic data can help avoid costly experimental failures or identify promising material candidates that might otherwise be overlooked.
Emerging trends in the market include increasing demand for synthetic data that can bridge multiple scales (from atomic to macroscopic properties), integration capabilities with existing materials databases, and solutions that provide uncertainty quantification for downstream modeling applications. There is also growing interest in synthetic data platforms that offer customization options for specific industry applications rather than generic materials datasets.
Current State and Challenges in Synthetic Data Validation
The validation of synthetic materials data represents one of the most critical challenges in computational materials science today. Current validation methodologies often lack standardization and comprehensive evaluation frameworks, creating significant barriers to the reliable use of synthetic data in downstream modeling applications. Traditional validation approaches typically focus on statistical similarity between synthetic and real datasets, but frequently fail to capture domain-specific nuances critical for materials science applications.
A major challenge in the field is the absence of universally accepted metrics for evaluating the quality and utility of synthetic materials data. While metrics such as Maximum Mean Discrepancy (MMD) and Fréchet Inception Distance (FID) have been borrowed from other domains, they often fail to address the unique characteristics of materials data, including complex crystallographic structures, multi-scale properties, and physical constraints.
The current validation landscape is further complicated by the diversity of synthetic data generation methods, ranging from physics-based simulations to machine learning approaches like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Each generation method introduces distinct biases and artifacts that require specialized validation techniques, yet cross-method validation frameworks remain underdeveloped.
Data leakage presents another significant challenge, particularly when synthetic data inadvertently incorporates information from test sets, leading to overly optimistic performance evaluations in downstream tasks. Current detection methods for such leakage are often inadequate for the complex, high-dimensional nature of materials data.
The validation of physical consistency represents perhaps the most formidable challenge. Synthetic materials data must not only match statistical distributions but also adhere to fundamental physical laws and constraints. Current validation approaches struggle to systematically verify properties such as conservation laws, thermodynamic consistency, and structural stability across diverse materials systems.
Temporal aspects of validation are frequently overlooked in current methodologies. As materials properties can evolve over time and under varying conditions, validation frameworks must account for dynamic behaviors rather than static snapshots—a capability largely absent from existing approaches.
The computational expense of thorough validation presents a practical challenge, particularly for large-scale materials datasets. Current validation pipelines often require significant computational resources, limiting their accessibility and widespread adoption across the materials science community.
A major challenge in the field is the absence of universally accepted metrics for evaluating the quality and utility of synthetic materials data. While metrics such as Maximum Mean Discrepancy (MMD) and Fréchet Inception Distance (FID) have been borrowed from other domains, they often fail to address the unique characteristics of materials data, including complex crystallographic structures, multi-scale properties, and physical constraints.
The current validation landscape is further complicated by the diversity of synthetic data generation methods, ranging from physics-based simulations to machine learning approaches like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Each generation method introduces distinct biases and artifacts that require specialized validation techniques, yet cross-method validation frameworks remain underdeveloped.
Data leakage presents another significant challenge, particularly when synthetic data inadvertently incorporates information from test sets, leading to overly optimistic performance evaluations in downstream tasks. Current detection methods for such leakage are often inadequate for the complex, high-dimensional nature of materials data.
The validation of physical consistency represents perhaps the most formidable challenge. Synthetic materials data must not only match statistical distributions but also adhere to fundamental physical laws and constraints. Current validation approaches struggle to systematically verify properties such as conservation laws, thermodynamic consistency, and structural stability across diverse materials systems.
Temporal aspects of validation are frequently overlooked in current methodologies. As materials properties can evolve over time and under varying conditions, validation frameworks must account for dynamic behaviors rather than static snapshots—a capability largely absent from existing approaches.
The computational expense of thorough validation presents a practical challenge, particularly for large-scale materials datasets. Current validation pipelines often require significant computational resources, limiting their accessibility and widespread adoption across the materials science community.
Current Evaluation Frameworks for Synthetic Materials Data
01 Machine learning methods for synthetic materials evaluation
Machine learning algorithms are employed to evaluate and predict properties of synthetic materials. These methods can analyze large datasets of material properties, identify patterns, and make predictions about new materials without extensive physical testing. Advanced algorithms can process complex relationships between material composition, structure, and performance characteristics, enabling more efficient materials discovery and optimization.- Machine learning methods for synthetic materials evaluation: Machine learning algorithms are increasingly used to evaluate synthetic materials data. These methods can process large datasets to identify patterns, predict material properties, and optimize formulations. Advanced algorithms can analyze complex relationships between material composition and performance characteristics, enabling more efficient materials discovery and development. These approaches often incorporate neural networks and other AI techniques to enhance predictive accuracy.
- Simulation and modeling techniques for materials data: Computational simulation and modeling techniques provide valuable tools for evaluating synthetic materials before physical testing. These methods include finite element analysis, molecular dynamics simulations, and quantum mechanical calculations that can predict material behavior under various conditions. Simulation approaches allow researchers to explore material properties virtually, reducing the need for extensive experimental testing and accelerating the materials development process.
- High-throughput screening and data processing systems: High-throughput screening systems enable rapid evaluation of multiple synthetic materials simultaneously. These systems typically incorporate automated testing equipment, data acquisition tools, and specialized software for processing large volumes of experimental results. By parallelizing the evaluation process, researchers can efficiently compare material properties across numerous samples and identify promising candidates for further development.
- Statistical analysis and quality control methods: Statistical methods play a crucial role in evaluating synthetic materials data, particularly for quality control and reliability assessment. Techniques such as design of experiments, variance analysis, and statistical process control help identify significant factors affecting material performance and ensure consistency in production. These approaches enable manufacturers to establish robust evaluation protocols and make data-driven decisions about material selection and processing parameters.
- Integrated materials databases and evaluation frameworks: Comprehensive materials databases and evaluation frameworks integrate multiple data sources and analysis methods to support synthetic materials assessment. These systems typically combine experimental data, computational models, and literature information to provide holistic evaluation capabilities. Advanced frameworks often incorporate standardized testing protocols, data visualization tools, and knowledge management systems to facilitate comparison across different material types and applications.
02 Simulation-based evaluation techniques
Computational simulation techniques are used to evaluate synthetic materials by modeling their behavior under various conditions. These methods include finite element analysis, molecular dynamics simulations, and quantum mechanical calculations that can predict material properties before physical prototyping. Simulation approaches reduce development time and costs by allowing researchers to screen potential materials virtually and focus physical testing on the most promising candidates.Expand Specific Solutions03 High-throughput experimental methods
High-throughput experimental platforms enable rapid evaluation of multiple synthetic materials simultaneously. These systems combine automated sample preparation, parallel testing, and data acquisition to efficiently characterize material properties. Advanced robotics, microfluidics, and sensor arrays allow researchers to generate large datasets of material performance metrics in a fraction of the time required by traditional methods, accelerating materials development cycles.Expand Specific Solutions04 Data management and integration systems
Specialized data management systems are developed to collect, organize, and analyze synthetic materials data from multiple sources. These platforms integrate experimental results, simulation outputs, and literature data to create comprehensive materials databases. Advanced data integration techniques enable researchers to identify correlations across different evaluation methods, establish structure-property relationships, and make more informed decisions in materials development.Expand Specific Solutions05 Quality control and standardization methods
Standardized protocols and quality control methods ensure reliable evaluation of synthetic materials across different laboratories and applications. These approaches include reference materials, calibration procedures, and statistical methods to quantify uncertainty in measurements. Standardization enables meaningful comparison of materials data from different sources, facilitates regulatory compliance, and improves the reproducibility of materials evaluation results.Expand Specific Solutions
Key Players in Materials Informatics and Synthetic Data
The synthetic materials data evaluation landscape is evolving rapidly, currently transitioning from early adoption to growth phase. The market is expanding significantly as industries recognize the value of synthetic data in materials science modeling. Key players demonstrate varying levels of technological maturity: NVIDIA leads with advanced AI-driven synthetic data validation frameworks, while traditional materials companies like BASF are developing specialized evaluation protocols. Energy sector companies (Shell, ExxonMobil) are investing in proprietary validation methodologies for petroleum applications. Boeing and MTU Aero Engines focus on aerospace-specific synthetic data verification. Academic institutions (MIT, Technical University of Berlin) contribute fundamental research on statistical validation approaches, while software providers like Microsoft and Synopsys develop integrated evaluation tools for synthetic materials data pipelines.
BASF Corp.
Technical Solution: BASF has developed a sophisticated multi-stage evaluation framework for synthetic materials data that combines domain expertise with advanced statistical methods. Their approach begins with chemical feasibility assessment, where synthetic molecular structures are validated against known chemical rules and constraints. BASF employs physics-based simulations to verify that synthetic data conforms to fundamental physical laws and thermodynamic principles. Their methodology includes comparative analysis between synthetic and experimental datasets using dimensionality reduction techniques like t-SNE and UMAP to visualize distribution similarities. BASF has implemented a tiered validation system where synthetic data must pass increasingly stringent tests before being approved for different modeling applications. Their framework incorporates uncertainty quantification methods that assess confidence levels in synthetic data predictions, allowing researchers to make informed decisions about data reliability for specific downstream tasks. BASF also employs active learning techniques to iteratively improve synthetic data generation based on validation results.
Strengths: Deep domain expertise in materials science; comprehensive understanding of chemical and physical constraints; extensive experimental data for validation benchmarking. Weaknesses: Potentially conservative approach may limit novel materials discovery; validation processes may be time-intensive compared to purely computational approaches.
NVIDIA Corp.
Technical Solution: NVIDIA has developed comprehensive frameworks for evaluating synthetic materials data through their AI and high-performance computing platforms. Their approach combines physics-based simulations with machine learning to generate and validate synthetic materials data. NVIDIA's MODULUS framework enables physics-informed machine learning for materials science, allowing researchers to incorporate physical laws and constraints into neural networks that generate synthetic data. Their GPU-accelerated simulation tools can rapidly generate large volumes of synthetic materials data while maintaining physical consistency. NVIDIA also employs generative adversarial networks (GANs) to create synthetic materials datasets that preserve the statistical properties of real-world materials while expanding available training data. Their validation methodology includes uncertainty quantification techniques that assess the reliability of synthetic data for downstream modeling applications.
Strengths: Unparalleled computational power for generating high-fidelity synthetic data; extensive expertise in AI-driven validation techniques; ability to integrate physics constraints with machine learning. Weaknesses: Solutions are hardware-dependent and may require significant computational resources; complexity of implementation may present barriers for organizations without specialized expertise.
Critical Metrics and Validation Techniques Analysis
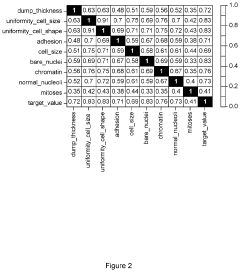
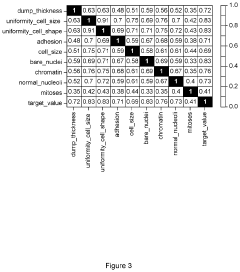
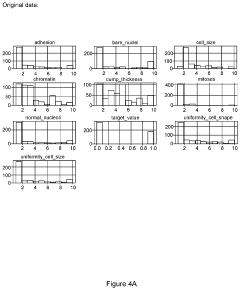
System, method, and computer-accessible medium for evaluating multi-dimensional synthetic data using integrated variants analysis
PatentActiveUS20240160502A1
Innovation
- A system and method for evaluating synthetic datasets by comparing results from models trained on original and synthetic datasets using analysis of variance and threshold procedures, with the ability to modify the synthetic datasets based on these comparisons until the results match within a specified threshold, ensuring the synthetic dataset is sufficient for model training.
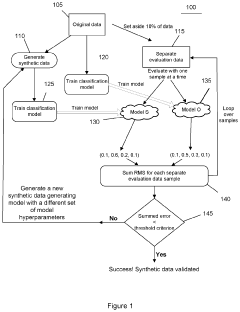
Method and system for generating fair synthetic representative data via optimal transport
PatentPendingUS20250181999A1
Innovation
- A method is implemented using a processor to generate synthetic data by receiving an original dataset with sensitive demographic features, decision-making features, and decision outcomes. The method determines a demographic parity constraint, generates synthetic data points, computes sample-level weights, and applies these weights to the synthetic data to minimize the Wasserstein distance between the original and synthetic datasets while ensuring demographic parity.
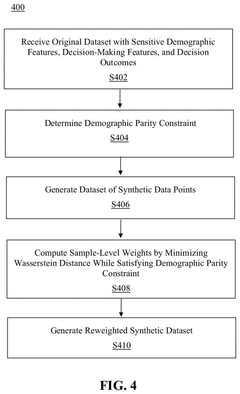
Computational Infrastructure Requirements
Evaluating synthetic materials data for downstream modeling requires robust computational infrastructure to handle the complex processes of data generation, validation, and model training. High-performance computing (HPC) systems with multi-core processors and significant RAM capacity (minimum 64GB, recommended 128GB or higher) are essential for processing large synthetic datasets efficiently. GPU acceleration, particularly using NVIDIA's CUDA-enabled cards with at least 8GB VRAM, significantly enhances performance for machine learning operations and molecular simulations.
Storage infrastructure must accommodate both the raw synthetic data and derived modeling outputs, typically requiring scalable solutions with multiple terabytes of high-speed storage. NVMe SSDs for active datasets and larger capacity HDDs or cloud storage for archival purposes create an effective tiered storage approach. When implementing distributed computing frameworks, technologies like Apache Spark, Dask, or Ray provide essential capabilities for parallel processing across computing clusters.
Containerization technologies such as Docker and Kubernetes have become indispensable for ensuring reproducibility and consistent environments across different computational platforms. These tools allow researchers to package dependencies and configurations, facilitating seamless deployment of synthetic data evaluation pipelines across various computing environments.
Specialized software requirements include molecular simulation packages (LAMMPS, GROMACS), quantum chemistry software (Quantum ESPRESSO, VASP), machine learning frameworks (PyTorch, TensorFlow), and materials informatics platforms (Matminer, Pymatgen). Integration of these diverse tools necessitates robust workflow management systems like Airflow or Prefect to orchestrate complex evaluation pipelines.
Data management infrastructure must incorporate version control systems for tracking changes in synthetic datasets and models. Solutions like DVC (Data Version Control) or specialized scientific data repositories enable proper provenance tracking and reproducibility. Additionally, metadata management systems are crucial for maintaining context about synthetic data generation parameters and validation metrics.
Network infrastructure considerations become particularly important when implementing federated learning approaches or when synthetic data evaluation involves collaboration across multiple institutions. High-bandwidth, low-latency connections are necessary for efficient data transfer, while secure VPN solutions protect sensitive synthetic data and proprietary models during transmission.
Cost optimization strategies should include leveraging cloud bursting capabilities during peak computational demands and implementing automated resource scaling based on workload requirements. Hybrid approaches combining on-premises resources with cloud services often provide the most cost-effective solution for the variable computational demands of synthetic materials data evaluation.
Storage infrastructure must accommodate both the raw synthetic data and derived modeling outputs, typically requiring scalable solutions with multiple terabytes of high-speed storage. NVMe SSDs for active datasets and larger capacity HDDs or cloud storage for archival purposes create an effective tiered storage approach. When implementing distributed computing frameworks, technologies like Apache Spark, Dask, or Ray provide essential capabilities for parallel processing across computing clusters.
Containerization technologies such as Docker and Kubernetes have become indispensable for ensuring reproducibility and consistent environments across different computational platforms. These tools allow researchers to package dependencies and configurations, facilitating seamless deployment of synthetic data evaluation pipelines across various computing environments.
Specialized software requirements include molecular simulation packages (LAMMPS, GROMACS), quantum chemistry software (Quantum ESPRESSO, VASP), machine learning frameworks (PyTorch, TensorFlow), and materials informatics platforms (Matminer, Pymatgen). Integration of these diverse tools necessitates robust workflow management systems like Airflow or Prefect to orchestrate complex evaluation pipelines.
Data management infrastructure must incorporate version control systems for tracking changes in synthetic datasets and models. Solutions like DVC (Data Version Control) or specialized scientific data repositories enable proper provenance tracking and reproducibility. Additionally, metadata management systems are crucial for maintaining context about synthetic data generation parameters and validation metrics.
Network infrastructure considerations become particularly important when implementing federated learning approaches or when synthetic data evaluation involves collaboration across multiple institutions. High-bandwidth, low-latency connections are necessary for efficient data transfer, while secure VPN solutions protect sensitive synthetic data and proprietary models during transmission.
Cost optimization strategies should include leveraging cloud bursting capabilities during peak computational demands and implementing automated resource scaling based on workload requirements. Hybrid approaches combining on-premises resources with cloud services often provide the most cost-effective solution for the variable computational demands of synthetic materials data evaluation.
Data Governance and Reproducibility Standards
Establishing robust data governance and reproducibility standards is critical when evaluating synthetic materials data for downstream modeling applications. Organizations must implement comprehensive frameworks that ensure data quality, traceability, and reproducibility throughout the entire synthetic data lifecycle. These frameworks should include detailed documentation of data generation methodologies, algorithms, parameters, and seed values used in the synthesis process.
Metadata management represents a cornerstone of effective governance for synthetic materials data. Each synthetic dataset should be accompanied by rich metadata describing its provenance, intended use cases, limitations, and validation metrics. This metadata should follow standardized schemas such as the Materials Data Curation System (MDCS) or similar domain-specific standards to facilitate interoperability across research teams and organizations.
Version control systems specifically designed for data assets are essential for maintaining reproducibility. These systems must track changes to synthetic data generation pipelines, model parameters, and validation procedures. Tools like DVC (Data Version Control) or GitLFS integrated with traditional code repositories can provide the necessary infrastructure for versioning large synthetic materials datasets alongside their generation code.
Validation protocols must be standardized and documented to ensure consistent evaluation of synthetic data quality. These protocols should include statistical tests comparing synthetic data distributions with reference data, domain-specific quality metrics, and performance benchmarks on downstream modeling tasks. Regular auditing of these validation processes helps maintain data integrity over time.
Access control and data lineage tracking form another critical component of governance frameworks. Organizations must implement systems that record who accessed synthetic datasets, how they were modified, and which downstream models incorporated them. This tracking enables compliance with regulatory requirements and facilitates troubleshooting when model performance issues arise.
Reproducibility challenges specific to materials science must be addressed through specialized standards. These include capturing stochastic elements in synthesis algorithms, documenting hardware dependencies that may affect numerical precision, and establishing procedures for reproducing edge cases or anomalies in synthetic data. Cross-validation across multiple synthetic data generation techniques can further enhance confidence in reproducibility.
Ultimately, successful implementation of governance and reproducibility standards requires organizational commitment and cultural adoption. Regular training, clear documentation, and automated compliance checking tools can help research teams integrate these practices into their daily workflows when developing and utilizing synthetic materials data for modeling applications.
Metadata management represents a cornerstone of effective governance for synthetic materials data. Each synthetic dataset should be accompanied by rich metadata describing its provenance, intended use cases, limitations, and validation metrics. This metadata should follow standardized schemas such as the Materials Data Curation System (MDCS) or similar domain-specific standards to facilitate interoperability across research teams and organizations.
Version control systems specifically designed for data assets are essential for maintaining reproducibility. These systems must track changes to synthetic data generation pipelines, model parameters, and validation procedures. Tools like DVC (Data Version Control) or GitLFS integrated with traditional code repositories can provide the necessary infrastructure for versioning large synthetic materials datasets alongside their generation code.
Validation protocols must be standardized and documented to ensure consistent evaluation of synthetic data quality. These protocols should include statistical tests comparing synthetic data distributions with reference data, domain-specific quality metrics, and performance benchmarks on downstream modeling tasks. Regular auditing of these validation processes helps maintain data integrity over time.
Access control and data lineage tracking form another critical component of governance frameworks. Organizations must implement systems that record who accessed synthetic datasets, how they were modified, and which downstream models incorporated them. This tracking enables compliance with regulatory requirements and facilitates troubleshooting when model performance issues arise.
Reproducibility challenges specific to materials science must be addressed through specialized standards. These include capturing stochastic elements in synthesis algorithms, documenting hardware dependencies that may affect numerical precision, and establishing procedures for reproducing edge cases or anomalies in synthetic data. Cross-validation across multiple synthetic data generation techniques can further enhance confidence in reproducibility.
Ultimately, successful implementation of governance and reproducibility standards requires organizational commitment and cultural adoption. Regular training, clear documentation, and automated compliance checking tools can help research teams integrate these practices into their daily workflows when developing and utilizing synthetic materials data for modeling applications.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!