

Combining High-Throughput Experiments With In-Silico Synthetic Data
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
High-Throughput Experimentation Background and Objectives
High-throughput experimentation (HTE) has emerged as a transformative approach in scientific research, enabling the rapid and systematic exploration of vast experimental spaces. This methodology, which gained prominence in the early 2000s, leverages automation, miniaturization, and parallelization to conduct thousands of experiments simultaneously, dramatically accelerating the discovery process across multiple disciplines including materials science, pharmaceuticals, and biotechnology.
The evolution of HTE has been closely tied to advancements in robotics, microfluidics, and data management systems. Initially focused on simple screening applications, modern HTE platforms now incorporate sophisticated experimental design, real-time analytics, and feedback mechanisms that allow for intelligent navigation of complex parameter spaces. This progression has shifted HTE from a brute-force approach to a more nuanced and efficient discovery tool.
Despite these advances, HTE faces inherent limitations in experimental throughput, cost constraints, and physical feasibility. These challenges have spurred interest in complementary computational approaches, particularly in-silico synthetic data generation. The integration of experimental and computational methodologies represents the frontier of modern scientific discovery.
In-silico synthetic data generation leverages computational models to simulate experimental outcomes, creating artificial datasets that mimic real-world observations. This approach has gained traction with recent breakthroughs in machine learning, particularly generative models and physics-informed neural networks, which can produce increasingly realistic synthetic data while respecting underlying scientific principles.
The convergence of HTE with in-silico methods aims to achieve several critical objectives. First, it seeks to expand the accessible experimental space beyond physical constraints, enabling exploration of conditions that would be impractical or impossible to test experimentally. Second, it aims to enhance experimental efficiency by using synthetic data to guide physical experiments toward promising regions of parameter space.
Additionally, this combined approach targets improved predictive modeling by creating feedback loops between experimental validation and computational refinement. The ultimate goal is to establish a synergistic framework where physical experiments validate and refine computational models, while computational insights direct experimental focus to maximize discovery potential.
As we look forward, the integration of HTE with synthetic data generation promises to revolutionize scientific discovery by dramatically accelerating innovation cycles, reducing research costs, and enabling exploration of previously inaccessible knowledge domains. This technological convergence represents a paradigm shift in how we approach complex scientific challenges across disciplines.
The evolution of HTE has been closely tied to advancements in robotics, microfluidics, and data management systems. Initially focused on simple screening applications, modern HTE platforms now incorporate sophisticated experimental design, real-time analytics, and feedback mechanisms that allow for intelligent navigation of complex parameter spaces. This progression has shifted HTE from a brute-force approach to a more nuanced and efficient discovery tool.
Despite these advances, HTE faces inherent limitations in experimental throughput, cost constraints, and physical feasibility. These challenges have spurred interest in complementary computational approaches, particularly in-silico synthetic data generation. The integration of experimental and computational methodologies represents the frontier of modern scientific discovery.
In-silico synthetic data generation leverages computational models to simulate experimental outcomes, creating artificial datasets that mimic real-world observations. This approach has gained traction with recent breakthroughs in machine learning, particularly generative models and physics-informed neural networks, which can produce increasingly realistic synthetic data while respecting underlying scientific principles.
The convergence of HTE with in-silico methods aims to achieve several critical objectives. First, it seeks to expand the accessible experimental space beyond physical constraints, enabling exploration of conditions that would be impractical or impossible to test experimentally. Second, it aims to enhance experimental efficiency by using synthetic data to guide physical experiments toward promising regions of parameter space.
Additionally, this combined approach targets improved predictive modeling by creating feedback loops between experimental validation and computational refinement. The ultimate goal is to establish a synergistic framework where physical experiments validate and refine computational models, while computational insights direct experimental focus to maximize discovery potential.
As we look forward, the integration of HTE with synthetic data generation promises to revolutionize scientific discovery by dramatically accelerating innovation cycles, reducing research costs, and enabling exploration of previously inaccessible knowledge domains. This technological convergence represents a paradigm shift in how we approach complex scientific challenges across disciplines.
Market Demand Analysis for Hybrid Experimental Approaches
The integration of high-throughput experimentation with in-silico synthetic data represents a rapidly growing market segment across multiple industries. Current market analysis indicates substantial demand for hybrid experimental approaches that combine real-world testing with computational modeling, driven primarily by cost reduction imperatives and accelerated development timelines.
The pharmaceutical and biotechnology sectors demonstrate the most immediate market need, with an estimated market size exceeding $5 billion for hybrid drug discovery platforms. These industries face mounting pressure to reduce the average $2.6 billion cost of bringing a new drug to market while shortening the typical 10-12 year development cycle. Hybrid approaches that reduce physical testing requirements while maintaining or improving predictive accuracy have shown potential to cut development costs by 30-40%.
Materials science represents another significant market, particularly in advanced materials development for electronics, aerospace, and automotive applications. Companies in these sectors report that hybrid experimental approaches can reduce material development cycles from 5-7 years to 2-3 years, creating substantial competitive advantages in rapidly evolving markets.
The agricultural technology sector shows growing demand for hybrid approaches in crop protection and enhancement product development. Market research indicates that companies implementing these methodologies have achieved 25-35% reductions in field testing requirements while maintaining regulatory compliance standards.
Consumer product companies are increasingly adopting hybrid approaches for formulation optimization across personal care, home care, and food products. This market segment values the ability to rapidly iterate through thousands of potential formulations virtually before conducting targeted physical testing on the most promising candidates.
From a geographical perspective, North America currently leads market demand (38%), followed by Europe (29%) and Asia-Pacific (24%), with the latter showing the fastest growth rate. This distribution reflects both technological readiness and regulatory environments that increasingly accept in-silico data as complementary evidence.
Key market drivers include the exponential growth in computational power, advances in machine learning algorithms that improve predictive accuracy, and the development of specialized software platforms that facilitate seamless integration between physical and virtual experimentation. Additionally, regulatory bodies in multiple industries are increasingly accepting well-validated in-silico data as supplementary evidence, further accelerating market adoption.
The pharmaceutical and biotechnology sectors demonstrate the most immediate market need, with an estimated market size exceeding $5 billion for hybrid drug discovery platforms. These industries face mounting pressure to reduce the average $2.6 billion cost of bringing a new drug to market while shortening the typical 10-12 year development cycle. Hybrid approaches that reduce physical testing requirements while maintaining or improving predictive accuracy have shown potential to cut development costs by 30-40%.
Materials science represents another significant market, particularly in advanced materials development for electronics, aerospace, and automotive applications. Companies in these sectors report that hybrid experimental approaches can reduce material development cycles from 5-7 years to 2-3 years, creating substantial competitive advantages in rapidly evolving markets.
The agricultural technology sector shows growing demand for hybrid approaches in crop protection and enhancement product development. Market research indicates that companies implementing these methodologies have achieved 25-35% reductions in field testing requirements while maintaining regulatory compliance standards.
Consumer product companies are increasingly adopting hybrid approaches for formulation optimization across personal care, home care, and food products. This market segment values the ability to rapidly iterate through thousands of potential formulations virtually before conducting targeted physical testing on the most promising candidates.
From a geographical perspective, North America currently leads market demand (38%), followed by Europe (29%) and Asia-Pacific (24%), with the latter showing the fastest growth rate. This distribution reflects both technological readiness and regulatory environments that increasingly accept in-silico data as complementary evidence.
Key market drivers include the exponential growth in computational power, advances in machine learning algorithms that improve predictive accuracy, and the development of specialized software platforms that facilitate seamless integration between physical and virtual experimentation. Additionally, regulatory bodies in multiple industries are increasingly accepting well-validated in-silico data as supplementary evidence, further accelerating market adoption.
Current Challenges in Combining Real and Synthetic Data
The integration of high-throughput experimental data with in-silico synthetic data presents significant challenges despite its promising potential. One primary obstacle is the inherent discrepancy between real-world experimental data and computationally generated synthetic data. Real experimental data contains natural variations, noise, and anomalies that are difficult to accurately replicate in synthetic datasets, leading to potential biases when these datasets are combined.
Data compatibility issues further complicate integration efforts. Differences in data formats, resolution, dimensionality, and measurement scales between experimental and synthetic datasets often necessitate complex preprocessing and normalization procedures. These transformations can inadvertently introduce artifacts or distort important signal features, compromising the integrity of subsequent analyses.
Validation methodologies represent another significant challenge. Traditional validation approaches may not be suitable for evaluating combined datasets, as they often assume homogeneity in data sources. Developing robust validation frameworks that can effectively assess the quality and reliability of integrated real and synthetic data remains an open research question.
Computational resource requirements pose practical limitations. Processing and analyzing high-throughput experimental data alongside synthetic datasets demands substantial computational power and storage capacity. This is particularly problematic for organizations with limited infrastructure, potentially creating barriers to entry for smaller research groups or companies.
Regulatory and ethical considerations add another layer of complexity. In fields like healthcare and pharmaceuticals, the use of synthetic data alongside real patient data raises questions about data privacy, consent, and regulatory compliance. Clear guidelines for the appropriate use of combined datasets in regulated environments are still evolving.
Domain expertise gaps present operational challenges. Effective integration requires interdisciplinary knowledge spanning experimental techniques, computational modeling, statistical analysis, and domain-specific expertise. Finding professionals with this diverse skill set or facilitating effective collaboration between specialists from different backgrounds can be difficult.
Lastly, methodological standardization remains underdeveloped. The lack of established best practices and standardized protocols for combining high-throughput experimental data with synthetic data leads to inconsistent approaches across different research groups. This hampers reproducibility and makes it difficult to compare results across studies, ultimately slowing progress in the field.
Data compatibility issues further complicate integration efforts. Differences in data formats, resolution, dimensionality, and measurement scales between experimental and synthetic datasets often necessitate complex preprocessing and normalization procedures. These transformations can inadvertently introduce artifacts or distort important signal features, compromising the integrity of subsequent analyses.
Validation methodologies represent another significant challenge. Traditional validation approaches may not be suitable for evaluating combined datasets, as they often assume homogeneity in data sources. Developing robust validation frameworks that can effectively assess the quality and reliability of integrated real and synthetic data remains an open research question.
Computational resource requirements pose practical limitations. Processing and analyzing high-throughput experimental data alongside synthetic datasets demands substantial computational power and storage capacity. This is particularly problematic for organizations with limited infrastructure, potentially creating barriers to entry for smaller research groups or companies.
Regulatory and ethical considerations add another layer of complexity. In fields like healthcare and pharmaceuticals, the use of synthetic data alongside real patient data raises questions about data privacy, consent, and regulatory compliance. Clear guidelines for the appropriate use of combined datasets in regulated environments are still evolving.
Domain expertise gaps present operational challenges. Effective integration requires interdisciplinary knowledge spanning experimental techniques, computational modeling, statistical analysis, and domain-specific expertise. Finding professionals with this diverse skill set or facilitating effective collaboration between specialists from different backgrounds can be difficult.
Lastly, methodological standardization remains underdeveloped. The lack of established best practices and standardized protocols for combining high-throughput experimental data with synthetic data leads to inconsistent approaches across different research groups. This hampers reproducibility and makes it difficult to compare results across studies, ultimately slowing progress in the field.
Existing Integration Frameworks and Methodologies
01 Integration of high-throughput experiments with synthetic data generation
The combination of high-throughput experimental methods with in-silico synthetic data generation enables researchers to enhance data quality and quantity. This approach allows for the creation of comprehensive datasets where experimental data may be limited or difficult to obtain. By generating synthetic data that mimics real experimental outcomes, researchers can improve model training, validate experimental results, and accelerate discovery processes across various scientific domains.- Integration of high-throughput experiments with synthetic data generation: The combination of high-throughput experimental methods with in-silico synthetic data generation enables researchers to enhance data quality and quantity. This approach allows for the creation of comprehensive datasets where experimental data may be limited or expensive to obtain. By supplementing real experimental results with computationally generated synthetic data, researchers can improve model training, validate hypotheses, and accelerate discovery processes while reducing costs and experimental time.
- Machine learning applications for synthetic data in experimental design: Machine learning algorithms can be used to generate synthetic data that complements high-throughput experiments. These algorithms analyze patterns in existing experimental data to create realistic synthetic datasets that preserve statistical properties and relationships. The synthetic data can then be used to optimize experimental design, identify promising research directions, and improve predictive models. This approach is particularly valuable in fields where experimental data collection is time-consuming or resource-intensive.
- Validation and quality control of synthetic data in scientific research: Methods for validating and ensuring the quality of synthetic data when combined with high-throughput experimental results are essential for scientific integrity. These approaches include statistical comparison between synthetic and real data, cross-validation techniques, and benchmarking against known standards. By implementing robust validation protocols, researchers can ensure that conclusions drawn from combined real and synthetic datasets are reliable and reproducible, maintaining scientific rigor while benefiting from expanded data resources.
- Computational frameworks for integrating experimental and synthetic data: Specialized computational frameworks facilitate the seamless integration of high-throughput experimental results with in-silico synthetic data. These frameworks provide tools for data harmonization, feature extraction, and analysis of combined datasets. They often include visualization capabilities, statistical analysis tools, and interfaces for various experimental platforms. Such integrated systems enable researchers to efficiently manage complex data workflows and extract meaningful insights from the combination of real and synthetic data sources.
- Applications in drug discovery and biomedical research: The combination of high-throughput experiments with in-silico synthetic data has significant applications in drug discovery and biomedical research. This approach enables virtual screening of compound libraries, prediction of drug-target interactions, and simulation of biological responses. By supplementing limited experimental data with synthetic data, researchers can explore larger chemical spaces, identify potential therapeutic candidates more efficiently, and reduce the need for extensive laboratory testing, ultimately accelerating the drug development process.
02 Machine learning algorithms for synthetic data augmentation
Advanced machine learning techniques are employed to generate synthetic data that complements high-throughput experimental results. These algorithms analyze patterns in existing experimental data to create realistic synthetic datasets that preserve statistical properties and biological relevance. The synthetic data can be used to fill gaps in experimental datasets, improve model robustness, and enable more comprehensive analysis without requiring additional laboratory experiments.Expand Specific Solutions03 Validation frameworks for synthetic data in scientific research
Specialized validation frameworks ensure that in-silico synthetic data accurately represents real-world phenomena and can be reliably used alongside high-throughput experimental data. These frameworks employ statistical methods to compare synthetic data distributions with experimental results, assess biological plausibility, and quantify uncertainty. Proper validation enables researchers to confidently use synthetic data for hypothesis testing, experimental design optimization, and predictive modeling.Expand Specific Solutions04 Computational infrastructure for parallel processing of experimental and synthetic data
Specialized computational infrastructures enable efficient processing of both high-throughput experimental data and in-silico synthetic data. These systems utilize parallel computing architectures, distributed processing frameworks, and optimized algorithms to handle the massive datasets generated through both approaches. The infrastructure facilitates seamless integration of experimental and synthetic data, enabling real-time analysis, model training, and decision-making in research workflows.Expand Specific Solutions05 Applications in drug discovery and biomedical research
The combination of high-throughput experiments with in-silico synthetic data has transformative applications in drug discovery and biomedical research. This approach enables virtual screening of compound libraries, prediction of drug-target interactions, simulation of clinical trials, and modeling of complex biological systems. By supplementing limited experimental data with synthetic data, researchers can accelerate the identification of promising drug candidates, optimize experimental designs, and reduce the cost and time required for drug development.Expand Specific Solutions
Key Industry Players and Research Institutions
The field of combining high-throughput experiments with in-silico synthetic data is currently in a growth phase, characterized by increasing adoption across pharmaceutical, materials science, and energy sectors. The market is expanding rapidly, estimated at $2-3 billion with projected annual growth of 15-20% as organizations seek to reduce R&D costs and accelerate innovation cycles. Technology maturity varies significantly across players: established companies like IBM, MathWorks, and GSK have developed sophisticated platforms integrating experimental and computational approaches, while specialized firms like Zymergen, Natera, and Novogene are advancing domain-specific applications. Academic institutions (Carnegie Mellon, KAIST) and government laboratories (Naval Research Laboratory, CSIR) are driving fundamental research, creating a competitive landscape where cross-sector collaboration is increasingly common to address complex multidisciplinary challenges.
The MathWorks, Inc.
Technical Solution: MathWorks has developed a comprehensive software ecosystem centered around MATLAB and Simulink that enables the integration of high-throughput experimental data with in-silico synthetic data generation. Their platform provides specialized toolboxes for statistical analysis, machine learning, and simulation that allow researchers to create digital twins of physical systems. These digital models can generate synthetic data that complements experimental results, enabling more comprehensive analysis and prediction. MathWorks' solutions include automated workflows for data preprocessing, feature extraction, and model training that can handle the large datasets typical of high-throughput experiments. Their software supports the development of surrogate models that can rapidly predict outcomes without running full physical simulations, accelerating the design-test cycle. The platform includes capabilities for uncertainty quantification and sensitivity analysis, helping researchers understand the reliability of both experimental and synthetic data. MathWorks' tools enable the creation of closed-loop systems where experimental results continuously refine computational models, which in turn guide future experiments.
Strengths: Mature, well-documented software ecosystem with extensive industry adoption, strong integration capabilities with laboratory equipment and data sources, and comprehensive tools for both data analysis and visualization. Weaknesses: Requires significant expertise to fully leverage advanced capabilities, potential computational limitations for extremely large-scale simulations, and subscription-based licensing model that may be costly for smaller organizations.
Accelergy Corp.
Technical Solution: Accelergy has pioneered an innovative approach to materials discovery by developing a platform that seamlessly integrates high-throughput experimentation with advanced computational modeling. Their technology combines automated laboratory systems with proprietary algorithms that generate synthetic data to fill gaps in experimental knowledge. Accelergy's platform employs machine learning models trained on both historical experimental results and theoretical calculations to predict the properties of novel materials before physical synthesis. Their system includes a feedback mechanism where experimental results are continuously used to refine computational models, improving prediction accuracy over time. Accelergy has developed specialized hardware interfaces that allow direct communication between laboratory equipment and computational resources, enabling real-time adjustments to experimental parameters based on in-silico predictions. Their platform includes visualization tools that help researchers identify patterns and relationships across both experimental and synthetic datasets, facilitating deeper insights and more efficient exploration of materials space.
Strengths: Highly specialized focus on materials discovery applications, seamless integration between experimental and computational workflows, and adaptive learning systems that improve with additional data. Weaknesses: More limited market presence compared to larger competitors, potential challenges scaling to very diverse application domains, and dependence on quality of initial training data for model accuracy.
Core Technologies for Synthetic Data Generation and Validation
User-configurable generic experiment class for combinatorial materials research
PatentInactiveUS7213034B2
Innovation
- A user-configurable generic experiment model and class that allows researchers to define variables and store data in a flexible format, enabling efficient data processing and storage through a generic experiment object model that can be extended dynamically without additional software development, facilitating rapid data storage and querying.
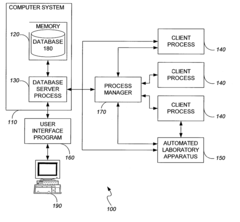
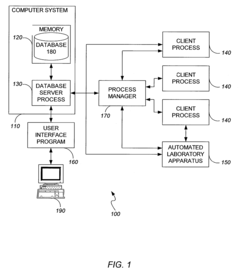
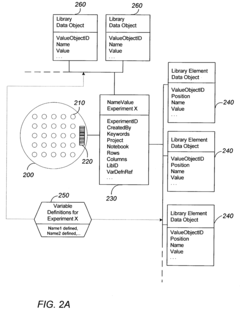
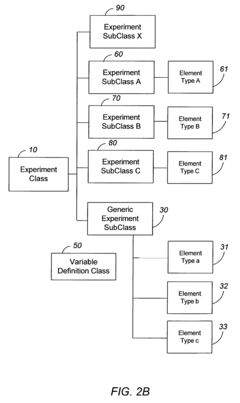
Techniques for training a classifier to detect executional artifacts in microwell plates
PatentPendingUS20220027795A1
Innovation
- A method is developed to train a classifier using spatial information from heat maps to automatically detect executional artifacts by computing feature vectors, applying wavelet transforms, and executing machine learning operations to generate a trained classifier that classifies microwell plates based on labels associated with executional artifacts, enabling consistent and objective analysis.
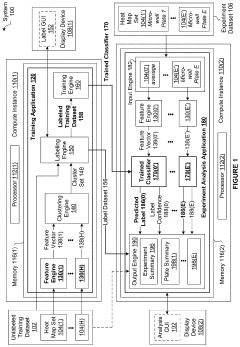
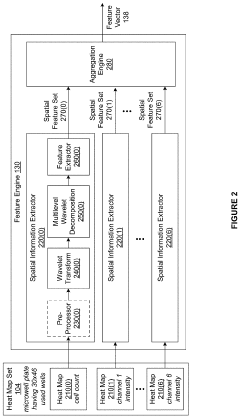
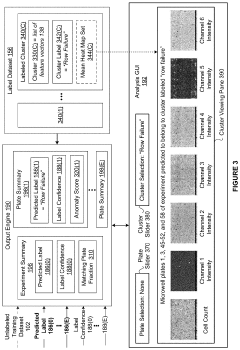
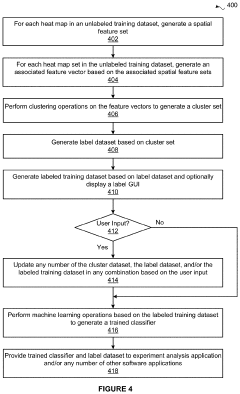
Data Quality and Reproducibility Considerations
The integration of high-throughput experimental data with in-silico synthetic data introduces significant challenges regarding data quality and reproducibility. Ensuring high-quality data is paramount as the combination of these two data sources can amplify errors if not properly managed. Experimental data often contains noise, outliers, and systematic biases that must be identified and addressed before integration with synthetic data. Similarly, synthetic data generation algorithms may incorporate assumptions or simplifications that limit their fidelity to real-world phenomena.
Reproducibility challenges emerge at multiple levels in this integrated approach. High-throughput experiments themselves face reproducibility issues due to variations in experimental conditions, reagent quality, and instrument calibration. When these experiments are combined with computational models generating synthetic data, the complexity of ensuring reproducibility increases exponentially. Documentation of both experimental protocols and computational parameters becomes critical for enabling independent verification of results.
Data validation frameworks must be established to assess the quality of both experimental and synthetic datasets before integration. These frameworks should include statistical methods for outlier detection, normalization techniques to address batch effects, and consistency checks between experimental replicates. For synthetic data, validation should include comparison against known benchmarks and sensitivity analysis of model parameters to ensure robustness.
Standardization of data formats and metadata is essential for maintaining data quality across the experimental-computational interface. Comprehensive metadata should capture all relevant experimental conditions and computational parameters to enable proper interpretation and reuse of integrated datasets. Industry standards such as FAIR principles (Findable, Accessible, Interoperable, Reusable) provide valuable guidelines for data management in this context.
Quality control metrics must be continuously monitored throughout the data lifecycle. This includes tracking data provenance from raw experimental measurements through various processing steps to final integration with synthetic data. Automated quality control pipelines can help identify issues early and maintain consistency across large datasets. Version control systems should be implemented for both experimental protocols and computational models to ensure traceability.
Cross-validation between experimental and synthetic data represents a powerful approach for assessing overall data quality. Discrepancies between these data sources can highlight potential issues in either experimental procedures or computational models. Establishing feedback loops where synthetic data predictions guide experimental design, and experimental results inform model refinement, can progressively improve data quality and reproducibility over time.
Reproducibility challenges emerge at multiple levels in this integrated approach. High-throughput experiments themselves face reproducibility issues due to variations in experimental conditions, reagent quality, and instrument calibration. When these experiments are combined with computational models generating synthetic data, the complexity of ensuring reproducibility increases exponentially. Documentation of both experimental protocols and computational parameters becomes critical for enabling independent verification of results.
Data validation frameworks must be established to assess the quality of both experimental and synthetic datasets before integration. These frameworks should include statistical methods for outlier detection, normalization techniques to address batch effects, and consistency checks between experimental replicates. For synthetic data, validation should include comparison against known benchmarks and sensitivity analysis of model parameters to ensure robustness.
Standardization of data formats and metadata is essential for maintaining data quality across the experimental-computational interface. Comprehensive metadata should capture all relevant experimental conditions and computational parameters to enable proper interpretation and reuse of integrated datasets. Industry standards such as FAIR principles (Findable, Accessible, Interoperable, Reusable) provide valuable guidelines for data management in this context.
Quality control metrics must be continuously monitored throughout the data lifecycle. This includes tracking data provenance from raw experimental measurements through various processing steps to final integration with synthetic data. Automated quality control pipelines can help identify issues early and maintain consistency across large datasets. Version control systems should be implemented for both experimental protocols and computational models to ensure traceability.
Cross-validation between experimental and synthetic data represents a powerful approach for assessing overall data quality. Discrepancies between these data sources can highlight potential issues in either experimental procedures or computational models. Establishing feedback loops where synthetic data predictions guide experimental design, and experimental results inform model refinement, can progressively improve data quality and reproducibility over time.
Regulatory and Ethical Implications of Synthetic Data Usage
The integration of synthetic data with high-throughput experiments introduces significant regulatory and ethical considerations that must be addressed to ensure responsible implementation. Current regulatory frameworks across jurisdictions vary considerably in their approach to synthetic data usage, with some regions like the European Union under GDPR providing clearer guidelines than others. These regulations typically focus on data privacy, security standards, and the potential for synthetic data to circumvent existing data protection measures.
A primary regulatory concern involves the validation and verification processes for synthetic data. Without standardized protocols to assess the quality and representativeness of synthetic datasets, there remains uncertainty about their regulatory acceptance in critical applications such as drug development or clinical trials. Regulatory bodies including the FDA and EMA are actively developing frameworks to evaluate synthetic data's reliability, but comprehensive guidelines remain under development.
Ethical implications extend beyond regulatory compliance, touching on issues of transparency and trust. When synthetic data is used alongside experimental results, clear disclosure practices become essential to maintain scientific integrity. The scientific community must establish norms regarding proper attribution and documentation of synthetic data sources, ensuring that downstream analyses can distinguish between experimental and synthetically generated information.
Privacy paradoxes present another ethical dimension, as synthetic data is often promoted as a privacy-enhancing technology while simultaneously raising concerns about potential re-identification risks. Advanced synthetic data generation techniques may inadvertently encode patterns that could lead to privacy breaches when combined with other data sources. This necessitates ongoing privacy risk assessments and the implementation of technical safeguards to prevent unintended information leakage.
Equity considerations also emerge when examining who benefits from synthetic data technologies. Access disparities to sophisticated synthetic data generation tools could exacerbate existing inequalities in research capabilities between well-resourced and under-resourced institutions. Ensuring equitable access to these technologies represents an important ethical imperative to prevent widening the digital divide in scientific research.
Informed consent frameworks require reconsideration in the context of synthetic data derived from human subjects' information. Questions arise regarding whether original consent extends to the creation and distribution of synthetic derivatives, particularly when these datasets enable analyses not contemplated in initial consent processes. Developing dynamic consent models that accommodate the evolving nature of synthetic data applications may provide a path forward for ethically sound practices.
A primary regulatory concern involves the validation and verification processes for synthetic data. Without standardized protocols to assess the quality and representativeness of synthetic datasets, there remains uncertainty about their regulatory acceptance in critical applications such as drug development or clinical trials. Regulatory bodies including the FDA and EMA are actively developing frameworks to evaluate synthetic data's reliability, but comprehensive guidelines remain under development.
Ethical implications extend beyond regulatory compliance, touching on issues of transparency and trust. When synthetic data is used alongside experimental results, clear disclosure practices become essential to maintain scientific integrity. The scientific community must establish norms regarding proper attribution and documentation of synthetic data sources, ensuring that downstream analyses can distinguish between experimental and synthetically generated information.
Privacy paradoxes present another ethical dimension, as synthetic data is often promoted as a privacy-enhancing technology while simultaneously raising concerns about potential re-identification risks. Advanced synthetic data generation techniques may inadvertently encode patterns that could lead to privacy breaches when combined with other data sources. This necessitates ongoing privacy risk assessments and the implementation of technical safeguards to prevent unintended information leakage.
Equity considerations also emerge when examining who benefits from synthetic data technologies. Access disparities to sophisticated synthetic data generation tools could exacerbate existing inequalities in research capabilities between well-resourced and under-resourced institutions. Ensuring equitable access to these technologies represents an important ethical imperative to prevent widening the digital divide in scientific research.
Informed consent frameworks require reconsideration in the context of synthetic data derived from human subjects' information. Questions arise regarding whether original consent extends to the creation and distribution of synthetic derivatives, particularly when these datasets enable analyses not contemplated in initial consent processes. Developing dynamic consent models that accommodate the evolving nature of synthetic data applications may provide a path forward for ethically sound practices.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!