Automated Closed-Loop Labs: Role Of Synthetic Data In Decision Making
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Automated Lab Evolution and Objectives
The evolution of automated laboratory systems has undergone significant transformation over the past decade, transitioning from basic robotic sample handling to sophisticated closed-loop experimentation platforms. Initially, laboratory automation focused primarily on high-throughput screening and repetitive tasks, with limited decision-making capabilities. The emergence of machine learning algorithms in the mid-2010s marked a pivotal shift, enabling systems to analyze experimental results and suggest subsequent experiments.
The integration of artificial intelligence with laboratory hardware has accelerated since 2018, with pioneering work at institutions like MIT, Stanford, and industrial research centers at companies such as Merck and Pfizer. These developments have established the foundation for what we now recognize as Automated Closed-Loop Labs—systems capable of designing experiments, executing them, analyzing results, and iteratively refining experimental parameters without human intervention.
A critical advancement in this evolution has been the incorporation of synthetic data generation capabilities. Initially, synthetic data served merely as a supplementary training resource for machine learning models. However, its role has expanded dramatically to become a cornerstone of experimental design and decision-making processes within automated laboratory environments.
The current technological objective centers on developing fully autonomous laboratory systems that can leverage synthetic data to navigate complex experimental spaces efficiently. This includes the ability to generate high-quality synthetic datasets that accurately represent potential experimental outcomes, thereby enabling more informed decision-making about which physical experiments to prioritize.
Key technical goals include reducing the dependency on extensive physical experimentation through improved synthetic data fidelity, developing robust validation frameworks to assess synthetic data quality, and creating adaptive algorithms that can continuously refine synthetic data models based on real experimental feedback.
The ultimate aim is to establish a symbiotic relationship between physical experimentation and synthetic data generation, where each informs and enhances the other. This would enable unprecedented acceleration in scientific discovery across multiple domains including drug discovery, materials science, and chemical engineering.
Industry projections suggest that achieving these objectives could reduce research timelines by 40-60% while simultaneously increasing the probability of successful outcomes through more comprehensive exploration of experimental possibilities. The convergence of automated experimentation with synthetic data represents a paradigm shift in how scientific research is conducted, promising to democratize access to advanced research capabilities and accelerate innovation across sectors.
The integration of artificial intelligence with laboratory hardware has accelerated since 2018, with pioneering work at institutions like MIT, Stanford, and industrial research centers at companies such as Merck and Pfizer. These developments have established the foundation for what we now recognize as Automated Closed-Loop Labs—systems capable of designing experiments, executing them, analyzing results, and iteratively refining experimental parameters without human intervention.
A critical advancement in this evolution has been the incorporation of synthetic data generation capabilities. Initially, synthetic data served merely as a supplementary training resource for machine learning models. However, its role has expanded dramatically to become a cornerstone of experimental design and decision-making processes within automated laboratory environments.
The current technological objective centers on developing fully autonomous laboratory systems that can leverage synthetic data to navigate complex experimental spaces efficiently. This includes the ability to generate high-quality synthetic datasets that accurately represent potential experimental outcomes, thereby enabling more informed decision-making about which physical experiments to prioritize.
Key technical goals include reducing the dependency on extensive physical experimentation through improved synthetic data fidelity, developing robust validation frameworks to assess synthetic data quality, and creating adaptive algorithms that can continuously refine synthetic data models based on real experimental feedback.
The ultimate aim is to establish a symbiotic relationship between physical experimentation and synthetic data generation, where each informs and enhances the other. This would enable unprecedented acceleration in scientific discovery across multiple domains including drug discovery, materials science, and chemical engineering.
Industry projections suggest that achieving these objectives could reduce research timelines by 40-60% while simultaneously increasing the probability of successful outcomes through more comprehensive exploration of experimental possibilities. The convergence of automated experimentation with synthetic data represents a paradigm shift in how scientific research is conducted, promising to democratize access to advanced research capabilities and accelerate innovation across sectors.
Market Demand Analysis for Closed-Loop Laboratory Systems
The market for automated closed-loop laboratory systems is experiencing significant growth, driven by increasing demands for efficiency, reproducibility, and accelerated innovation across multiple industries. Current market analysis indicates that pharmaceutical and biotechnology sectors represent the largest market segments, with an estimated annual growth rate of 15-20% for automated lab solutions incorporating synthetic data capabilities.
Research institutions and academic laboratories are rapidly adopting these technologies, particularly as funding agencies increasingly prioritize data-driven research methodologies. The integration of synthetic data in closed-loop systems addresses critical market pain points, including data scarcity in rare disease research, ethical constraints in clinical trials, and the high costs associated with physical experimentation.
Market surveys reveal that over 70% of laboratory directors cite decision-making optimization as their primary motivation for implementing closed-loop systems. The ability to generate and utilize synthetic data to simulate experimental outcomes before physical implementation represents a compelling value proposition, potentially reducing research timelines by 30-40% according to early adopters.
The market demand is further strengthened by regulatory trends favoring increased automation and data integrity in research environments. Regulatory bodies in North America and Europe have begun establishing frameworks for validating synthetic data applications in regulated research, signaling growing acceptance of these methodologies.
Geographically, North America currently leads market demand, followed by Europe and rapidly growing adoption in Asia-Pacific regions, particularly in China, Japan, and Singapore where significant investments in research infrastructure are occurring. Industry analysts project the global market for closed-loop laboratory systems incorporating synthetic data capabilities could reach $5-7 billion by 2028.
Customer segmentation analysis reveals distinct demand patterns: large pharmaceutical companies seek enterprise-wide implementations focusing on cross-functional data integration; biotechnology startups prioritize scalable systems with lower initial investment requirements; and academic institutions emphasize open architecture solutions compatible with existing research infrastructure.
The market is also witnessing increased demand for specialized applications in emerging fields such as personalized medicine, where synthetic patient data can accelerate treatment protocol development while addressing privacy concerns. Similarly, materials science and chemical industries are adopting these systems to reduce development cycles for new compounds.
Return on investment considerations remain a key factor influencing market demand, with organizations increasingly requiring demonstrable efficiency gains and cost reductions to justify implementation. Vendors offering subscription-based models and modular implementation approaches are gaining market share by addressing these concerns.
Research institutions and academic laboratories are rapidly adopting these technologies, particularly as funding agencies increasingly prioritize data-driven research methodologies. The integration of synthetic data in closed-loop systems addresses critical market pain points, including data scarcity in rare disease research, ethical constraints in clinical trials, and the high costs associated with physical experimentation.
Market surveys reveal that over 70% of laboratory directors cite decision-making optimization as their primary motivation for implementing closed-loop systems. The ability to generate and utilize synthetic data to simulate experimental outcomes before physical implementation represents a compelling value proposition, potentially reducing research timelines by 30-40% according to early adopters.
The market demand is further strengthened by regulatory trends favoring increased automation and data integrity in research environments. Regulatory bodies in North America and Europe have begun establishing frameworks for validating synthetic data applications in regulated research, signaling growing acceptance of these methodologies.
Geographically, North America currently leads market demand, followed by Europe and rapidly growing adoption in Asia-Pacific regions, particularly in China, Japan, and Singapore where significant investments in research infrastructure are occurring. Industry analysts project the global market for closed-loop laboratory systems incorporating synthetic data capabilities could reach $5-7 billion by 2028.
Customer segmentation analysis reveals distinct demand patterns: large pharmaceutical companies seek enterprise-wide implementations focusing on cross-functional data integration; biotechnology startups prioritize scalable systems with lower initial investment requirements; and academic institutions emphasize open architecture solutions compatible with existing research infrastructure.
The market is also witnessing increased demand for specialized applications in emerging fields such as personalized medicine, where synthetic patient data can accelerate treatment protocol development while addressing privacy concerns. Similarly, materials science and chemical industries are adopting these systems to reduce development cycles for new compounds.
Return on investment considerations remain a key factor influencing market demand, with organizations increasingly requiring demonstrable efficiency gains and cost reductions to justify implementation. Vendors offering subscription-based models and modular implementation approaches are gaining market share by addressing these concerns.
Current State and Challenges in Synthetic Data Generation
Synthetic data generation has evolved significantly over the past decade, transitioning from simple statistical sampling methods to sophisticated AI-driven approaches. Currently, the field employs various techniques including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models to create realistic synthetic datasets that mimic real-world data distributions while preserving privacy and addressing data scarcity issues.
In automated closed-loop laboratories, synthetic data serves as a critical component for decision-making processes, enabling rapid experimentation and hypothesis testing without the constraints of physical experimentation. However, the current state of synthetic data generation faces several significant challenges that limit its effectiveness and widespread adoption.
Data quality and fidelity remain primary concerns, as synthetic data often fails to capture the nuanced complexities and edge cases present in real-world data. This limitation is particularly problematic in scientific domains where subtle patterns and anomalies can significantly impact experimental outcomes and decision-making processes. The "reality gap" between synthetic and real data continues to pose challenges for transferability of insights.
Validation methodologies for synthetic data represent another substantial challenge. Current approaches lack standardized metrics and frameworks to evaluate how well synthetic data preserves the statistical properties and relationships of the original data while maintaining utility for downstream tasks in automated laboratories. This deficiency creates uncertainty about the reliability of decisions based on synthetic data.
Computational resource requirements present practical limitations, especially for generating high-dimensional, complex datasets needed in scientific experimentation. The most advanced generative models demand significant processing power and specialized hardware, creating barriers to implementation for many research institutions and smaller organizations.
Domain-specific challenges exist across different scientific fields. For instance, in chemistry and materials science, generating synthetic molecular structures that respect physical and chemical constraints requires specialized knowledge and algorithms that are still evolving. Similarly, in biological applications, capturing the intricate interdependencies between biological systems remains difficult.
Regulatory and ethical considerations further complicate synthetic data implementation. Questions regarding intellectual property rights for synthetically generated data, potential biases inherited from training data, and compliance with data protection regulations create uncertainty in governance frameworks.
Integration challenges with existing laboratory automation systems and experimental workflows hinder seamless adoption. Many current synthetic data generation tools operate as standalone solutions rather than integrated components of automated closed-loop laboratory ecosystems, limiting their practical utility in real-time decision-making processes.
In automated closed-loop laboratories, synthetic data serves as a critical component for decision-making processes, enabling rapid experimentation and hypothesis testing without the constraints of physical experimentation. However, the current state of synthetic data generation faces several significant challenges that limit its effectiveness and widespread adoption.
Data quality and fidelity remain primary concerns, as synthetic data often fails to capture the nuanced complexities and edge cases present in real-world data. This limitation is particularly problematic in scientific domains where subtle patterns and anomalies can significantly impact experimental outcomes and decision-making processes. The "reality gap" between synthetic and real data continues to pose challenges for transferability of insights.
Validation methodologies for synthetic data represent another substantial challenge. Current approaches lack standardized metrics and frameworks to evaluate how well synthetic data preserves the statistical properties and relationships of the original data while maintaining utility for downstream tasks in automated laboratories. This deficiency creates uncertainty about the reliability of decisions based on synthetic data.
Computational resource requirements present practical limitations, especially for generating high-dimensional, complex datasets needed in scientific experimentation. The most advanced generative models demand significant processing power and specialized hardware, creating barriers to implementation for many research institutions and smaller organizations.
Domain-specific challenges exist across different scientific fields. For instance, in chemistry and materials science, generating synthetic molecular structures that respect physical and chemical constraints requires specialized knowledge and algorithms that are still evolving. Similarly, in biological applications, capturing the intricate interdependencies between biological systems remains difficult.
Regulatory and ethical considerations further complicate synthetic data implementation. Questions regarding intellectual property rights for synthetically generated data, potential biases inherited from training data, and compliance with data protection regulations create uncertainty in governance frameworks.
Integration challenges with existing laboratory automation systems and experimental workflows hinder seamless adoption. Many current synthetic data generation tools operate as standalone solutions rather than integrated components of automated closed-loop laboratory ecosystems, limiting their practical utility in real-time decision-making processes.
Current Synthetic Data Implementation Methodologies
01 AI-driven experimental design and optimization
Automated closed-loop laboratory systems utilize artificial intelligence algorithms to design, execute, and optimize experiments without human intervention. These systems can analyze experimental results in real-time, make decisions about subsequent experiments, and continuously refine experimental parameters to achieve desired outcomes more efficiently. The AI components can identify patterns in complex data sets and suggest novel experimental approaches that might not be obvious to human researchers.- AI-driven experimental design and optimization: Automated closed-loop laboratory systems utilize artificial intelligence algorithms to design, execute, and optimize experiments without human intervention. These systems can analyze experimental results in real-time, make data-driven decisions about subsequent experiments, and continuously refine experimental parameters to achieve desired outcomes more efficiently. The AI components can identify patterns in complex datasets, predict experimental outcomes, and suggest optimal experimental conditions, significantly reducing the time and resources required for scientific discovery.
- Integrated laboratory automation systems: Comprehensive laboratory automation systems integrate various laboratory instruments, robotics, and software platforms to create a seamless closed-loop decision-making environment. These systems coordinate multiple laboratory processes, from sample preparation to analysis and data interpretation, enabling fully automated experimental workflows. The integration allows for real-time data exchange between different components, facilitating immediate decision-making based on experimental outcomes and ensuring consistent execution of complex protocols.
- Machine learning for predictive modeling in laboratory environments: Machine learning algorithms are employed in automated laboratories to develop predictive models based on historical experimental data. These models can forecast experimental outcomes, identify potential failure points, and suggest optimal parameters for future experiments. By continuously learning from new experimental results, the models improve over time, enhancing the efficiency and effectiveness of the decision-making process. This approach enables laboratories to make more informed decisions about resource allocation and experimental priorities.
- Real-time data analysis and feedback systems: Automated closed-loop laboratories implement real-time data analysis capabilities that process experimental results as they are generated. These systems can immediately evaluate data quality, identify anomalies, and make on-the-fly adjustments to experimental parameters. The feedback mechanisms enable dynamic optimization of experiments, reducing waste and accelerating the discovery process. Advanced analytics tools can extract meaningful insights from complex datasets, supporting more sophisticated decision-making processes.
- Cloud-based collaborative laboratory decision platforms: Cloud-based platforms enable distributed teams to collaborate on laboratory experiments and decision-making processes. These systems provide secure access to experimental data, analysis tools, and decision support systems from multiple locations. The platforms facilitate knowledge sharing, enable remote monitoring of experiments, and support collaborative decision-making across organizational boundaries. By leveraging cloud computing resources, these systems can handle large-scale data processing and complex simulations to inform laboratory decisions.
02 Integration of machine learning for predictive analytics
Machine learning models are incorporated into closed-loop laboratory systems to predict experimental outcomes, identify optimal reaction conditions, and forecast potential failures. These predictive capabilities enable the system to make informed decisions about which experiments to prioritize and how to adjust parameters for maximum efficiency. The models continuously learn from new experimental data, improving their predictive accuracy over time and enhancing the overall decision-making process in automated laboratories.Expand Specific Solutions03 Automated workflow management and resource allocation
Closed-loop laboratory systems implement sophisticated workflow management algorithms that coordinate multiple instruments, schedule experiments, and allocate resources optimally. These systems can automatically prioritize tasks based on urgency, equipment availability, and expected value of information. The workflow management component ensures efficient use of laboratory resources, reduces downtime, and maximizes throughput while maintaining experimental quality and integrity.Expand Specific Solutions04 Real-time data analysis and decision feedback loops
Automated laboratory systems incorporate real-time data analysis capabilities that process experimental results as they are generated and immediately feed insights back into the decision-making process. This continuous feedback loop allows the system to rapidly adapt experimental strategies based on emerging data patterns. The real-time analysis component can detect anomalies, identify promising research directions, and automatically trigger follow-up experiments without waiting for human review, significantly accelerating the research process.Expand Specific Solutions05 Multi-objective optimization for complex experimental spaces
Advanced closed-loop laboratory systems employ multi-objective optimization algorithms to navigate complex experimental spaces with competing objectives. These systems can balance multiple factors such as yield, purity, cost, time, and sustainability when making decisions about experimental design. The optimization component enables researchers to explore trade-offs between different objectives and identify Pareto-optimal solutions that represent the best possible compromises for specific research goals.Expand Specific Solutions
Key Industry Players in Automated Laboratory Solutions
Automated Closed-Loop Labs with synthetic data for decision-making are in an early growth phase, with the market expanding rapidly due to increasing demand for data-driven decision processes. The technology is maturing but still evolving, with key players demonstrating varying levels of advancement. IBM, Microsoft, and Accenture lead in enterprise AI integration, while specialized players like Intrinsic Innovation and Serenus AI focus on niche applications. Academic institutions (MIT, Zhejiang University) contribute fundamental research, while tech giants (Oracle, Huawei, Adobe) develop complementary platforms. Financial and healthcare sectors (Wells Fargo, Cleveland Clinic) are early adopters, indicating cross-industry potential as the technology progresses toward standardization.
International Business Machines Corp.
Technical Solution: IBM has developed an advanced closed-loop laboratory system called "RoboRXN" that integrates synthetic data generation with automated chemical synthesis and testing. Their platform combines cloud computing, AI, and robotics to create a fully autonomous research environment for chemical discovery. RoboRXN generates synthetic reaction data through sophisticated chemical simulation models and retrosynthesis algorithms that predict reaction outcomes and pathways[1]. These synthetic predictions guide the selection of promising reactions for physical testing, with results automatically fed back into the system to refine future predictions. The platform employs natural language processing to interpret chemical literature and extract reaction knowledge, which is then incorporated into the synthetic data generation process to improve prediction accuracy[3]. Their decision-making framework utilizes reinforcement learning techniques that optimize for both scientific discovery and resource efficiency, allowing researchers to explore chemical space more effectively than traditional methods. The system includes a distributed architecture that enables multiple physical laboratories to contribute to and benefit from a shared knowledge base, creating a network effect that accelerates learning across the entire platform[5]. IBM's approach particularly excels at handling uncertainty in chemical predictions, using ensemble methods to generate confidence intervals for synthetic data predictions.
Strengths: Enterprise-grade scalability and integration capabilities allow deployment across multiple research sites; sophisticated NLP components enable automatic incorporation of published literature into synthetic data models. Weaknesses: Significant infrastructure requirements limit accessibility to large organizations; system optimization focuses primarily on chemical synthesis applications with less flexibility for other domains.
Intrinsic Innovation LLC
Technical Solution: Intrinsic Innovation has developed an advanced closed-loop laboratory system that integrates synthetic data generation with real-time decision making processes. Their platform utilizes generative adversarial networks (GANs) to create high-fidelity synthetic datasets that closely mimic real-world experimental outcomes. This synthetic data is then fed into their proprietary machine learning algorithms that continuously refine experimental parameters based on both real and synthetic results. The system employs a novel reinforcement learning framework that optimizes experimental design by predicting outcomes across thousands of potential parameter combinations without requiring physical testing for each scenario[1]. Their automated lab infrastructure includes robotic systems capable of executing experiments with minimal human intervention, while their decision-making engine uses Bayesian optimization techniques to determine the most informative experiments to run next, significantly reducing the total number of physical experiments needed to reach conclusive results[3].
Strengths: Superior synthetic data quality through advanced GANs allows for more accurate predictions and decision making; integrated robotics platform enables true closed-loop automation with minimal human oversight. Weaknesses: High computational requirements for synthetic data generation; system requires extensive initial calibration with real experimental data before synthetic data becomes reliable enough for critical decision making.
Core Technologies for Data-Driven Decision Making
Chemical synthesis optimiser
PatentWO2025078643A1
Innovation
- A method and chemical synthesiser that utilize reaction data for process state monitoring, allowing for dynamic procedure execution, self-correction, and real-time decision making during chemical synthesis. This closed-loop system adjusts reaction parameters based on predictions derived from previous test syntheses, optimizing chemical synthesis protocols.
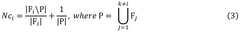
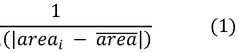
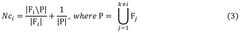
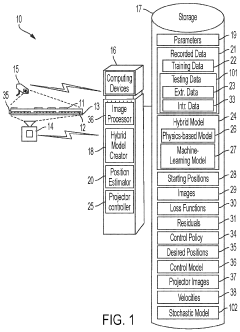
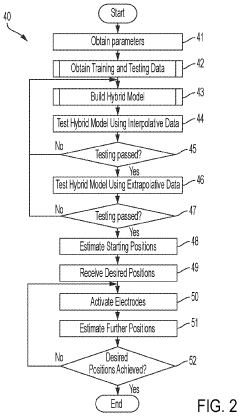
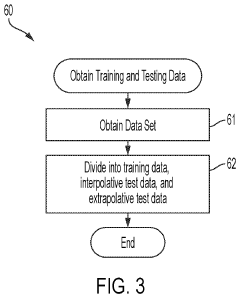
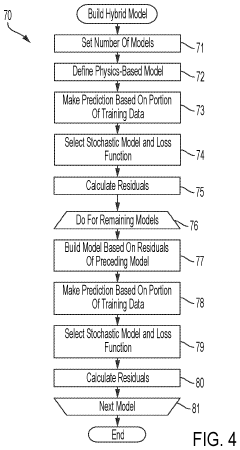
System and method for hybrid-model-based micro-assembly control with the aid of a digital computer
PatentPendingUS20240036534A1
Innovation
- A hybrid model combining physics-based and machine-learning models using gradient boosting is employed to predict the position of micro-objects, accounting for both deterministic and stochastic components, thereby improving accuracy and throughput by incorporating residual calculations and loss function selection.
Data Privacy and Security Considerations
In the realm of Automated Closed-Loop Labs, synthetic data plays a pivotal role in decision-making processes, yet this integration raises significant data privacy and security considerations. The utilization of synthetic data, while beneficial for training algorithms without exposing sensitive information, necessitates robust security frameworks to prevent potential breaches and unauthorized access.
Privacy concerns emerge prominently when real-world data is used to generate synthetic datasets. Even though synthetic data does not directly contain identifiable information, sophisticated re-identification attacks could potentially extract patterns that link back to original data sources. This risk is particularly acute in closed-loop laboratory environments where continuous data collection and processing occur automatically without human oversight.
Regulatory compliance presents another critical dimension, with frameworks like GDPR in Europe, HIPAA in healthcare, and CCPA in California imposing strict requirements on data handling. Automated labs must implement privacy-by-design principles, ensuring that synthetic data generation processes comply with these regulations while maintaining utility for decision-making algorithms.
Data anonymization techniques serve as essential safeguards in this context. Methods such as differential privacy, k-anonymity, and federated learning can be implemented to ensure that synthetic data retains analytical value while protecting individual privacy. However, these techniques often involve trade-offs between privacy protection and data utility that must be carefully balanced.
Security vulnerabilities in automated lab infrastructures present additional challenges. The interconnected nature of IoT devices, sensors, and computational systems creates multiple potential entry points for malicious actors. Implementing end-to-end encryption, secure API gateways, and regular security audits becomes imperative to protect both the synthetic data and the algorithms that leverage it for decision-making.
Ethical considerations surrounding informed consent also warrant attention. When original data is collected from human subjects or proprietary sources, clear policies must establish whether consent extends to synthetic data generation. Transparency in communicating how synthetic data will be used for automated decision-making builds trust with stakeholders and ensures ethical compliance.
Long-term data governance strategies must address the lifecycle management of synthetic datasets. This includes establishing clear protocols for data retention, access controls, and eventual disposal. As automated closed-loop labs evolve, these governance frameworks must adapt to emerging threats and changing regulatory landscapes while maintaining operational efficiency.
Privacy concerns emerge prominently when real-world data is used to generate synthetic datasets. Even though synthetic data does not directly contain identifiable information, sophisticated re-identification attacks could potentially extract patterns that link back to original data sources. This risk is particularly acute in closed-loop laboratory environments where continuous data collection and processing occur automatically without human oversight.
Regulatory compliance presents another critical dimension, with frameworks like GDPR in Europe, HIPAA in healthcare, and CCPA in California imposing strict requirements on data handling. Automated labs must implement privacy-by-design principles, ensuring that synthetic data generation processes comply with these regulations while maintaining utility for decision-making algorithms.
Data anonymization techniques serve as essential safeguards in this context. Methods such as differential privacy, k-anonymity, and federated learning can be implemented to ensure that synthetic data retains analytical value while protecting individual privacy. However, these techniques often involve trade-offs between privacy protection and data utility that must be carefully balanced.
Security vulnerabilities in automated lab infrastructures present additional challenges. The interconnected nature of IoT devices, sensors, and computational systems creates multiple potential entry points for malicious actors. Implementing end-to-end encryption, secure API gateways, and regular security audits becomes imperative to protect both the synthetic data and the algorithms that leverage it for decision-making.
Ethical considerations surrounding informed consent also warrant attention. When original data is collected from human subjects or proprietary sources, clear policies must establish whether consent extends to synthetic data generation. Transparency in communicating how synthetic data will be used for automated decision-making builds trust with stakeholders and ensures ethical compliance.
Long-term data governance strategies must address the lifecycle management of synthetic datasets. This includes establishing clear protocols for data retention, access controls, and eventual disposal. As automated closed-loop labs evolve, these governance frameworks must adapt to emerging threats and changing regulatory landscapes while maintaining operational efficiency.
Validation Frameworks for Synthetic Data Reliability
The reliability of synthetic data in automated closed-loop laboratories necessitates robust validation frameworks to ensure decision-making integrity. These frameworks must systematically evaluate whether synthetic datasets accurately represent real-world phenomena and can reliably inform experimental decisions. Current validation approaches typically incorporate multi-dimensional assessment methodologies that examine statistical fidelity, predictive accuracy, and domain-specific relevance.
Statistical validation techniques form the foundation of these frameworks, employing distribution comparisons, correlation analyses, and variance assessments between synthetic and real datasets. Advanced methods utilize Kullback-Leibler divergence and Wasserstein distance metrics to quantify distributional similarities, providing objective measures of synthetic data quality. These statistical validations must be complemented by task-specific performance evaluations to ensure practical utility.
Cross-validation protocols represent another critical component, where models trained on synthetic data are tested against real-world datasets and vice versa. This bidirectional validation helps identify potential gaps or biases in synthetic data generation processes. Increasingly, automated closed-loop labs implement continuous validation pipelines that monitor synthetic data quality throughout the experimental lifecycle, enabling real-time adjustments to data generation parameters.
Domain-specific validation frameworks have emerged as particularly valuable, incorporating expert knowledge and field-specific constraints into the evaluation process. For instance, in pharmaceutical research, synthetic molecular data must satisfy chemical feasibility rules and demonstrate appropriate binding affinities. These specialized frameworks often employ benchmark datasets and standardized test cases to enable consistent evaluation across different synthetic data generation methods.
Uncertainty quantification represents an evolving frontier in synthetic data validation. Modern frameworks increasingly incorporate explicit uncertainty measurements with synthetic data points, allowing decision-making algorithms to appropriately weight information based on confidence levels. This approach has proven especially valuable in high-stakes domains where understanding prediction confidence is crucial for risk management.
Adversarial testing methodologies have also gained prominence, deliberately probing synthetic datasets for weaknesses or blind spots. These approaches attempt to identify scenarios where synthetic data might lead to suboptimal or dangerous decisions, thereby establishing safety boundaries for automated systems. The integration of these diverse validation techniques into cohesive frameworks provides a comprehensive assessment of synthetic data reliability for closed-loop laboratory applications.
Statistical validation techniques form the foundation of these frameworks, employing distribution comparisons, correlation analyses, and variance assessments between synthetic and real datasets. Advanced methods utilize Kullback-Leibler divergence and Wasserstein distance metrics to quantify distributional similarities, providing objective measures of synthetic data quality. These statistical validations must be complemented by task-specific performance evaluations to ensure practical utility.
Cross-validation protocols represent another critical component, where models trained on synthetic data are tested against real-world datasets and vice versa. This bidirectional validation helps identify potential gaps or biases in synthetic data generation processes. Increasingly, automated closed-loop labs implement continuous validation pipelines that monitor synthetic data quality throughout the experimental lifecycle, enabling real-time adjustments to data generation parameters.
Domain-specific validation frameworks have emerged as particularly valuable, incorporating expert knowledge and field-specific constraints into the evaluation process. For instance, in pharmaceutical research, synthetic molecular data must satisfy chemical feasibility rules and demonstrate appropriate binding affinities. These specialized frameworks often employ benchmark datasets and standardized test cases to enable consistent evaluation across different synthetic data generation methods.
Uncertainty quantification represents an evolving frontier in synthetic data validation. Modern frameworks increasingly incorporate explicit uncertainty measurements with synthetic data points, allowing decision-making algorithms to appropriately weight information based on confidence levels. This approach has proven especially valuable in high-stakes domains where understanding prediction confidence is crucial for risk management.
Adversarial testing methodologies have also gained prominence, deliberately probing synthetic datasets for weaknesses or blind spots. These approaches attempt to identify scenarios where synthetic data might lead to suboptimal or dangerous decisions, thereby establishing safety boundaries for automated systems. The integration of these diverse validation techniques into cohesive frameworks provides a comprehensive assessment of synthetic data reliability for closed-loop laboratory applications.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!