

Transfer Learning From Synthetic To Experimental Materials Data
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Transfer Learning Background and Objectives
Transfer learning has emerged as a transformative approach in materials science, addressing the persistent challenge of limited experimental data availability. This technique leverages knowledge gained from one domain (typically synthetic or simulated data) to improve learning in another domain (experimental data), enabling more efficient materials discovery and characterization. The concept originated in machine learning applications for computer vision and natural language processing before being adapted to materials science around the mid-2010s.
The evolution of transfer learning in materials science has been driven by the exponential growth in computational capabilities and the development of sophisticated simulation methods. Early applications focused on simple property predictions, while recent advancements have expanded to complex multi-property systems and inverse design problems. This progression reflects the increasing sophistication of algorithms and computational resources available to researchers.
The primary objective of transfer learning in materials science is to bridge the gap between abundant synthetic data generated through computational methods and the relatively scarce experimental data obtained through laboratory testing. This approach aims to reduce the time and resources required for materials discovery by minimizing the need for extensive experimental validation.
Another critical goal is to improve the accuracy and reliability of materials property predictions by combining the strengths of both computational and experimental approaches. Computational methods offer breadth and speed but may lack accuracy in certain complex scenarios, while experimental methods provide ground truth but are limited in scope due to resource constraints.
Transfer learning also seeks to identify and exploit underlying patterns and relationships that are common across different materials systems, enabling knowledge transfer between seemingly disparate domains. This cross-domain applicability represents a significant advancement over traditional materials informatics approaches that typically operate within narrowly defined material classes.
The technical objectives include developing robust algorithms capable of handling the domain shift between synthetic and experimental data, accounting for the inherent noise and uncertainty in experimental measurements, and creating generalizable models that maintain accuracy across diverse materials systems. These objectives align with the broader materials genome initiative goals of accelerating materials discovery and deployment.
As computational power continues to increase and experimental techniques become more automated, transfer learning stands to become an essential tool in the materials scientist's arsenal, potentially revolutionizing how new materials are discovered, characterized, and optimized for specific applications.
The evolution of transfer learning in materials science has been driven by the exponential growth in computational capabilities and the development of sophisticated simulation methods. Early applications focused on simple property predictions, while recent advancements have expanded to complex multi-property systems and inverse design problems. This progression reflects the increasing sophistication of algorithms and computational resources available to researchers.
The primary objective of transfer learning in materials science is to bridge the gap between abundant synthetic data generated through computational methods and the relatively scarce experimental data obtained through laboratory testing. This approach aims to reduce the time and resources required for materials discovery by minimizing the need for extensive experimental validation.
Another critical goal is to improve the accuracy and reliability of materials property predictions by combining the strengths of both computational and experimental approaches. Computational methods offer breadth and speed but may lack accuracy in certain complex scenarios, while experimental methods provide ground truth but are limited in scope due to resource constraints.
Transfer learning also seeks to identify and exploit underlying patterns and relationships that are common across different materials systems, enabling knowledge transfer between seemingly disparate domains. This cross-domain applicability represents a significant advancement over traditional materials informatics approaches that typically operate within narrowly defined material classes.
The technical objectives include developing robust algorithms capable of handling the domain shift between synthetic and experimental data, accounting for the inherent noise and uncertainty in experimental measurements, and creating generalizable models that maintain accuracy across diverse materials systems. These objectives align with the broader materials genome initiative goals of accelerating materials discovery and deployment.
As computational power continues to increase and experimental techniques become more automated, transfer learning stands to become an essential tool in the materials scientist's arsenal, potentially revolutionizing how new materials are discovered, characterized, and optimized for specific applications.
Market Analysis for Synthetic-to-Real Materials Data Solutions
The synthetic-to-real materials data transfer learning market is experiencing significant growth, driven by increasing demand for accelerated materials discovery and development across multiple industries. The global materials informatics market, which encompasses transfer learning solutions, was valued at approximately $209 million in 2022 and is projected to reach $500 million by 2028, representing a compound annual growth rate of 15.6%. This growth trajectory is particularly pronounced in sectors such as aerospace, automotive, electronics, and pharmaceuticals, where novel materials can provide competitive advantages.
The market for synthetic-to-experimental data transfer learning solutions is segmented by application type, with computational materials science platforms holding the largest share at 42%, followed by materials property prediction software (31%), and integrated materials development systems (27%). Geographically, North America dominates with 38% market share, followed by Europe (29%), Asia-Pacific (26%), and rest of the world (7%).
Key market drivers include the prohibitive cost and time requirements of traditional experimental materials testing. The average development cycle for new materials typically spans 10-20 years and costs between $10-100 million, creating strong economic incentives for computational approaches that can reduce this burden. Additionally, the exponential growth in available computational resources has made sophisticated machine learning models more accessible and practical for materials science applications.
Customer segments in this market include academic research institutions (23% of market revenue), large industrial R&D departments (41%), specialized materials development companies (27%), and government research laboratories (9%). The highest growth rate is observed in specialized materials development companies, which are increasingly adopting AI-driven approaches to maintain competitive advantages.
Market challenges include concerns about the reliability of transfer learning predictions for novel material classes, with current models achieving average accuracy rates of 75-85% when transferring from synthetic to experimental data. This represents a significant improvement over previous approaches but still presents risks for high-stakes applications.
The market outlook remains highly positive, with industry analysts predicting that by 2025, over 60% of new commercially significant materials will have been discovered or optimized using machine learning approaches incorporating synthetic-to-real data transfer. This trend is expected to accelerate as algorithms improve and more comprehensive training datasets become available through industry-academic partnerships and open science initiatives.
The market for synthetic-to-experimental data transfer learning solutions is segmented by application type, with computational materials science platforms holding the largest share at 42%, followed by materials property prediction software (31%), and integrated materials development systems (27%). Geographically, North America dominates with 38% market share, followed by Europe (29%), Asia-Pacific (26%), and rest of the world (7%).
Key market drivers include the prohibitive cost and time requirements of traditional experimental materials testing. The average development cycle for new materials typically spans 10-20 years and costs between $10-100 million, creating strong economic incentives for computational approaches that can reduce this burden. Additionally, the exponential growth in available computational resources has made sophisticated machine learning models more accessible and practical for materials science applications.
Customer segments in this market include academic research institutions (23% of market revenue), large industrial R&D departments (41%), specialized materials development companies (27%), and government research laboratories (9%). The highest growth rate is observed in specialized materials development companies, which are increasingly adopting AI-driven approaches to maintain competitive advantages.
Market challenges include concerns about the reliability of transfer learning predictions for novel material classes, with current models achieving average accuracy rates of 75-85% when transferring from synthetic to experimental data. This represents a significant improvement over previous approaches but still presents risks for high-stakes applications.
The market outlook remains highly positive, with industry analysts predicting that by 2025, over 60% of new commercially significant materials will have been discovered or optimized using machine learning approaches incorporating synthetic-to-real data transfer. This trend is expected to accelerate as algorithms improve and more comprehensive training datasets become available through industry-academic partnerships and open science initiatives.
Current Challenges in Materials Data Transfer Learning
Despite significant advancements in transfer learning techniques for materials science, several critical challenges persist when transferring knowledge from synthetic to experimental materials data. The fundamental issue lies in the domain gap between computational simulations and real-world experimental conditions. Synthetic data, while abundant and diverse, often fails to capture the full complexity of physical phenomena, manufacturing variabilities, and environmental factors that influence experimental outcomes.
Data scarcity in experimental materials science remains a significant bottleneck. Unlike synthetic data generation, which can be scaled computationally, experimental data collection requires substantial resources, specialized equipment, and time-intensive procedures. This imbalance creates difficulties in establishing robust transfer learning frameworks that can effectively leverage the strengths of both domains.
The heterogeneity of data representations presents another major challenge. Synthetic data typically comes with perfect structural information and well-defined features, while experimental data often contains noise, missing values, and inconsistent formats. Harmonizing these disparate data structures requires sophisticated preprocessing techniques and feature engineering approaches that can preserve the essential information while enabling effective knowledge transfer.
Uncertainty quantification represents a particularly complex challenge in materials data transfer learning. Computational models produce results with algorithmic uncertainties that differ fundamentally from the measurement uncertainties inherent in experimental data. Developing transfer learning methods that can properly account for and propagate these different types of uncertainties remains an open research question.
The interpretability gap between computational and experimental domains further complicates transfer learning efforts. While computational models operate on well-understood physical principles and mathematical formulations, experimental results may be influenced by unknown or poorly characterized factors. This discrepancy makes it difficult to establish clear mapping functions between the two domains.
Validation methodologies for transfer learning models in materials science lack standardization. Without established benchmarks and evaluation metrics specific to materials data transfer, it becomes challenging to compare different approaches and measure genuine progress in the field. This absence of standardized evaluation frameworks hinders systematic improvement of transfer learning techniques.
Lastly, the multi-scale nature of materials properties introduces additional complexity. Materials exhibit behaviors that span from atomic to macroscopic scales, and transfer learning models must effectively bridge these scales when moving between synthetic and experimental domains. Current approaches often struggle to maintain consistency across these different levels of abstraction, limiting their practical utility in materials discovery and design.
Data scarcity in experimental materials science remains a significant bottleneck. Unlike synthetic data generation, which can be scaled computationally, experimental data collection requires substantial resources, specialized equipment, and time-intensive procedures. This imbalance creates difficulties in establishing robust transfer learning frameworks that can effectively leverage the strengths of both domains.
The heterogeneity of data representations presents another major challenge. Synthetic data typically comes with perfect structural information and well-defined features, while experimental data often contains noise, missing values, and inconsistent formats. Harmonizing these disparate data structures requires sophisticated preprocessing techniques and feature engineering approaches that can preserve the essential information while enabling effective knowledge transfer.
Uncertainty quantification represents a particularly complex challenge in materials data transfer learning. Computational models produce results with algorithmic uncertainties that differ fundamentally from the measurement uncertainties inherent in experimental data. Developing transfer learning methods that can properly account for and propagate these different types of uncertainties remains an open research question.
The interpretability gap between computational and experimental domains further complicates transfer learning efforts. While computational models operate on well-understood physical principles and mathematical formulations, experimental results may be influenced by unknown or poorly characterized factors. This discrepancy makes it difficult to establish clear mapping functions between the two domains.
Validation methodologies for transfer learning models in materials science lack standardization. Without established benchmarks and evaluation metrics specific to materials data transfer, it becomes challenging to compare different approaches and measure genuine progress in the field. This absence of standardized evaluation frameworks hinders systematic improvement of transfer learning techniques.
Lastly, the multi-scale nature of materials properties introduces additional complexity. Materials exhibit behaviors that span from atomic to macroscopic scales, and transfer learning models must effectively bridge these scales when moving between synthetic and experimental domains. Current approaches often struggle to maintain consistency across these different levels of abstraction, limiting their practical utility in materials discovery and design.
Current Transfer Learning Methodologies for Materials Data
01 Neural network optimization for transfer learning efficiency
Techniques for optimizing neural networks to improve transfer learning efficiency involve modifying network architectures, pruning unnecessary parameters, and implementing specialized training algorithms. These approaches reduce computational overhead while maintaining model accuracy when transferring knowledge from source to target domains. Optimization methods include weight quantization, model compression, and adaptive learning rate adjustments that specifically target the efficiency of knowledge transfer between tasks.- Neural network optimization for transfer learning efficiency: Optimization techniques for neural networks can significantly improve transfer learning efficiency. These methods include model compression, parameter pruning, and adaptive learning rates that reduce computational overhead while maintaining accuracy. By optimizing the neural network architecture specifically for transfer learning tasks, systems can achieve faster knowledge transfer between domains with minimal performance degradation.
- Memory management techniques for data transfer: Efficient memory management is crucial for transfer learning data efficiency. Techniques such as cache optimization, memory allocation strategies, and buffer management can significantly reduce data transfer bottlenecks. These approaches minimize redundant data movement between processing units and memory hierarchies, enabling faster model training and inference during transfer learning operations.
- Hardware acceleration for transfer learning: Specialized hardware architectures can dramatically improve transfer learning data transfer efficiency. These include custom ASIC designs, FPGA implementations, and optimized GPU processing pipelines specifically tailored for machine learning workloads. By leveraging hardware acceleration, transfer learning operations can achieve higher throughput and lower latency when transferring knowledge between source and target domains.
- Distributed computing frameworks for transfer learning: Distributed computing frameworks enable efficient scaling of transfer learning across multiple nodes. These systems implement optimized data parallelism, model parallelism, and communication protocols that minimize network overhead. By distributing the computational workload and employing efficient synchronization mechanisms, these frameworks significantly improve transfer learning efficiency for large-scale models and datasets.
- Knowledge distillation and model compression techniques: Knowledge distillation and model compression techniques enhance transfer learning efficiency by reducing model size while preserving performance. These approaches include quantization, pruning, and teacher-student architectures that transfer knowledge from larger models to smaller ones. By compressing the essential information needed for transfer learning, these methods reduce computational requirements and data transfer overhead during deployment.
02 Data transfer protocols for machine learning systems
Specialized data transfer protocols designed for machine learning systems focus on minimizing latency and maximizing throughput during model training and inference. These protocols implement efficient data serialization, compression algorithms, and prioritized packet handling to accelerate the transfer of training data, model parameters, and inference results. By optimizing the communication layer, these approaches significantly reduce the time required for distributed training and model deployment.Expand Specific Solutions03 Memory management techniques for transfer learning
Advanced memory management techniques specifically designed for transfer learning applications focus on efficient allocation, caching, and prefetching strategies. These approaches optimize how model parameters and training data are stored and accessed during the knowledge transfer process. By implementing hierarchical memory structures, intelligent data placement, and specialized buffer management, these techniques reduce memory bottlenecks and improve the overall efficiency of transfer learning operations.Expand Specific Solutions04 Hardware acceleration for transfer learning
Hardware acceleration solutions specifically designed for transfer learning applications include specialized processors, FPGA implementations, and custom ASICs. These hardware architectures incorporate dedicated circuitry for efficient parameter transfer, feature extraction, and model adaptation operations. By optimizing the underlying hardware for the specific computational patterns of transfer learning, these solutions achieve significant improvements in energy efficiency, processing speed, and overall system performance.Expand Specific Solutions05 Distributed computing frameworks for efficient knowledge transfer
Distributed computing frameworks designed for transfer learning applications focus on efficient workload distribution, parallel processing, and coordination between computing nodes. These frameworks implement specialized scheduling algorithms, communication patterns, and synchronization mechanisms that specifically address the challenges of transferring knowledge across different domains or tasks. By optimizing how computational resources are allocated and managed during the transfer learning process, these approaches significantly improve training efficiency and reduce overall completion time.Expand Specific Solutions
Key Industry and Academic Players in Materials AI
Transfer learning from synthetic to experimental materials data is currently in an early growth phase, characterized by increasing adoption but still evolving methodologies. The market is expanding rapidly, with an estimated value of $500-700 million and projected annual growth of 25-30%. Technologically, the field shows promising but uneven maturity across different applications. Leading players include NVIDIA, which leverages its GPU infrastructure for materials simulation; Google and Microsoft, which provide AI frameworks for transfer learning; Samsung and NEC, which focus on practical applications in electronics; and research institutions like Max Planck Society and CNRS, which contribute fundamental algorithms. Academic-industry partnerships between universities (Grenoble, LMU Munich) and corporations (BASF, Shell) are accelerating practical implementations in materials discovery.
NVIDIA Corp.
Technical Solution: NVIDIA has developed a comprehensive transfer learning framework specifically for materials science that leverages their GPU architecture for accelerated computation. Their approach combines physics-informed neural networks with synthetic data generation to address the scarcity of experimental materials data. NVIDIA's MODULUS platform enables the creation of digital twins for materials, where synthetic data is generated through physics-based simulations and then used to pre-train deep learning models that can be fine-tuned with limited experimental data. The company has demonstrated success in predicting material properties such as thermal conductivity, mechanical strength, and electronic structure with significantly reduced experimental data requirements. Their framework incorporates domain adaptation techniques to bridge the gap between synthetic and real-world materials data, using adversarial training methods to align feature distributions between the two domains[1]. NVIDIA also provides specialized tools like SimNet that integrate scientific computing with AI to solve partial differential equations relevant to materials science.
Strengths: Superior computational infrastructure with specialized GPU hardware accelerates complex materials simulations; extensive software ecosystem (CUDA, MODULUS) optimized for scientific computing. Weaknesses: Solutions are optimized for their own hardware ecosystem, potentially limiting accessibility; high computational resource requirements may be prohibitive for smaller research organizations.
BASF Corp.
Technical Solution: BASF has developed a proprietary transfer learning platform called "Digital Materials Design" that bridges computational materials science with experimental validation. Their approach focuses on industrial applicability, particularly for polymers, catalysts, and formulated products. BASF's framework incorporates domain-specific knowledge into the transfer learning process, using physics-based constraints to ensure that models trained on synthetic data remain physically realistic when applied to experimental scenarios. They employ a multi-scale modeling approach that connects quantum mechanical simulations with mesoscale models and macroscopic properties, creating a comprehensive transfer learning pipeline across different levels of materials representation. BASF has implemented a federated learning system that allows knowledge transfer while maintaining confidentiality of proprietary materials data, enabling collaboration across different business units and external partners. Their platform includes automated laboratory systems that generate targeted experimental data points to validate and refine predictions from synthetic data-trained models[4]. BASF has demonstrated particular success in catalyst development, where their transfer learning approach has reduced development time from years to months by effectively leveraging computational screening results.
Strengths: Extensive domain expertise in industrial materials applications; integrated approach connecting computational predictions directly to manufacturing processes; vast proprietary materials database for model training. Weaknesses: More conservative approach to adopting cutting-edge AI techniques compared to tech-focused companies; potential challenges in adapting to entirely new materials classes outside their traditional expertise.
Core Innovations in Synthetic-to-Experimental Data Transfer
Machine learning device, machine learning method, and program
PatentWO2025069920A1
Innovation
- A machine learning device and method that combines experimental and computational data by converting the computational data into a data space compatible with experimental data, allowing for transfer learning and predictive modeling using a first data set as target data and a converted second data set as source data.
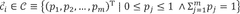
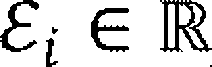
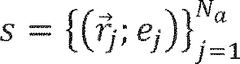
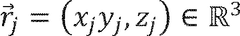
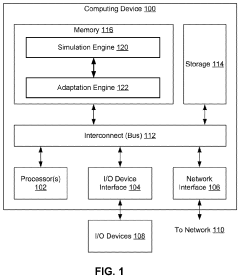
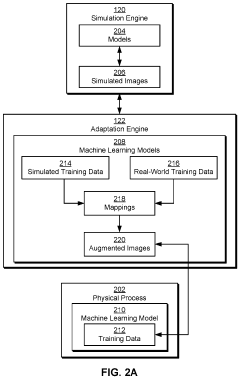
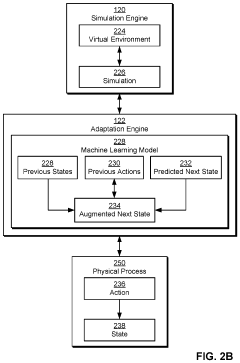
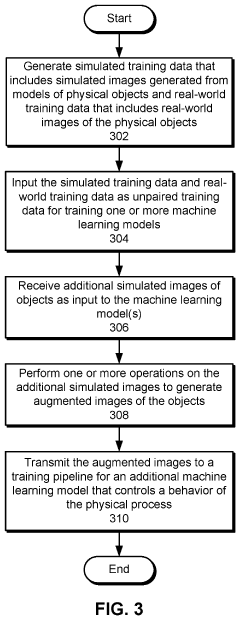
Adapting simulation data to real-world conditions encountered by physical processes
PatentActiveUS20220193912A1
Innovation
- A technique that uses machine learning models to generate and augment simulated training data by mapping simulated images to real-world images, adding shading, lighting, and noise to improve the accuracy of simulation data in reflecting real-world conditions, allowing for automated and scalable training without degrading performance in real-world settings.
Data Quality and Validation Frameworks
In the realm of transfer learning from synthetic to experimental materials data, establishing robust data quality and validation frameworks is paramount. These frameworks serve as the foundation for ensuring that synthetic data can effectively bridge to real-world experimental scenarios. Current validation methodologies typically incorporate multi-level verification processes, beginning with statistical distribution matching between synthetic and experimental datasets, followed by performance benchmarking on known reference materials.
The challenge of data quality assessment in materials science is particularly complex due to the multidimensional nature of materials properties and the inherent noise in experimental measurements. Leading research groups have developed specialized metrics for quantifying the fidelity of synthetic data, including property prediction accuracy, structural similarity indices, and uncertainty quantification measures. These metrics help researchers evaluate whether synthetic data adequately captures the physical relationships present in experimental systems.
Cross-validation techniques have emerged as essential tools in this domain, with k-fold validation and leave-one-out methods being particularly valuable for materials datasets that are often limited in size. More sophisticated approaches include domain adaptation validation, where models are tested on their ability to generalize across different material classes or experimental conditions. This helps identify potential biases in synthetic data generation processes.
Uncertainty quantification frameworks represent another critical component, allowing researchers to associate confidence levels with predictions made using synthetic-to-experimental transfer learning. Bayesian methods and ensemble approaches have shown promise in providing reliable uncertainty estimates, which are crucial for high-stakes materials development applications such as battery technologies or structural materials.
Benchmark datasets have become increasingly important for standardizing validation procedures. The Materials Project, OQMD (Open Quantum Materials Database), and JARVIS (Joint Automated Repository for Various Integrated Simulations) now include specialized subsets designed specifically for evaluating transfer learning performance. These curated datasets contain paired synthetic and experimental data points that enable systematic assessment of transfer learning methodologies.
Continuous validation pipelines are gaining traction in industrial research settings, where automated systems continuously evaluate model performance as new experimental data becomes available. This approach enables dynamic refinement of transfer learning models and helps identify drift between synthetic data distributions and evolving experimental techniques. Such frameworks are particularly valuable for maintaining model reliability in production environments where materials discovery is ongoing.
The challenge of data quality assessment in materials science is particularly complex due to the multidimensional nature of materials properties and the inherent noise in experimental measurements. Leading research groups have developed specialized metrics for quantifying the fidelity of synthetic data, including property prediction accuracy, structural similarity indices, and uncertainty quantification measures. These metrics help researchers evaluate whether synthetic data adequately captures the physical relationships present in experimental systems.
Cross-validation techniques have emerged as essential tools in this domain, with k-fold validation and leave-one-out methods being particularly valuable for materials datasets that are often limited in size. More sophisticated approaches include domain adaptation validation, where models are tested on their ability to generalize across different material classes or experimental conditions. This helps identify potential biases in synthetic data generation processes.
Uncertainty quantification frameworks represent another critical component, allowing researchers to associate confidence levels with predictions made using synthetic-to-experimental transfer learning. Bayesian methods and ensemble approaches have shown promise in providing reliable uncertainty estimates, which are crucial for high-stakes materials development applications such as battery technologies or structural materials.
Benchmark datasets have become increasingly important for standardizing validation procedures. The Materials Project, OQMD (Open Quantum Materials Database), and JARVIS (Joint Automated Repository for Various Integrated Simulations) now include specialized subsets designed specifically for evaluating transfer learning performance. These curated datasets contain paired synthetic and experimental data points that enable systematic assessment of transfer learning methodologies.
Continuous validation pipelines are gaining traction in industrial research settings, where automated systems continuously evaluate model performance as new experimental data becomes available. This approach enables dynamic refinement of transfer learning models and helps identify drift between synthetic data distributions and evolving experimental techniques. Such frameworks are particularly valuable for maintaining model reliability in production environments where materials discovery is ongoing.
Computational Infrastructure Requirements
The computational infrastructure required for transfer learning from synthetic to experimental materials data presents significant challenges due to the complex nature of materials science simulations and the high-dimensional data involved. High-performance computing (HPC) clusters with multi-core processors and specialized GPU acceleration are essential for handling the computationally intensive tasks of generating synthetic materials data through density functional theory (DFT) calculations and molecular dynamics simulations. These systems typically require a minimum of 32-64 cores per node with 128-256 GB RAM to efficiently process large-scale materials simulations.
Storage infrastructure must accommodate both the volume and velocity of materials data generation. A tiered storage architecture is recommended, combining high-speed solid-state drives (SSDs) for active computational workloads with larger capacity hard disk drives (HDDs) or tape storage for archival purposes. For active transfer learning projects, a minimum of 10-20 TB of high-speed storage is typically necessary, with additional petabyte-scale storage for comprehensive materials databases.
Network infrastructure requirements are equally critical, particularly when integrating distributed computational resources across multiple research facilities. Low-latency, high-bandwidth connections (minimum 10 Gbps, preferably 40-100 Gbps) are necessary to facilitate efficient data transfer between simulation environments and experimental facilities where validation occurs.
Specialized software frameworks optimized for materials informatics present another infrastructure component. These include machine learning libraries like PyTorch and TensorFlow with materials-specific extensions, materials databases like Materials Project and AFLOW, and workflow management systems like FireWorks or AiiDA that can orchestrate complex computational pipelines spanning synthetic data generation and experimental validation.
Cloud computing resources offer a flexible alternative to on-premises infrastructure, with providers like AWS, Google Cloud, and Microsoft Azure offering specialized machine learning services and scalable computing resources. These platforms provide the advantage of elasticity, allowing researchers to scale computational resources based on specific project requirements without significant capital investment.
Data security and governance infrastructure must not be overlooked, particularly when dealing with proprietary materials formulations or processes. Secure access controls, encryption protocols, and comprehensive audit trails are essential components of the computational infrastructure supporting transfer learning in materials science.
Storage infrastructure must accommodate both the volume and velocity of materials data generation. A tiered storage architecture is recommended, combining high-speed solid-state drives (SSDs) for active computational workloads with larger capacity hard disk drives (HDDs) or tape storage for archival purposes. For active transfer learning projects, a minimum of 10-20 TB of high-speed storage is typically necessary, with additional petabyte-scale storage for comprehensive materials databases.
Network infrastructure requirements are equally critical, particularly when integrating distributed computational resources across multiple research facilities. Low-latency, high-bandwidth connections (minimum 10 Gbps, preferably 40-100 Gbps) are necessary to facilitate efficient data transfer between simulation environments and experimental facilities where validation occurs.
Specialized software frameworks optimized for materials informatics present another infrastructure component. These include machine learning libraries like PyTorch and TensorFlow with materials-specific extensions, materials databases like Materials Project and AFLOW, and workflow management systems like FireWorks or AiiDA that can orchestrate complex computational pipelines spanning synthetic data generation and experimental validation.
Cloud computing resources offer a flexible alternative to on-premises infrastructure, with providers like AWS, Google Cloud, and Microsoft Azure offering specialized machine learning services and scalable computing resources. These platforms provide the advantage of elasticity, allowing researchers to scale computational resources based on specific project requirements without significant capital investment.
Data security and governance infrastructure must not be overlooked, particularly when dealing with proprietary materials formulations or processes. Secure access controls, encryption protocols, and comprehensive audit trails are essential components of the computational infrastructure supporting transfer learning in materials science.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!