

Best Practices For Generating Synthetic Data For Materials Machine Learning
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Materials ML Synthetic Data Background and Objectives
The field of materials science has witnessed a significant transformation with the integration of machine learning (ML) techniques over the past decade. This convergence has accelerated materials discovery and optimization processes that traditionally required extensive laboratory experimentation and theoretical modeling. However, the effectiveness of ML models in materials science is heavily dependent on the quality and quantity of available data, which often presents a substantial challenge due to the inherent complexity and diversity of materials systems.
Synthetic data generation has emerged as a promising solution to address the data scarcity problem in materials machine learning. By creating artificial datasets that mimic the statistical properties and physical relationships found in real materials data, researchers can augment limited experimental datasets, balance underrepresented classes, and explore hypothetical materials compositions that have not yet been synthesized in laboratories.
The evolution of synthetic data techniques in materials science has progressed from simple interpolation methods to sophisticated generative models. Early approaches relied on physics-based simulations and first-principles calculations, while recent advancements leverage deep learning architectures such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models to generate realistic materials data across multiple modalities including crystal structures, spectroscopic measurements, and property values.
The primary objective of establishing best practices for synthetic data generation in materials ML is to develop standardized methodologies that ensure the generated data maintains physical realism, preserves structure-property relationships, and effectively captures the underlying physics and chemistry of materials systems. This includes creating protocols for validating synthetic data quality, quantifying uncertainty in generated samples, and assessing the transferability of models trained on synthetic datasets to real-world materials applications.
Additionally, this technical research aims to identify optimal approaches for integrating domain knowledge into data generation processes, balancing the trade-off between data diversity and physical plausibility, and addressing ethical considerations related to potential biases in synthetic data. The ultimate goal is to establish a framework that enables materials scientists and ML practitioners to reliably generate high-quality synthetic data that accelerates materials innovation while maintaining scientific rigor.
As the field continues to evolve, these best practices will need to adapt to incorporate emerging technologies and methodologies, ensuring that synthetic data remains a valuable tool in the materials discovery pipeline and contributes meaningfully to addressing global challenges in energy, healthcare, and sustainability through advanced materials development.
Synthetic data generation has emerged as a promising solution to address the data scarcity problem in materials machine learning. By creating artificial datasets that mimic the statistical properties and physical relationships found in real materials data, researchers can augment limited experimental datasets, balance underrepresented classes, and explore hypothetical materials compositions that have not yet been synthesized in laboratories.
The evolution of synthetic data techniques in materials science has progressed from simple interpolation methods to sophisticated generative models. Early approaches relied on physics-based simulations and first-principles calculations, while recent advancements leverage deep learning architectures such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models to generate realistic materials data across multiple modalities including crystal structures, spectroscopic measurements, and property values.
The primary objective of establishing best practices for synthetic data generation in materials ML is to develop standardized methodologies that ensure the generated data maintains physical realism, preserves structure-property relationships, and effectively captures the underlying physics and chemistry of materials systems. This includes creating protocols for validating synthetic data quality, quantifying uncertainty in generated samples, and assessing the transferability of models trained on synthetic datasets to real-world materials applications.
Additionally, this technical research aims to identify optimal approaches for integrating domain knowledge into data generation processes, balancing the trade-off between data diversity and physical plausibility, and addressing ethical considerations related to potential biases in synthetic data. The ultimate goal is to establish a framework that enables materials scientists and ML practitioners to reliably generate high-quality synthetic data that accelerates materials innovation while maintaining scientific rigor.
As the field continues to evolve, these best practices will need to adapt to incorporate emerging technologies and methodologies, ensuring that synthetic data remains a valuable tool in the materials discovery pipeline and contributes meaningfully to addressing global challenges in energy, healthcare, and sustainability through advanced materials development.
Market Analysis for Synthetic Data in Materials Science
The synthetic data market for materials science is experiencing significant growth, driven by the increasing adoption of machine learning techniques in materials discovery and development. Current market estimates value the global materials informatics market at approximately $500 million, with synthetic data generation tools representing a rapidly growing segment expected to reach $150 million by 2025. This growth trajectory is supported by a compound annual growth rate (CAGR) of 35% in the materials AI sector overall.
Demand for synthetic data solutions in materials science stems primarily from three key market segments. First, academic research institutions account for roughly 40% of current market demand, as they seek cost-effective alternatives to expensive experimental data generation. Second, large industrial materials manufacturers represent 35% of the market, leveraging synthetic data to accelerate product development cycles and reduce R&D costs. Third, specialized AI startups focusing on materials discovery constitute 25% of market demand, using synthetic data to train their proprietary algorithms.
Geographically, North America leads the market with approximately 45% share, driven by substantial investments in materials science research and strong computational infrastructure. Europe follows at 30%, with particular strength in academic-industrial partnerships. The Asia-Pacific region accounts for 20% and is experiencing the fastest growth rate, fueled by China's aggressive investments in advanced materials development and AI capabilities.
Key market drivers include the prohibitive cost of experimental data collection in materials science, with typical material characterization processes costing between $5,000-$50,000 per material. Additionally, the expanding capabilities of machine learning models in materials prediction are creating demand for larger training datasets than can be feasibly generated through traditional experimental methods.
Market challenges include concerns about the fidelity and reliability of synthetic data, regulatory uncertainties regarding intellectual property derived from synthetic data, and integration difficulties with existing materials research workflows. Despite these challenges, the market is expected to continue its robust growth as synthetic data generation techniques mature and demonstrate increasing accuracy in replicating real-world material properties.
Customer segments show varying needs, with academic users prioritizing cost-effectiveness and transparency, industrial users focusing on accuracy and integration with existing systems, and startups valuing scalability and customization options. This market differentiation is driving the development of specialized synthetic data solutions tailored to specific use cases within materials science.
Demand for synthetic data solutions in materials science stems primarily from three key market segments. First, academic research institutions account for roughly 40% of current market demand, as they seek cost-effective alternatives to expensive experimental data generation. Second, large industrial materials manufacturers represent 35% of the market, leveraging synthetic data to accelerate product development cycles and reduce R&D costs. Third, specialized AI startups focusing on materials discovery constitute 25% of market demand, using synthetic data to train their proprietary algorithms.
Geographically, North America leads the market with approximately 45% share, driven by substantial investments in materials science research and strong computational infrastructure. Europe follows at 30%, with particular strength in academic-industrial partnerships. The Asia-Pacific region accounts for 20% and is experiencing the fastest growth rate, fueled by China's aggressive investments in advanced materials development and AI capabilities.
Key market drivers include the prohibitive cost of experimental data collection in materials science, with typical material characterization processes costing between $5,000-$50,000 per material. Additionally, the expanding capabilities of machine learning models in materials prediction are creating demand for larger training datasets than can be feasibly generated through traditional experimental methods.
Market challenges include concerns about the fidelity and reliability of synthetic data, regulatory uncertainties regarding intellectual property derived from synthetic data, and integration difficulties with existing materials research workflows. Despite these challenges, the market is expected to continue its robust growth as synthetic data generation techniques mature and demonstrate increasing accuracy in replicating real-world material properties.
Customer segments show varying needs, with academic users prioritizing cost-effectiveness and transparency, industrial users focusing on accuracy and integration with existing systems, and startups valuing scalability and customization options. This market differentiation is driving the development of specialized synthetic data solutions tailored to specific use cases within materials science.
Current Challenges in Materials ML Synthetic Data Generation
Despite significant advancements in materials machine learning (ML), synthetic data generation faces several critical challenges that impede broader implementation and reliability. The primary obstacle remains the accurate representation of complex material properties and behaviors. Current synthetic data often fails to capture the intricate quantum mechanical interactions and multi-scale phenomena that govern real materials, resulting in models that perform well on synthetic datasets but struggle with real-world applications.
Data quality and validation present another significant hurdle. Unlike other domains where synthetic data generation has matured, materials science lacks standardized metrics to evaluate the fidelity of synthetic data. Researchers struggle to quantify how well synthetic samples represent the distribution of real materials properties, leading to uncertainty about model transferability and generalization capabilities.
The high-dimensional nature of materials representation compounds these challenges. Materials are characterized by numerous parameters including atomic composition, crystal structure, electronic properties, and processing conditions. Generating synthetic data that maintains realistic correlations across these dimensions remains computationally intensive and methodologically complex.
Computational efficiency represents a persistent bottleneck. High-fidelity simulations based on density functional theory (DFT) or molecular dynamics are computationally expensive, limiting the scale of synthetic datasets. While surrogate models offer faster alternatives, they introduce additional approximation errors that propagate through the ML pipeline.
Domain knowledge integration poses another challenge. Current synthetic data generation approaches often operate as black boxes, making it difficult to incorporate established materials science principles. This disconnect between data-driven approaches and domain expertise results in physically implausible synthetic samples that undermine model reliability.
The scarcity of negative examples further complicates synthetic data generation. Materials databases predominantly contain successful materials, creating an inherent bias toward positive outcomes. Generating realistic "failed" materials or properties is challenging but essential for developing robust ML models capable of distinguishing promising candidates from unpromising ones.
Lastly, the reproducibility crisis affects materials ML synthetic data generation. Variations in computational environments, simulation parameters, and random seed initialization lead to inconsistent synthetic datasets across different research groups, hampering collaborative progress and benchmarking efforts. These challenges collectively highlight the need for standardized protocols and innovative approaches to synthetic data generation in materials science.
Data quality and validation present another significant hurdle. Unlike other domains where synthetic data generation has matured, materials science lacks standardized metrics to evaluate the fidelity of synthetic data. Researchers struggle to quantify how well synthetic samples represent the distribution of real materials properties, leading to uncertainty about model transferability and generalization capabilities.
The high-dimensional nature of materials representation compounds these challenges. Materials are characterized by numerous parameters including atomic composition, crystal structure, electronic properties, and processing conditions. Generating synthetic data that maintains realistic correlations across these dimensions remains computationally intensive and methodologically complex.
Computational efficiency represents a persistent bottleneck. High-fidelity simulations based on density functional theory (DFT) or molecular dynamics are computationally expensive, limiting the scale of synthetic datasets. While surrogate models offer faster alternatives, they introduce additional approximation errors that propagate through the ML pipeline.
Domain knowledge integration poses another challenge. Current synthetic data generation approaches often operate as black boxes, making it difficult to incorporate established materials science principles. This disconnect between data-driven approaches and domain expertise results in physically implausible synthetic samples that undermine model reliability.
The scarcity of negative examples further complicates synthetic data generation. Materials databases predominantly contain successful materials, creating an inherent bias toward positive outcomes. Generating realistic "failed" materials or properties is challenging but essential for developing robust ML models capable of distinguishing promising candidates from unpromising ones.
Lastly, the reproducibility crisis affects materials ML synthetic data generation. Variations in computational environments, simulation parameters, and random seed initialization lead to inconsistent synthetic datasets across different research groups, hampering collaborative progress and benchmarking efforts. These challenges collectively highlight the need for standardized protocols and innovative approaches to synthetic data generation in materials science.
Current Synthetic Data Generation Techniques for Materials
01 Quality assessment methods for synthetic data
Various methods are employed to assess the quality of synthetically generated data. These include statistical validation techniques, comparison with real-world datasets, and evaluation of data distribution characteristics. Quality assessment ensures that synthetic data accurately represents the properties and patterns of original data while maintaining privacy and utility. Advanced algorithms can measure the fidelity, diversity, and statistical similarity between synthetic and real datasets.- Quality assessment methods for synthetic data: Various methods are employed to assess the quality of synthetically generated data. These methods include statistical validation techniques, comparison with real-world datasets, and evaluation of data distribution characteristics. Quality assessment ensures that synthetic data accurately represents the properties and patterns of original data while maintaining privacy and utility. Advanced algorithms can measure the fidelity, diversity, and statistical similarity between synthetic and real datasets.
- Machine learning approaches for synthetic data generation: Machine learning models, particularly generative adversarial networks (GANs) and deep learning architectures, are used to create high-quality synthetic data. These approaches learn the underlying distributions of real datasets and generate new data points that maintain statistical properties while preserving privacy. The quality of synthetic data depends on model architecture, training parameters, and the diversity of training data. Advanced techniques include conditional generation and transfer learning to improve synthetic data quality.
- Privacy-preserving synthetic data techniques: Methods for generating synthetic data that maintain privacy while preserving utility are essential for sensitive applications. These techniques include differential privacy integration, federated learning approaches, and anonymization methods that protect individual identities while maintaining data utility. The quality of privacy-preserving synthetic data is measured by both its utility for downstream tasks and its resistance to re-identification attacks or information leakage.
- Domain-specific synthetic data generation: Specialized approaches for generating synthetic data in specific domains such as healthcare, finance, and autonomous driving require tailored quality metrics. These methods incorporate domain knowledge, regulatory requirements, and specific data characteristics to ensure the synthetic data is suitable for specialized applications. Quality assessment in domain-specific contexts often involves expert validation and domain-specific performance metrics to ensure the synthetic data can effectively replace real data in sensitive applications.
- Synthetic data augmentation and enhancement: Techniques for augmenting existing datasets with synthetic data to improve model training and testing. These methods focus on generating high-quality synthetic samples to address data imbalance, rare cases, or edge scenarios. Quality metrics for augmented datasets include diversity measures, class balance assessment, and performance improvements in downstream machine learning tasks. Advanced approaches combine real and synthetic data in optimal proportions to maximize model performance while ensuring data quality.
02 Machine learning approaches for synthetic data generation
Machine learning models, particularly generative adversarial networks (GANs) and deep learning architectures, are used to create high-quality synthetic data. These approaches learn the underlying distribution of real data and generate new samples that preserve statistical properties while ensuring privacy. The quality of synthetic data depends on model architecture, training parameters, and the diversity of training datasets. Advanced techniques incorporate differential privacy to balance utility and confidentiality.Expand Specific Solutions03 Data augmentation techniques for quality improvement
Data augmentation techniques enhance the quality and utility of synthetic data by introducing controlled variations. These methods include feature transformation, noise injection, and domain-specific modifications that increase dataset diversity while maintaining realistic characteristics. Augmentation helps address class imbalance issues and improves the robustness of models trained on synthetic data. The techniques can be tailored to specific domains such as healthcare, finance, or computer vision.Expand Specific Solutions04 Privacy preservation in high-quality synthetic data
Maintaining privacy while generating high-quality synthetic data involves specialized techniques such as differential privacy, federated learning, and anonymization methods. These approaches ensure that sensitive information from original datasets cannot be reverse-engineered from synthetic data. The quality-privacy tradeoff is managed through parameter tuning and privacy budgeting. Advanced frameworks incorporate privacy guarantees while maximizing the utility and representativeness of the generated data.Expand Specific Solutions05 Domain-specific synthetic data quality frameworks
Domain-specific frameworks address unique quality requirements for synthetic data in specialized fields. These frameworks incorporate industry-specific validation metrics, regulatory compliance checks, and domain knowledge to ensure synthetic data meets particular use case requirements. For example, healthcare synthetic data must preserve clinical relationships, while financial synthetic data must maintain temporal patterns and regulatory compliance. These frameworks often include automated validation pipelines and quality scoring systems.Expand Specific Solutions
Leading Organizations in Materials ML and Synthetic Data
The synthetic data generation for materials machine learning is evolving rapidly in a market transitioning from early adoption to growth phase. The field is expanding as materials science increasingly embraces AI-driven discovery, with market size projected to grow significantly due to reduced experimental costs and accelerated materials development. Technologically, the landscape shows varying maturity levels: NVIDIA and Microsoft lead with advanced AI frameworks; academic institutions like University of Science & Technology Beijing and Zhejiang University contribute fundamental research; while industrial players including Boeing, Schlumberger, and IBM implement domain-specific applications. The convergence of materials science expertise with AI capabilities is creating a competitive environment where cross-sector collaboration is becoming essential for innovation in this interdisciplinary field.
University of Science & Technology Beijing
Technical Solution: The University of Science & Technology Beijing has developed innovative approaches for generating synthetic materials data through physics-informed deep learning models. Their research focuses on creating realistic microstructure representations using specialized generative adversarial networks that incorporate materials science domain knowledge. The university's Materials Genome Initiative lab has pioneered techniques for synthetic data augmentation that preserve critical structure-property relationships while expanding limited experimental datasets. Their approach combines traditional materials simulation methods with modern deep learning architectures to generate diverse synthetic datasets that capture the full range of material behaviors. The university has developed specialized validation metrics for synthetic materials data that assess both statistical similarity to real data and physical plausibility of generated samples.
Strengths: Strong foundation in fundamental materials science principles; innovative integration of physics constraints in generative models; extensive experimental validation capabilities. Weaknesses: Potentially limited computational resources compared to industry players; may focus on specific material classes rather than general solutions; possible challenges in scaling approaches to industrial applications.
NVIDIA Corp.
Technical Solution: NVIDIA has developed comprehensive frameworks for materials machine learning that leverage their GPU architecture for accelerated synthetic data generation. Their NVIDIA Modulus platform combines physics-informed neural networks with generative models to create high-fidelity synthetic materials data. The company employs multi-physics simulations that can generate synthetic microstructure images, property distributions, and process-structure-property relationships. Their approach incorporates generative adversarial networks (GANs) specifically optimized for materials science applications, allowing researchers to augment limited experimental datasets with physically consistent synthetic samples. NVIDIA's MaterialGAN architecture enables controlled generation of material microstructures with specific target properties, addressing the common challenge of limited training data in materials informatics.
Strengths: Unparalleled computational efficiency through GPU optimization; seamless integration with existing deep learning frameworks; ability to generate physically consistent data at scale. Weaknesses: High computational resource requirements; potential domain gap between synthetic and real-world materials data; requires significant expertise to properly configure simulation parameters.
Key Algorithms and Models for Materials Synthetic Data
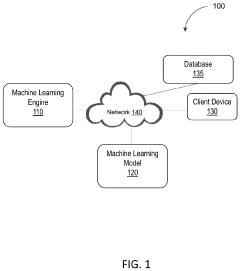
Generating Synthetic Data For Machine Learning Training
PatentPendingUS20250045823A1
Innovation
- The EchoFlux technique generates synthetic peer stocks that move in tandem with the original stock but introduce variability, creating a more robust dataset for training machine learning-based stock price forecasting systems.
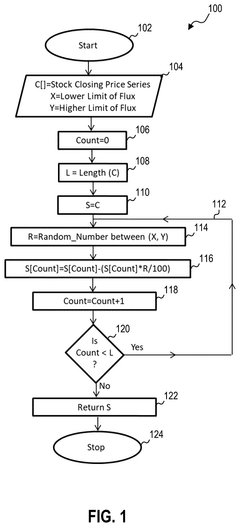
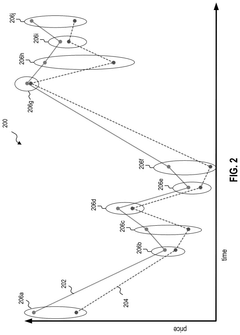
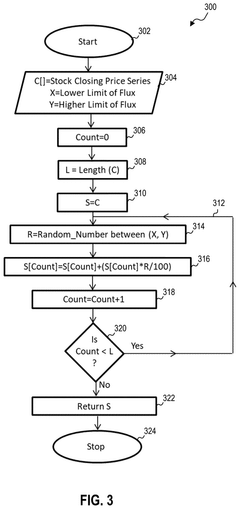
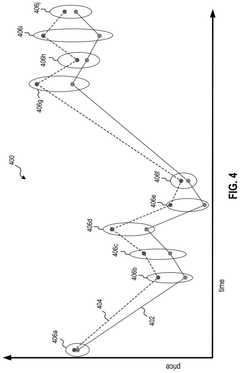
Synthetic data generation for machine learning models
PatentPendingUS20240112045A1
Innovation
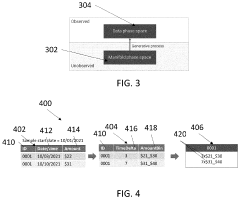
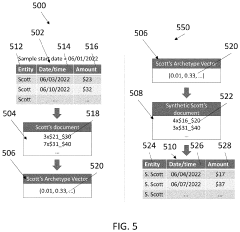
- A system and method for generating synthetic data by determining archetype probability distributions, clustering data points into transactional behavior patterns, removing non-representative data points, and generating updated archetype probability distributions to create representative transaction data, which is used to train machine learning models.
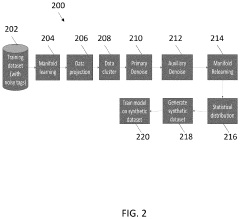
Validation Metrics for Materials Synthetic Data Quality
Validating the quality of synthetic data for materials science applications requires robust metrics that can quantify how well the generated data represents real materials properties and behaviors. The primary validation approaches include statistical distribution matching, which ensures synthetic data maintains the same statistical properties as experimental datasets. This involves comparing probability distributions, means, variances, and higher-order moments between synthetic and real data populations. For materials science specifically, preserving correlations between physical properties (e.g., bandgap-lattice parameter relationships) is critical, as these interdependencies define material behavior.
Physical consistency validation ensures synthetic data adheres to fundamental physical laws and constraints. This includes thermodynamic consistency checks (e.g., energy conservation), structural feasibility assessments (bond lengths, angles), and phase stability evaluations. Machine learning models trained on physically inconsistent data may produce unrealistic predictions, making this validation step essential for maintaining scientific integrity.
Downstream task performance serves as a pragmatic validation approach, where synthetic data quality is assessed by how well models trained on it perform on real-world tasks. This includes evaluating prediction accuracy on held-out experimental data, comparing performance between models trained on synthetic versus real data, and measuring generalization capabilities across different material classes.
Diversity and coverage metrics evaluate how well synthetic data spans the relevant materials design space. Techniques such as principal component analysis can visualize coverage in high-dimensional property spaces, while novelty detection algorithms can identify regions where synthetic data explores beyond existing experimental datasets. Optimal synthetic data should balance between interpolating known regions and extrapolating into unexplored but physically plausible spaces.
Time-series validation becomes particularly important for dynamic materials properties, such as degradation processes or phase transformations. This requires metrics that capture temporal dependencies and transition probabilities between states, ensuring synthetic time-series data maintains realistic evolution patterns observed in experimental studies.
Uncertainty quantification in validation metrics provides confidence levels in synthetic data quality. This involves propagating uncertainties from generative models through to validation metrics, establishing confidence intervals for quality assessments, and identifying regions of the materials space where synthetic data may be less reliable. Transparent reporting of these uncertainties is essential for responsible use of synthetic data in materials discovery pipelines.
Physical consistency validation ensures synthetic data adheres to fundamental physical laws and constraints. This includes thermodynamic consistency checks (e.g., energy conservation), structural feasibility assessments (bond lengths, angles), and phase stability evaluations. Machine learning models trained on physically inconsistent data may produce unrealistic predictions, making this validation step essential for maintaining scientific integrity.
Downstream task performance serves as a pragmatic validation approach, where synthetic data quality is assessed by how well models trained on it perform on real-world tasks. This includes evaluating prediction accuracy on held-out experimental data, comparing performance between models trained on synthetic versus real data, and measuring generalization capabilities across different material classes.
Diversity and coverage metrics evaluate how well synthetic data spans the relevant materials design space. Techniques such as principal component analysis can visualize coverage in high-dimensional property spaces, while novelty detection algorithms can identify regions where synthetic data explores beyond existing experimental datasets. Optimal synthetic data should balance between interpolating known regions and extrapolating into unexplored but physically plausible spaces.
Time-series validation becomes particularly important for dynamic materials properties, such as degradation processes or phase transformations. This requires metrics that capture temporal dependencies and transition probabilities between states, ensuring synthetic time-series data maintains realistic evolution patterns observed in experimental studies.
Uncertainty quantification in validation metrics provides confidence levels in synthetic data quality. This involves propagating uncertainties from generative models through to validation metrics, establishing confidence intervals for quality assessments, and identifying regions of the materials space where synthetic data may be less reliable. Transparent reporting of these uncertainties is essential for responsible use of synthetic data in materials discovery pipelines.
Data Privacy and IP Considerations in Materials Synthetic Data
The generation and utilization of synthetic data in materials science present significant challenges regarding data privacy and intellectual property (IP) protection. As organizations increasingly rely on machine learning models trained with synthetic data, they must navigate complex legal and ethical frameworks that govern data usage and ownership. Materials science datasets often contain proprietary information about composition, processing parameters, and performance metrics that represent substantial investments in research and development.
Privacy concerns in materials synthetic data differ from those in consumer data, focusing less on personal identifiable information and more on protecting competitive advantages and trade secrets. Companies must implement robust data governance frameworks that classify information sensitivity levels and establish clear protocols for synthetic data generation that preserve confidentiality while enabling collaborative research. Technical approaches such as differential privacy can be incorporated into synthetic data generation algorithms to mathematically guarantee that original proprietary data cannot be reverse-engineered from the synthetic datasets.
Intellectual property considerations are particularly nuanced in materials science, where patent protection often covers specific compositions, structures, or manufacturing processes. When generating synthetic data, organizations must carefully evaluate whether the synthetic data might inadvertently disclose patented information or enable competitors to circumvent existing patents. Clear IP policies should address ownership of both the input data used to train generative models and the resulting synthetic datasets.
Contractual agreements play a crucial role in managing these concerns, especially in collaborative research environments. Material Transfer Agreements (MTAs) and Data Use Agreements (DUAs) should explicitly address synthetic data generation rights, including limitations on how synthetic data can be shared, published, or commercialized. These agreements should also specify attribution requirements and potential revenue-sharing mechanisms for innovations derived from synthetic data.
International considerations add another layer of complexity, as data privacy regulations and IP protection standards vary significantly across jurisdictions. Organizations operating globally must develop synthetic data strategies that comply with the most stringent applicable regulations while maintaining scientific utility. This may require implementing region-specific controls or creating different versions of synthetic datasets for use in different jurisdictions.
Emerging best practices include conducting regular privacy impact assessments specifically tailored to materials data, implementing technical safeguards such as watermarking synthetic data to track provenance, and establishing ethics committees to evaluate potential misuse scenarios. Forward-thinking organizations are also exploring blockchain-based solutions to create immutable records of data provenance and usage permissions throughout the synthetic data lifecycle.
Privacy concerns in materials synthetic data differ from those in consumer data, focusing less on personal identifiable information and more on protecting competitive advantages and trade secrets. Companies must implement robust data governance frameworks that classify information sensitivity levels and establish clear protocols for synthetic data generation that preserve confidentiality while enabling collaborative research. Technical approaches such as differential privacy can be incorporated into synthetic data generation algorithms to mathematically guarantee that original proprietary data cannot be reverse-engineered from the synthetic datasets.
Intellectual property considerations are particularly nuanced in materials science, where patent protection often covers specific compositions, structures, or manufacturing processes. When generating synthetic data, organizations must carefully evaluate whether the synthetic data might inadvertently disclose patented information or enable competitors to circumvent existing patents. Clear IP policies should address ownership of both the input data used to train generative models and the resulting synthetic datasets.
Contractual agreements play a crucial role in managing these concerns, especially in collaborative research environments. Material Transfer Agreements (MTAs) and Data Use Agreements (DUAs) should explicitly address synthetic data generation rights, including limitations on how synthetic data can be shared, published, or commercialized. These agreements should also specify attribution requirements and potential revenue-sharing mechanisms for innovations derived from synthetic data.
International considerations add another layer of complexity, as data privacy regulations and IP protection standards vary significantly across jurisdictions. Organizations operating globally must develop synthetic data strategies that comply with the most stringent applicable regulations while maintaining scientific utility. This may require implementing region-specific controls or creating different versions of synthetic datasets for use in different jurisdictions.
Emerging best practices include conducting regular privacy impact assessments specifically tailored to materials data, implementing technical safeguards such as watermarking synthetic data to track provenance, and establishing ethics committees to evaluate potential misuse scenarios. Forward-thinking organizations are also exploring blockchain-based solutions to create immutable records of data provenance and usage permissions throughout the synthetic data lifecycle.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!