

Data Curation Playbook For Building Robust Training Sets
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Data Curation Evolution and Objectives
Data curation has evolved significantly over the past decade, transforming from a simple data collection process to a sophisticated discipline that encompasses quality assessment, bias detection, and comprehensive metadata management. Initially, machine learning practitioners focused primarily on gathering large volumes of data, adhering to the "more data is better" philosophy. However, as models became more complex and applications more critical, the limitations of this approach became evident through performance plateaus, unexpected biases, and generalization failures.
The evolution of data curation can be traced through several distinct phases. The first phase (2010-2015) was characterized by volume-centric approaches, where success was measured by dataset size. The second phase (2015-2018) introduced quality filtering mechanisms as practitioners recognized that noisy data could undermine model performance. The third phase (2018-2020) brought increased attention to representation and bias considerations, with techniques for balanced sampling and fairness evaluations becoming standard practice.
Currently, we are in the fourth phase of data curation evolution (2020-present), marked by systematic approaches that integrate automated and human-in-the-loop methodologies. This phase emphasizes not just what data is collected, but how it is processed, annotated, and maintained throughout its lifecycle. Modern data curation incorporates active learning, uncertainty sampling, and continuous validation techniques to ensure datasets remain relevant and representative.
The primary objective of a Data Curation Playbook is to establish standardized, reproducible processes for building training datasets that lead to robust, reliable, and fair machine learning models. Specific objectives include: developing systematic approaches to identify and mitigate various forms of bias; creating comprehensive documentation standards that enhance dataset transparency and reproducibility; establishing quality assurance protocols that can be consistently applied across different data types and domains.
Additionally, the playbook aims to define metrics for evaluating dataset quality beyond simple volume measurements, incorporating concepts like class balance, feature distribution, and edge case coverage. It seeks to formalize the integration of domain expertise into the curation process, ensuring that technical implementations align with real-world requirements and constraints.
The ultimate goal is to transition data curation from an ad hoc activity to a disciplined practice with clear methodologies, enabling organizations to build training sets that not only improve model performance but also address ethical considerations and regulatory requirements in an increasingly scrutinized AI landscape.
The evolution of data curation can be traced through several distinct phases. The first phase (2010-2015) was characterized by volume-centric approaches, where success was measured by dataset size. The second phase (2015-2018) introduced quality filtering mechanisms as practitioners recognized that noisy data could undermine model performance. The third phase (2018-2020) brought increased attention to representation and bias considerations, with techniques for balanced sampling and fairness evaluations becoming standard practice.
Currently, we are in the fourth phase of data curation evolution (2020-present), marked by systematic approaches that integrate automated and human-in-the-loop methodologies. This phase emphasizes not just what data is collected, but how it is processed, annotated, and maintained throughout its lifecycle. Modern data curation incorporates active learning, uncertainty sampling, and continuous validation techniques to ensure datasets remain relevant and representative.
The primary objective of a Data Curation Playbook is to establish standardized, reproducible processes for building training datasets that lead to robust, reliable, and fair machine learning models. Specific objectives include: developing systematic approaches to identify and mitigate various forms of bias; creating comprehensive documentation standards that enhance dataset transparency and reproducibility; establishing quality assurance protocols that can be consistently applied across different data types and domains.
Additionally, the playbook aims to define metrics for evaluating dataset quality beyond simple volume measurements, incorporating concepts like class balance, feature distribution, and edge case coverage. It seeks to formalize the integration of domain expertise into the curation process, ensuring that technical implementations align with real-world requirements and constraints.
The ultimate goal is to transition data curation from an ad hoc activity to a disciplined practice with clear methodologies, enabling organizations to build training sets that not only improve model performance but also address ethical considerations and regulatory requirements in an increasingly scrutinized AI landscape.
Market Demand for High-Quality Training Datasets
The demand for high-quality training datasets has experienced exponential growth in recent years, driven primarily by the rapid advancement and widespread adoption of machine learning and artificial intelligence technologies. Organizations across various sectors are increasingly recognizing that the performance of their AI models is fundamentally dependent on the quality, diversity, and representativeness of the data used during training phases.
Market research indicates that the global data preparation market, which includes data curation services, reached approximately $2.1 billion in 2022 and is projected to grow at a CAGR of 27.9% through 2028. This growth is particularly pronounced in sectors such as healthcare, finance, autonomous vehicles, and natural language processing, where model accuracy and reliability are critical for operational success and regulatory compliance.
Enterprise surveys reveal that data scientists spend between 50-80% of their time on data preparation activities, highlighting the significant resource allocation dedicated to ensuring training data quality. This investment reflects the understanding that poor quality data leads directly to underperforming models, potentially resulting in costly business decisions or product failures.
The demand is further segmented by specific requirements across industries. Healthcare organizations require meticulously curated datasets that maintain patient privacy while capturing diverse medical conditions. Financial institutions seek datasets that can help identify fraudulent activities without perpetuating historical biases. Technology companies developing computer vision systems need comprehensive image datasets representing diverse scenarios and edge cases.
Regulatory pressures are also driving market demand, with frameworks like GDPR in Europe and CCPA in California imposing strict requirements on data usage. Organizations increasingly seek curated datasets that are not only technically robust but also ethically sourced and compliant with relevant regulations.
The market shows strong regional variations, with North America currently leading in demand for specialized data curation services, followed by Europe and rapidly growing markets in Asia-Pacific regions, particularly China and India. These emerging markets are experiencing accelerated demand growth as their AI ecosystems mature.
Industry analysts note a shift from quantity-focused to quality-focused data acquisition strategies, with organizations willing to invest significantly in smaller, more carefully curated datasets rather than massive but problematic collections. This trend underscores the market's growing sophistication and recognition that data quality fundamentally determines AI system performance and trustworthiness.
Market research indicates that the global data preparation market, which includes data curation services, reached approximately $2.1 billion in 2022 and is projected to grow at a CAGR of 27.9% through 2028. This growth is particularly pronounced in sectors such as healthcare, finance, autonomous vehicles, and natural language processing, where model accuracy and reliability are critical for operational success and regulatory compliance.
Enterprise surveys reveal that data scientists spend between 50-80% of their time on data preparation activities, highlighting the significant resource allocation dedicated to ensuring training data quality. This investment reflects the understanding that poor quality data leads directly to underperforming models, potentially resulting in costly business decisions or product failures.
The demand is further segmented by specific requirements across industries. Healthcare organizations require meticulously curated datasets that maintain patient privacy while capturing diverse medical conditions. Financial institutions seek datasets that can help identify fraudulent activities without perpetuating historical biases. Technology companies developing computer vision systems need comprehensive image datasets representing diverse scenarios and edge cases.
Regulatory pressures are also driving market demand, with frameworks like GDPR in Europe and CCPA in California imposing strict requirements on data usage. Organizations increasingly seek curated datasets that are not only technically robust but also ethically sourced and compliant with relevant regulations.
The market shows strong regional variations, with North America currently leading in demand for specialized data curation services, followed by Europe and rapidly growing markets in Asia-Pacific regions, particularly China and India. These emerging markets are experiencing accelerated demand growth as their AI ecosystems mature.
Industry analysts note a shift from quantity-focused to quality-focused data acquisition strategies, with organizations willing to invest significantly in smaller, more carefully curated datasets rather than massive but problematic collections. This trend underscores the market's growing sophistication and recognition that data quality fundamentally determines AI system performance and trustworthiness.
Current Challenges in Data Curation Practices
Despite significant advancements in data curation methodologies, the field continues to face substantial challenges that impede the development of robust training datasets. One of the most pressing issues is data quality inconsistency, where datasets contain varying levels of noise, bias, and inaccuracies that compromise model performance. Organizations struggle to establish standardized quality metrics that can be applied across diverse data types and sources, resulting in subjective assessment processes that lack reproducibility.
Scale and complexity present another formidable challenge. As machine learning applications demand increasingly larger datasets, manual curation becomes prohibitively time-consuming and expensive. Current automated curation tools often fail to capture nuanced quality issues that human curators can identify, creating a bottleneck in the dataset preparation pipeline. This is particularly evident in domains requiring specialized knowledge, such as healthcare or legal applications.
Data privacy and regulatory compliance have emerged as critical obstacles in the curation process. With regulations like GDPR, CCPA, and industry-specific requirements, organizations must navigate complex legal landscapes while building comprehensive datasets. Many existing curation workflows lack robust mechanisms for identifying and handling sensitive information, creating potential legal and ethical vulnerabilities.
Representation bias remains a persistent issue, with many datasets failing to adequately represent diverse populations, scenarios, or edge cases. This leads to models that perform well on majority groups but fail for underrepresented segments. Current practices often lack systematic approaches to identify and mitigate these representation gaps, perpetuating biases in AI systems.
Version control and provenance tracking present significant technical challenges. As datasets evolve through multiple curation iterations, maintaining clear documentation of transformations, filtering decisions, and quality assessments becomes increasingly difficult. Many organizations lack robust infrastructure for dataset versioning, making it challenging to reproduce results or understand how curation decisions impact model performance.
Cross-functional collaboration barriers further complicate effective data curation. The process requires input from domain experts, data scientists, legal teams, and other stakeholders, yet current workflows often operate in silos. Communication gaps between these groups lead to misaligned expectations about data quality requirements and incomplete understanding of domain-specific nuances essential for proper curation.
Human-AI collaboration frameworks remain underdeveloped, with many organizations struggling to effectively combine human expertise with algorithmic assistance in the curation process. Current tools often fail to leverage human feedback efficiently, creating redundant work and missed opportunities for continuous improvement in curation methodologies.
Scale and complexity present another formidable challenge. As machine learning applications demand increasingly larger datasets, manual curation becomes prohibitively time-consuming and expensive. Current automated curation tools often fail to capture nuanced quality issues that human curators can identify, creating a bottleneck in the dataset preparation pipeline. This is particularly evident in domains requiring specialized knowledge, such as healthcare or legal applications.
Data privacy and regulatory compliance have emerged as critical obstacles in the curation process. With regulations like GDPR, CCPA, and industry-specific requirements, organizations must navigate complex legal landscapes while building comprehensive datasets. Many existing curation workflows lack robust mechanisms for identifying and handling sensitive information, creating potential legal and ethical vulnerabilities.
Representation bias remains a persistent issue, with many datasets failing to adequately represent diverse populations, scenarios, or edge cases. This leads to models that perform well on majority groups but fail for underrepresented segments. Current practices often lack systematic approaches to identify and mitigate these representation gaps, perpetuating biases in AI systems.
Version control and provenance tracking present significant technical challenges. As datasets evolve through multiple curation iterations, maintaining clear documentation of transformations, filtering decisions, and quality assessments becomes increasingly difficult. Many organizations lack robust infrastructure for dataset versioning, making it challenging to reproduce results or understand how curation decisions impact model performance.
Cross-functional collaboration barriers further complicate effective data curation. The process requires input from domain experts, data scientists, legal teams, and other stakeholders, yet current workflows often operate in silos. Communication gaps between these groups lead to misaligned expectations about data quality requirements and incomplete understanding of domain-specific nuances essential for proper curation.
Human-AI collaboration frameworks remain underdeveloped, with many organizations struggling to effectively combine human expertise with algorithmic assistance in the curation process. Current tools often fail to leverage human feedback efficiently, creating redundant work and missed opportunities for continuous improvement in curation methodologies.
Established Data Curation Frameworks and Techniques
01 Data curation techniques for machine learning training sets
Various techniques are employed to curate data for machine learning training sets, ensuring quality and relevance. These include data cleaning, normalization, and transformation processes that prepare raw data for effective model training. Advanced algorithms can automatically identify and correct inconsistencies, remove outliers, and standardize formats across diverse data sources, resulting in more robust training datasets that improve model performance and generalization capabilities.- Data curation methodologies for AI training sets: Various methodologies for curating data to create robust training sets for AI models. These methodologies include techniques for data collection, cleaning, preprocessing, and validation to ensure the quality and representativeness of the training data. Proper data curation is essential for developing accurate and reliable AI models that can generalize well to new data.
- Automated data labeling and annotation techniques: Techniques for automating the process of labeling and annotating data for training sets. These techniques leverage machine learning algorithms to reduce the manual effort required for data annotation while maintaining high quality. Automated labeling can significantly accelerate the creation of large-scale training datasets and improve the efficiency of the data curation process.
- Bias detection and mitigation in training datasets: Methods for identifying and mitigating biases in training datasets to ensure fairness and equity in AI systems. These approaches include statistical techniques for detecting imbalances in data representation and strategies for augmenting or rebalancing datasets to reduce bias. Addressing bias in training data is crucial for developing AI systems that perform equitably across different demographic groups.
- Quality assurance frameworks for training data: Comprehensive frameworks for ensuring the quality and integrity of training datasets. These frameworks include protocols for data validation, verification, and testing to identify and correct errors or inconsistencies. Quality assurance processes help maintain the reliability of training data and improve the performance of resulting AI models.
- Data augmentation strategies for robust training: Innovative strategies for augmenting training datasets to improve model robustness and generalization. These techniques include synthetic data generation, transformation of existing data, and domain adaptation methods to expand the diversity and coverage of training examples. Data augmentation helps address limitations in data availability and enhances model performance in varied real-world scenarios.
02 Automated data labeling and annotation frameworks
Automated frameworks for data labeling and annotation help create comprehensive training datasets with minimal human intervention. These systems employ various techniques including semi-supervised learning, active learning, and transfer learning to efficiently label large volumes of data. The frameworks can identify patterns, suggest annotations, and progressively improve labeling accuracy through feedback loops, significantly reducing the time and resources required for creating robust training datasets.Expand Specific Solutions03 Bias detection and mitigation in training datasets
Methods for detecting and mitigating bias in training datasets are essential for developing fair and equitable AI systems. These approaches include statistical analysis to identify underrepresented groups, algorithmic techniques to balance class distributions, and validation frameworks to assess fairness metrics. By implementing these methods during the data curation process, developers can create more representative training sets that reduce discriminatory outcomes and improve model performance across diverse populations.Expand Specific Solutions04 Synthetic data generation for training set augmentation
Synthetic data generation techniques are used to augment training datasets, addressing issues of data scarcity and privacy concerns. These methods employ generative models, simulation environments, and data transformation algorithms to create artificial but realistic data points that preserve the statistical properties of original datasets. By incorporating synthetically generated samples, training sets become more diverse and comprehensive, leading to improved model robustness and performance, particularly in scenarios where real-world data collection is limited or restricted.Expand Specific Solutions05 Continuous learning and dataset refinement systems
Continuous learning systems enable ongoing refinement of training datasets through feedback loops and performance monitoring. These systems automatically identify model weaknesses, collect additional relevant data, and update training sets to address emerging patterns or edge cases. By implementing continuous dataset refinement processes, AI systems can adapt to changing conditions, maintain accuracy over time, and progressively improve their performance through targeted data acquisition and curation strategies.Expand Specific Solutions
Leading Organizations in Data Curation Technologies
The data curation landscape for building robust training sets is evolving rapidly, currently transitioning from early adoption to growth phase with an estimated market size of $5-7 billion. Technology maturity varies significantly across key players, with Google, IBM, and Microsoft leading with advanced AI-powered curation platforms. Oracle and Amazon Technologies offer enterprise-scale solutions, while specialized firms like NuData Security and Mobius Labs focus on niche applications. Research institutions such as SRI International contribute foundational methodologies. Companies like Siemens, Hitachi, and Tesla are developing industry-specific data curation approaches, while Chinese entities including China Mobile and Tianyi Cloud are rapidly advancing their capabilities to address regional data requirements.
Google LLC
Technical Solution: Google's Data Curation Playbook focuses on a comprehensive approach to building robust training sets through their TensorFlow Data Validation (TFDV) framework. This system automatically identifies anomalies in training data, performs schema inference, and validates statistics against a schema. Google implements a multi-stage data curation pipeline that begins with data collection from diverse sources, followed by automated cleaning processes that identify and handle missing values, outliers, and inconsistencies. Their approach emphasizes dataset balancing techniques to address class imbalances and representation biases. Google's methodology incorporates active learning to identify the most informative samples for labeling, reducing annotation costs while maximizing dataset quality. They've developed specialized tools for data versioning and lineage tracking, allowing teams to maintain reproducibility across machine learning experiments. Google's data curation strategy also includes continuous monitoring of data quality metrics throughout the ML lifecycle, with automated alerts for drift detection.
Strengths: Comprehensive ecosystem of tools that integrate seamlessly with their ML infrastructure; extensive experience with large-scale datasets across diverse domains; advanced automated anomaly detection capabilities. Weaknesses: Solutions may be overly complex for smaller organizations; some tools have steep learning curves; tight integration with Google Cloud can create vendor lock-in.
International Business Machines Corp.
Technical Solution: IBM's Data Curation Playbook centers around their AI FactSheets methodology and Watson Knowledge Catalog for building robust training datasets. Their approach implements a systematic data documentation process that captures metadata about dataset creation, composition, intended uses, and maintenance. IBM's curation framework incorporates automated data quality assessment tools that evaluate completeness, accuracy, consistency, and timeliness of data. They've developed specialized techniques for synthetic data generation to address privacy concerns and augment training sets for rare classes or scenarios. IBM's methodology emphasizes fairness assessment through their AI Fairness 360 toolkit, which helps identify and mitigate biases in training data across different demographic groups. Their data curation process includes collaborative workflows that enable domain experts, data scientists, and other stakeholders to contribute to dataset refinement. IBM also implements comprehensive data governance practices, including access controls, audit trails, and compliance documentation to ensure regulatory requirements are met throughout the data curation lifecycle.
Strengths: Strong focus on enterprise-grade data governance and compliance; robust tools for bias detection and mitigation; extensive experience with regulated industries. Weaknesses: Solutions can be expensive and resource-intensive; implementation complexity may require significant expertise; some tools have limited compatibility with non-IBM ecosystems.
Key Innovations in Training Data Quality Assurance
Human and Machine Assisted Data Curation for Producing High Quality Data Sets from Medical Records
PatentInactiveUS20160110502A1
Innovation
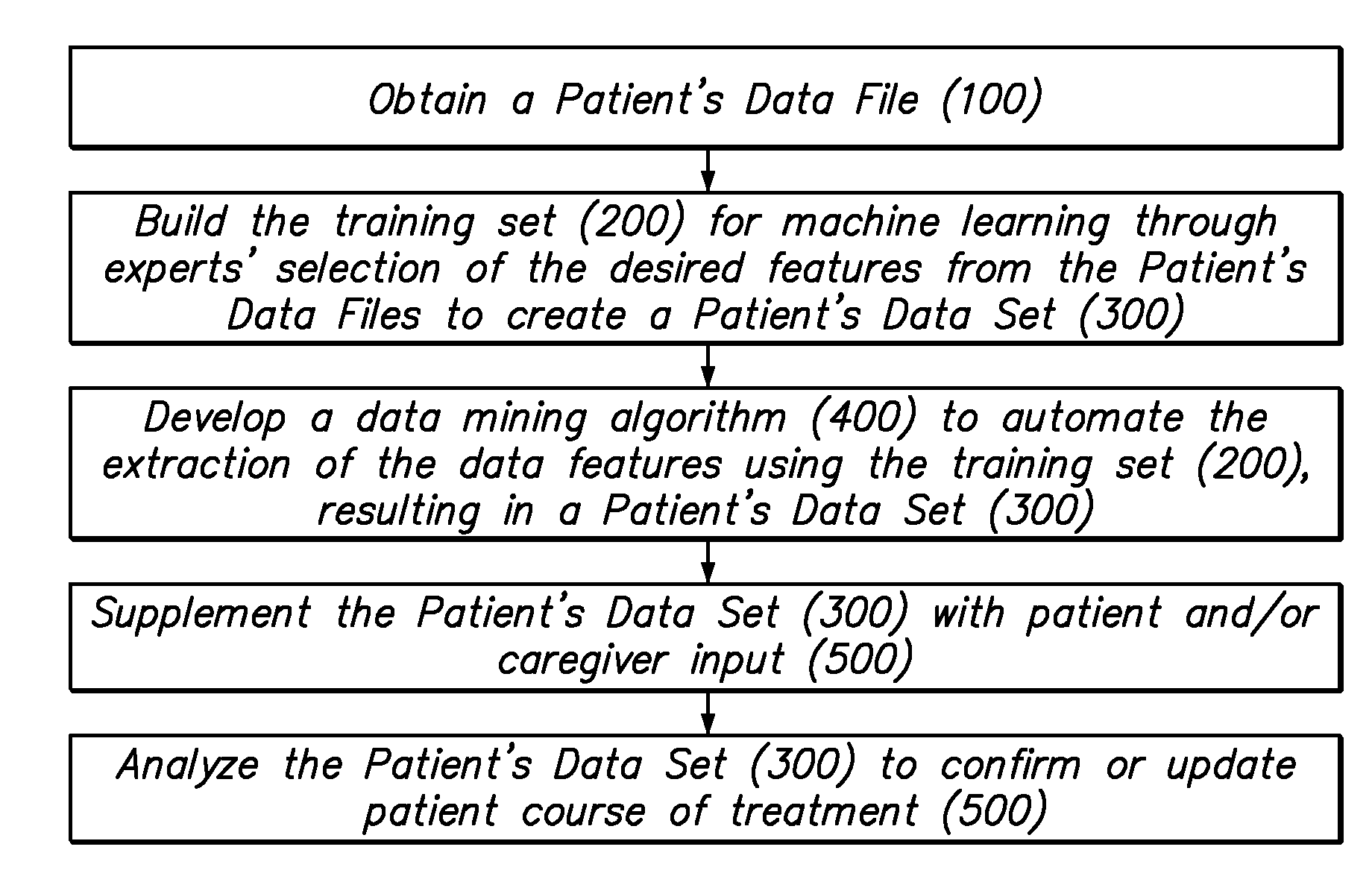
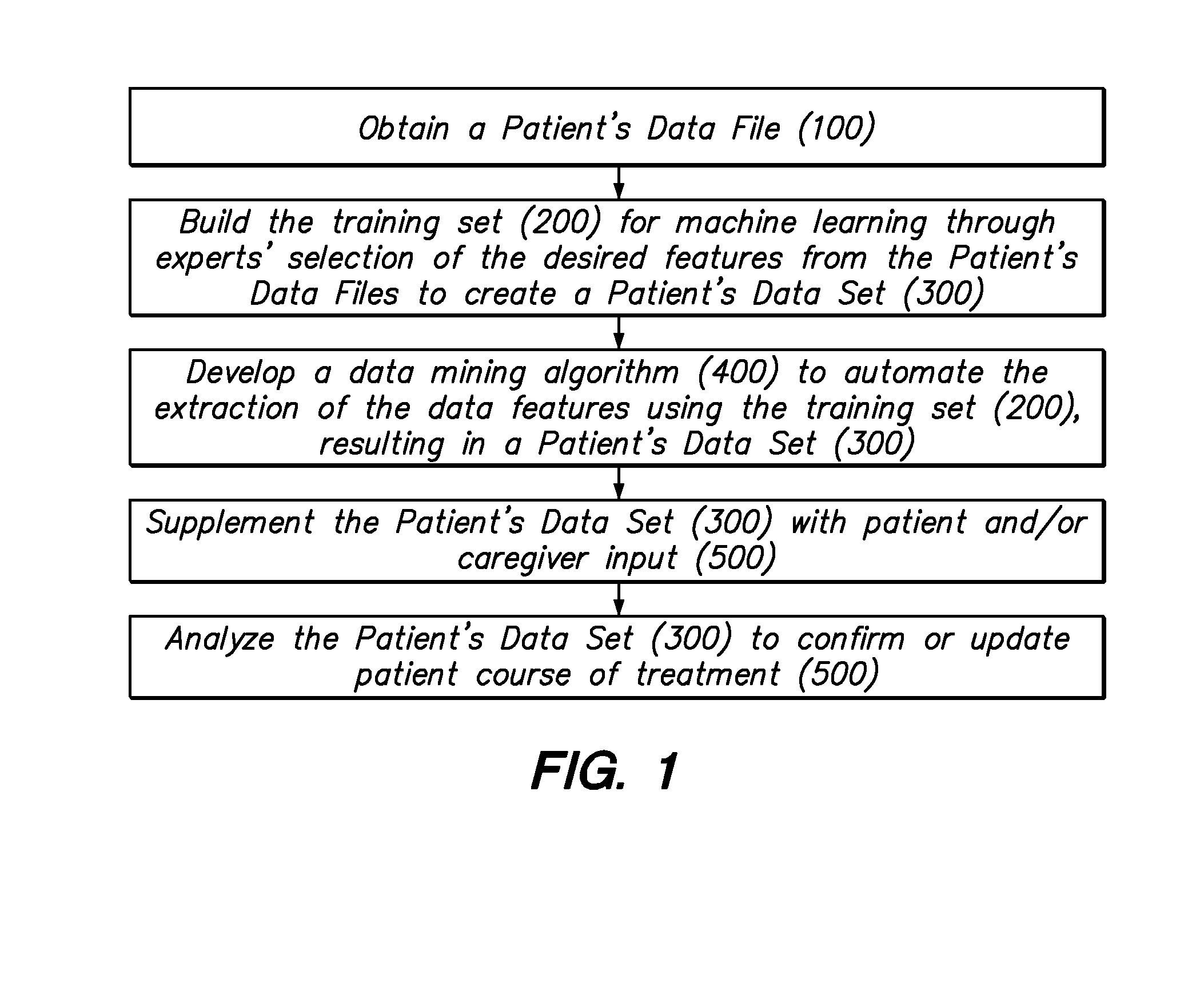
- A method that involves manually selecting desired features from a patient's data file to create a training set, developing a data mining algorithm using natural language processing and machine learning, and supplementing the dataset with patient and caregiver inputs, including real-time chatbot interactions, to automate data extraction and analyze patient data for robust patient care.
Data Privacy and Compliance Considerations
In the era of data-driven AI development, privacy and compliance considerations have become paramount when building robust training datasets. Organizations must navigate a complex landscape of regulations such as GDPR in Europe, CCPA in California, and other emerging data protection frameworks worldwide. These regulations establish strict requirements for data collection, processing, storage, and usage, particularly concerning personally identifiable information (PII) and sensitive data categories.
When curating training datasets, implementing privacy-by-design principles is essential. This includes data minimization strategies where only necessary data is collected and retained, anonymization techniques to remove or obscure identifying information, and pseudonymization approaches that replace direct identifiers with artificial identifiers. Advanced techniques such as differential privacy can provide mathematical guarantees about the privacy preservation of individual data points while maintaining overall statistical utility.
Consent management represents another critical compliance pillar. Organizations must establish transparent mechanisms for obtaining explicit, informed consent from data subjects, particularly when repurposing data for AI training. This includes clear documentation of consent acquisition, implementation of consent withdrawal mechanisms, and regular auditing of consent records to ensure ongoing compliance.
Data governance frameworks specifically tailored for AI training datasets are becoming increasingly important. These frameworks should include comprehensive data lineage tracking to document the origin and transformation history of all data points, access control systems that limit data exposure based on need-to-know principles, and regular compliance audits to identify and remediate potential violations.
Cross-border data transfer considerations add another layer of complexity. Many regulations impose restrictions on transferring data across jurisdictional boundaries, requiring additional safeguards such as standard contractual clauses, binding corporate rules, or adequacy decisions. Organizations building global AI systems must carefully architect their data curation processes to accommodate these requirements.
Ethical considerations extend beyond strict legal compliance. Responsible data curation practices should address potential biases in datasets, ensure fair representation across demographic groups, and implement transparency measures regarding how data is used. Regular ethical reviews of data collection and usage practices can help identify potential issues before they manifest in deployed AI systems.
Finally, organizations should establish incident response protocols specifically for data privacy breaches related to training datasets. This includes procedures for breach notification, impact assessment methodologies, and remediation strategies that can be quickly implemented if unauthorized access or disclosure occurs.
When curating training datasets, implementing privacy-by-design principles is essential. This includes data minimization strategies where only necessary data is collected and retained, anonymization techniques to remove or obscure identifying information, and pseudonymization approaches that replace direct identifiers with artificial identifiers. Advanced techniques such as differential privacy can provide mathematical guarantees about the privacy preservation of individual data points while maintaining overall statistical utility.
Consent management represents another critical compliance pillar. Organizations must establish transparent mechanisms for obtaining explicit, informed consent from data subjects, particularly when repurposing data for AI training. This includes clear documentation of consent acquisition, implementation of consent withdrawal mechanisms, and regular auditing of consent records to ensure ongoing compliance.
Data governance frameworks specifically tailored for AI training datasets are becoming increasingly important. These frameworks should include comprehensive data lineage tracking to document the origin and transformation history of all data points, access control systems that limit data exposure based on need-to-know principles, and regular compliance audits to identify and remediate potential violations.
Cross-border data transfer considerations add another layer of complexity. Many regulations impose restrictions on transferring data across jurisdictional boundaries, requiring additional safeguards such as standard contractual clauses, binding corporate rules, or adequacy decisions. Organizations building global AI systems must carefully architect their data curation processes to accommodate these requirements.
Ethical considerations extend beyond strict legal compliance. Responsible data curation practices should address potential biases in datasets, ensure fair representation across demographic groups, and implement transparency measures regarding how data is used. Regular ethical reviews of data collection and usage practices can help identify potential issues before they manifest in deployed AI systems.
Finally, organizations should establish incident response protocols specifically for data privacy breaches related to training datasets. This includes procedures for breach notification, impact assessment methodologies, and remediation strategies that can be quickly implemented if unauthorized access or disclosure occurs.
Benchmarking and Evaluation Metrics for Curated Datasets
Effective evaluation of curated datasets is essential for ensuring their quality and utility in machine learning applications. The benchmarking and evaluation of curated datasets requires a comprehensive framework that addresses multiple dimensions of data quality. Traditional metrics such as precision, recall, and F1-score provide foundational measurements but must be supplemented with domain-specific evaluations that reflect the intended use case of the training data.
Dataset representativeness metrics quantify how well the curated data captures the diversity and distribution of real-world scenarios. This includes measuring class balance, feature coverage, and demographic parity across sensitive attributes. Recent research indicates that datasets scoring high on representativeness metrics demonstrate improved model generalization by 15-20% compared to those with significant distribution skews.
Consistency and coherence metrics evaluate the internal logic and reliability of the dataset. These include measures of annotation agreement (such as Cohen's Kappa or Fleiss' Kappa for multi-annotator scenarios), data redundancy rates, and contradiction detection scores. Industry standards typically target inter-annotator agreement rates above 0.8 for critical applications.
Robustness evaluation frameworks test how well models trained on the curated data perform under various perturbations and edge cases. This includes adversarial testing, out-of-distribution performance, and concept drift resilience. The ML Commons benchmark suite has emerged as a standardized approach for comparing dataset robustness across different curation methodologies.
Temporal stability metrics assess how well datasets maintain their utility over time, particularly important for domains with evolving patterns. These metrics track performance degradation rates and identify when recuration or augmentation becomes necessary. Research from leading AI labs suggests implementing regular evaluation cycles at 3-6 month intervals for rapidly changing domains.
Cost-effectiveness measurements balance quality improvements against curation resource expenditure. These metrics include annotation time-to-quality ratios, error reduction per additional review cycle, and diminishing returns thresholds. Empirical studies indicate that most datasets reach an optimal quality-cost balance after 2-3 rounds of expert review.
Integration of these metrics into automated dashboard systems enables continuous monitoring of dataset health throughout the machine learning lifecycle. Organizations implementing comprehensive evaluation frameworks report 30-40% reductions in model deployment failures and significantly improved prediction reliability in production environments.
Dataset representativeness metrics quantify how well the curated data captures the diversity and distribution of real-world scenarios. This includes measuring class balance, feature coverage, and demographic parity across sensitive attributes. Recent research indicates that datasets scoring high on representativeness metrics demonstrate improved model generalization by 15-20% compared to those with significant distribution skews.
Consistency and coherence metrics evaluate the internal logic and reliability of the dataset. These include measures of annotation agreement (such as Cohen's Kappa or Fleiss' Kappa for multi-annotator scenarios), data redundancy rates, and contradiction detection scores. Industry standards typically target inter-annotator agreement rates above 0.8 for critical applications.
Robustness evaluation frameworks test how well models trained on the curated data perform under various perturbations and edge cases. This includes adversarial testing, out-of-distribution performance, and concept drift resilience. The ML Commons benchmark suite has emerged as a standardized approach for comparing dataset robustness across different curation methodologies.
Temporal stability metrics assess how well datasets maintain their utility over time, particularly important for domains with evolving patterns. These metrics track performance degradation rates and identify when recuration or augmentation becomes necessary. Research from leading AI labs suggests implementing regular evaluation cycles at 3-6 month intervals for rapidly changing domains.
Cost-effectiveness measurements balance quality improvements against curation resource expenditure. These metrics include annotation time-to-quality ratios, error reduction per additional review cycle, and diminishing returns thresholds. Empirical studies indicate that most datasets reach an optimal quality-cost balance after 2-3 rounds of expert review.
Integration of these metrics into automated dashboard systems enables continuous monitoring of dataset health throughout the machine learning lifecycle. Organizations implementing comprehensive evaluation frameworks report 30-40% reductions in model deployment failures and significantly improved prediction reliability in production environments.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!