How to Integrate AI-Predicted Catalysts into Experimental Validation Pipelines
AUG 20, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
AI Catalyst Prediction Background and Objectives
The integration of AI-predicted catalysts into experimental validation pipelines represents a significant advancement in the field of catalysis research and development. This approach combines the power of artificial intelligence with traditional experimental methods to accelerate the discovery and optimization of catalysts for various chemical processes.
The evolution of catalyst discovery has undergone several paradigm shifts over the past century. Initially, catalysts were discovered through trial and error methods, which were time-consuming and resource-intensive. The advent of computational chemistry in the late 20th century introduced more systematic approaches, allowing researchers to model and predict catalyst behavior based on theoretical principles. However, these methods were often limited by computational power and the complexity of real-world catalytic systems.
The emergence of machine learning and artificial intelligence in the 21st century has ushered in a new era of catalyst prediction. AI algorithms can now analyze vast datasets of chemical properties, reaction conditions, and experimental results to identify patterns and predict promising catalyst candidates. This approach significantly reduces the time and resources required for catalyst discovery, potentially accelerating the development of new materials and processes for industries ranging from pharmaceuticals to renewable energy.
The primary objective of integrating AI-predicted catalysts into experimental validation pipelines is to create a seamless workflow that combines the speed and efficiency of computational predictions with the reliability of experimental verification. This integration aims to streamline the catalyst discovery process, reduce the number of experimental iterations required, and ultimately accelerate the commercialization of new catalytic technologies.
Key technical goals include developing robust AI models capable of accurately predicting catalyst performance across a wide range of chemical reactions and conditions. These models must be able to incorporate diverse data types, including structural information, electronic properties, and reaction kinetics. Additionally, the integration process seeks to establish standardized protocols for translating AI predictions into experimental designs, ensuring that computational insights can be effectively validated in laboratory settings.
Another critical objective is to create feedback loops between experimental results and AI models, allowing for continuous refinement and improvement of predictive capabilities. This iterative approach aims to enhance the accuracy and reliability of AI predictions over time, leading to increasingly efficient catalyst discovery cycles.
Furthermore, the integration of AI-predicted catalysts into experimental pipelines aims to address longstanding challenges in catalyst design, such as improving selectivity, enhancing stability, and reducing the use of rare or expensive materials. By leveraging AI's ability to explore vast chemical spaces and identify non-obvious relationships, researchers hope to discover novel catalyst formulations that outperform traditional options across multiple performance metrics.
The evolution of catalyst discovery has undergone several paradigm shifts over the past century. Initially, catalysts were discovered through trial and error methods, which were time-consuming and resource-intensive. The advent of computational chemistry in the late 20th century introduced more systematic approaches, allowing researchers to model and predict catalyst behavior based on theoretical principles. However, these methods were often limited by computational power and the complexity of real-world catalytic systems.
The emergence of machine learning and artificial intelligence in the 21st century has ushered in a new era of catalyst prediction. AI algorithms can now analyze vast datasets of chemical properties, reaction conditions, and experimental results to identify patterns and predict promising catalyst candidates. This approach significantly reduces the time and resources required for catalyst discovery, potentially accelerating the development of new materials and processes for industries ranging from pharmaceuticals to renewable energy.
The primary objective of integrating AI-predicted catalysts into experimental validation pipelines is to create a seamless workflow that combines the speed and efficiency of computational predictions with the reliability of experimental verification. This integration aims to streamline the catalyst discovery process, reduce the number of experimental iterations required, and ultimately accelerate the commercialization of new catalytic technologies.
Key technical goals include developing robust AI models capable of accurately predicting catalyst performance across a wide range of chemical reactions and conditions. These models must be able to incorporate diverse data types, including structural information, electronic properties, and reaction kinetics. Additionally, the integration process seeks to establish standardized protocols for translating AI predictions into experimental designs, ensuring that computational insights can be effectively validated in laboratory settings.
Another critical objective is to create feedback loops between experimental results and AI models, allowing for continuous refinement and improvement of predictive capabilities. This iterative approach aims to enhance the accuracy and reliability of AI predictions over time, leading to increasingly efficient catalyst discovery cycles.
Furthermore, the integration of AI-predicted catalysts into experimental pipelines aims to address longstanding challenges in catalyst design, such as improving selectivity, enhancing stability, and reducing the use of rare or expensive materials. By leveraging AI's ability to explore vast chemical spaces and identify non-obvious relationships, researchers hope to discover novel catalyst formulations that outperform traditional options across multiple performance metrics.
Market Analysis for AI-Driven Catalyst Discovery
The market for AI-driven catalyst discovery is experiencing rapid growth and transformation, driven by the increasing demand for more efficient and sustainable chemical processes across various industries. This market segment sits at the intersection of artificial intelligence, materials science, and chemical engineering, offering significant potential for innovation and economic impact.
The global catalyst market, which forms the broader context for AI-driven discovery, was valued at approximately $33.9 billion in 2020 and is projected to reach $48.1 billion by 2027, growing at a CAGR of 5.2%. Within this larger market, the AI-driven catalyst discovery segment is emerging as a high-growth area, with some estimates suggesting it could capture up to 10-15% of the total catalyst market by 2030.
Key industries driving the demand for AI-predicted catalysts include petrochemicals, pharmaceuticals, fine chemicals, and renewable energy. The petrochemical sector, in particular, is showing strong interest in AI-driven catalyst discovery to optimize processes and reduce environmental impact. The pharmaceutical industry is leveraging this technology to accelerate drug discovery and development, potentially reducing time-to-market for new therapies.
The market is characterized by a mix of established chemical companies investing in AI capabilities and startups specializing in AI-driven materials discovery. Major players like BASF, Dow Chemical, and Johnson Matthey are actively exploring AI integration into their catalyst development pipelines. Simultaneously, startups such as Kebotix, Citrine Informatics, and Matmerize are gaining traction with their specialized AI platforms for materials discovery.
Geographically, North America and Europe are leading in AI-driven catalyst discovery, with significant research and development activities concentrated in these regions. However, Asia-Pacific is emerging as a fast-growing market, driven by increasing industrialization and government initiatives to promote advanced technologies.
The market is witnessing several trends that are shaping its growth trajectory. There is a growing emphasis on sustainable and green chemistry, pushing the development of catalysts that enable more environmentally friendly processes. Additionally, the integration of machine learning with high-throughput experimentation is accelerating the discovery and optimization of novel catalysts.
Challenges in the market include the need for high-quality, diverse datasets to train AI models effectively, and the complexity of integrating AI predictions with experimental validation processes. However, these challenges also present opportunities for companies that can successfully bridge the gap between computational predictions and real-world applications.
The global catalyst market, which forms the broader context for AI-driven discovery, was valued at approximately $33.9 billion in 2020 and is projected to reach $48.1 billion by 2027, growing at a CAGR of 5.2%. Within this larger market, the AI-driven catalyst discovery segment is emerging as a high-growth area, with some estimates suggesting it could capture up to 10-15% of the total catalyst market by 2030.
Key industries driving the demand for AI-predicted catalysts include petrochemicals, pharmaceuticals, fine chemicals, and renewable energy. The petrochemical sector, in particular, is showing strong interest in AI-driven catalyst discovery to optimize processes and reduce environmental impact. The pharmaceutical industry is leveraging this technology to accelerate drug discovery and development, potentially reducing time-to-market for new therapies.
The market is characterized by a mix of established chemical companies investing in AI capabilities and startups specializing in AI-driven materials discovery. Major players like BASF, Dow Chemical, and Johnson Matthey are actively exploring AI integration into their catalyst development pipelines. Simultaneously, startups such as Kebotix, Citrine Informatics, and Matmerize are gaining traction with their specialized AI platforms for materials discovery.
Geographically, North America and Europe are leading in AI-driven catalyst discovery, with significant research and development activities concentrated in these regions. However, Asia-Pacific is emerging as a fast-growing market, driven by increasing industrialization and government initiatives to promote advanced technologies.
The market is witnessing several trends that are shaping its growth trajectory. There is a growing emphasis on sustainable and green chemistry, pushing the development of catalysts that enable more environmentally friendly processes. Additionally, the integration of machine learning with high-throughput experimentation is accelerating the discovery and optimization of novel catalysts.
Challenges in the market include the need for high-quality, diverse datasets to train AI models effectively, and the complexity of integrating AI predictions with experimental validation processes. However, these challenges also present opportunities for companies that can successfully bridge the gap between computational predictions and real-world applications.
Current Challenges in AI-Predicted Catalyst Validation
The integration of AI-predicted catalysts into experimental validation pipelines faces several significant challenges. One of the primary obstacles is the inherent complexity of catalyst systems, which often involve intricate interactions between multiple components. AI models, while powerful, may struggle to capture all the nuances of these complex systems, leading to potential discrepancies between predictions and experimental results.
Another major challenge lies in the data quality and quantity available for AI training. Catalyst research often relies on limited datasets due to the time-consuming and expensive nature of experimental work. This scarcity of high-quality, diverse data can lead to biased or incomplete AI predictions, potentially misdirecting experimental efforts.
The interpretability of AI models presents a further hurdle. Many advanced AI algorithms, particularly deep learning models, operate as "black boxes," making it difficult for researchers to understand the reasoning behind specific catalyst predictions. This lack of transparency can hinder the integration of AI predictions into experimental workflows, as scientists may be hesitant to rely on recommendations without clear justification.
Bridging the gap between computational predictions and experimental realities poses another significant challenge. AI models often make predictions based on idealized conditions, while real-world experiments must contend with various practical constraints and environmental factors. This discrepancy can lead to unexpected results and complicate the validation process.
The dynamic nature of catalyst research also presents difficulties for AI integration. As new experimental techniques and theoretical insights emerge, AI models need to be continuously updated and retrained. This requirement for ongoing model maintenance and adaptation can strain resources and slow down the integration process.
Furthermore, the interdisciplinary nature of catalyst research complicates the integration of AI predictions. Effective collaboration between computational scientists, chemists, and engineers is crucial but often challenging due to differences in expertise and communication styles. Bridging these disciplinary gaps is essential for successful integration but requires significant effort and coordination.
Lastly, the validation of AI-predicted catalysts often requires specialized equipment and expertise, which may not be readily available in all research settings. This limitation can create bottlenecks in the experimental pipeline, slowing down the overall process of catalyst discovery and optimization.
Another major challenge lies in the data quality and quantity available for AI training. Catalyst research often relies on limited datasets due to the time-consuming and expensive nature of experimental work. This scarcity of high-quality, diverse data can lead to biased or incomplete AI predictions, potentially misdirecting experimental efforts.
The interpretability of AI models presents a further hurdle. Many advanced AI algorithms, particularly deep learning models, operate as "black boxes," making it difficult for researchers to understand the reasoning behind specific catalyst predictions. This lack of transparency can hinder the integration of AI predictions into experimental workflows, as scientists may be hesitant to rely on recommendations without clear justification.
Bridging the gap between computational predictions and experimental realities poses another significant challenge. AI models often make predictions based on idealized conditions, while real-world experiments must contend with various practical constraints and environmental factors. This discrepancy can lead to unexpected results and complicate the validation process.
The dynamic nature of catalyst research also presents difficulties for AI integration. As new experimental techniques and theoretical insights emerge, AI models need to be continuously updated and retrained. This requirement for ongoing model maintenance and adaptation can strain resources and slow down the integration process.
Furthermore, the interdisciplinary nature of catalyst research complicates the integration of AI predictions. Effective collaboration between computational scientists, chemists, and engineers is crucial but often challenging due to differences in expertise and communication styles. Bridging these disciplinary gaps is essential for successful integration but requires significant effort and coordination.
Lastly, the validation of AI-predicted catalysts often requires specialized equipment and expertise, which may not be readily available in all research settings. This limitation can create bottlenecks in the experimental pipeline, slowing down the overall process of catalyst discovery and optimization.
Existing AI-Experimental Integration Methodologies
01 AI-driven catalyst design for chemical reactions
Artificial intelligence is being used to predict and design novel catalysts for various chemical reactions. This approach involves using machine learning algorithms to analyze large datasets of known catalysts and their properties, enabling the identification of potential new catalysts with improved performance and efficiency.- AI-driven catalyst design and optimization: Artificial intelligence techniques are employed to predict and design novel catalysts with improved performance. Machine learning algorithms analyze vast datasets of chemical properties and reaction outcomes to identify promising catalyst candidates, accelerating the discovery process and reducing experimental costs.
- Computational screening of catalysts for specific reactions: Advanced computational methods are used to screen large libraries of potential catalysts for specific chemical reactions. These techniques involve simulating reaction mechanisms, predicting catalytic activity, and evaluating selectivity to identify the most promising candidates for experimental validation.
- Integration of machine learning with high-throughput experimentation: Machine learning algorithms are combined with high-throughput experimental techniques to rapidly evaluate and optimize catalyst performance. This approach enables the efficient exploration of complex catalyst compositions and reaction conditions, leading to faster discovery of improved catalysts.
- AI-assisted catalyst structure-property relationship analysis: Artificial intelligence techniques are applied to analyze the relationships between catalyst structures and their properties. These methods help identify key structural features that contribute to catalytic activity and selectivity, guiding the design of more effective catalysts.
- Predictive modeling of catalyst stability and deactivation: AI-driven models are developed to predict catalyst stability and deactivation mechanisms under various reaction conditions. These predictive tools help in designing more robust catalysts with extended lifetimes and improved performance in industrial applications.
02 Machine learning for catalyst optimization in industrial processes
Machine learning techniques are being applied to optimize catalysts used in industrial processes. These AI-powered methods can analyze process data, predict catalyst performance, and suggest modifications to improve yield, selectivity, and energy efficiency in large-scale chemical production.Expand Specific Solutions03 AI-assisted discovery of electrocatalysts for energy applications
Artificial intelligence is facilitating the discovery of new electrocatalysts for energy-related applications such as fuel cells, water splitting, and CO2 reduction. AI algorithms can predict the activity and stability of potential electrocatalysts, accelerating the development of more efficient and cost-effective materials for clean energy technologies.Expand Specific Solutions04 Deep learning for predicting catalyst structure-property relationships
Deep learning models are being developed to predict the structure-property relationships of catalysts. These models can analyze complex molecular structures and composition data to forecast catalytic activity, selectivity, and stability, enabling researchers to focus on the most promising candidates for experimental validation.Expand Specific Solutions05 AI-enabled high-throughput screening of heterogeneous catalysts
Artificial intelligence is being used to enhance high-throughput screening methods for heterogeneous catalysts. AI algorithms can rapidly analyze experimental data from combinatorial synthesis and testing, identifying trends and patterns to guide the design of improved catalyst formulations and accelerate the discovery process.Expand Specific Solutions
Key Players in AI Catalyst Discovery Industry
The integration of AI-predicted catalysts into experimental validation pipelines is an emerging field at the intersection of artificial intelligence and materials science. This technology is in its early stages of development, with a growing market potential as industries seek more efficient and cost-effective catalyst discovery methods. The competitive landscape is characterized by collaborations between academic institutions and industry leaders. Companies like IBM, ExxonMobil, and Chevron are investing in this area, leveraging their expertise in AI and chemical engineering. Meanwhile, research institutions such as Zhejiang University, Dalian Institute of Chemical Physics, and Beijing University of Chemical Technology are contributing significant advancements in the field. The technology's maturity is still evolving, with ongoing efforts to improve prediction accuracy and experimental integration.
International Business Machines Corp.
Technical Solution: IBM has developed an AI-driven approach to integrate predicted catalysts into experimental validation pipelines. Their system utilizes machine learning models to predict catalyst properties and performance, which are then seamlessly integrated into automated experimental workflows. The AI system analyzes vast chemical databases and scientific literature to identify promising catalyst candidates[1]. These predictions are then fed into robotic experimentation platforms that can rapidly synthesize and test the catalysts[2]. IBM's approach incorporates feedback loops, where experimental results are used to refine and improve the AI models, creating a continuous learning cycle[3]. This integration allows for faster discovery and optimization of novel catalysts for various applications, including energy storage, chemical synthesis, and environmental remediation.
Strengths: Accelerated catalyst discovery, reduced experimental costs, and improved accuracy through continuous learning. Weaknesses: Reliance on high-quality data for initial model training and potential bias in AI predictions.
ExxonMobil Technology & Engineering Co.
Technical Solution: ExxonMobil has implemented an advanced AI-driven catalyst prediction and validation system. Their approach combines quantum mechanical simulations, machine learning algorithms, and high-throughput experimentation to accelerate catalyst discovery[1]. The AI system predicts catalyst structures and properties based on theoretical calculations and historical data. These predictions are then integrated into automated synthesis and testing platforms, allowing for rapid experimental validation[2]. ExxonMobil's pipeline incorporates in-situ characterization techniques to provide real-time feedback on catalyst performance, which is used to refine the AI models[3]. The company has also developed a unique data management system that ensures seamless integration of predicted and experimental data, facilitating efficient analysis and decision-making in the catalyst development process[4].
Strengths: Comprehensive approach combining theoretical predictions with advanced experimental techniques. Weaknesses: High initial investment in infrastructure and potential challenges in scaling to diverse catalyst types.
Innovative AI Algorithms for Catalyst Prediction
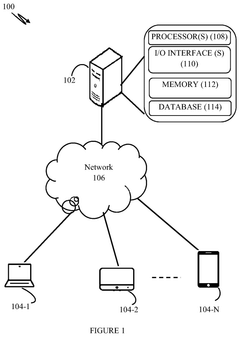
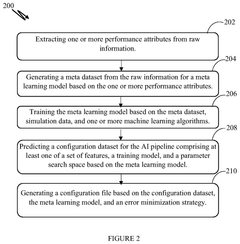
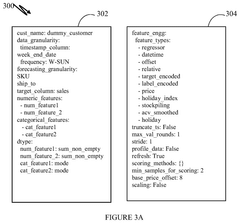
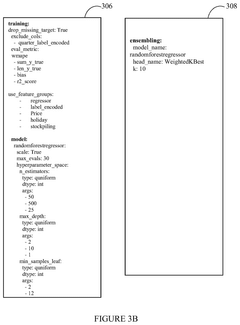
System and method for configuring an artificial intelligence pipeline
PatentPendingUS20250117697A1
Innovation
- A system and method that utilize a meta learning model to automatically generate a configuration file for AI pipelines by extracting performance attributes from raw data, generating a meta dataset, training the meta learning model with simulation data and machine learning algorithms, predicting a configuration dataset, and applying an error minimization strategy.
Automatic expected validation definition generation for data correctness in AI/ML pipelines
PatentActiveUS12086153B1
Innovation
- The implementation of an output schema engine, validator rule definition interface, and validation engine that generates and reuses validator rules to automate the validation process, reducing user interaction and ensuring independent validation of ETL ML pipelines.
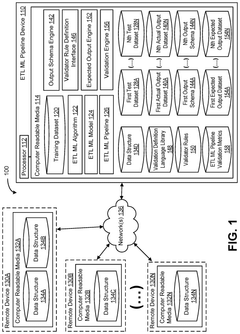
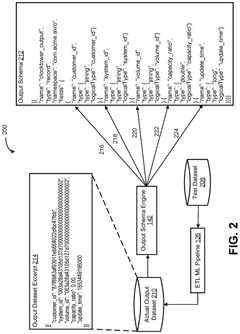
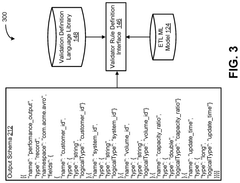
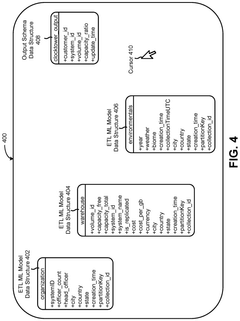
Data Management in AI-Experimental Pipelines
Effective data management is crucial in integrating AI-predicted catalysts into experimental validation pipelines. The process involves handling large volumes of diverse data types, from molecular structures and reaction conditions to spectroscopic measurements and performance metrics. A robust data management system must be implemented to ensure data integrity, accessibility, and traceability throughout the AI-experimental pipeline.
One key aspect of data management in this context is the establishment of standardized data formats and protocols. This standardization facilitates seamless data exchange between AI models and experimental platforms, reducing the risk of data loss or misinterpretation. Implementing well-defined metadata schemas is essential for capturing relevant information about each experiment, including catalyst properties, reaction conditions, and analytical results.
Data storage and retrieval systems play a vital role in managing the vast amounts of information generated during the AI-catalyst discovery process. Cloud-based solutions offer scalability and accessibility, allowing researchers to store and access data from multiple locations. These systems should incorporate robust security measures to protect sensitive information and intellectual property.
Version control is another critical component of data management in AI-experimental pipelines. It enables researchers to track changes in data sets, AI models, and experimental protocols over time. This feature is particularly important when iterating on catalyst designs or refining prediction algorithms, as it allows for easy comparison of results across different versions.
Data quality assurance and validation processes are essential for maintaining the reliability of the AI-experimental pipeline. Automated data validation tools can be employed to check for inconsistencies, outliers, or missing values in experimental results. These tools help ensure that only high-quality data is used for training and validating AI models, thereby improving the accuracy of catalyst predictions.
Integration of laboratory information management systems (LIMS) with AI platforms can streamline data flow and enhance overall efficiency. LIMS can automate data collection from experimental equipment, reducing manual data entry errors and saving time. This integration also facilitates real-time monitoring of experiments and enables rapid feedback loops between AI predictions and experimental validation.
Lastly, implementing data governance policies is crucial for managing data access, sharing, and long-term preservation. These policies should define roles and responsibilities for data stewardship, establish guidelines for data sharing within and outside the organization, and ensure compliance with relevant regulations and ethical standards.
One key aspect of data management in this context is the establishment of standardized data formats and protocols. This standardization facilitates seamless data exchange between AI models and experimental platforms, reducing the risk of data loss or misinterpretation. Implementing well-defined metadata schemas is essential for capturing relevant information about each experiment, including catalyst properties, reaction conditions, and analytical results.
Data storage and retrieval systems play a vital role in managing the vast amounts of information generated during the AI-catalyst discovery process. Cloud-based solutions offer scalability and accessibility, allowing researchers to store and access data from multiple locations. These systems should incorporate robust security measures to protect sensitive information and intellectual property.
Version control is another critical component of data management in AI-experimental pipelines. It enables researchers to track changes in data sets, AI models, and experimental protocols over time. This feature is particularly important when iterating on catalyst designs or refining prediction algorithms, as it allows for easy comparison of results across different versions.
Data quality assurance and validation processes are essential for maintaining the reliability of the AI-experimental pipeline. Automated data validation tools can be employed to check for inconsistencies, outliers, or missing values in experimental results. These tools help ensure that only high-quality data is used for training and validating AI models, thereby improving the accuracy of catalyst predictions.
Integration of laboratory information management systems (LIMS) with AI platforms can streamline data flow and enhance overall efficiency. LIMS can automate data collection from experimental equipment, reducing manual data entry errors and saving time. This integration also facilitates real-time monitoring of experiments and enables rapid feedback loops between AI predictions and experimental validation.
Lastly, implementing data governance policies is crucial for managing data access, sharing, and long-term preservation. These policies should define roles and responsibilities for data stewardship, establish guidelines for data sharing within and outside the organization, and ensure compliance with relevant regulations and ethical standards.
Ethical Considerations in AI-Driven Materials Research
The integration of AI-predicted catalysts into experimental validation pipelines raises significant ethical considerations that must be carefully addressed. As AI-driven materials research advances, it is crucial to ensure that the development and application of these technologies align with ethical principles and societal values.
One primary concern is the potential for bias in AI algorithms used to predict catalysts. These biases may stem from incomplete or skewed training data, leading to predictions that favor certain types of catalysts or overlook promising candidates from underrepresented categories. This could result in a narrowing of research focus and missed opportunities for breakthrough discoveries. To mitigate this risk, researchers must prioritize the development of diverse and representative datasets, as well as implement rigorous validation processes to identify and correct potential biases.
The use of AI in catalyst prediction also raises questions about transparency and interpretability. As AI models become more complex, it becomes increasingly challenging for researchers to understand and explain the reasoning behind specific predictions. This lack of transparency can hinder scientific progress and make it difficult to build trust in AI-driven research methodologies. Efforts should be made to develop explainable AI models and to establish clear protocols for documenting and communicating the decision-making processes of AI systems used in materials research.
Another ethical consideration is the potential impact on the scientific workforce. As AI systems become more sophisticated in predicting catalysts and designing experiments, there is a risk of reducing the role of human researchers in certain aspects of materials science. This could lead to job displacement or a shift in required skills for scientists in the field. It is essential to consider the long-term implications of AI integration on the scientific community and to develop strategies for reskilling and upskilling researchers to work effectively alongside AI systems.
Data privacy and security also present ethical challenges in AI-driven materials research. The development of accurate catalyst prediction models often requires large amounts of experimental data, which may include proprietary information from multiple sources. Ensuring the proper handling, storage, and protection of this data is crucial to maintain trust among collaborators and prevent unauthorized access or misuse. Researchers and institutions must implement robust data governance frameworks and adhere to strict ethical guidelines for data sharing and usage.
Lastly, the potential dual-use nature of AI-predicted catalysts must be considered. While many catalysts have beneficial applications in areas such as clean energy and environmental remediation, some may also have potential for harmful uses, such as in the production of chemical weapons or illicit substances. Researchers and institutions must establish clear ethical guidelines and oversight mechanisms to ensure that AI-driven catalyst discovery is directed towards beneficial applications and that appropriate safeguards are in place to prevent misuse.
One primary concern is the potential for bias in AI algorithms used to predict catalysts. These biases may stem from incomplete or skewed training data, leading to predictions that favor certain types of catalysts or overlook promising candidates from underrepresented categories. This could result in a narrowing of research focus and missed opportunities for breakthrough discoveries. To mitigate this risk, researchers must prioritize the development of diverse and representative datasets, as well as implement rigorous validation processes to identify and correct potential biases.
The use of AI in catalyst prediction also raises questions about transparency and interpretability. As AI models become more complex, it becomes increasingly challenging for researchers to understand and explain the reasoning behind specific predictions. This lack of transparency can hinder scientific progress and make it difficult to build trust in AI-driven research methodologies. Efforts should be made to develop explainable AI models and to establish clear protocols for documenting and communicating the decision-making processes of AI systems used in materials research.
Another ethical consideration is the potential impact on the scientific workforce. As AI systems become more sophisticated in predicting catalysts and designing experiments, there is a risk of reducing the role of human researchers in certain aspects of materials science. This could lead to job displacement or a shift in required skills for scientists in the field. It is essential to consider the long-term implications of AI integration on the scientific community and to develop strategies for reskilling and upskilling researchers to work effectively alongside AI systems.
Data privacy and security also present ethical challenges in AI-driven materials research. The development of accurate catalyst prediction models often requires large amounts of experimental data, which may include proprietary information from multiple sources. Ensuring the proper handling, storage, and protection of this data is crucial to maintain trust among collaborators and prevent unauthorized access or misuse. Researchers and institutions must implement robust data governance frameworks and adhere to strict ethical guidelines for data sharing and usage.
Lastly, the potential dual-use nature of AI-predicted catalysts must be considered. While many catalysts have beneficial applications in areas such as clean energy and environmental remediation, some may also have potential for harmful uses, such as in the production of chemical weapons or illicit substances. Researchers and institutions must establish clear ethical guidelines and oversight mechanisms to ensure that AI-driven catalyst discovery is directed towards beneficial applications and that appropriate safeguards are in place to prevent misuse.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!