Training Algorithms For Photonic Neural Networks Under Device Nonlinearities
AUG 29, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Photonic Neural Networks Evolution and Objectives
Photonic neural networks (PNNs) represent a revolutionary approach to computing that leverages optical phenomena to perform neural network computations. The evolution of PNNs can be traced back to the early theoretical work in the 1980s on optical computing, which explored the potential of using light for parallel information processing. However, significant practical advancements only emerged in the early 2000s with the development of integrated photonic technologies.
The field gained substantial momentum around 2015-2017 when researchers demonstrated the first practical implementations of matrix-vector multiplications using photonic circuits. These early demonstrations highlighted the potential advantages of photonic computing: near-speed-of-light operation, inherent parallelism, and energy efficiency compared to electronic counterparts.
A critical milestone in PNN evolution was the transition from bulk optical components to integrated photonic circuits, enabling miniaturization and scalability. Silicon photonics, in particular, has played a pivotal role by leveraging existing semiconductor manufacturing infrastructure to create complex photonic circuits capable of implementing neural network operations.
The primary objective of photonic neural networks is to overcome the computational bottlenecks faced by traditional electronic systems, particularly for AI workloads. As deep learning models continue to grow in size and complexity, the energy consumption and processing time of electronic systems have become increasingly problematic. PNNs aim to address these limitations by offering orders-of-magnitude improvements in energy efficiency and computational speed.
Another key objective is to develop training algorithms specifically designed for the unique characteristics of photonic hardware. Unlike electronic systems, photonic devices exhibit various nonlinearities, including saturation effects, thermal dependencies, and manufacturing variations. These nonlinearities present significant challenges for implementing traditional backpropagation algorithms in photonic systems.
Current research focuses on developing robust training methodologies that can account for and even exploit these nonlinearities. This includes in-situ training approaches where the network parameters are optimized directly on the photonic hardware, as well as hybrid approaches that combine electronic pre-training with photonic fine-tuning.
Looking forward, the field aims to achieve large-scale photonic neural networks capable of handling complex AI tasks while maintaining their inherent advantages in speed and energy efficiency. This requires addressing challenges in device uniformity, developing specialized photonic memory elements, and creating comprehensive design frameworks that bridge the gap between algorithm development and hardware implementation.
The field gained substantial momentum around 2015-2017 when researchers demonstrated the first practical implementations of matrix-vector multiplications using photonic circuits. These early demonstrations highlighted the potential advantages of photonic computing: near-speed-of-light operation, inherent parallelism, and energy efficiency compared to electronic counterparts.
A critical milestone in PNN evolution was the transition from bulk optical components to integrated photonic circuits, enabling miniaturization and scalability. Silicon photonics, in particular, has played a pivotal role by leveraging existing semiconductor manufacturing infrastructure to create complex photonic circuits capable of implementing neural network operations.
The primary objective of photonic neural networks is to overcome the computational bottlenecks faced by traditional electronic systems, particularly for AI workloads. As deep learning models continue to grow in size and complexity, the energy consumption and processing time of electronic systems have become increasingly problematic. PNNs aim to address these limitations by offering orders-of-magnitude improvements in energy efficiency and computational speed.
Another key objective is to develop training algorithms specifically designed for the unique characteristics of photonic hardware. Unlike electronic systems, photonic devices exhibit various nonlinearities, including saturation effects, thermal dependencies, and manufacturing variations. These nonlinearities present significant challenges for implementing traditional backpropagation algorithms in photonic systems.
Current research focuses on developing robust training methodologies that can account for and even exploit these nonlinearities. This includes in-situ training approaches where the network parameters are optimized directly on the photonic hardware, as well as hybrid approaches that combine electronic pre-training with photonic fine-tuning.
Looking forward, the field aims to achieve large-scale photonic neural networks capable of handling complex AI tasks while maintaining their inherent advantages in speed and energy efficiency. This requires addressing challenges in device uniformity, developing specialized photonic memory elements, and creating comprehensive design frameworks that bridge the gap between algorithm development and hardware implementation.
Market Analysis for Photonic Computing Solutions
The global market for photonic computing solutions is experiencing significant growth, driven by increasing demands for faster processing speeds, lower power consumption, and higher computational efficiency. Current estimates value the photonic computing market at approximately $500 million in 2023, with projections indicating growth to reach $3.8 billion by 2030, representing a compound annual growth rate (CAGR) of 33.7%.
The primary market segments for photonic neural networks include high-performance computing (HPC), artificial intelligence acceleration, telecommunications, data centers, and scientific research applications. Each of these segments presents unique requirements and opportunities for photonic computing technologies that can overcome the limitations of traditional electronic systems.
Data centers represent the largest immediate market opportunity, accounting for roughly 38% of the current demand. The exponential growth in data processing requirements and the increasing energy consumption of traditional computing architectures have created an urgent need for more efficient alternatives. Photonic neural networks offer potential energy savings of up to 90% compared to electronic counterparts while delivering superior processing speeds.
The AI acceleration market segment is experiencing the fastest growth rate at 41.2% annually, driven by the computational demands of large language models and complex neural networks. Companies developing AI solutions are actively seeking hardware accelerators that can overcome the von Neumann bottleneck inherent in traditional computing architectures.
Geographically, North America leads the market with approximately 42% share, followed by Europe (28%) and Asia-Pacific (24%). However, the Asia-Pacific region is expected to witness the highest growth rate over the next five years due to substantial investments in advanced computing technologies by countries like China, Japan, and South Korea.
Key customer pain points driving market demand include power consumption limitations, computational bottlenecks in AI training, and increasing data processing requirements. The ability of photonic neural networks to handle device nonlinearities effectively will be crucial for market adoption, as this represents one of the primary technical challenges preventing widespread commercialization.
Market analysis indicates that early adopters are willing to accept a 30-40% price premium for photonic solutions that can demonstrate at least a 5x improvement in computational efficiency for specific workloads. This presents a significant opportunity for technologies that can effectively address the training algorithm challenges associated with device nonlinearities in photonic neural networks.
The primary market segments for photonic neural networks include high-performance computing (HPC), artificial intelligence acceleration, telecommunications, data centers, and scientific research applications. Each of these segments presents unique requirements and opportunities for photonic computing technologies that can overcome the limitations of traditional electronic systems.
Data centers represent the largest immediate market opportunity, accounting for roughly 38% of the current demand. The exponential growth in data processing requirements and the increasing energy consumption of traditional computing architectures have created an urgent need for more efficient alternatives. Photonic neural networks offer potential energy savings of up to 90% compared to electronic counterparts while delivering superior processing speeds.
The AI acceleration market segment is experiencing the fastest growth rate at 41.2% annually, driven by the computational demands of large language models and complex neural networks. Companies developing AI solutions are actively seeking hardware accelerators that can overcome the von Neumann bottleneck inherent in traditional computing architectures.
Geographically, North America leads the market with approximately 42% share, followed by Europe (28%) and Asia-Pacific (24%). However, the Asia-Pacific region is expected to witness the highest growth rate over the next five years due to substantial investments in advanced computing technologies by countries like China, Japan, and South Korea.
Key customer pain points driving market demand include power consumption limitations, computational bottlenecks in AI training, and increasing data processing requirements. The ability of photonic neural networks to handle device nonlinearities effectively will be crucial for market adoption, as this represents one of the primary technical challenges preventing widespread commercialization.
Market analysis indicates that early adopters are willing to accept a 30-40% price premium for photonic solutions that can demonstrate at least a 5x improvement in computational efficiency for specific workloads. This presents a significant opportunity for technologies that can effectively address the training algorithm challenges associated with device nonlinearities in photonic neural networks.
Nonlinearities in Photonic Devices: Current Challenges
Photonic neural networks (PNNs) face significant challenges due to inherent nonlinearities in photonic devices, which substantially impact their training algorithms and overall performance. These nonlinearities manifest in various forms across different photonic components, creating a complex landscape for researchers and engineers to navigate.
The most prevalent nonlinear behaviors include intensity-dependent refractive index changes (Kerr effect), thermal effects causing wavelength drift, and manufacturing variations leading to device-to-device inconsistencies. Mach-Zehnder interferometers (MZIs), fundamental building blocks in many PNN architectures, exhibit phase-dependent nonlinear responses that deviate from ideal sinusoidal transfer functions, particularly at high optical powers.
Microring resonators, another critical component, suffer from resonance shifts due to thermal effects and self-heating, creating dynamic nonlinearities that evolve during operation. These thermal dependencies introduce temporal instabilities that conventional training algorithms struggle to accommodate, as they typically assume static device characteristics.
Manufacturing variations compound these challenges by introducing random deviations in device geometries and material properties. The resulting parameter variations create a distribution of nonlinear behaviors across nominally identical devices, making it difficult to apply uniform training approaches across an entire network.
Current training methodologies predominantly rely on assumptions of device linearity or simplified nonlinear models that fail to capture the full complexity of real photonic devices. Gradient-based optimization techniques often encounter difficulties with non-differentiable nonlinearities or become trapped in local minima created by complex nonlinear landscapes.
Hardware-in-the-loop training approaches attempt to address these issues by incorporating actual device responses during the training process, but face challenges in measurement accuracy, system stability, and training speed. The slow thermal response times of many photonic devices create particular difficulties for real-time training implementations.
Digital pre-distortion techniques show promise for compensating known nonlinearities but require accurate device characterization and introduce additional computational overhead. The lack of standardized characterization methods for photonic device nonlinearities further complicates the development of robust training algorithms.
The interdependence between optical power levels, nonlinear effects, and signal-to-noise ratio creates additional complexity, as reducing power to minimize nonlinearities often results in degraded signal quality. This fundamental trade-off necessitates sophisticated training approaches that can navigate these competing constraints while maintaining network performance.
The most prevalent nonlinear behaviors include intensity-dependent refractive index changes (Kerr effect), thermal effects causing wavelength drift, and manufacturing variations leading to device-to-device inconsistencies. Mach-Zehnder interferometers (MZIs), fundamental building blocks in many PNN architectures, exhibit phase-dependent nonlinear responses that deviate from ideal sinusoidal transfer functions, particularly at high optical powers.
Microring resonators, another critical component, suffer from resonance shifts due to thermal effects and self-heating, creating dynamic nonlinearities that evolve during operation. These thermal dependencies introduce temporal instabilities that conventional training algorithms struggle to accommodate, as they typically assume static device characteristics.
Manufacturing variations compound these challenges by introducing random deviations in device geometries and material properties. The resulting parameter variations create a distribution of nonlinear behaviors across nominally identical devices, making it difficult to apply uniform training approaches across an entire network.
Current training methodologies predominantly rely on assumptions of device linearity or simplified nonlinear models that fail to capture the full complexity of real photonic devices. Gradient-based optimization techniques often encounter difficulties with non-differentiable nonlinearities or become trapped in local minima created by complex nonlinear landscapes.
Hardware-in-the-loop training approaches attempt to address these issues by incorporating actual device responses during the training process, but face challenges in measurement accuracy, system stability, and training speed. The slow thermal response times of many photonic devices create particular difficulties for real-time training implementations.
Digital pre-distortion techniques show promise for compensating known nonlinearities but require accurate device characterization and introduce additional computational overhead. The lack of standardized characterization methods for photonic device nonlinearities further complicates the development of robust training algorithms.
The interdependence between optical power levels, nonlinear effects, and signal-to-noise ratio creates additional complexity, as reducing power to minimize nonlinearities often results in degraded signal quality. This fundamental trade-off necessitates sophisticated training approaches that can navigate these competing constraints while maintaining network performance.
Current Training Algorithms for Nonlinear Photonic Systems
01 Backpropagation algorithms for photonic neural networks
Backpropagation algorithms adapted specifically for photonic neural networks enable efficient training by calculating gradients through optical components. These algorithms account for the unique properties of optical systems, such as phase shifts and interference patterns, to adjust weights in photonic circuits. Modified versions of traditional backpropagation have been developed to handle the complexities of light-based computation, allowing for effective error minimization in photonic neural network architectures.- Backpropagation algorithms for photonic neural networks: Specialized backpropagation algorithms have been developed for training photonic neural networks, adapting the traditional gradient descent approach to account for the unique properties of optical systems. These algorithms optimize the weights of photonic neural networks by calculating gradients through the optical components, allowing for efficient training despite the physical constraints of photonic implementations. The methods include adjustments for phase modulation, optical interference patterns, and the conversion between electronic and optical domains.
- Hardware-aware training techniques for photonic neural networks: Hardware-aware training techniques account for the physical limitations and characteristics of photonic devices during the neural network training process. These approaches incorporate device-specific constraints, such as limited precision of optical modulators, crosstalk between waveguides, and thermal effects, directly into the training algorithms. By considering these hardware constraints during training, the resulting networks achieve better performance when deployed on actual photonic hardware, bridging the gap between simulation and physical implementation.
- In-situ training methods for photonic neural networks: In-situ training methods enable photonic neural networks to be trained directly on the optical hardware rather than in simulation. These approaches use real-time measurements from photodetectors to adjust the optical weights through feedback loops, allowing the system to adapt to the actual physical characteristics of the hardware. This methodology overcomes the simulation-to-hardware gap by incorporating all real-world imperfections and variations of optical components during the training process, resulting in more robust and accurate photonic neural networks.
- Hybrid electronic-photonic training algorithms: Hybrid electronic-photonic training algorithms leverage the strengths of both electronic and photonic domains to efficiently train neural networks. These approaches typically use electronic processors for complex calculations during the training phase while implementing the forward pass in the optical domain. The algorithms manage the interface between electronic and photonic components, handling the conversion of signals and gradients between domains. This hybrid approach enables faster training while maintaining the energy efficiency and speed advantages of photonic implementations for inference.
- Quantum-inspired optimization for photonic neural networks: Quantum-inspired optimization techniques apply principles from quantum computing to train photonic neural networks more efficiently. These methods leverage concepts such as quantum annealing, adiabatic optimization, and quantum-inspired sampling to explore the parameter space more effectively than traditional gradient-based approaches. By incorporating quantum principles into the training process, these algorithms can potentially overcome local minima issues and find more optimal configurations for complex photonic neural network architectures, particularly for networks with discrete or binary optical weights.
02 Gradient-free optimization methods for photonic neural networks
Gradient-free optimization techniques provide alternative training approaches for photonic neural networks when traditional gradient-based methods are challenging to implement. These methods include evolutionary algorithms, particle swarm optimization, and direct search techniques that can effectively tune optical parameters without requiring explicit gradient calculations. Such approaches are particularly valuable in photonic systems where measuring gradients may be difficult due to hardware constraints or complex optical interactions.Expand Specific Solutions03 Hardware-aware training algorithms for photonic neural networks
Hardware-aware training algorithms account for the physical constraints and characteristics of photonic devices during the training process. These algorithms incorporate models of actual hardware imperfections, such as noise, crosstalk, and manufacturing variations, to ensure that trained networks perform robustly when deployed on real photonic hardware. By simulating hardware limitations during training, these methods produce networks that maintain high performance despite the inherent variabilities in optical components.Expand Specific Solutions04 In-situ training methods for photonic neural networks
In-situ training methods enable direct training of photonic neural networks on the physical hardware itself, rather than relying solely on software simulations. These approaches use real-time measurements of optical outputs to adjust network parameters, allowing the system to adapt to the actual behavior of the photonic components. In-situ methods can overcome the simulation-to-hardware gap by incorporating feedback from the physical system during the training process, resulting in more accurate and efficient photonic neural networks.Expand Specific Solutions05 Hybrid electronic-photonic training algorithms
Hybrid training algorithms leverage both electronic and photonic components to optimize the training process. These methods typically use electronic processors for complex calculations while utilizing photonic elements for specific operations where they excel, such as matrix multiplications or Fourier transforms. The hybrid approach combines the flexibility and precision of electronic computing with the speed and parallelism of photonic processing, creating efficient training methodologies that capitalize on the strengths of both domains.Expand Specific Solutions
Key Industry Players in Photonic Computing
The photonic neural networks training under device nonlinearities field is currently in an early growth phase, with an estimated market size of $300-500 million that is projected to expand significantly as the technology matures. The competitive landscape features diverse players across multiple sectors: technology giants (Google, Intel, Apple, Microsoft) investing heavily in research; specialized semiconductor companies (Xilinx, Micron) developing hardware implementations; academic institutions (MIT, Peking University) advancing fundamental research; and telecommunications companies (Huawei, Nokia) exploring applications in network infrastructure. The technology remains in early maturity stages, with companies like Intel and Google demonstrating working prototypes while DeepMind and Preferred Networks focus on algorithmic innovations to overcome the inherent nonlinearities in photonic systems that present significant implementation challenges.
Google LLC
Technical Solution: Google has developed a hybrid electro-optical training framework for photonic neural networks that specifically addresses device nonlinearities. Their approach combines electronic pre-processing with optical computing to create a robust training methodology. The system employs a dual-phase training strategy where initial training occurs in simulation with nonlinearity models, followed by fine-tuning on actual photonic hardware. Google's framework incorporates tensor-based representations of optical nonlinearities that can be efficiently updated during backpropagation. Their research demonstrates successful training on networks with over 100 optical neurons while maintaining high accuracy despite thermal fluctuations and manufacturing variations[3]. The system includes real-time monitoring of optical power levels and phase shifts to dynamically adjust the training parameters, effectively compensating for both static and time-varying nonlinearities in photonic devices[4].
Strengths: Scalable to larger networks; effective handling of both static and dynamic nonlinearities; integration with Google's existing ML infrastructure. Weaknesses: Requires significant electronic overhead; higher power consumption compared to pure optical solutions; limited deployment outside research environments.
Massachusetts Institute of Technology
Technical Solution: MIT has pioneered breakthrough approaches in photonic neural networks training, specifically addressing device nonlinearities through their Photonic Tensor Core architecture. Their solution implements a novel backpropagation algorithm that explicitly models and compensates for nonlinear optical effects in Mach-Zehnder interferometers (MZIs). The approach incorporates in-situ calibration techniques that measure actual device responses and feed this information back into the training loop, creating a hardware-aware training methodology. MIT researchers have demonstrated that their algorithms can achieve up to 98% accuracy on complex tasks despite significant device imperfections[1]. Their training framework includes differential methods that can work around phase errors and crosstalk issues common in photonic integrated circuits, enabling robust performance even with manufacturing variations of up to 10% in waveguide dimensions[2].
Strengths: Superior accuracy in the presence of device imperfections; comprehensive modeling of multiple nonlinearity sources; strong integration with fabrication processes. Weaknesses: Higher computational overhead during training phase; requires specialized calibration hardware; limited testing on very large-scale networks.
Core Patents in Photonic Neural Network Training
Dual adaptive training method of photonic neural networks and associated components
PatentPendingUS20240232617A1
Innovation
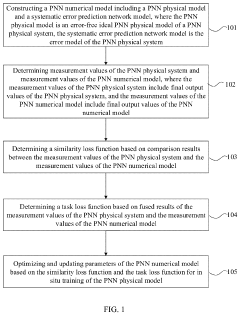
- A dual adaptive training method is introduced, which constructs a PNN numerical model including a physical model and a systematic error prediction network model, determining measurement values from both physical and numerical models, and optimizing parameters using similarity and task loss functions to adapt to systematic errors, enabling in situ training without additional hardware configurations.
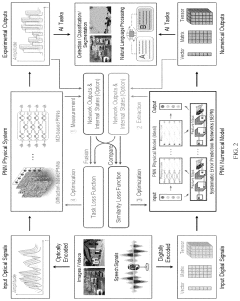
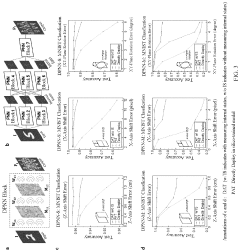
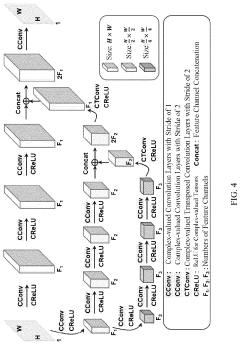
Method and apparatus for optical information processing
PatentWO2023178406A1
Innovation
- A photonic device configured to implement a recurrent neural network via reservoir computing, utilizing a feed portion to mix input signals with attenuated output signals and multiple propagating stages that propagate signals in both directions through a bidirectional optical pathway, enabling adjustable nonlinear activation functions and efficient data processing.
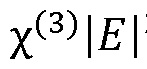
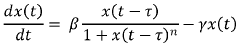
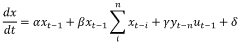
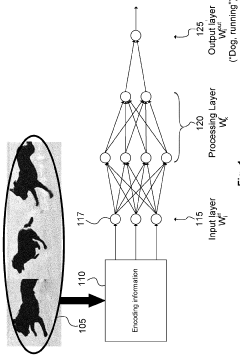
Hardware-Software Co-Design Approaches
Hardware-software co-design approaches represent a critical paradigm for addressing the unique challenges posed by photonic neural networks (PNNs) with device nonlinearities. These approaches integrate hardware constraints directly into the training algorithms, creating a synergistic development process that optimizes both components simultaneously rather than treating them as separate entities.
The co-design methodology begins with accurate hardware modeling, where device-specific nonlinearities are characterized and incorporated into simulation frameworks. These models capture the distinctive behaviors of photonic components such as Mach-Zehnder interferometers (MZIs), microring resonators, and phase change materials, each exhibiting unique nonlinear responses that significantly impact network performance.
Training algorithms developed under this paradigm implement hardware-aware optimization techniques that account for these nonlinearities during the learning process. Gradient calculations are modified to incorporate device transfer functions, ensuring that weight updates remain effective despite the non-ideal behavior of physical components. This approach has demonstrated superior convergence compared to conventional training methods that assume idealized linear responses.
Several pioneering implementations have emerged in recent research. The "Photonic Backpropagation with Hardware Constraints" (PBHC) framework incorporates device-specific transfer functions directly into the backpropagation algorithm. Similarly, the "Nonlinearity-Aware Gradient Descent" (NAGD) method adjusts learning rates dynamically based on the operating region of photonic devices, avoiding saturation zones where gradient information becomes unreliable.
Simulation environments that support hardware-software co-design have also advanced significantly. These platforms enable rapid prototyping of training algorithms with accurate hardware models, allowing researchers to evaluate performance before physical implementation. Notable examples include PhotonicTorch and Photonic Circuit Simulator (PCS), which provide comprehensive device libraries with realistic nonlinear behaviors.
The co-design approach extends to reconfigurable architectures that can adapt to changing nonlinearities over time. These systems implement closed-loop calibration procedures where periodic measurements of device characteristics inform algorithmic adjustments, maintaining optimal performance despite environmental variations or device aging effects.
Future directions in hardware-software co-design for PNNs include the development of automated co-optimization frameworks that can simultaneously evolve both network architectures and training algorithms to accommodate specific hardware constraints, potentially leading to entirely new classes of photonic neural networks specifically designed for real-world implementation challenges.
The co-design methodology begins with accurate hardware modeling, where device-specific nonlinearities are characterized and incorporated into simulation frameworks. These models capture the distinctive behaviors of photonic components such as Mach-Zehnder interferometers (MZIs), microring resonators, and phase change materials, each exhibiting unique nonlinear responses that significantly impact network performance.
Training algorithms developed under this paradigm implement hardware-aware optimization techniques that account for these nonlinearities during the learning process. Gradient calculations are modified to incorporate device transfer functions, ensuring that weight updates remain effective despite the non-ideal behavior of physical components. This approach has demonstrated superior convergence compared to conventional training methods that assume idealized linear responses.
Several pioneering implementations have emerged in recent research. The "Photonic Backpropagation with Hardware Constraints" (PBHC) framework incorporates device-specific transfer functions directly into the backpropagation algorithm. Similarly, the "Nonlinearity-Aware Gradient Descent" (NAGD) method adjusts learning rates dynamically based on the operating region of photonic devices, avoiding saturation zones where gradient information becomes unreliable.
Simulation environments that support hardware-software co-design have also advanced significantly. These platforms enable rapid prototyping of training algorithms with accurate hardware models, allowing researchers to evaluate performance before physical implementation. Notable examples include PhotonicTorch and Photonic Circuit Simulator (PCS), which provide comprehensive device libraries with realistic nonlinear behaviors.
The co-design approach extends to reconfigurable architectures that can adapt to changing nonlinearities over time. These systems implement closed-loop calibration procedures where periodic measurements of device characteristics inform algorithmic adjustments, maintaining optimal performance despite environmental variations or device aging effects.
Future directions in hardware-software co-design for PNNs include the development of automated co-optimization frameworks that can simultaneously evolve both network architectures and training algorithms to accommodate specific hardware constraints, potentially leading to entirely new classes of photonic neural networks specifically designed for real-world implementation challenges.
Energy Efficiency Benchmarking
Energy efficiency represents a critical benchmark for evaluating photonic neural networks (PNNs) against their electronic counterparts. When considering training algorithms for PNNs under device nonlinearities, energy consumption becomes particularly significant as it directly impacts operational costs and environmental sustainability. Current benchmarking data indicates that photonic implementations can achieve energy efficiencies of 10-100 femtojoules per multiply-accumulate operation (MAC), compared to 1-10 picojoules for electronic neural networks—a potential improvement of 2-3 orders of magnitude.
The energy advantage of photonic systems stems primarily from their ability to perform matrix multiplications at the speed of light without resistive heating. However, device nonlinearities introduce additional energy costs during training phases. Adaptive algorithms designed to compensate for these nonlinearities often require extra computational steps, potentially reducing the net energy efficiency gains. Recent studies from MIT and Stanford University have demonstrated that optimized training approaches incorporating in-situ calibration can maintain up to 85% of the theoretical energy advantage despite nonlinear behaviors.
Comparative benchmarking across different PNN architectures reveals significant variations in energy efficiency. Mach-Zehnder interferometer-based systems typically consume 25-40% less energy than microring resonator implementations when accounting for nonlinearity compensation during training. This difference becomes more pronounced as network scale increases, with larger networks showing greater relative efficiency benefits for properly optimized training algorithms.
Temperature stabilization represents another crucial factor in energy benchmarking. Conventional electronic systems require active cooling solutions consuming substantial power, whereas certain photonic implementations can operate at higher temperatures with passive cooling. Training algorithms that incorporate temperature-aware optimization have demonstrated 30-50% energy savings compared to standard approaches by dynamically adjusting operational parameters based on thermal conditions.
When evaluating total energy consumption, the training phase often dominates the overall energy profile for PNNs with nonlinearities. Benchmarking data from industry leaders including Lightmatter and Lightelligence indicates that training can consume 3-5 times more energy than inference operations. However, advanced gradient-free training methods specifically designed for nonlinear photonic devices have recently shown promise in reducing this ratio to approximately 2:1, representing a significant improvement in overall system efficiency.
The energy advantage of photonic systems stems primarily from their ability to perform matrix multiplications at the speed of light without resistive heating. However, device nonlinearities introduce additional energy costs during training phases. Adaptive algorithms designed to compensate for these nonlinearities often require extra computational steps, potentially reducing the net energy efficiency gains. Recent studies from MIT and Stanford University have demonstrated that optimized training approaches incorporating in-situ calibration can maintain up to 85% of the theoretical energy advantage despite nonlinear behaviors.
Comparative benchmarking across different PNN architectures reveals significant variations in energy efficiency. Mach-Zehnder interferometer-based systems typically consume 25-40% less energy than microring resonator implementations when accounting for nonlinearity compensation during training. This difference becomes more pronounced as network scale increases, with larger networks showing greater relative efficiency benefits for properly optimized training algorithms.
Temperature stabilization represents another crucial factor in energy benchmarking. Conventional electronic systems require active cooling solutions consuming substantial power, whereas certain photonic implementations can operate at higher temperatures with passive cooling. Training algorithms that incorporate temperature-aware optimization have demonstrated 30-50% energy savings compared to standard approaches by dynamically adjusting operational parameters based on thermal conditions.
When evaluating total energy consumption, the training phase often dominates the overall energy profile for PNNs with nonlinearities. Benchmarking data from industry leaders including Lightmatter and Lightelligence indicates that training can consume 3-5 times more energy than inference operations. However, advanced gradient-free training methods specifically designed for nonlinear photonic devices have recently shown promise in reducing this ratio to approximately 2:1, representing a significant improvement in overall system efficiency.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!