

Webpage crawling method and device
A web scraping, web page technology, applied in the field of search engines, can solve problems such as inability to update or download web resources, website server crashes, website response timeouts, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0119] See figure 1 , is a flow chart of the method for webpage crawling provided by the embodiment of the present invention, as shown in the figure, the method for webpage crawling provided by the embodiment of the present invention may include the following steps:
[0120] S110: Obtain a dynamic traffic quota value for web crawling on the target website;
[0121] In the process of crawling the web pages of the target website by the crawler program, in order to avoid unlimited crawling of the same website, which will affect the normal visit of the website, etc., it is usually necessary to crawl the crawler program on the target website. Fetching traffic or frequency is limited to a certain extent, and the dynamic traffic quota value is a restriction on the crawling traffic of the crawler program on the target website. The dynamic traffic quota value for web crawling on the target website can be understood as the traffic limit for crawling the same website within a unit of ti...
Embodiment 2
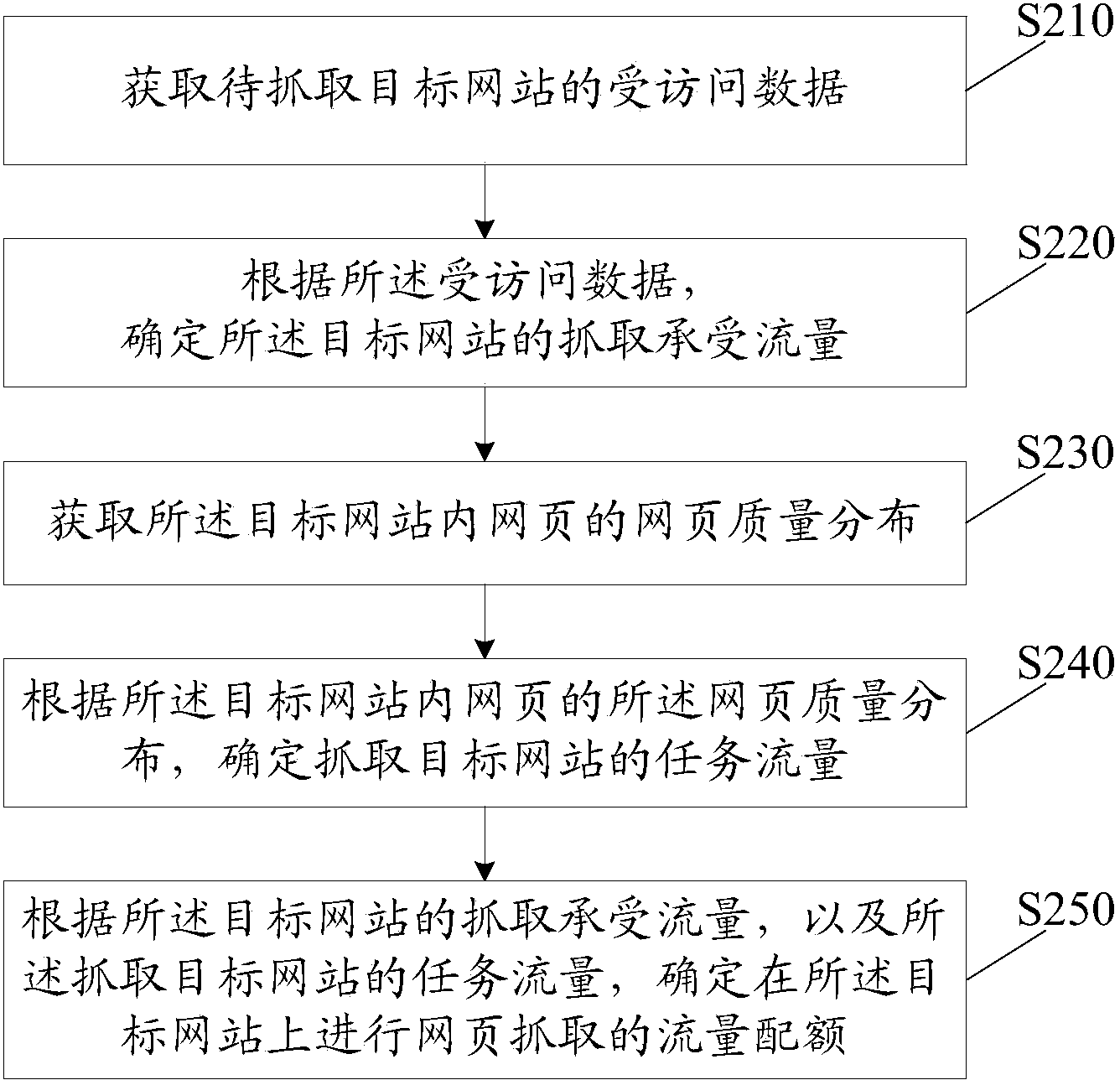
[0136] See figure 2 , is a flowchart of a method for determining a website crawling traffic quota provided in Embodiment 2 of the present invention. As shown in the figure, the method for determining a website crawling traffic quota provided in an embodiment of the present invention may include the following steps:
[0137] S210: Obtain the visited data of the target website to be captured;
[0138] Firstly, the visited data of the target website to be captured can be obtained. The visited data of the target website to be captured can be the click volume data of a certain day of the website, such as the parameter C in Table 1, and the visited data of the target website to be captured can be obtained. After accessing the data, the visit tolerance of the target website to be captured can be deduced based on the visited data of the target website.
[0139] The visited data of the target website can be obtained from various sources, for example, it can be obtained from published...
Embodiment 3
[0193] See image 3 , is a flowchart of a method for determining captured traffic provided in Embodiment 3 of the present invention. As shown in the figure, the method for determining captured traffic provided in this embodiment of the present invention may include the following steps.
[0194] S310: Obtain a task scaling factor according to the attribute characteristics of the target website;
[0195] S320: Based on the task scaling factor and the sum of webpage quality distributions in the target website, determine the task traffic of crawling the target website.
[0196] Wherein, the obtained task proportion factor can be the ratio of the number of webpages to be crawled to the total number of webpages in the target website; and / or, the ratio of the number of non-duplicated webpages in the target website percentage of the total number of pages. Obtaining the ratio of the number of webpages to be crawled in the target website to the total number of webpages in the target w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More