

Dictation and reading audio generation method, electronic equipment and storage medium
An electronic device and dictation technology, which is applied in the field of education, can solve the problems of low dictation accuracy, dictation errors, and inability to inspire students to associate new words, etc., and achieve the effects of narrowing the prompt range, improving emotion, and improving dictation accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
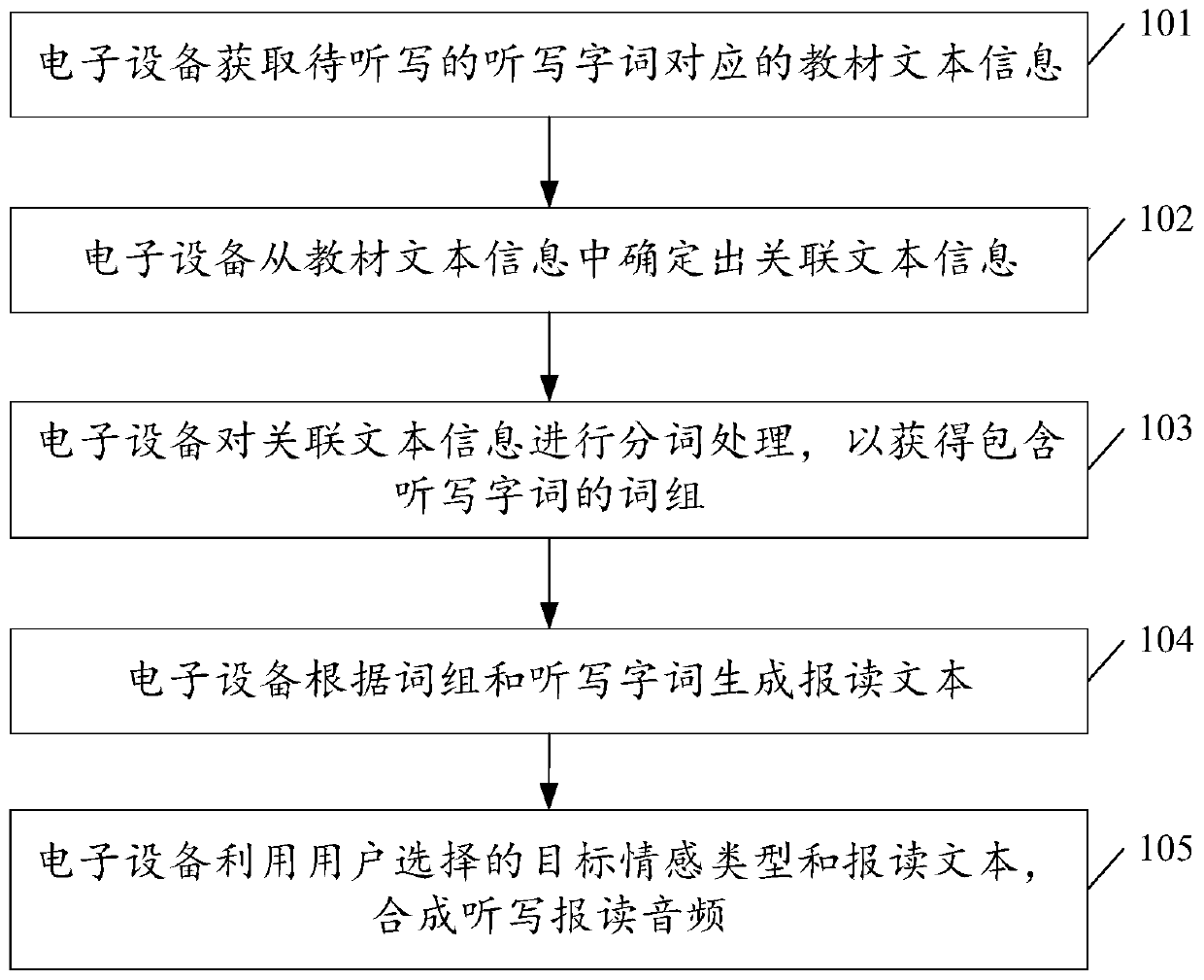
[0071] see figure 1 , figure 1 It is a schematic flowchart of a method for generating dictation reading audio disclosed by an embodiment of the present invention. Such as figure 1 As shown, the method for generating the dictation reading audio may include the following steps:
[0072] 101. The electronic device acquires textbook text information corresponding to a dictation word to be dictated.
[0073] In the embodiment of the present invention, the dictation words to be dictated include but are not limited to any one of Chinese new words, Chinese pinyin letters, English phrases, English words, English letters, English phonetic symbols, names and symbols of chemical elements, and music surnames. Content, the present invention is not specifically limited here. Among them, music roll call refers to content such as do, re, mi, fa, so, la, si, etc.
[0074] In the embodiment of the present invention, a dictation application program may be installed on the electronic device, ...
Embodiment 2
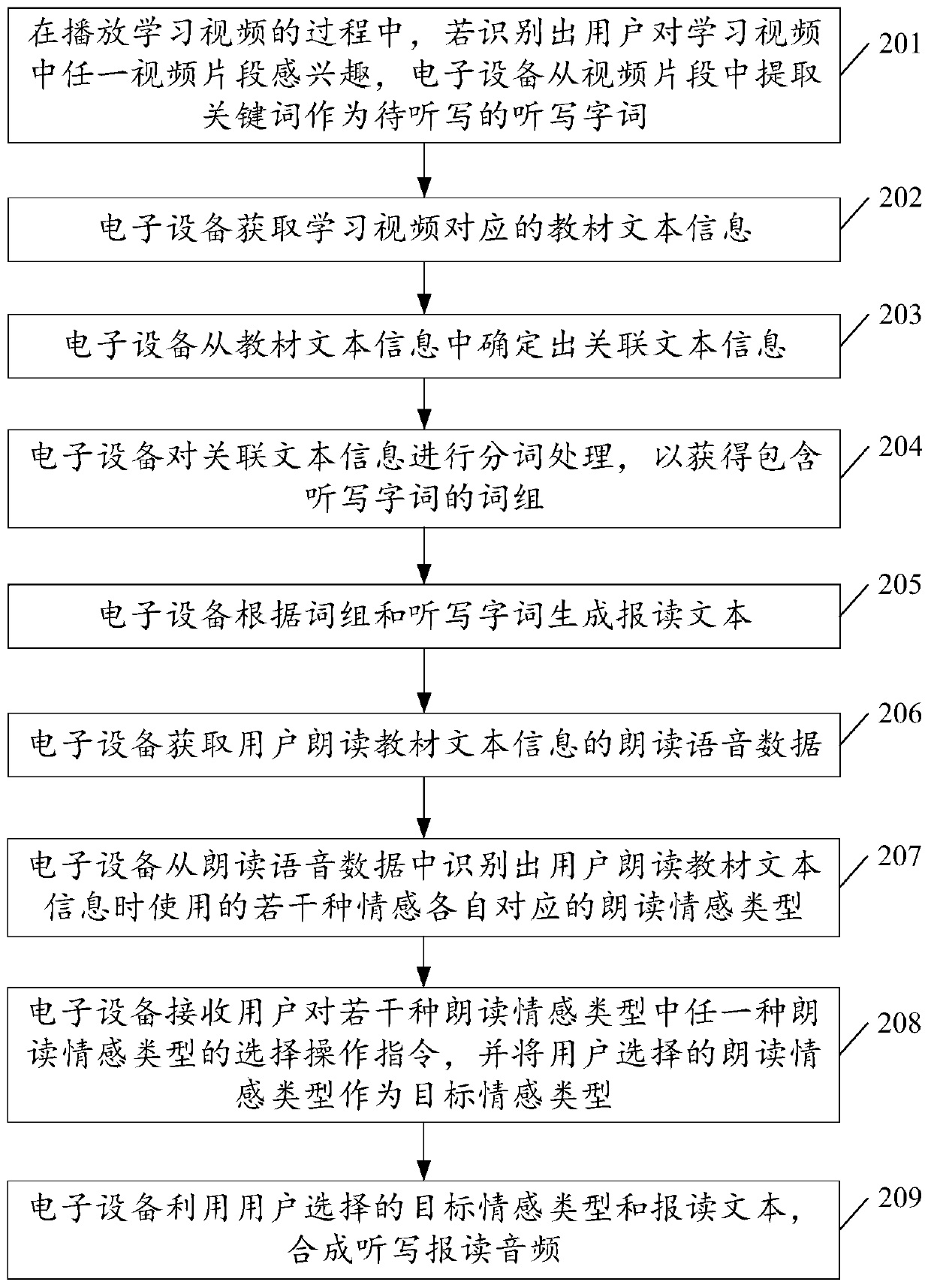
[0105] see figure 2 , figure 2 It is a schematic flowchart of another method for generating dictation reading audio disclosed in the embodiment of the present invention. Such as figure 2 As shown, the method for generating the dictation reading audio may include the following steps:
[0106] 201. In the process of playing the learning video, if it is recognized that the user is interested in any video segment in the learning video, the electronic device extracts keywords from the video segment as dictation words to be dictated.
[0107] In the embodiment of the present invention, the learning video can be pre-divided into multiple video clips according to time or content. Therefore, as an optional implementation, during the process of playing the learning video, the electronic device can transmit Sensing device and / or image sensing device, obtain the emotional factor of user watching any video segment; Analyze the emotional factor to identify the user's viewing emotion t...
Embodiment 3
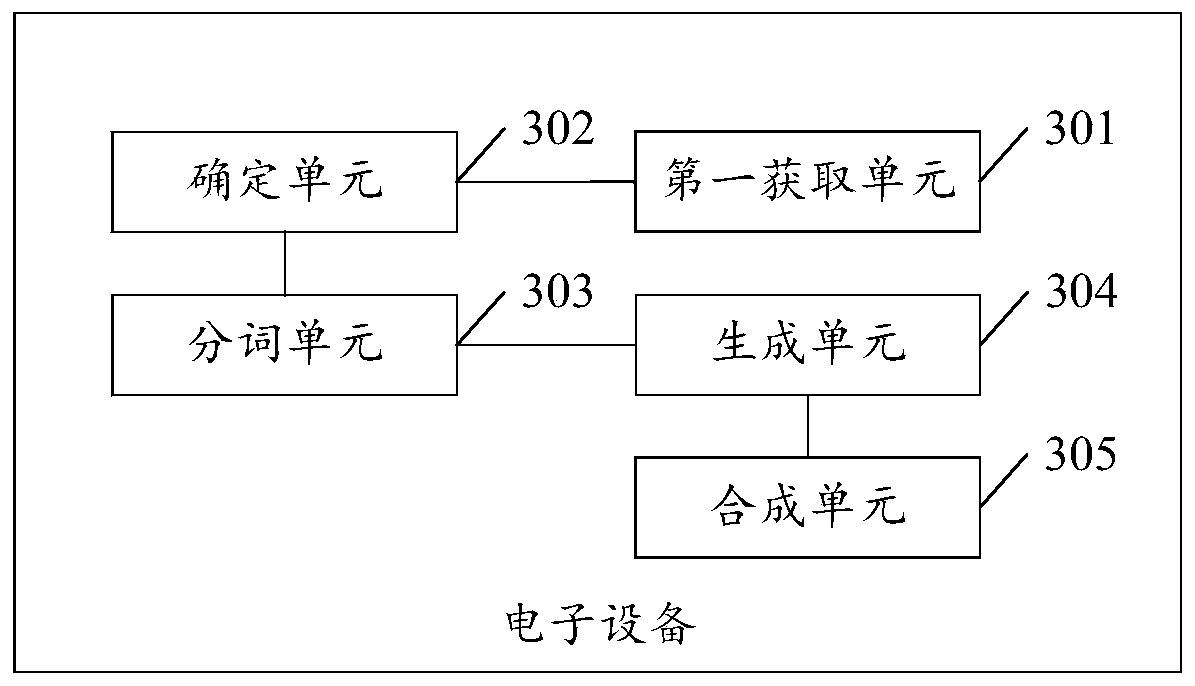
[0143] see image 3 , image 3 It is a schematic structural diagram of an electronic device disclosed in an embodiment of the present invention. Such as image 3 As shown, the electronic equipment may include:
[0144] The first acquiring unit 301 is configured to acquire teaching material text information corresponding to a dictated word to be dictated.
[0145] The determining unit 302 is configured to determine associated text information from the text information of teaching materials. The contextual information includes the dictated words and the contextual content of the dictated words.
[0146] The word segmentation unit 303 is configured to perform word segmentation processing on associated text information to obtain phrases containing dictated words.
[0147] The generation unit 304 is configured to generate the registration text according to the phrase and the dictated words.
[0148] The synthesizing unit 305 is configured to use the target emotion type select...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More