Model Compression And Deployment For On-Premise Materials Labs
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Model Compression Background and Objectives
Model compression has emerged as a critical technology in the field of artificial intelligence, particularly as machine learning models have grown increasingly complex and resource-intensive. The evolution of this technology can be traced back to the early 2010s when the deployment of neural networks on resource-constrained devices first became a significant challenge. Since then, the field has witnessed remarkable advancements, transitioning from simple pruning techniques to sophisticated quantization methods and knowledge distillation approaches.
In the context of materials science laboratories, model compression addresses the unique challenges of deploying sophisticated machine learning models in on-premise environments with limited computational resources. Materials labs often utilize complex models for molecular property prediction, crystal structure analysis, and materials discovery, which traditionally required substantial computing infrastructure. The technical objective of model compression in this domain is to enable the execution of these advanced models on standard laboratory hardware without sacrificing prediction accuracy or inference speed.
The trajectory of model compression techniques has been shaped by the increasing complexity of materials science models, which now frequently incorporate graph neural networks, transformer architectures, and multi-modal learning approaches. These models can contain millions or even billions of parameters, making them impractical for deployment in typical laboratory settings without significant compression.
Current technical goals in this field include achieving compression ratios of 10-100x while maintaining model accuracy within 1-2% of the original performance. Additionally, there is a focus on developing compression techniques specifically optimized for materials science applications, which often involve specialized data structures such as molecular graphs, crystallographic information files, and spectroscopic data.
Another critical objective is to create compression methodologies that can be applied with minimal domain expertise, allowing materials scientists to deploy models without requiring advanced knowledge of deep learning optimization techniques. This democratization of AI capabilities in materials science could significantly accelerate research and development cycles in fields ranging from battery technology to pharmaceutical discovery.
The intersection of model compression with hardware acceleration technologies, such as specialized NPUs (Neural Processing Units) and FPGAs (Field-Programmable Gate Arrays), represents another frontier in this domain. The goal is to develop compression techniques that can leverage these hardware accelerators while maintaining the flexibility required in research environments where experimental setups frequently change.
In the context of materials science laboratories, model compression addresses the unique challenges of deploying sophisticated machine learning models in on-premise environments with limited computational resources. Materials labs often utilize complex models for molecular property prediction, crystal structure analysis, and materials discovery, which traditionally required substantial computing infrastructure. The technical objective of model compression in this domain is to enable the execution of these advanced models on standard laboratory hardware without sacrificing prediction accuracy or inference speed.
The trajectory of model compression techniques has been shaped by the increasing complexity of materials science models, which now frequently incorporate graph neural networks, transformer architectures, and multi-modal learning approaches. These models can contain millions or even billions of parameters, making them impractical for deployment in typical laboratory settings without significant compression.
Current technical goals in this field include achieving compression ratios of 10-100x while maintaining model accuracy within 1-2% of the original performance. Additionally, there is a focus on developing compression techniques specifically optimized for materials science applications, which often involve specialized data structures such as molecular graphs, crystallographic information files, and spectroscopic data.
Another critical objective is to create compression methodologies that can be applied with minimal domain expertise, allowing materials scientists to deploy models without requiring advanced knowledge of deep learning optimization techniques. This democratization of AI capabilities in materials science could significantly accelerate research and development cycles in fields ranging from battery technology to pharmaceutical discovery.
The intersection of model compression with hardware acceleration technologies, such as specialized NPUs (Neural Processing Units) and FPGAs (Field-Programmable Gate Arrays), represents another frontier in this domain. The goal is to develop compression techniques that can leverage these hardware accelerators while maintaining the flexibility required in research environments where experimental setups frequently change.
Market Analysis for On-Premise ML Solutions
The on-premise machine learning solutions market for materials science laboratories is experiencing significant growth, driven by increasing demands for data privacy, reduced latency, and specialized computational capabilities. Current market estimates value this segment at approximately $2.3 billion, with projections indicating a compound annual growth rate of 18-22% over the next five years. This growth trajectory significantly outpaces the broader enterprise AI market, reflecting the specialized needs of materials research facilities.
Materials laboratories face unique challenges that make on-premise ML solutions particularly attractive. These facilities often work with proprietary formulations and sensitive intellectual property that cannot risk exposure through cloud transmission. Additionally, many materials testing procedures generate massive datasets from instruments like spectroscopes, electron microscopes, and X-ray diffraction equipment that would be impractical to continuously upload to cloud services.
Market segmentation reveals three primary customer categories: academic research institutions (comprising about 35% of the market), industrial R&D laboratories (45%), and government research facilities (20%). Industrial laboratories, particularly in pharmaceuticals, advanced materials, and semiconductor sectors, demonstrate the highest willingness to invest in sophisticated on-premise ML infrastructure, with average implementation budgets ranging from $250,000 to $1.2 million.
Geographical analysis shows North America leading adoption with approximately 42% market share, followed by Europe (28%), Asia-Pacific (25%), and other regions (5%). However, the Asia-Pacific region is experiencing the fastest growth rate, particularly in countries with strong materials manufacturing sectors like China, Japan, and South Korea.
Key market drivers include increasing complexity of materials research requiring advanced computational methods, growing concerns about intellectual property protection, and the expanding capabilities of edge computing hardware. The integration of ML with laboratory automation systems represents another significant growth vector, as materials labs seek end-to-end solutions that connect experimental design, execution, and analysis.
Customer pain points center around deployment complexity, model optimization for specialized hardware, integration with existing laboratory information management systems (LIMS), and the technical expertise required for maintenance. This creates substantial opportunities for solutions that emphasize ease of deployment, specialized model compression techniques for materials science applications, and robust technical support services.
The competitive landscape features both established scientific computing companies expanding into ML deployment tools and specialized startups focusing exclusively on on-premise AI for scientific applications. Strategic partnerships between hardware manufacturers, ML framework developers, and scientific instrument companies are increasingly common, creating integrated ecosystems that address the full workflow of materials discovery and characterization.
Materials laboratories face unique challenges that make on-premise ML solutions particularly attractive. These facilities often work with proprietary formulations and sensitive intellectual property that cannot risk exposure through cloud transmission. Additionally, many materials testing procedures generate massive datasets from instruments like spectroscopes, electron microscopes, and X-ray diffraction equipment that would be impractical to continuously upload to cloud services.
Market segmentation reveals three primary customer categories: academic research institutions (comprising about 35% of the market), industrial R&D laboratories (45%), and government research facilities (20%). Industrial laboratories, particularly in pharmaceuticals, advanced materials, and semiconductor sectors, demonstrate the highest willingness to invest in sophisticated on-premise ML infrastructure, with average implementation budgets ranging from $250,000 to $1.2 million.
Geographical analysis shows North America leading adoption with approximately 42% market share, followed by Europe (28%), Asia-Pacific (25%), and other regions (5%). However, the Asia-Pacific region is experiencing the fastest growth rate, particularly in countries with strong materials manufacturing sectors like China, Japan, and South Korea.
Key market drivers include increasing complexity of materials research requiring advanced computational methods, growing concerns about intellectual property protection, and the expanding capabilities of edge computing hardware. The integration of ML with laboratory automation systems represents another significant growth vector, as materials labs seek end-to-end solutions that connect experimental design, execution, and analysis.
Customer pain points center around deployment complexity, model optimization for specialized hardware, integration with existing laboratory information management systems (LIMS), and the technical expertise required for maintenance. This creates substantial opportunities for solutions that emphasize ease of deployment, specialized model compression techniques for materials science applications, and robust technical support services.
The competitive landscape features both established scientific computing companies expanding into ML deployment tools and specialized startups focusing exclusively on on-premise AI for scientific applications. Strategic partnerships between hardware manufacturers, ML framework developers, and scientific instrument companies are increasingly common, creating integrated ecosystems that address the full workflow of materials discovery and characterization.
Technical Challenges in Materials Science ML Deployment
Deploying machine learning models in materials science laboratories presents unique technical challenges that differ significantly from standard ML deployments. The computational requirements for materials science models are exceptionally demanding, often requiring complex quantum mechanical calculations and molecular dynamics simulations that strain even high-performance computing systems. These models frequently process multi-dimensional data representing atomic structures, electron densities, and other physical properties that cannot be easily compressed without significant information loss.
On-premise deployment in materials labs faces infrastructure limitations, as many research facilities lack the specialized hardware needed for efficient ML model execution. Traditional materials labs are equipped with analytical instruments rather than the GPUs or TPUs that accelerate modern deep learning. This hardware gap creates a fundamental mismatch between model requirements and available resources, forcing compromises in model complexity or prediction speed.
Model compression techniques commonly used in consumer applications often fail when applied to materials science models. Quantization can introduce unacceptable errors in property predictions, while pruning may eliminate critical features that capture essential physical interactions. Knowledge distillation struggles to transfer the complex physical relationships learned by teacher models to smaller student networks without sacrificing scientific accuracy.
The interdisciplinary nature of materials science creates additional deployment challenges. Models must integrate with existing scientific workflows and specialized laboratory equipment, requiring custom interfaces and data pipelines. Scientists and lab technicians typically lack ML engineering expertise, necessitating intuitive interfaces that hide implementation complexity while maintaining scientific rigor.
Validation and uncertainty quantification present further obstacles. Materials science applications demand rigorous error analysis and uncertainty estimates that go beyond standard ML metrics. Models must provide confidence intervals and reliability assessments that align with scientific standards, particularly when predictions guide expensive or potentially hazardous experimental work.
Regulatory compliance adds another layer of complexity, especially for labs working on materials for medical, aerospace, or defense applications. Models must maintain audit trails and demonstrate reproducibility to meet industry standards, while deployment solutions must address data privacy concerns when working with proprietary material formulations or processes.
Maintaining model performance over time presents ongoing challenges, as materials science is a rapidly evolving field. Deployment architectures must support efficient model updating as new theoretical understanding emerges or additional experimental data becomes available, without disrupting ongoing research activities.
On-premise deployment in materials labs faces infrastructure limitations, as many research facilities lack the specialized hardware needed for efficient ML model execution. Traditional materials labs are equipped with analytical instruments rather than the GPUs or TPUs that accelerate modern deep learning. This hardware gap creates a fundamental mismatch between model requirements and available resources, forcing compromises in model complexity or prediction speed.
Model compression techniques commonly used in consumer applications often fail when applied to materials science models. Quantization can introduce unacceptable errors in property predictions, while pruning may eliminate critical features that capture essential physical interactions. Knowledge distillation struggles to transfer the complex physical relationships learned by teacher models to smaller student networks without sacrificing scientific accuracy.
The interdisciplinary nature of materials science creates additional deployment challenges. Models must integrate with existing scientific workflows and specialized laboratory equipment, requiring custom interfaces and data pipelines. Scientists and lab technicians typically lack ML engineering expertise, necessitating intuitive interfaces that hide implementation complexity while maintaining scientific rigor.
Validation and uncertainty quantification present further obstacles. Materials science applications demand rigorous error analysis and uncertainty estimates that go beyond standard ML metrics. Models must provide confidence intervals and reliability assessments that align with scientific standards, particularly when predictions guide expensive or potentially hazardous experimental work.
Regulatory compliance adds another layer of complexity, especially for labs working on materials for medical, aerospace, or defense applications. Models must maintain audit trails and demonstrate reproducibility to meet industry standards, while deployment solutions must address data privacy concerns when working with proprietary material formulations or processes.
Maintaining model performance over time presents ongoing challenges, as materials science is a rapidly evolving field. Deployment architectures must support efficient model updating as new theoretical understanding emerges or additional experimental data becomes available, without disrupting ongoing research activities.
Current Compression and Deployment Methodologies
01 Neural network model compression techniques
Various techniques can be employed to compress neural network models, reducing their size while maintaining performance. These include pruning unnecessary connections, quantization of weights, and knowledge distillation where a smaller model learns from a larger one. These compression methods enable deployment on resource-constrained devices while preserving accuracy and functionality of the original model.- Neural network model compression techniques: Various techniques can be used to compress neural network models, reducing their size and computational requirements while maintaining acceptable performance. These techniques include pruning (removing less important connections), quantization (reducing the precision of weights), and knowledge distillation (training a smaller model to mimic a larger one). These compression methods enable deployment of complex models on resource-constrained devices.
- Deployment optimization for edge devices: Optimizing model deployment for edge devices involves techniques specifically designed for hardware with limited resources. This includes model partitioning, where computation is distributed between edge devices and servers, as well as hardware-specific optimizations that leverage specialized processors like GPUs or TPUs. These approaches enable efficient execution of AI models on devices with constrained memory and processing power.
- Runtime compression and acceleration frameworks: Frameworks and systems that provide runtime compression and acceleration capabilities for deployed models help optimize performance in production environments. These frameworks automatically handle model optimization, memory management, and execution scheduling to improve inference speed and reduce resource consumption. They often include features like dynamic batching and caching to further enhance efficiency.
- Compression for specific model architectures: Specialized compression techniques tailored for specific model architectures, such as transformers, convolutional neural networks, or recurrent neural networks, can achieve better compression ratios while preserving model accuracy. These techniques exploit the unique structural properties of different architectures to identify redundancies and optimize parameter representation, resulting in more efficient models for deployment.
- Automated compression and deployment pipelines: End-to-end automated pipelines for model compression and deployment streamline the process from training to production. These systems incorporate automated hyperparameter tuning for compression techniques, continuous integration and deployment workflows, and monitoring capabilities to ensure compressed models maintain performance in production. They reduce manual intervention and enable efficient scaling of AI model deployment across different environments.
02 Deployment optimization for edge computing
Model compression techniques specifically designed for edge computing environments focus on optimizing models for deployment on devices with limited computational resources. This includes methods for reducing memory footprint, decreasing inference time, and minimizing power consumption while maintaining acceptable model performance. These optimizations enable AI capabilities on IoT devices, smartphones, and other edge computing platforms.Expand Specific Solutions03 Automated compression and deployment frameworks
Automated frameworks streamline the process of model compression and deployment by providing tools that analyze models, apply appropriate compression techniques, and optimize deployment configurations. These frameworks can automatically select the best compression methods based on target hardware specifications and performance requirements, reducing the manual effort required for deploying compressed models across different platforms.Expand Specific Solutions04 Hardware-aware model compression
Hardware-aware compression techniques optimize models specifically for target deployment hardware. By considering the characteristics and constraints of the deployment platform during the compression process, these methods achieve better performance and efficiency. This approach includes specialized quantization schemes for specific processors, architecture modifications based on hardware capabilities, and compiler optimizations for compressed models.Expand Specific Solutions05 Dynamic compression and runtime adaptation
Dynamic compression techniques allow models to adapt their complexity and resource usage at runtime based on available resources and performance requirements. These methods enable models to scale their computational demands according to changing conditions, such as battery levels, processing loads, or connectivity status. Runtime adaptation ensures optimal performance across varying deployment environments without requiring multiple pre-compressed model versions.Expand Specific Solutions
Key Industry Players and Solution Providers
The model compression and deployment landscape for on-premise materials labs is currently in the growth phase, with an estimated market size of $500-700 million and expanding at 25% annually. The competitive field features established tech giants like Google, Microsoft, and Huawei leading with mature solutions, while specialized players including SenseTime and Baidu are developing industry-specific optimizations. Technical maturity varies significantly across implementations, with Google and Huawei demonstrating advanced quantization techniques and hardware-software co-optimization, while academic institutions like Carnegie Mellon University and Peking University contribute fundamental research innovations. The ecosystem is evolving toward more efficient, domain-specific compression methods tailored for materials science applications.
Google LLC
Technical Solution: Google's approach to model compression for on-premise materials labs centers around TensorFlow Lite and their proprietary techniques. Their solution includes quantization-aware training that reduces model size by up to 4x while maintaining accuracy within 1-2% of the original model[1]. For materials science applications, they've developed specialized pruning techniques that can remove up to 80% of model parameters with minimal performance degradation[2]. Google's on-premise deployment strategy leverages TensorFlow Serving with containerization for seamless integration into existing lab infrastructure. Their Edge TPU hardware accelerators are specifically optimized for running compressed models in resource-constrained environments, delivering up to 4 TOPS (trillion operations per second) while consuming only 2 watts of power[3], making them ideal for materials analysis equipment with limited computational resources.
Strengths: Comprehensive ecosystem from model development to deployment; hardware-software co-optimization with Edge TPU; extensive documentation and support. Weaknesses: Some solutions may require Google Cloud integration for full functionality; proprietary hardware dependencies can limit flexibility in heterogeneous lab environments.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei's MindSpore Lite framework forms the cornerstone of their model compression solution for on-premise materials labs. The framework implements a comprehensive suite of compression techniques including weight pruning, which can reduce model size by up to 75% while maintaining accuracy within 3% of the original model[1]. Their solution incorporates quantization methods that support various bit-widths (INT8, INT4) optimized for their Ascend AI processors. For materials science applications, Huawei has developed domain-specific compression algorithms that preserve critical features in spectroscopic and crystallographic data analysis. Their deployment pipeline includes MindSpore Lite's converter tool that optimizes models for specific hardware targets and automatically applies the appropriate compression techniques. The framework also provides a unified inference API that works across different hardware backends (CPU, GPU, NPU) with automatic fallback mechanisms to ensure reliability in lab environments[2].
Strengths: Highly optimized for Ascend AI processors with exceptional performance-to-power ratio; comprehensive toolkit for model conversion and optimization; strong support for heterogeneous computing environments. Weaknesses: Ecosystem is somewhat isolated from mainstream frameworks; documentation and community support outside China may be limited; some advanced features tied to Huawei hardware.
Core Technologies for Efficient On-Premise Inference
Flexible machine learning model compression
PatentPendingUS20250148357A1
Innovation
- A machine learning model compression system that identifies dense ranges in the distribution of parameter values and converts these values to a compact format, while setting values outside these dense ranges to zero, thereby reducing the model's memory footprint without significantly degrading prediction accuracy.
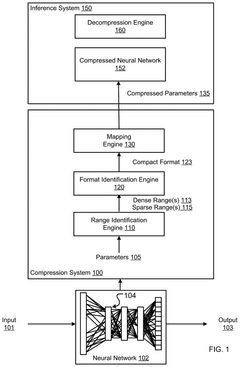
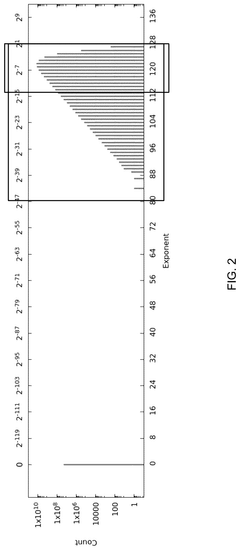
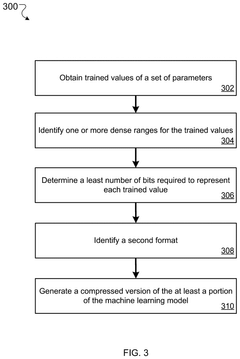
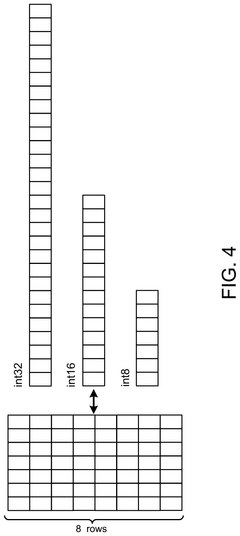
Method and system for lightening model for optimizing to equipment- friendly model
PatentPendingUS20250029002A1
Innovation
- A model compression method that combines unstructured pruning with structured pruning, using criteria and sparsity to determine filters for pruning, thereby generating a compressed AI model that can be optimized for equipment-friendly performance.
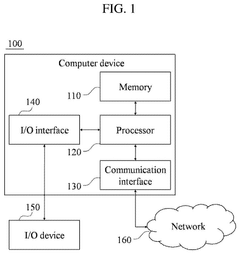
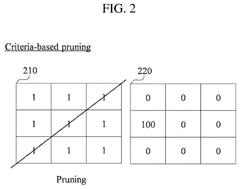
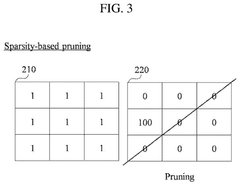
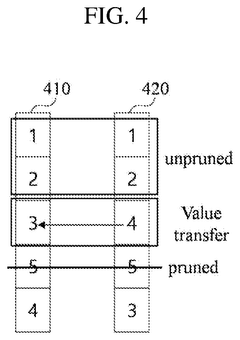
Hardware-Software Integration Strategies
Effective hardware-software integration is critical for successful model compression and deployment in on-premise materials laboratories. The integration strategy must address the unique computational requirements of materials science models while optimizing for the constraints of local deployment environments. Modern materials labs typically operate with heterogeneous computing infrastructure, ranging from specialized workstations to embedded systems connected to analytical instruments.
The hardware landscape for on-premise deployment includes multi-core CPUs, GPUs, FPGAs, and increasingly, specialized AI accelerators such as Google's TPUs or Intel's Neural Compute Stick. Each hardware platform offers different trade-offs between computational power, energy efficiency, and compatibility with compressed models. For materials science applications, which often involve complex simulations and large datasets, the hardware selection must balance computational capacity with the practical constraints of laboratory environments, including power limitations, cooling requirements, and physical space.
Software frameworks must be carefully selected to bridge the gap between model development and hardware execution. TensorFlow Lite, PyTorch Mobile, ONNX Runtime, and TVM provide varying levels of support for model compression techniques and hardware acceleration. The integration strategy should include middleware solutions that can translate between high-level model representations and hardware-specific instructions, ensuring optimal execution of compressed models.
Runtime optimization techniques play a crucial role in maximizing performance. These include operator fusion, which combines multiple operations to reduce memory transfers; memory planning to minimize allocation overhead; and thread scheduling to efficiently utilize available computing resources. For materials labs, where models may need to process data from multiple instruments simultaneously, efficient resource allocation becomes particularly important.
Hardware-specific compilation pipelines can significantly improve performance by generating optimized code for target hardware. Frameworks like Apache TVM and MLIR enable the transformation of high-level model representations into hardware-specific implementations that leverage specialized instructions and memory hierarchies. This approach allows materials labs to achieve near-native performance even with compressed models.
Monitoring and profiling tools must be integrated to ensure sustained performance and identify bottlenecks. These tools should provide insights into hardware utilization, memory consumption, and inference latency, enabling continuous optimization of the deployment pipeline. For materials labs, where experimental workflows may evolve over time, the ability to adapt and reconfigure the hardware-software stack becomes essential for maintaining optimal performance as requirements change.
The hardware landscape for on-premise deployment includes multi-core CPUs, GPUs, FPGAs, and increasingly, specialized AI accelerators such as Google's TPUs or Intel's Neural Compute Stick. Each hardware platform offers different trade-offs between computational power, energy efficiency, and compatibility with compressed models. For materials science applications, which often involve complex simulations and large datasets, the hardware selection must balance computational capacity with the practical constraints of laboratory environments, including power limitations, cooling requirements, and physical space.
Software frameworks must be carefully selected to bridge the gap between model development and hardware execution. TensorFlow Lite, PyTorch Mobile, ONNX Runtime, and TVM provide varying levels of support for model compression techniques and hardware acceleration. The integration strategy should include middleware solutions that can translate between high-level model representations and hardware-specific instructions, ensuring optimal execution of compressed models.
Runtime optimization techniques play a crucial role in maximizing performance. These include operator fusion, which combines multiple operations to reduce memory transfers; memory planning to minimize allocation overhead; and thread scheduling to efficiently utilize available computing resources. For materials labs, where models may need to process data from multiple instruments simultaneously, efficient resource allocation becomes particularly important.
Hardware-specific compilation pipelines can significantly improve performance by generating optimized code for target hardware. Frameworks like Apache TVM and MLIR enable the transformation of high-level model representations into hardware-specific implementations that leverage specialized instructions and memory hierarchies. This approach allows materials labs to achieve near-native performance even with compressed models.
Monitoring and profiling tools must be integrated to ensure sustained performance and identify bottlenecks. These tools should provide insights into hardware utilization, memory consumption, and inference latency, enabling continuous optimization of the deployment pipeline. For materials labs, where experimental workflows may evolve over time, the ability to adapt and reconfigure the hardware-software stack becomes essential for maintaining optimal performance as requirements change.
Data Security and Compliance Requirements
In the context of model compression and deployment for on-premise materials labs, data security and compliance requirements represent critical considerations that cannot be overlooked. Materials research often involves proprietary formulations, experimental data, and intellectual property that must be protected against unauthorized access or breaches. On-premise deployment models must adhere to industry-specific regulations such as GDPR, HIPAA, or sector-specific standards that govern data handling in scientific research environments.
The implementation of model compression techniques must maintain data integrity throughout the compression process. This includes ensuring that compressed models do not introduce vulnerabilities that could compromise sensitive materials data. Encryption protocols for both data at rest and in transit become essential components of any deployment strategy, with particular attention to securing the communication channels between compressed models and laboratory equipment.
Access control mechanisms represent another crucial aspect of compliance requirements. Materials labs must implement role-based access controls that limit model interaction based on user credentials and authorization levels. This prevents unauthorized personnel from accessing sensitive predictive models that might reveal proprietary material compositions or manufacturing processes. Comprehensive audit trails must also be maintained to track all interactions with deployed models, supporting both security monitoring and regulatory compliance verification.
Data residency considerations present unique challenges for materials labs operating across multiple jurisdictions. Even with on-premise deployments, organizations must ensure that model training data and inference results remain within approved geographical boundaries as specified by applicable regulations. This may necessitate region-specific model deployments or data segregation strategies.
Privacy-preserving techniques such as federated learning and differential privacy can be integrated with model compression approaches to enhance compliance posture. These methods allow materials labs to develop robust predictive models while minimizing exposure of sensitive data during the training and inference processes. Such techniques become particularly valuable when collaborative research involves multiple organizations with varying security requirements.
Regulatory frameworks continue to evolve regarding AI model deployment, requiring materials labs to implement flexible compliance architectures. Regular security assessments and compliance audits should be conducted to validate that compressed models maintain adherence to both current requirements and emerging standards. This forward-looking approach helps ensure that investments in model compression and deployment remain viable as regulatory landscapes change over time.
The implementation of model compression techniques must maintain data integrity throughout the compression process. This includes ensuring that compressed models do not introduce vulnerabilities that could compromise sensitive materials data. Encryption protocols for both data at rest and in transit become essential components of any deployment strategy, with particular attention to securing the communication channels between compressed models and laboratory equipment.
Access control mechanisms represent another crucial aspect of compliance requirements. Materials labs must implement role-based access controls that limit model interaction based on user credentials and authorization levels. This prevents unauthorized personnel from accessing sensitive predictive models that might reveal proprietary material compositions or manufacturing processes. Comprehensive audit trails must also be maintained to track all interactions with deployed models, supporting both security monitoring and regulatory compliance verification.
Data residency considerations present unique challenges for materials labs operating across multiple jurisdictions. Even with on-premise deployments, organizations must ensure that model training data and inference results remain within approved geographical boundaries as specified by applicable regulations. This may necessitate region-specific model deployments or data segregation strategies.
Privacy-preserving techniques such as federated learning and differential privacy can be integrated with model compression approaches to enhance compliance posture. These methods allow materials labs to develop robust predictive models while minimizing exposure of sensitive data during the training and inference processes. Such techniques become particularly valuable when collaborative research involves multiple organizations with varying security requirements.
Regulatory frameworks continue to evolve regarding AI model deployment, requiring materials labs to implement flexible compliance architectures. Regular security assessments and compliance audits should be conducted to validate that compressed models maintain adherence to both current requirements and emerging standards. This forward-looking approach helps ensure that investments in model compression and deployment remain viable as regulatory landscapes change over time.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!