Quality Metrics For Synthetic Data: Precision, Recall, And Beyond
SEP 1, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Synthetic Data Quality Assessment Background and Objectives
Synthetic data has emerged as a critical resource in the era of data-driven technologies, particularly in scenarios where real data is scarce, sensitive, or difficult to obtain. The assessment of synthetic data quality represents a fundamental challenge that has evolved significantly over the past decade, transitioning from basic statistical comparisons to sophisticated evaluation frameworks that consider multiple dimensions of data utility and fidelity.
The evolution of synthetic data quality metrics began with simple statistical measures comparing distributions between real and synthetic datasets. These early approaches focused primarily on univariate statistics and basic correlation patterns. As machine learning applications grew more complex, the evaluation methods expanded to include performance-based metrics that assessed how well models trained on synthetic data could generalize to real-world scenarios.
Recent advancements have introduced more nuanced evaluation frameworks that extend beyond traditional precision and recall metrics. These frameworks incorporate privacy preservation assessment, fairness considerations, and domain-specific utility measures that align with the intended use cases of the synthetic data.
The primary objective of synthetic data quality assessment is to establish reliable, standardized methods for evaluating how well synthetic data captures the essential characteristics of real data while maintaining privacy and utility. This includes developing metrics that can quantify the trade-offs between statistical fidelity, privacy protection, and downstream task performance.
Current research aims to address several key challenges in this domain, including the development of context-aware quality metrics that adapt to specific application requirements, methods for evaluating high-dimensional data representations, and techniques for assessing temporal consistency in sequential synthetic data.
The field is increasingly moving toward multi-objective evaluation frameworks that simultaneously consider statistical similarity, machine learning utility, privacy guarantees, and fairness implications. This holistic approach recognizes that synthetic data quality cannot be reduced to a single metric but must be evaluated across multiple dimensions relevant to its intended use.
Industry adoption of synthetic data has accelerated the need for standardized quality benchmarks that can provide stakeholders with clear indicators of synthetic data reliability and limitations. These benchmarks are essential for building trust in synthetic data solutions and enabling informed decisions about their application in critical domains such as healthcare, finance, and autonomous systems.
The evolution of synthetic data quality metrics began with simple statistical measures comparing distributions between real and synthetic datasets. These early approaches focused primarily on univariate statistics and basic correlation patterns. As machine learning applications grew more complex, the evaluation methods expanded to include performance-based metrics that assessed how well models trained on synthetic data could generalize to real-world scenarios.
Recent advancements have introduced more nuanced evaluation frameworks that extend beyond traditional precision and recall metrics. These frameworks incorporate privacy preservation assessment, fairness considerations, and domain-specific utility measures that align with the intended use cases of the synthetic data.
The primary objective of synthetic data quality assessment is to establish reliable, standardized methods for evaluating how well synthetic data captures the essential characteristics of real data while maintaining privacy and utility. This includes developing metrics that can quantify the trade-offs between statistical fidelity, privacy protection, and downstream task performance.
Current research aims to address several key challenges in this domain, including the development of context-aware quality metrics that adapt to specific application requirements, methods for evaluating high-dimensional data representations, and techniques for assessing temporal consistency in sequential synthetic data.
The field is increasingly moving toward multi-objective evaluation frameworks that simultaneously consider statistical similarity, machine learning utility, privacy guarantees, and fairness implications. This holistic approach recognizes that synthetic data quality cannot be reduced to a single metric but must be evaluated across multiple dimensions relevant to its intended use.
Industry adoption of synthetic data has accelerated the need for standardized quality benchmarks that can provide stakeholders with clear indicators of synthetic data reliability and limitations. These benchmarks are essential for building trust in synthetic data solutions and enabling informed decisions about their application in critical domains such as healthcare, finance, and autonomous systems.
Market Demand Analysis for High-Quality Synthetic Data
The synthetic data market is experiencing unprecedented growth, driven by increasing data privacy regulations and the need for large, diverse datasets in AI development. According to recent market research, the global synthetic data generation market is projected to reach $1.3 billion by 2027, growing at a CAGR of 35% from 2022. This rapid expansion reflects the critical demand for high-quality synthetic data across multiple industries.
Healthcare organizations represent one of the largest market segments, with 78% of healthcare institutions expressing interest in synthetic data solutions to overcome patient privacy concerns while maintaining analytical capabilities. Financial services follow closely, where 65% of banks and insurance companies are exploring synthetic data for fraud detection model training and customer behavior analysis without exposing sensitive information.
The demand for quality metrics in synthetic data is particularly acute in autonomous vehicle development, where companies require synthetic driving scenarios that precisely mirror real-world conditions. Tesla, Waymo, and other autonomous vehicle developers have increased their synthetic data budgets by an average of 40% annually since 2020, emphasizing the need for reliable quality assessment frameworks.
Enterprise AI adoption is another significant driver, with 82% of Fortune 500 companies citing data limitations as a primary obstacle to AI implementation. These organizations are increasingly turning to synthetic data solutions that can demonstrably preserve statistical properties of original datasets while offering enhanced privacy protection.
Market research indicates that 73% of data scientists and AI engineers consider quality assessment metrics as the most critical factor when evaluating synthetic data solutions. The ability to quantitatively measure how well synthetic data captures the characteristics of real data—beyond basic precision and recall—has become a key purchasing criterion.
Regulatory compliance represents another substantial market driver. With GDPR in Europe, CCPA in California, and similar regulations worldwide, organizations face significant penalties for mishandling personal data. This regulatory landscape has created a $300 million market segment specifically for privacy-preserving synthetic data solutions with robust quality validation frameworks.
Emerging applications in retail, manufacturing, and telecommunications are expanding the market further. These sectors show growing demand for synthetic data that can accurately represent customer behavior, production processes, and network traffic patterns while providing measurable quality guarantees that ensure business decisions based on synthetic data remain reliable.
Healthcare organizations represent one of the largest market segments, with 78% of healthcare institutions expressing interest in synthetic data solutions to overcome patient privacy concerns while maintaining analytical capabilities. Financial services follow closely, where 65% of banks and insurance companies are exploring synthetic data for fraud detection model training and customer behavior analysis without exposing sensitive information.
The demand for quality metrics in synthetic data is particularly acute in autonomous vehicle development, where companies require synthetic driving scenarios that precisely mirror real-world conditions. Tesla, Waymo, and other autonomous vehicle developers have increased their synthetic data budgets by an average of 40% annually since 2020, emphasizing the need for reliable quality assessment frameworks.
Enterprise AI adoption is another significant driver, with 82% of Fortune 500 companies citing data limitations as a primary obstacle to AI implementation. These organizations are increasingly turning to synthetic data solutions that can demonstrably preserve statistical properties of original datasets while offering enhanced privacy protection.
Market research indicates that 73% of data scientists and AI engineers consider quality assessment metrics as the most critical factor when evaluating synthetic data solutions. The ability to quantitatively measure how well synthetic data captures the characteristics of real data—beyond basic precision and recall—has become a key purchasing criterion.
Regulatory compliance represents another substantial market driver. With GDPR in Europe, CCPA in California, and similar regulations worldwide, organizations face significant penalties for mishandling personal data. This regulatory landscape has created a $300 million market segment specifically for privacy-preserving synthetic data solutions with robust quality validation frameworks.
Emerging applications in retail, manufacturing, and telecommunications are expanding the market further. These sectors show growing demand for synthetic data that can accurately represent customer behavior, production processes, and network traffic patterns while providing measurable quality guarantees that ensure business decisions based on synthetic data remain reliable.
Current Evaluation Metrics and Technical Challenges
The evaluation of synthetic data quality presents a complex landscape of metrics and challenges. Traditional evaluation approaches have primarily relied on statistical measures such as precision and recall, which assess how accurately synthetic data represents the original distribution. Precision measures the proportion of synthetic data points that accurately reflect real-world patterns, while recall evaluates how comprehensively the synthetic data captures the full spectrum of patterns present in the original dataset.
Beyond these fundamental metrics, researchers have developed more sophisticated evaluation frameworks. Fidelity metrics quantify how closely synthetic data mimics the statistical properties of real data, including distributions, correlations, and outlier patterns. Privacy preservation metrics assess the risk of information leakage, measuring how effectively synthetic data protects sensitive information while maintaining utility.
Utility-based evaluation has gained prominence, focusing on how well downstream machine learning models trained on synthetic data perform compared to those trained on real data. This approach includes measures like classification accuracy delta, F1-score differences, and model transferability metrics that evaluate performance across different domains.
Technical challenges in synthetic data evaluation remain significant. The high-dimensionality problem makes comprehensive quality assessment computationally intensive and statistically complex. As data dimensionality increases, the curse of dimensionality makes it increasingly difficult to ensure that synthetic data accurately represents joint distributions across all variables.
Mode collapse represents another critical challenge, where generative models fail to capture the full diversity of the original data, instead producing a limited subset of patterns. Detecting and quantifying this phenomenon requires specialized metrics beyond traditional statistical measures.
The temporal aspect of data presents unique evaluation challenges, particularly for time-series synthetic data. Metrics must capture not only point-wise statistical properties but also temporal dependencies, seasonal patterns, and trend preservation. Current approaches often struggle to comprehensively evaluate these temporal characteristics.
Domain-specific quality requirements further complicate evaluation frameworks. Medical data requires different quality assessments than financial or industrial data, necessitating specialized metrics tailored to specific use cases. The lack of standardized, cross-domain evaluation protocols remains a significant obstacle to widespread synthetic data adoption.
Emerging research focuses on developing holistic evaluation frameworks that combine multiple metrics across different dimensions of quality. These approaches aim to provide a more comprehensive assessment of synthetic data quality, addressing the multifaceted nature of the evaluation challenge while balancing computational feasibility with evaluation thoroughness.
Beyond these fundamental metrics, researchers have developed more sophisticated evaluation frameworks. Fidelity metrics quantify how closely synthetic data mimics the statistical properties of real data, including distributions, correlations, and outlier patterns. Privacy preservation metrics assess the risk of information leakage, measuring how effectively synthetic data protects sensitive information while maintaining utility.
Utility-based evaluation has gained prominence, focusing on how well downstream machine learning models trained on synthetic data perform compared to those trained on real data. This approach includes measures like classification accuracy delta, F1-score differences, and model transferability metrics that evaluate performance across different domains.
Technical challenges in synthetic data evaluation remain significant. The high-dimensionality problem makes comprehensive quality assessment computationally intensive and statistically complex. As data dimensionality increases, the curse of dimensionality makes it increasingly difficult to ensure that synthetic data accurately represents joint distributions across all variables.
Mode collapse represents another critical challenge, where generative models fail to capture the full diversity of the original data, instead producing a limited subset of patterns. Detecting and quantifying this phenomenon requires specialized metrics beyond traditional statistical measures.
The temporal aspect of data presents unique evaluation challenges, particularly for time-series synthetic data. Metrics must capture not only point-wise statistical properties but also temporal dependencies, seasonal patterns, and trend preservation. Current approaches often struggle to comprehensively evaluate these temporal characteristics.
Domain-specific quality requirements further complicate evaluation frameworks. Medical data requires different quality assessments than financial or industrial data, necessitating specialized metrics tailored to specific use cases. The lack of standardized, cross-domain evaluation protocols remains a significant obstacle to widespread synthetic data adoption.
Emerging research focuses on developing holistic evaluation frameworks that combine multiple metrics across different dimensions of quality. These approaches aim to provide a more comprehensive assessment of synthetic data quality, addressing the multifaceted nature of the evaluation challenge while balancing computational feasibility with evaluation thoroughness.
Existing Frameworks for Synthetic Data Quality Assessment
01 Evaluation metrics for synthetic data quality
Precision and recall are key metrics used to evaluate the quality of synthetic data. Precision measures the accuracy of the generated data points that match the real data, while recall measures the ability to generate all relevant data patterns. These metrics help assess how well synthetic data represents the characteristics and distributions of real-world data, ensuring that machine learning models trained on synthetic data perform reliably when applied to real data.- Evaluation metrics for synthetic data quality: Precision and recall are key metrics used to evaluate the quality of synthetic data. Precision measures the accuracy of the generated data points, indicating how many of the synthetic data points are relevant or accurate. Recall measures the completeness of the synthetic data, indicating how many of the relevant data points are actually captured in the synthetic dataset. These metrics help in assessing whether the synthetic data accurately represents the characteristics and distributions of the original data.
- Machine learning models for synthetic data validation: Machine learning algorithms can be employed to validate synthetic data quality using precision and recall metrics. These models compare the synthetic data against real data to determine how well the synthetic data preserves the statistical properties and relationships present in the original dataset. The validation process involves training models on both real and synthetic data, then measuring performance differences to assess the synthetic data's utility and fidelity.
- Error detection and correction in synthetic datasets: Systems for detecting and correcting errors in synthetic datasets utilize precision and recall measurements to identify discrepancies between expected and actual data patterns. These systems employ statistical analysis to flag potential anomalies or inconsistencies in the synthetic data. By continuously monitoring precision and recall metrics during the synthetic data generation process, the quality of the output can be improved through iterative refinement and error correction mechanisms.
- Network performance evaluation using synthetic data: Synthetic data is used to evaluate network performance by simulating various traffic conditions and measuring system responses. Precision metrics assess how accurately the synthetic data represents real-world network conditions, while recall metrics evaluate how comprehensively the synthetic data captures different network scenarios. These measurements help in optimizing network configurations, identifying potential bottlenecks, and ensuring robust performance under diverse operating conditions.
- Synthetic data generation for testing and validation: Techniques for generating high-quality synthetic data focus on maintaining precision and recall relative to source data distributions. These methods employ various algorithms to create realistic synthetic datasets that preserve the statistical properties of the original data while protecting privacy. The quality of the generated synthetic data is evaluated using precision and recall metrics to ensure that it can effectively substitute for real data in testing and validation scenarios without compromising analytical outcomes.
02 Synthetic data validation frameworks
Frameworks for validating synthetic data quality incorporate precision and recall measurements within comprehensive testing protocols. These frameworks compare generated data against reference datasets to identify discrepancies and ensure statistical similarity. By implementing automated validation processes, organizations can systematically evaluate synthetic data across multiple dimensions including feature distributions, correlations, and edge cases, thereby maintaining high data quality standards.Expand Specific Solutions03 Machine learning applications with synthetic data quality metrics
Machine learning systems utilize precision and recall metrics to optimize synthetic data generation processes. These metrics guide the refinement of generative models to produce higher quality synthetic datasets that preserve privacy while maintaining utility. By continuously monitoring precision and recall during training, ML systems can adaptively improve data generation techniques, resulting in synthetic data that better supports downstream applications like testing, training, and validation of AI models.Expand Specific Solutions04 Network performance testing with synthetic data
Network testing systems employ synthetic data with precision and recall metrics to evaluate network performance under various conditions. These systems generate realistic traffic patterns that accurately represent real-world network loads while measuring how precisely the synthetic data matches expected network behaviors. By analyzing both precision and recall in network simulations, engineers can identify potential bottlenecks, security vulnerabilities, and performance issues before deployment in production environments.Expand Specific Solutions05 Error detection and correction in synthetic data
Error detection and correction mechanisms for synthetic data rely on precision and recall metrics to identify and address quality issues. These systems analyze discrepancies between generated and expected data patterns, flagging potential errors for correction. By implementing automated feedback loops that continuously evaluate precision and recall, data generation systems can self-improve over time, reducing anomalies and ensuring that synthetic data maintains high fidelity to the source data characteristics while preserving privacy constraints.Expand Specific Solutions
Leading Organizations in Synthetic Data Evaluation
The synthetic data quality metrics landscape is evolving rapidly, with the market currently in its growth phase as organizations increasingly recognize the value of high-quality synthetic data. The global market is expanding significantly, driven by applications in AI training, privacy-preserving analytics, and testing. Technologically, the field is maturing but still developing standardized evaluation frameworks beyond traditional precision and recall metrics. Key players demonstrate varying levels of technological sophistication: Microsoft, Huawei, and Amazon lead with advanced proprietary frameworks; financial institutions like Bank of America and Capital One focus on domain-specific metrics; while research-oriented organizations such as Robert Bosch GmbH and Beijing Institute of Technology contribute fundamental methodological innovations. The ecosystem shows a healthy balance between established tech giants, specialized startups, and academic institutions collaborating to advance measurement standards.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a comprehensive synthetic data quality evaluation framework called SDQE (Synthetic Data Quality Evaluator) that extends beyond traditional precision and recall metrics. Their approach incorporates statistical fidelity measures using multiple distribution comparison techniques including Kullback-Leibler divergence and Maximum Mean Discrepancy. Huawei's framework places particular emphasis on temporal consistency metrics for time-series synthetic data, which is crucial for telecommunications applications. Their system evaluates both marginal distributions of individual features and joint distributions to ensure complex relationships are preserved. For privacy evaluation, they've implemented differential privacy guarantees and empirical privacy risk assessments through simulated attacks. Huawei's framework also includes domain-specific utility metrics that evaluate how well synthetic data performs in downstream tasks like network anomaly detection or user behavior prediction. The system generates comprehensive quality reports with visualization tools that help data scientists identify specific areas where synthetic data may diverge from real data patterns.
Strengths: Strong focus on temporal consistency metrics particularly valuable for time-series data; comprehensive privacy evaluation framework; domain-specific utility metrics tailored to telecommunications use cases. Weaknesses: Heavy computational requirements for full evaluation suite; complex configuration needed for optimal results; potential challenges in balancing privacy and utility trade-offs.
Fair Isaac Corp.
Technical Solution: Fair Isaac Corporation (FICO) has developed a specialized synthetic data quality framework focused on financial applications called SynFi (Synthetic Financial Data Quality Framework). Their approach extends precision and recall concepts to handle the unique challenges of financial data, including rare events and highly skewed distributions. FICO's framework incorporates statistical tests specifically designed for credit risk modeling, including population stability index (PSI) and characteristic analysis (CA) to ensure synthetic data maintains the same predictive power as real data. Their system includes specialized metrics for evaluating temporal consistency in financial time series and transaction data. FICO has implemented fairness metrics that ensure synthetic data doesn't amplify biases present in original datasets, which is crucial for regulatory compliance. Their framework also includes adversarial evaluation techniques where synthetic data quality is measured by how well it can fool specialized detection algorithms designed to distinguish synthetic from real financial data. The system produces detailed quality reports highlighting areas where synthetic data may need refinement to meet specific use case requirements.
Strengths: Domain-specific metrics tailored to financial services applications; strong focus on regulatory compliance and fairness considerations; specialized handling of rare events and skewed distributions common in financial data. Weaknesses: Highly specialized for financial domain with limited generalizability; complex configuration requirements; potential challenges in balancing competing objectives like privacy and utility.
Critical Analysis of Precision-Recall Metrics for Synthetic Data
Multiclass classification with diversified precision and recall weightings
PatentWO2021163524A1
Innovation
- A weighted f-measure metric is introduced, allowing for nonuniform weighting of class-specific precision and recall, providing a flexible evaluation method that considers the importance of each class, and includes a regularization term to stabilize performance in imbalanced data scenarios.


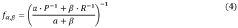

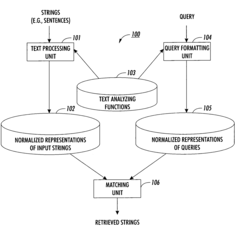
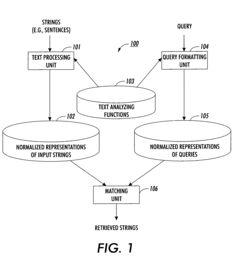
Method and apparatus for generating normalized representations of strings
PatentInactiveUS6983240B2
Innovation
- A method and apparatus for generating normalized representations of strings through morphological, syntactic, and semantic analysis, followed by skeletisation to replace linguistic information with abstract variables, allowing for more accurate matching and retrieval of similar strings across different linguistic forms and structures.
Privacy and Security Implications of Synthetic Data Quality
The intersection of synthetic data quality and privacy presents a complex landscape of trade-offs and considerations. As synthetic data generation techniques advance, the quality metrics used to evaluate these datasets directly impact their privacy and security implications. High-fidelity synthetic data that closely mimics original datasets may preserve statistical properties but simultaneously increases the risk of privacy breaches through membership inference attacks or model inversion techniques.
Research indicates that precision and recall metrics, when optimized without privacy considerations, can inadvertently create synthetic datasets that leak sensitive information from training data. For instance, synthetic datasets with high precision may reproduce rare patterns present in original data, potentially exposing unique individual characteristics that could be traced back to specific data subjects.
Privacy-preserving synthetic data generation often requires deliberate introduction of statistical noise or perturbation, which inherently affects quality metrics. This creates a fundamental tension between utility and privacy that must be carefully balanced. Differential privacy techniques applied during synthetic data generation provide mathematical guarantees against re-identification but typically reduce precision and recall scores.
Recent studies demonstrate that synthetic data quality assessment should incorporate privacy-specific metrics alongside traditional evaluation measures. The "privacy-utility frontier" concept helps quantify the relationship between synthetic data quality and privacy risk, enabling organizations to make informed decisions about acceptable trade-offs based on their specific use cases and regulatory requirements.
Security vulnerabilities in synthetic data pipelines present additional concerns. Adversarial attacks targeting the generation process can potentially extract training data or manipulate synthetic outputs. Quality metrics that fail to detect these manipulations may give false confidence in datasets that actually contain security vulnerabilities.
Regulatory frameworks like GDPR and CCPA have begun addressing synthetic data, but interpretations vary regarding whether high-quality synthetic data should be treated as personal information. The determination often hinges on re-identification risk, which directly correlates with certain quality metrics. Organizations deploying synthetic data solutions must therefore consider not only technical quality measures but also evolving legal interpretations of what constitutes anonymized data.
Emerging best practices suggest implementing continuous privacy risk assessment throughout the synthetic data lifecycle, with quality metrics serving as early indicators of potential security vulnerabilities rather than just utility measures.
Research indicates that precision and recall metrics, when optimized without privacy considerations, can inadvertently create synthetic datasets that leak sensitive information from training data. For instance, synthetic datasets with high precision may reproduce rare patterns present in original data, potentially exposing unique individual characteristics that could be traced back to specific data subjects.
Privacy-preserving synthetic data generation often requires deliberate introduction of statistical noise or perturbation, which inherently affects quality metrics. This creates a fundamental tension between utility and privacy that must be carefully balanced. Differential privacy techniques applied during synthetic data generation provide mathematical guarantees against re-identification but typically reduce precision and recall scores.
Recent studies demonstrate that synthetic data quality assessment should incorporate privacy-specific metrics alongside traditional evaluation measures. The "privacy-utility frontier" concept helps quantify the relationship between synthetic data quality and privacy risk, enabling organizations to make informed decisions about acceptable trade-offs based on their specific use cases and regulatory requirements.
Security vulnerabilities in synthetic data pipelines present additional concerns. Adversarial attacks targeting the generation process can potentially extract training data or manipulate synthetic outputs. Quality metrics that fail to detect these manipulations may give false confidence in datasets that actually contain security vulnerabilities.
Regulatory frameworks like GDPR and CCPA have begun addressing synthetic data, but interpretations vary regarding whether high-quality synthetic data should be treated as personal information. The determination often hinges on re-identification risk, which directly correlates with certain quality metrics. Organizations deploying synthetic data solutions must therefore consider not only technical quality measures but also evolving legal interpretations of what constitutes anonymized data.
Emerging best practices suggest implementing continuous privacy risk assessment throughout the synthetic data lifecycle, with quality metrics serving as early indicators of potential security vulnerabilities rather than just utility measures.
Standardization Efforts for Synthetic Data Evaluation
As the field of synthetic data generation continues to evolve, there is a growing recognition of the need for standardized evaluation frameworks. Several organizations and research institutions have initiated efforts to establish common benchmarks and metrics for assessing synthetic data quality. The IEEE P7002 working group has been developing standards for data privacy and synthetic data generation, with specific attention to evaluation criteria that balance utility and privacy considerations.
The National Institute of Standards and Technology (NIST) has launched a Synthetic Data Framework initiative that aims to provide guidelines for evaluating synthetic data across various domains. This framework incorporates both traditional metrics like precision and recall, as well as newer metrics focused on distributional similarity and privacy preservation. Their approach emphasizes the importance of context-specific evaluation, acknowledging that different use cases may require different quality thresholds.
In the healthcare sector, the Synthetic Data Collaborative, comprising major research hospitals and technology companies, has proposed domain-specific standards for evaluating synthetic medical data. Their framework includes specialized metrics for assessing clinical validity and maintaining statistical relationships critical for medical research.
The European Union's AI Alliance has incorporated synthetic data evaluation standards into their broader AI governance framework, emphasizing transparency in reporting how synthetic data performs across multiple quality dimensions. Their approach requires documentation of both the generation process and comprehensive evaluation results using standardized metrics.
Academic consortiums have also contributed significantly to standardization efforts. The Synthetic Data Evaluation Consortium (SDEC), formed by leading universities, has published benchmark datasets and evaluation protocols that are gaining traction in research communities. Their work focuses on creating reproducible evaluation methodologies that can be applied consistently across different synthetic data generation techniques.
Industry leaders like Google, Microsoft, and Amazon have published open-source evaluation toolkits that implement standardized metrics for synthetic data quality assessment. These tools are increasingly being adopted as de facto standards in commercial applications, providing common ground for comparing different synthetic data solutions.
Despite these advances, challenges remain in harmonizing evaluation approaches across different domains and use cases. Current standardization efforts are working to address the tension between generalized metrics that enable cross-domain comparisons and specialized metrics that capture domain-specific quality requirements. The development of adaptive evaluation frameworks that can be customized while maintaining comparability represents the frontier of current standardization work.
The National Institute of Standards and Technology (NIST) has launched a Synthetic Data Framework initiative that aims to provide guidelines for evaluating synthetic data across various domains. This framework incorporates both traditional metrics like precision and recall, as well as newer metrics focused on distributional similarity and privacy preservation. Their approach emphasizes the importance of context-specific evaluation, acknowledging that different use cases may require different quality thresholds.
In the healthcare sector, the Synthetic Data Collaborative, comprising major research hospitals and technology companies, has proposed domain-specific standards for evaluating synthetic medical data. Their framework includes specialized metrics for assessing clinical validity and maintaining statistical relationships critical for medical research.
The European Union's AI Alliance has incorporated synthetic data evaluation standards into their broader AI governance framework, emphasizing transparency in reporting how synthetic data performs across multiple quality dimensions. Their approach requires documentation of both the generation process and comprehensive evaluation results using standardized metrics.
Academic consortiums have also contributed significantly to standardization efforts. The Synthetic Data Evaluation Consortium (SDEC), formed by leading universities, has published benchmark datasets and evaluation protocols that are gaining traction in research communities. Their work focuses on creating reproducible evaluation methodologies that can be applied consistently across different synthetic data generation techniques.
Industry leaders like Google, Microsoft, and Amazon have published open-source evaluation toolkits that implement standardized metrics for synthetic data quality assessment. These tools are increasingly being adopted as de facto standards in commercial applications, providing common ground for comparing different synthetic data solutions.
Despite these advances, challenges remain in harmonizing evaluation approaches across different domains and use cases. Current standardization efforts are working to address the tension between generalized metrics that enable cross-domain comparisons and specialized metrics that capture domain-specific quality requirements. The development of adaptive evaluation frameworks that can be customized while maintaining comparability represents the frontier of current standardization work.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!