

Broadcast television voice recognition method and system
A voice recognition, broadcasting and TV technology, applied in the field of audio and video processing, can solve the problems of incomplete recognition results, intelligent, automatic processing can not provide any valuable reference information, can not filter non-voice content of broadcast TV data, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
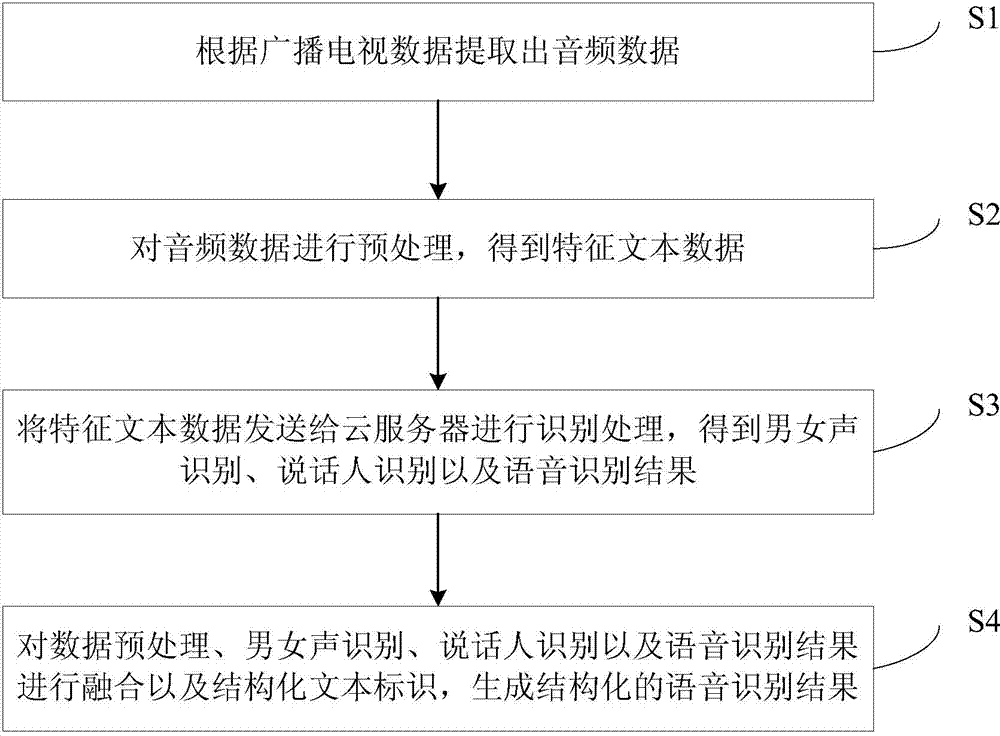
[0061] Embodiment 1 of the present invention provides a radio and television voice recognition method, the steps of which are as follows figure 1 As shown, it specifically includes the following steps:
[0062] Step S1, extracting audio data according to broadcast TV data.
[0063] Step S2, preprocessing the audio data to obtain feature text data.
[0064] Step S3, sending the characteristic text data to the cloud server for recognition processing, and obtaining male and female voice recognition, speaker recognition and speech recognition results;
[0065] Step S4, performing fusion and structured text identification on data preprocessing, male and female voice recognition, speaker recognition and speech recognition results to generate a structured speech recognition result.
[0066] The above method first extracts the audio data from the radio and television data to be identified (that is, audio and video data) provided by the user, and obtains the characteristic text data ...
Embodiment 2
[0128] Embodiment 2 of the present invention also provides a radio and television speech recognition system, the composition diagram is as follows Figure 5 As shown, the system includes:
[0129] An extracting unit 10 extracts audio data according to broadcast television data;
[0130] The preprocessing terminal 20 preprocesses the audio data to obtain feature text data and sends it to the cloud server 30;
[0131] The cloud server 30 performs recognition processing on the feature text data to obtain a speech recognition result, and performs fusion and structured text identification on the speech recognition results to generate a structured speech recognition result.
[0132] Preferably, the schematic diagram of the composition of the preprocessing terminal 20 in this embodiment is as follows Image 6 shown, including:
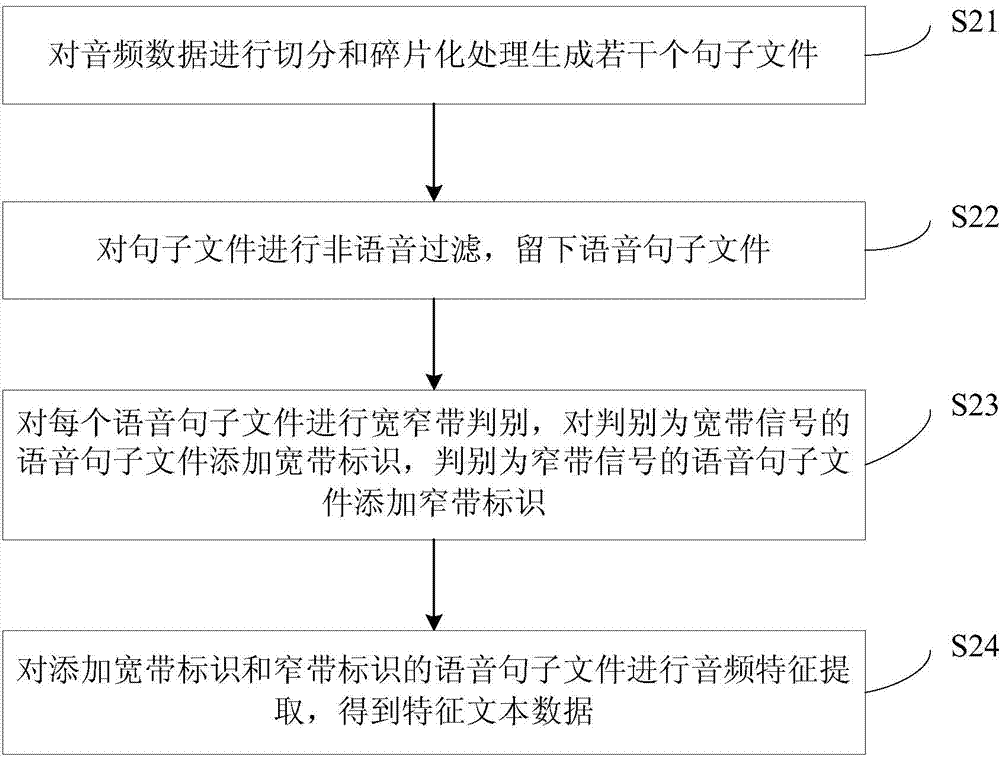
[0133] Segmentation module 21, audio data is carried out segmentation and fragmentation processing and generates several sentence files;
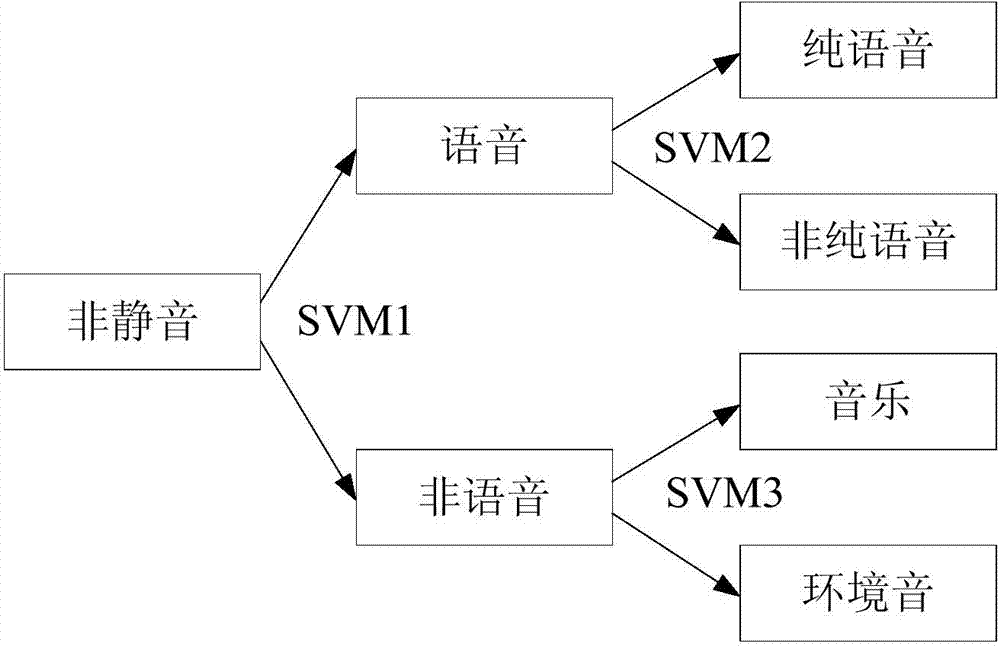
[0134] Non-spe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More