Method and system for radio and television speech recognition system
What is AI technical title?
AI technical title is built by Patsnap AI team. It summarizes the technical point description of the patent document.
A speech recognition, radio and television technology, applied in the field of audio and video processing, can solve the problems of affecting the processing speed, unable to mark the time stamp, consuming resources, etc.
Active Publication Date: 2016-08-17
北京中科模识科技有限公司
View PDF5 Cites 0 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
[0004] 1) The radio and television industry often has special processing and operations for speech recognition that are different from other industries. However, because the above-mentioned traditional speech recognition is applied to various industries, it is not targeted for the radio and television industry, and cannot be based on the characteristics of the radio and television industry. Filtering of non-speech content in broadcast TV data
Because non-speech content is not within the scope of processing for speech recognition in the radio and television industry, if non-speech content is not filtered, it needs to be transmitted and processed, which not only leads to waste of transmission resources and computing resources, but also It will also cause more misrecognition operations due to the existence of non-speech content, and affect the processing speed
[0005] 2) Because the traditional voice recognition technology does not have the voice recognition function for the radio and television industry, the recognition results are not complete. The content is segmented according to different speakers, and the time stamp of each voice word cannot be identified, and it cannot provide any valuable reference information for the subsequent intelligent and automatic processing of other broadcast and television services
[0006] In summary, the application of traditional speech recognition methods in the broadcasting and television industry has problems such as resource consumption, slow processing speed, low accuracy, and insufficient information provided.
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
Embodiment 1
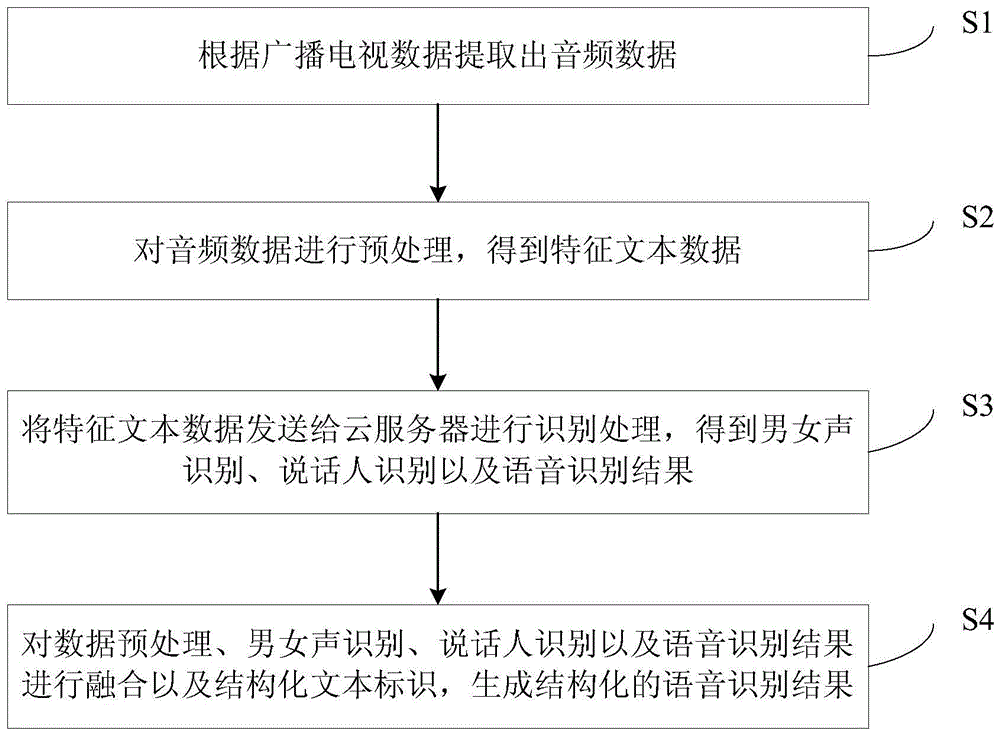
[0061] Embodiment 1 of the present invention provides a radio and television voice recognition method, the steps of which are as follows figure 1 As shown, it specifically includes the following steps:
[0062] Step S1, extracting audio data according to broadcast TV data.
[0063] Step S2, preprocessing the audio data to obtain feature text data.
[0064] Step S3, sending the characteristic text data to the cloud server for recognition processing, and obtaining male and female voice recognition, speaker recognition and speech recognition results;
[0065] Step S4, performing fusion and structured text identification on data preprocessing, male and female voice recognition, speaker recognition and speech recognition results to generate a structured speech recognition result.
[0066] The above method first extracts the audio data from the radio and television data to be identified (that is, audio and video data) provided by the user, and obtains the characteristic text data ...
Embodiment 2
[0128] Embodiment 2 of the present invention also provides a radio and television speech recognition system, the composition diagram is as follows Figure 5 As shown, the system includes:
[0129] An extracting unit 10 extracts audio data according to broadcast television data;
[0130] The preprocessing terminal 20 preprocesses the audio data to obtain feature text data and sends it to the cloud server 30;
[0131] The cloud server 30 performs recognition processing on the feature text data to obtain a speech recognition result, and performs fusion and structured text identification on the speech recognition results to generate a structured speech recognition result.
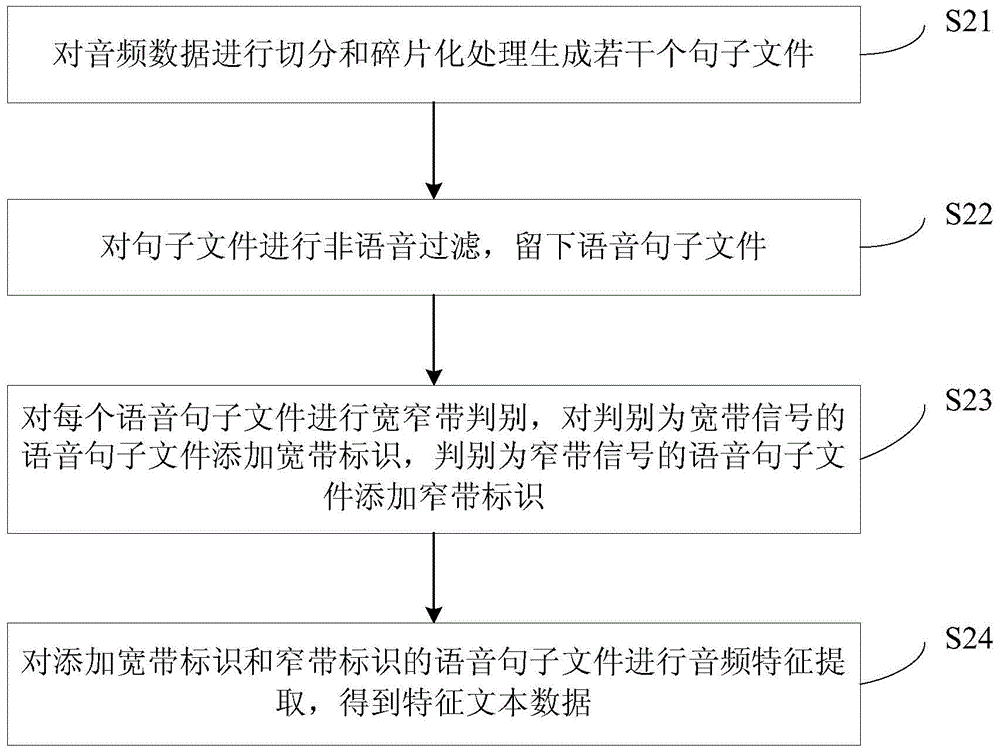
[0132] Preferably, the schematic diagram of the composition of the preprocessing terminal 20 in this embodiment is as follows Figure 6 shown, including:
[0133] Segmentation module 21, audio data is carried out segmentation and fragmentation processing and generates several sentence files;
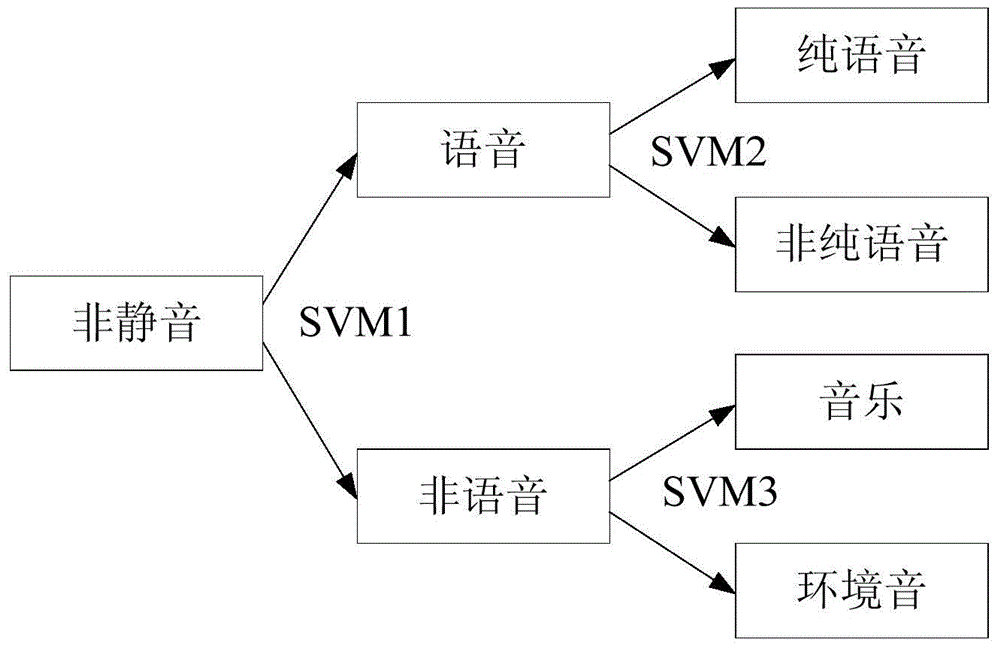
[0134] Non-sp...
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
The invention discloses a broadcast television voice recognition method and system. The method comprises the following steps: extracting audio data according to broadcast television data; pre-processing the audio data to obtain feature text data; transmitting the feature text data to a cloud server for recognition to achieve male and female voice recognition, speaker recognition and voice recognition results; fusing the male and female voice recognition, speaker recognition and voice recognition results and marking a structured text to generate a structured voice recognition result. According to the method, the conventional voice recognition method is improved; various broadcast television data pre-processing technologies and broadcast television voice recognition methods are integrated; voice data is identified to meet data processing requirements in broadcast television industry; various recognition results are integrated to generate the structured voice recognition result; basic data can be provided for intelligent processing of other service of subsequent broadcast television programs; processing speed is increased; the accuracy is improved.
Description
technical field [0001] The invention relates to the technical field of audio and video processing, in particular to a radio and television voice recognition method and system. Background technique [0002] At present, in the field of radio and television, traditional speech recognition methods suitable for various industries are mainly used for radio and television speech recognition, and traditional speech recognition mainly uses pattern matching method, which is divided into two stages: training and recognition. In the training stage, the user will Each word in the vocabulary is read or spoken in turn, and its feature vector is stored as a template in the template library; in the recognition stage, the feature vector of the input speech is compared with each template in the template library in turn, and the The one with the highest similarity is output as the recognition result. [0003] But the voice recognition of this voice recognition application has the following pro...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



 Login to View More
Login to View More  Login to View More
Login to View More