

Parallel Feature Extraction System and Method for General Specific Speech in Speech Signal
A speech signal and feature extraction technology, applied in speech analysis, speech recognition, instruments, etc., can solve the problems of low recognition accuracy, low integration accuracy, and uncommon emotion recognition task models, so as to improve recognition accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
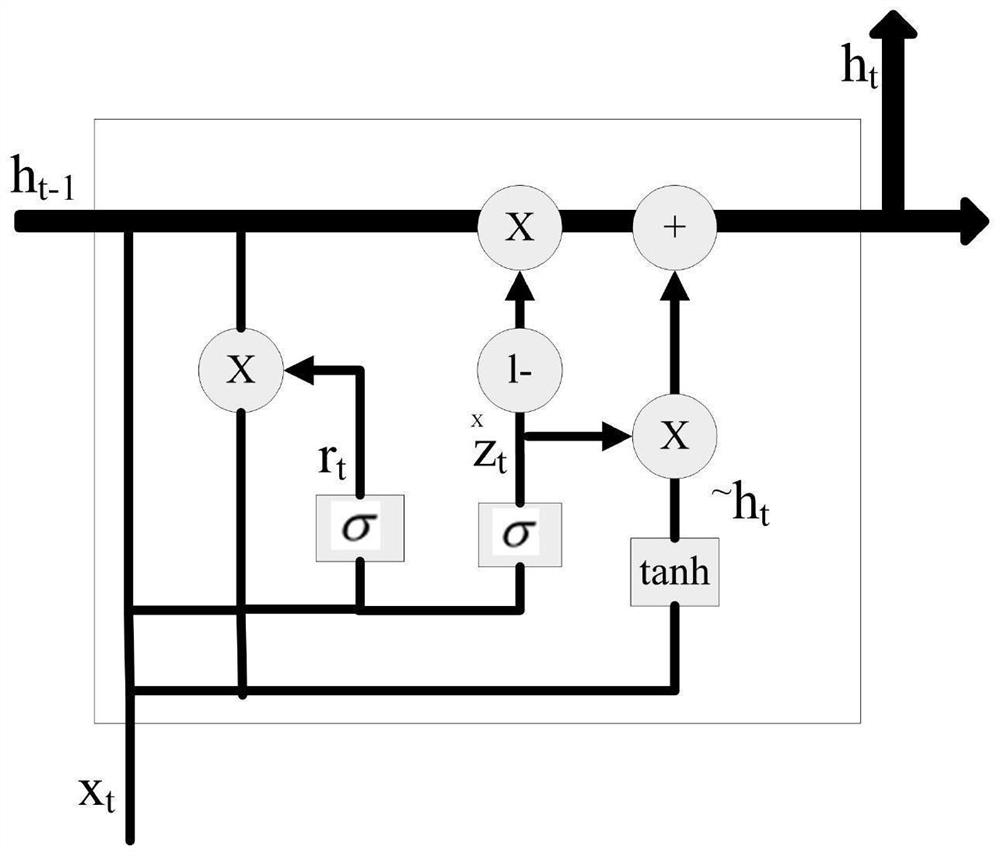
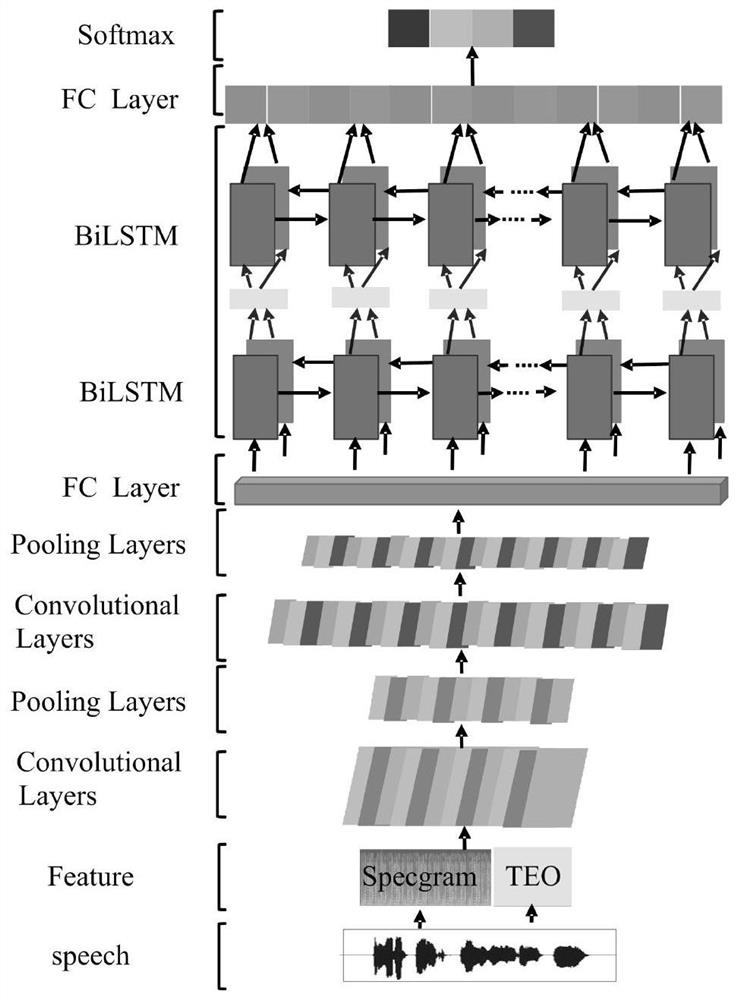
[0092] The present invention will be further described below in conjunction with accompanying drawing:
[0093] The model of the present invention mainly includes a voice signal, an emotion recognition model, a voiceprint recognition model and a speech recognition model;
[0094] Described spectrogram is the display image of the Fourier analysis of speech signal, and spectrogram is a kind of three-dimensional frequency spectrum, represents the graph that speech spectrum changes with time, and its vertical axis is frequency, and horizontal axis is time; Any given The intensity of a frequency component at a given moment is represented by the shade of gray or tone at the corresponding point. The acquisition method is as follows: For a piece of speech signal x(t), first divide it into frames and change it to x(m,n) (n is the frame length, m is the number of frames), perform fast Fourier transform, and obtain X(m,n ), get the periodogram Y(m,n)(Y(m,n)=X(m,n)*X(m,n)'), take 10*log1...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More