Method and system for developing data integration applications with reusable functional rules that are managed according to their output variables
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035]I. Introduction
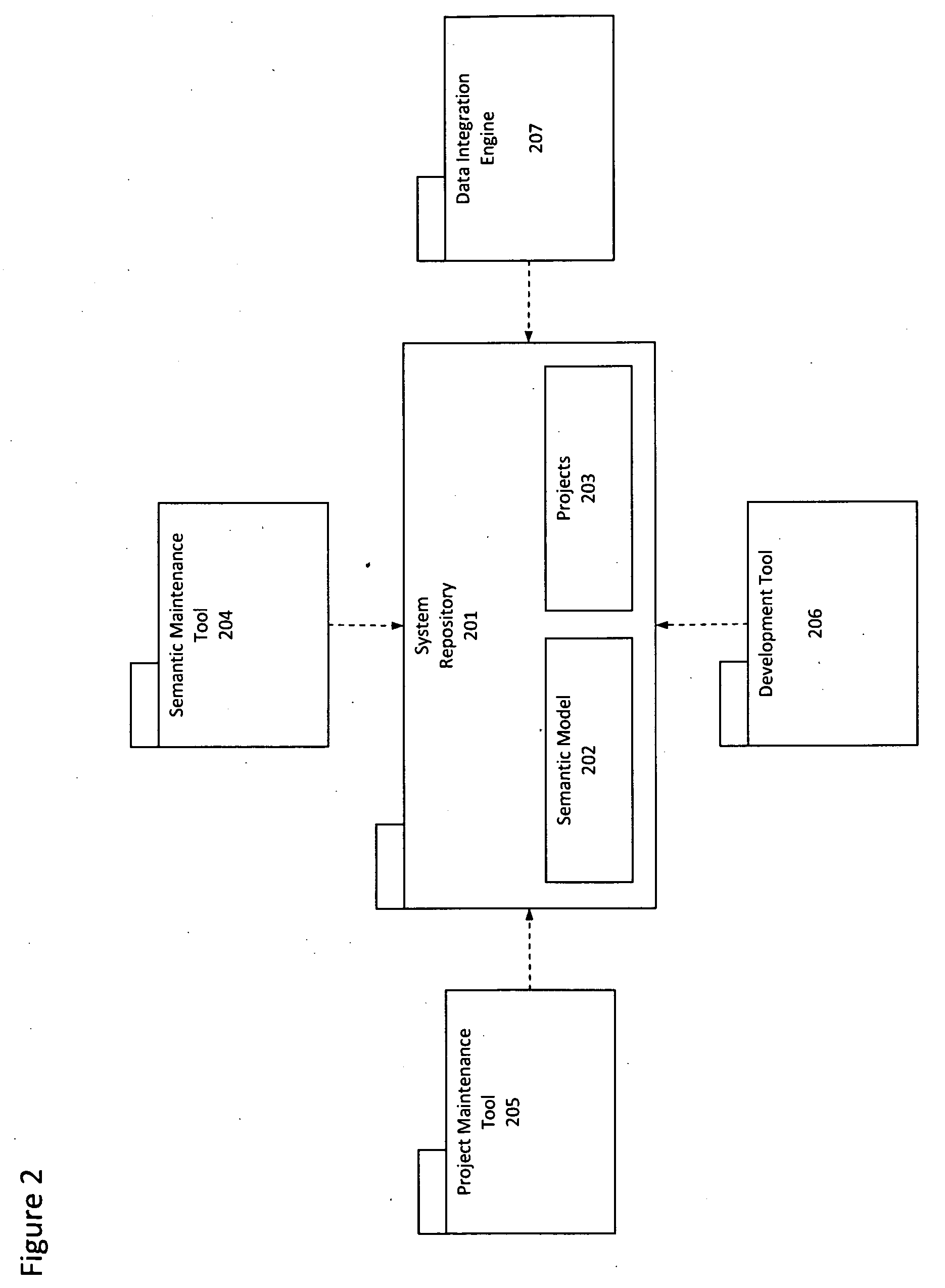
[0036]Preferred embodiments of the present invention provide semantic systems and methods for developing, deploying, running, maintaining, and analyzing data integration applications and environments.
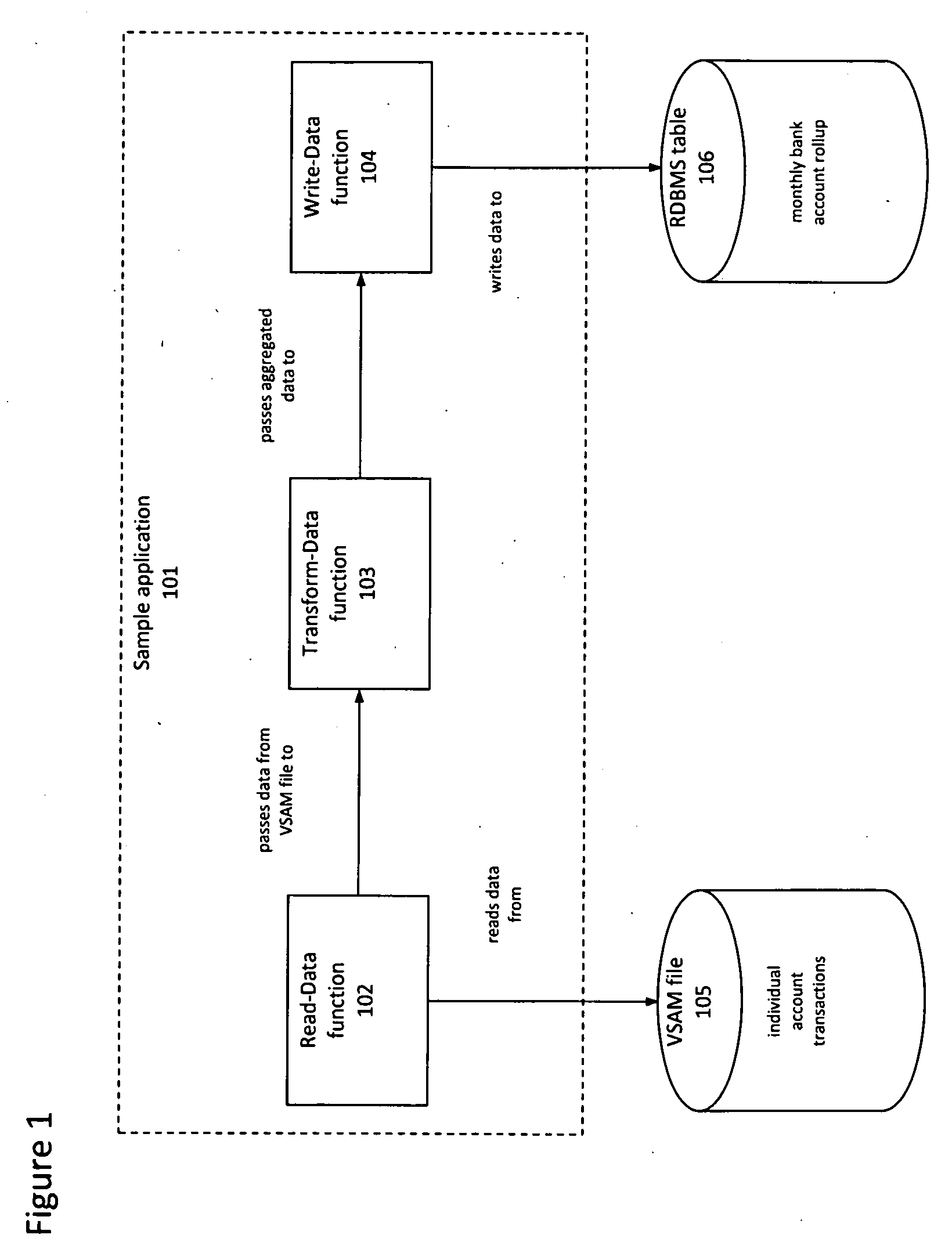
[0037]Those data integration applications that are relevant to the techniques described herein are broadly described by the class of applications concerned with the movement and transformation of data between systems and commonly represented by, but not limited to: data warehousing or ETL (extract-transform-load) applications, data profiling and data quality applications, and data migration applications that are concerned with moving data from old to new systems.
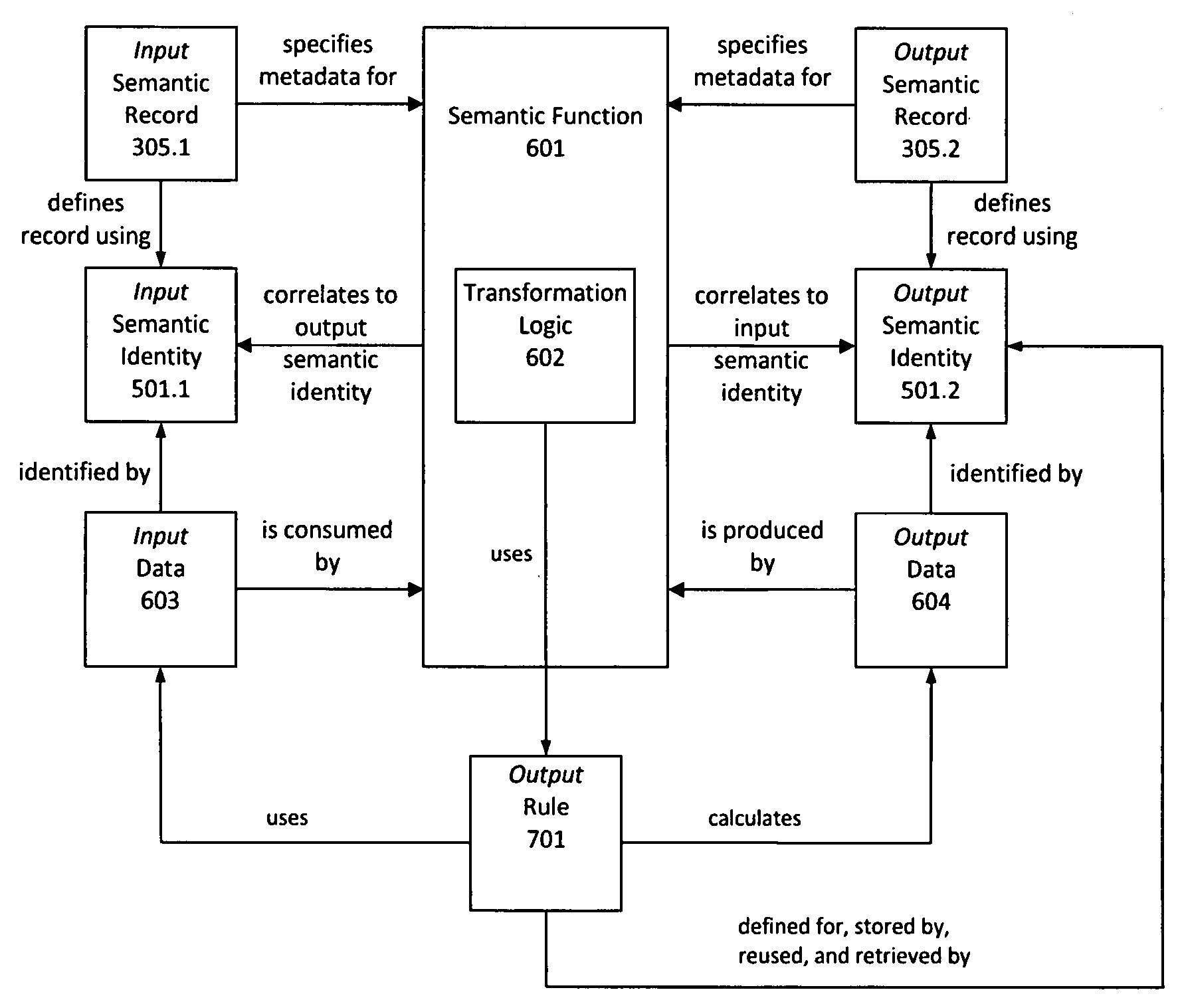
[0038]Data integration applications developed and maintained using these techniques are developed using a semantic model. At its core, a semantic development model enables an application to be partially or fully developed without knowledge of the physical data identities (locations, structures, names, types,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



