

Architectures For Energy-Efficient In-Memory Computing Accelerators In AI Workloads
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
IMC Technology Background and Objectives
In-Memory Computing (IMC) represents a paradigm shift in computing architecture, evolving from the traditional von Neumann architecture that has dominated computing for decades. The conventional separation between processing and memory units has led to the well-known "memory wall" problem, where data transfer between these units creates significant bottlenecks in performance and energy efficiency. This limitation has become increasingly critical as artificial intelligence workloads continue to demand unprecedented computational resources.
The evolution of IMC technology can be traced back to the early 2000s, with fundamental research in resistive memory devices. However, it has gained substantial momentum in the past decade due to the exponential growth in AI applications and the corresponding need for more efficient computing solutions. The technology has progressed from theoretical concepts to practical implementations, with various architectural approaches emerging to address specific computational challenges.
The primary objective of energy-efficient IMC accelerators is to minimize data movement by performing computations directly within memory arrays. This approach aims to drastically reduce energy consumption while simultaneously increasing computational throughput for AI workloads. Current research indicates that IMC architectures can potentially achieve 10-100x improvements in energy efficiency compared to conventional computing systems for specific AI tasks.
Technical goals for IMC accelerators in AI workloads include developing scalable architectures that can handle diverse neural network models, optimizing memory cell designs for computational efficiency, addressing precision and reliability challenges inherent in analog computing, and creating programming models that abstract hardware complexities. Additionally, there is a focus on developing hybrid systems that intelligently combine IMC with traditional computing paradigms to maximize overall system performance.
The technology trajectory suggests a convergence toward heterogeneous computing systems where IMC accelerators handle specific computational kernels within larger AI workflows. This evolution is driven by the recognition that different computational patterns benefit from different architectural approaches. Current research emphasizes the development of specialized IMC accelerators for matrix multiplication, convolution operations, and other compute-intensive functions common in deep learning models.
As AI continues to permeate various industries and applications, the demand for energy-efficient computing solutions becomes increasingly urgent. IMC technology represents one of the most promising approaches to address this challenge, potentially enabling the next generation of AI systems that can operate within strict power constraints while delivering the computational performance required for advanced AI applications.
The evolution of IMC technology can be traced back to the early 2000s, with fundamental research in resistive memory devices. However, it has gained substantial momentum in the past decade due to the exponential growth in AI applications and the corresponding need for more efficient computing solutions. The technology has progressed from theoretical concepts to practical implementations, with various architectural approaches emerging to address specific computational challenges.
The primary objective of energy-efficient IMC accelerators is to minimize data movement by performing computations directly within memory arrays. This approach aims to drastically reduce energy consumption while simultaneously increasing computational throughput for AI workloads. Current research indicates that IMC architectures can potentially achieve 10-100x improvements in energy efficiency compared to conventional computing systems for specific AI tasks.
Technical goals for IMC accelerators in AI workloads include developing scalable architectures that can handle diverse neural network models, optimizing memory cell designs for computational efficiency, addressing precision and reliability challenges inherent in analog computing, and creating programming models that abstract hardware complexities. Additionally, there is a focus on developing hybrid systems that intelligently combine IMC with traditional computing paradigms to maximize overall system performance.
The technology trajectory suggests a convergence toward heterogeneous computing systems where IMC accelerators handle specific computational kernels within larger AI workflows. This evolution is driven by the recognition that different computational patterns benefit from different architectural approaches. Current research emphasizes the development of specialized IMC accelerators for matrix multiplication, convolution operations, and other compute-intensive functions common in deep learning models.
As AI continues to permeate various industries and applications, the demand for energy-efficient computing solutions becomes increasingly urgent. IMC technology represents one of the most promising approaches to address this challenge, potentially enabling the next generation of AI systems that can operate within strict power constraints while delivering the computational performance required for advanced AI applications.
AI Workload Market Demand Analysis
The global AI workload market is experiencing unprecedented growth, driven by the increasing adoption of artificial intelligence across various industries. According to recent market research, the AI chip market is projected to reach $83.2 billion by 2027, growing at a CAGR of 35.8% from 2022. This remarkable growth is primarily fueled by the escalating demand for energy-efficient computing solutions capable of handling complex AI workloads.
Traditional computing architectures face significant challenges in meeting the computational demands of modern AI applications. The von Neumann bottleneck, characterized by the separation between processing and memory units, creates substantial energy inefficiencies when processing data-intensive AI workloads. This has created a strong market pull for in-memory computing accelerators that can reduce energy consumption while maintaining or improving performance.
Enterprise sectors, particularly cloud service providers and data centers, represent the largest market segment for energy-efficient AI accelerators. These organizations face mounting pressure to reduce operational costs and carbon footprints while handling increasingly complex AI workloads. The data center power consumption attributed to AI workloads has grown by 25% annually since 2020, creating urgent demand for more efficient computing architectures.
Edge computing represents another rapidly expanding market segment, with projections indicating a market size of $43.4 billion by 2027 for edge AI hardware. Battery-powered devices and IoT applications require ultra-low power consumption while maintaining adequate computational capabilities for AI inference tasks. This segment demands in-memory computing solutions that can operate within strict power envelopes of milliwatts or even microwatts.
Industry-specific AI applications are driving specialized demand patterns. Healthcare imaging analysis, autonomous vehicles, industrial automation, and financial services each present unique computational requirements and energy constraints. The healthcare AI hardware market alone is expected to reach $14.6 billion by 2026, with medical imaging analysis demanding both high computational throughput and energy efficiency.
The market is increasingly segmenting between training and inference solutions. While training workloads typically occur in controlled data center environments with access to substantial power resources, inference workloads are more distributed and often operate under strict energy constraints. This bifurcation is creating distinct market opportunities for specialized in-memory computing architectures optimized for either training or inference scenarios.
Geographically, North America currently leads the market for AI accelerators, followed by Asia-Pacific and Europe. However, the Asia-Pacific region is experiencing the fastest growth rate, driven by substantial investments in AI infrastructure in China, South Korea, and Taiwan. This regional diversification presents both opportunities and challenges for technology providers developing energy-efficient in-memory computing solutions.
Traditional computing architectures face significant challenges in meeting the computational demands of modern AI applications. The von Neumann bottleneck, characterized by the separation between processing and memory units, creates substantial energy inefficiencies when processing data-intensive AI workloads. This has created a strong market pull for in-memory computing accelerators that can reduce energy consumption while maintaining or improving performance.
Enterprise sectors, particularly cloud service providers and data centers, represent the largest market segment for energy-efficient AI accelerators. These organizations face mounting pressure to reduce operational costs and carbon footprints while handling increasingly complex AI workloads. The data center power consumption attributed to AI workloads has grown by 25% annually since 2020, creating urgent demand for more efficient computing architectures.
Edge computing represents another rapidly expanding market segment, with projections indicating a market size of $43.4 billion by 2027 for edge AI hardware. Battery-powered devices and IoT applications require ultra-low power consumption while maintaining adequate computational capabilities for AI inference tasks. This segment demands in-memory computing solutions that can operate within strict power envelopes of milliwatts or even microwatts.
Industry-specific AI applications are driving specialized demand patterns. Healthcare imaging analysis, autonomous vehicles, industrial automation, and financial services each present unique computational requirements and energy constraints. The healthcare AI hardware market alone is expected to reach $14.6 billion by 2026, with medical imaging analysis demanding both high computational throughput and energy efficiency.
The market is increasingly segmenting between training and inference solutions. While training workloads typically occur in controlled data center environments with access to substantial power resources, inference workloads are more distributed and often operate under strict energy constraints. This bifurcation is creating distinct market opportunities for specialized in-memory computing architectures optimized for either training or inference scenarios.
Geographically, North America currently leads the market for AI accelerators, followed by Asia-Pacific and Europe. However, the Asia-Pacific region is experiencing the fastest growth rate, driven by substantial investments in AI infrastructure in China, South Korea, and Taiwan. This regional diversification presents both opportunities and challenges for technology providers developing energy-efficient in-memory computing solutions.
IMC Technical Challenges and Global Development Status
In-Memory Computing (IMC) technology faces several critical technical challenges that have shaped its global development trajectory. The fundamental challenge lies in the integration of computing capabilities directly into memory structures, which requires overcoming the traditional von Neumann bottleneck where data transfer between processing and memory units creates significant energy consumption and performance limitations.
Material selection presents a significant hurdle for IMC accelerators. While emerging non-volatile memories such as RRAM, PCM, and STT-MRAM offer promising characteristics for IMC applications, they still struggle with issues of endurance, reliability, and manufacturing scalability. These materials must simultaneously function as both storage elements and computational units, requiring precise control of their electrical properties.
Circuit design complexity represents another major challenge. Analog computing within memory arrays demands sophisticated peripheral circuits for precise signal conditioning, while managing parasitic effects and noise that can severely impact computational accuracy. The design of efficient analog-to-digital converters (ADCs) and digital-to-analog converters (DACs) with minimal area and power overhead remains particularly challenging.
From a system architecture perspective, integrating IMC accelerators into existing AI frameworks requires significant modifications to compiler toolchains and programming models. The lack of standardized interfaces and programming abstractions for IMC technologies has hindered widespread adoption despite their theoretical advantages.
Globally, IMC development has seen concentrated efforts in several regions. The United States leads in fundamental research through institutions like Stanford, MIT, and industry players including IBM and Intel. Their focus has been on novel device physics and system-level integration. Asia, particularly China, Taiwan, and South Korea, has emphasized manufacturing scalability and integration with existing semiconductor processes, with companies like TSMC and Samsung making significant investments.
European research centers have contributed substantially to theoretical foundations and algorithm development for IMC systems, particularly in neuromorphic computing applications. The European Commission has funded several large-scale initiatives under Horizon programs to advance IMC technologies.
Recent global development trends show increasing collaboration between academic institutions and industry partners to bridge the gap between theoretical advantages of IMC and practical implementation challenges. International consortia have formed to address standardization issues and develop benchmarking methodologies specific to IMC accelerators for AI workloads.
Despite these collaborative efforts, significant regional differences exist in research focus and commercialization strategies, reflecting varying national priorities in semiconductor independence and AI leadership.
Material selection presents a significant hurdle for IMC accelerators. While emerging non-volatile memories such as RRAM, PCM, and STT-MRAM offer promising characteristics for IMC applications, they still struggle with issues of endurance, reliability, and manufacturing scalability. These materials must simultaneously function as both storage elements and computational units, requiring precise control of their electrical properties.
Circuit design complexity represents another major challenge. Analog computing within memory arrays demands sophisticated peripheral circuits for precise signal conditioning, while managing parasitic effects and noise that can severely impact computational accuracy. The design of efficient analog-to-digital converters (ADCs) and digital-to-analog converters (DACs) with minimal area and power overhead remains particularly challenging.
From a system architecture perspective, integrating IMC accelerators into existing AI frameworks requires significant modifications to compiler toolchains and programming models. The lack of standardized interfaces and programming abstractions for IMC technologies has hindered widespread adoption despite their theoretical advantages.
Globally, IMC development has seen concentrated efforts in several regions. The United States leads in fundamental research through institutions like Stanford, MIT, and industry players including IBM and Intel. Their focus has been on novel device physics and system-level integration. Asia, particularly China, Taiwan, and South Korea, has emphasized manufacturing scalability and integration with existing semiconductor processes, with companies like TSMC and Samsung making significant investments.
European research centers have contributed substantially to theoretical foundations and algorithm development for IMC systems, particularly in neuromorphic computing applications. The European Commission has funded several large-scale initiatives under Horizon programs to advance IMC technologies.
Recent global development trends show increasing collaboration between academic institutions and industry partners to bridge the gap between theoretical advantages of IMC and practical implementation challenges. International consortia have formed to address standardization issues and develop benchmarking methodologies specific to IMC accelerators for AI workloads.
Despite these collaborative efforts, significant regional differences exist in research focus and commercialization strategies, reflecting varying national priorities in semiconductor independence and AI leadership.
Current Energy-Efficient IMC Architectures
01 Memory-centric computing architectures
Memory-centric computing architectures integrate processing capabilities directly within memory components to reduce data movement between memory and processing units. This approach significantly improves energy efficiency by minimizing the energy-intensive data transfers that occur in conventional computing systems. These architectures enable computation to happen where data resides, reducing latency and power consumption associated with moving data across the memory hierarchy.- Memory-centric computing architectures: Memory-centric computing architectures integrate processing capabilities directly within memory components to reduce data movement between memory and processing units. This approach significantly improves energy efficiency by minimizing the energy-intensive data transfers that occur in conventional computing systems. These architectures enable computational operations to be performed where data resides, reducing latency and power consumption associated with moving data across the memory hierarchy.
- Near-memory and in-memory processing techniques: Near-memory and in-memory processing techniques involve placing computational elements closer to or directly within memory arrays. These approaches reduce the physical distance data needs to travel, thereby decreasing energy consumption and latency. By performing computations directly within memory structures, these techniques eliminate the need for frequent data transfers between separate processing and storage units, resulting in significant energy efficiency improvements for data-intensive applications.
- Power management strategies for in-memory computing: Advanced power management strategies specifically designed for in-memory computing systems help optimize energy consumption. These include dynamic voltage and frequency scaling, selective activation of memory regions, power gating unused components, and intelligent workload scheduling. Such techniques allow systems to adapt their power consumption based on computational demands, ensuring energy is used efficiently while maintaining performance requirements.
- Novel memory technologies for energy-efficient computing: Emerging non-volatile memory technologies such as resistive RAM, phase-change memory, and magnetoresistive RAM offer inherent advantages for energy-efficient in-memory computing. These technologies consume less power than traditional DRAM and can retain data without continuous power supply. When integrated into computing accelerators, they enable persistent storage with lower standby power, faster access times, and the ability to perform certain computational operations directly within the memory structure.
- System-level optimization for in-memory accelerators: System-level optimization approaches for in-memory computing accelerators include specialized hardware-software co-design, efficient data mapping strategies, and workload-aware resource allocation. These optimizations ensure that the entire computing stack is aligned to maximize energy efficiency. By considering the interaction between hardware accelerators, memory subsystems, and application requirements, these approaches minimize unnecessary operations and data movements, resulting in substantial energy savings.
02 Power management techniques for in-memory computing
Various power management techniques are employed in in-memory computing accelerators to optimize energy efficiency. These include dynamic voltage and frequency scaling, selective power gating of inactive components, and intelligent workload distribution. Advanced power states and context-aware power management allow systems to adapt their energy consumption based on computational demands, significantly reducing overall power consumption while maintaining performance requirements.Expand Specific Solutions03 Novel memory cell designs for computing
Specialized memory cell designs enable computational capabilities within memory arrays while maintaining energy efficiency. These include resistive, phase-change, and magnetoresistive memory technologies that can perform logical and arithmetic operations directly within the memory fabric. By leveraging the physical properties of these memory technologies, computational operations can be performed with minimal energy expenditure, significantly improving the energy efficiency of in-memory computing accelerators.Expand Specific Solutions04 Data flow optimization for energy efficiency
Optimizing data flow patterns in in-memory computing accelerators significantly enhances energy efficiency. This involves techniques such as data locality exploitation, minimizing redundant data movements, and implementing efficient data access patterns. Advanced data mapping strategies ensure that computations are performed with minimal data transfers, reducing the energy overhead associated with moving data between memory and processing elements.Expand Specific Solutions05 Hardware-software co-design approaches
Hardware-software co-design approaches optimize the energy efficiency of in-memory computing accelerators by ensuring that hardware architectures and software implementations work synergistically. This includes developing specialized instruction sets, compiler optimizations, and runtime systems that are aware of the underlying in-memory computing architecture. By jointly optimizing hardware and software components, these approaches minimize unnecessary operations and data movements, leading to significant improvements in energy efficiency.Expand Specific Solutions
Key IMC Accelerator Industry Players
The in-memory computing accelerator market for AI workloads is currently in a growth phase, with increasing demand driven by AI's computational requirements. The market is expanding rapidly, estimated to reach several billion dollars by 2025. Technologically, the field shows varying maturity levels across players. Industry leaders like Intel, IBM, and Samsung have established robust architectures, while TSMC provides advanced manufacturing capabilities. Qualcomm and Huawei are leveraging their mobile expertise for edge AI applications. Emerging players like Rain Neuromorphics and Shanghai Tianshu Zhixin are introducing innovative neuromorphic approaches. Academic institutions including Tsinghua University and USC are contributing fundamental research. The competitive landscape reflects a balance between established semiconductor giants focusing on optimization and startups pursuing novel architectural paradigms.
Intel Corp.
Technical Solution: Intel has developed Compute-in-Memory (CiM) architectures focusing on both SRAM and emerging non-volatile memory technologies. Their SRAM-based accelerator design implements bit-line computing techniques that enable parallel MAC operations directly within memory arrays, achieving energy efficiencies of up to 10 TOPS/W for 8-bit operations. Intel's Loihi neuromorphic research chip incorporates in-memory computing principles with 130,000 neurons and 130 million synapses arranged in a mesh network of 128 neuromorphic cores. For deep learning inference, Intel has demonstrated 3D-stacked RRAM (Resistive RAM) architectures that reduce energy consumption by 85% compared to conventional GPU implementations by minimizing data movement between memory and processing units. Their Optane DC Persistent Memory technology, while primarily focused on storage, has been adapted for certain in-memory computing applications requiring persistence.
Strengths: Intel's solutions leverage their advanced manufacturing capabilities and ecosystem integration, allowing for practical deployment in existing computing environments. Their neuromorphic approaches show particular promise for edge AI applications with strict power constraints. Weaknesses: Some of Intel's in-memory computing technologies remain in research phases rather than commercial products. Their SRAM-based approaches face density limitations compared to emerging memory technologies like RRAM or PCM.
International Business Machines Corp.
Technical Solution: IBM has pioneered in-memory computing architectures through their Phase-Change Memory (PCM) technology and Analog AI accelerators. Their Digital In-Memory Compute (DIMC) approach integrates computation directly within SRAM arrays, enabling massively parallel vector-matrix multiplications essential for AI workloads. IBM's True North and subsequent neuromorphic chips implement synaptic operations directly in memory, achieving energy efficiencies of 4 TOPS/W. Their Analog AI accelerator demonstrated 8-bit precision for inference tasks while consuming only 0.6 pJ per operation. The company's Resistive Processing Unit (RPU) architecture combines non-volatile memory with analog computing elements to perform neural network operations with minimal data movement, addressing the von Neumann bottleneck that traditionally limits energy efficiency.
Strengths: IBM's solutions offer exceptional energy efficiency (>10x improvement over conventional architectures) and reduced latency by minimizing data movement. Their mature fabrication processes enable practical implementation at scale. Weaknesses: Analog computing approaches face precision and reliability challenges, particularly for training workloads requiring high accuracy. Temperature sensitivity of memory elements can affect computational stability in variable environments.
Core IMC Patents and Technical Innovations
Two-dimensional mesh for compute-in-memory accelerator architecture
PatentWO2023186503A1
Innovation
- A heterogeneous and programmable CIM accelerator architecture featuring a two-dimensional mesh interconnect that integrates spatially-distributed CIM memory-array tiles for energy-efficient MAC operations and specialized compute-cores for auxiliary digital computations, supporting a wide range of DNN workloads through a 2D grid of tiles and compute-cores interconnected by a 2D mesh, enabling efficient data transport and pipelining across various mini-batch sizes.
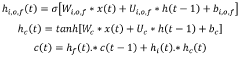
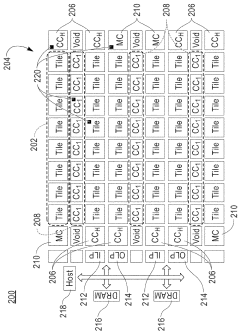
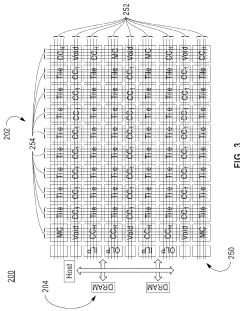
Novel in-memory computing architecture supporting various workloads
PatentActiveCN118132507A
Innovation
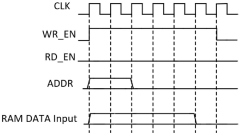
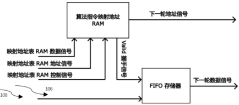
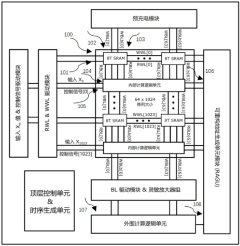
- A new in-memory computing architecture is designed, including an in-memory computing array, a precharge module, a read word line and a write word line driver module, an input value and control signal driver module, a bit line driver module, a sensitive amplifier group, and a peripheral computing logic module. And the reconfigurable address generation unit module, through the combination of these modules, efficient calculation and general processing of data can be achieved.
Energy Efficiency Metrics and Benchmarking
Evaluating energy efficiency in in-memory computing (IMC) accelerators requires standardized metrics and benchmarking methodologies that accurately reflect real-world AI workload performance. The most widely adopted metric is Operations Per Second per Watt (OPS/W), which quantifies computational throughput relative to power consumption. This metric enables direct comparison between different IMC architectures and conventional computing systems, revealing the energy advantage of memory-centric approaches.
Beyond raw efficiency metrics, researchers have developed more nuanced evaluation frameworks such as Energy-Delay Product (EDP) and Energy-Delay-Area Product (EDAP), which incorporate latency and silicon area considerations. These compound metrics provide a more holistic view of IMC accelerator performance, particularly important when evaluating designs for edge AI applications where both energy and response time are critical constraints.
Benchmarking methodologies for IMC accelerators have evolved to include standardized AI workload suites that represent diverse computational patterns. MLPerf, an industry-standard benchmark suite, has been adapted specifically for IMC architectures to ensure fair comparison across different implementation technologies. These benchmarks typically include convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformer models that stress different aspects of memory-compute integration.
Granular power profiling has emerged as an essential benchmarking practice, with researchers now separately measuring dynamic computation energy, leakage power, and data movement costs. This detailed analysis helps identify energy bottlenecks specific to IMC architectures, such as analog-to-digital conversion overhead in resistive memory implementations or sensing amplifier power in SRAM-based designs.
Temperature sensitivity presents a unique challenge for IMC benchmarking, as many emerging memory technologies exhibit performance characteristics that vary significantly with operating temperature. Standardized benchmarking protocols now include temperature-controlled testing environments and report energy efficiency across temperature ranges to provide more realistic performance expectations.
Recent advances in benchmarking also address the accuracy-efficiency tradeoff inherent in many IMC designs. Metrics like Energy-Accuracy Product (EAP) have been proposed to quantify how architectural choices impact both computational efficiency and model accuracy, particularly important for IMC systems that introduce quantization or other approximation techniques to improve energy efficiency.
Beyond raw efficiency metrics, researchers have developed more nuanced evaluation frameworks such as Energy-Delay Product (EDP) and Energy-Delay-Area Product (EDAP), which incorporate latency and silicon area considerations. These compound metrics provide a more holistic view of IMC accelerator performance, particularly important when evaluating designs for edge AI applications where both energy and response time are critical constraints.
Benchmarking methodologies for IMC accelerators have evolved to include standardized AI workload suites that represent diverse computational patterns. MLPerf, an industry-standard benchmark suite, has been adapted specifically for IMC architectures to ensure fair comparison across different implementation technologies. These benchmarks typically include convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformer models that stress different aspects of memory-compute integration.
Granular power profiling has emerged as an essential benchmarking practice, with researchers now separately measuring dynamic computation energy, leakage power, and data movement costs. This detailed analysis helps identify energy bottlenecks specific to IMC architectures, such as analog-to-digital conversion overhead in resistive memory implementations or sensing amplifier power in SRAM-based designs.
Temperature sensitivity presents a unique challenge for IMC benchmarking, as many emerging memory technologies exhibit performance characteristics that vary significantly with operating temperature. Standardized benchmarking protocols now include temperature-controlled testing environments and report energy efficiency across temperature ranges to provide more realistic performance expectations.
Recent advances in benchmarking also address the accuracy-efficiency tradeoff inherent in many IMC designs. Metrics like Energy-Accuracy Product (EAP) have been proposed to quantify how architectural choices impact both computational efficiency and model accuracy, particularly important for IMC systems that introduce quantization or other approximation techniques to improve energy efficiency.
Hardware-Software Co-design Strategies
Hardware-software co-design represents a critical approach for maximizing the efficiency of in-memory computing (IMC) accelerators in AI workloads. This strategy bridges the traditional gap between hardware architecture and software development, creating synergistic solutions that address the unique challenges of IMC implementations.
The fundamental principle of hardware-software co-design for IMC accelerators involves simultaneous optimization of hardware components and software frameworks. Hardware designers must consider the specific requirements of AI algorithms, while software developers need to adapt their implementations to leverage the unique capabilities of IMC architectures. This bidirectional optimization process enables significant improvements in energy efficiency that would be unattainable through isolated hardware or software approaches.
Memory-aware algorithm design constitutes a key element of this co-design strategy. By restructuring neural network operations to minimize data movement and maximize data reuse within memory arrays, developers can substantially reduce energy consumption. Techniques such as operator fusion, computation reordering, and strategic data placement help align algorithmic requirements with the physical constraints of IMC hardware.
Specialized compiler technologies form another crucial component of the co-design approach. These compilers translate high-level AI frameworks (TensorFlow, PyTorch) into optimized instruction sequences for IMC accelerators, incorporating knowledge of the underlying hardware architecture. Advanced mapping techniques ensure efficient utilization of computational resources while respecting the unique characteristics of resistive, capacitive, or magnetic memory arrays.
Runtime management systems provide dynamic optimization capabilities that complement static compiler optimizations. These systems monitor workload characteristics and hardware conditions during execution, making real-time adjustments to voltage levels, precision requirements, and memory access patterns. Such adaptive approaches enable IMC accelerators to maintain optimal energy efficiency across diverse AI applications and operational scenarios.
Cross-layer optimization frameworks facilitate communication between different abstraction levels of the hardware-software stack. These frameworks enable information sharing between application, compiler, runtime, and hardware layers, creating opportunities for holistic optimizations that consider end-to-end system behavior rather than isolated components.
Quantization and precision adaptation strategies represent particularly valuable co-design techniques for IMC accelerators. By carefully analyzing the precision requirements of different neural network layers and dynamically adjusting computational precision, these approaches minimize energy consumption while maintaining acceptable accuracy levels for AI workloads.
The fundamental principle of hardware-software co-design for IMC accelerators involves simultaneous optimization of hardware components and software frameworks. Hardware designers must consider the specific requirements of AI algorithms, while software developers need to adapt their implementations to leverage the unique capabilities of IMC architectures. This bidirectional optimization process enables significant improvements in energy efficiency that would be unattainable through isolated hardware or software approaches.
Memory-aware algorithm design constitutes a key element of this co-design strategy. By restructuring neural network operations to minimize data movement and maximize data reuse within memory arrays, developers can substantially reduce energy consumption. Techniques such as operator fusion, computation reordering, and strategic data placement help align algorithmic requirements with the physical constraints of IMC hardware.
Specialized compiler technologies form another crucial component of the co-design approach. These compilers translate high-level AI frameworks (TensorFlow, PyTorch) into optimized instruction sequences for IMC accelerators, incorporating knowledge of the underlying hardware architecture. Advanced mapping techniques ensure efficient utilization of computational resources while respecting the unique characteristics of resistive, capacitive, or magnetic memory arrays.
Runtime management systems provide dynamic optimization capabilities that complement static compiler optimizations. These systems monitor workload characteristics and hardware conditions during execution, making real-time adjustments to voltage levels, precision requirements, and memory access patterns. Such adaptive approaches enable IMC accelerators to maintain optimal energy efficiency across diverse AI applications and operational scenarios.
Cross-layer optimization frameworks facilitate communication between different abstraction levels of the hardware-software stack. These frameworks enable information sharing between application, compiler, runtime, and hardware layers, creating opportunities for holistic optimizations that consider end-to-end system behavior rather than isolated components.
Quantization and precision adaptation strategies represent particularly valuable co-design techniques for IMC accelerators. By carefully analyzing the precision requirements of different neural network layers and dynamically adjusting computational precision, these approaches minimize energy consumption while maintaining acceptable accuracy levels for AI workloads.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!