

How In-Memory Computing Improves Matrix-Vector Multiplication In Neural Networks
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
In-Memory Computing Evolution and Objectives
In-memory computing represents a paradigm shift in computer architecture that has evolved significantly over the past decade. Traditional von Neumann architectures, characterized by separate processing and memory units, have faced increasing performance bottlenecks due to the "memory wall" - the growing disparity between processor and memory speeds. This limitation becomes particularly pronounced in neural network computations where matrix-vector multiplications dominate the computational workload.
The evolution of in-memory computing began with the recognition that data movement between memory and processing units consumes significant energy and time. Early developments focused on bringing computation closer to memory through 3D stacking and near-memory processing. By 2015, researchers started exploring the possibility of performing computations within memory arrays themselves, particularly using emerging non-volatile memory technologies.
Resistive random-access memory (RRAM), phase-change memory (PCM), and magnetoresistive RAM (MRAM) emerged as promising candidates for in-memory computing due to their ability to both store information and perform analog computations. These technologies enable matrix-vector multiplications to be executed in a single step using physical principles such as Ohm's law and Kirchhoff's current law, dramatically reducing the energy consumption and latency compared to conventional approaches.
The primary objective of in-memory computing for neural networks is to overcome the von Neumann bottleneck by eliminating unnecessary data movement. This approach aims to achieve orders of magnitude improvements in energy efficiency and computational throughput for matrix-vector operations, which constitute over 90% of neural network inference computations.
Another critical goal is to enable edge AI applications by reducing the power consumption of neural network inference to levels compatible with battery-powered devices. This would allow sophisticated AI models to run locally on IoT devices, smartphones, and wearables without requiring cloud connectivity, thereby enhancing privacy and reducing latency.
The technology also seeks to address the increasing memory bandwidth requirements of modern neural networks, which have grown exponentially in size. By performing computations within memory, the architecture can potentially scale to accommodate larger models without corresponding increases in energy consumption or processing time.
Looking forward, in-memory computing aims to support more complex neural network architectures and training operations, not just inference. Researchers are exploring techniques to implement backpropagation and weight updates directly within memory arrays, which could revolutionize how neural networks are trained and deployed.
The evolution of in-memory computing began with the recognition that data movement between memory and processing units consumes significant energy and time. Early developments focused on bringing computation closer to memory through 3D stacking and near-memory processing. By 2015, researchers started exploring the possibility of performing computations within memory arrays themselves, particularly using emerging non-volatile memory technologies.
Resistive random-access memory (RRAM), phase-change memory (PCM), and magnetoresistive RAM (MRAM) emerged as promising candidates for in-memory computing due to their ability to both store information and perform analog computations. These technologies enable matrix-vector multiplications to be executed in a single step using physical principles such as Ohm's law and Kirchhoff's current law, dramatically reducing the energy consumption and latency compared to conventional approaches.
The primary objective of in-memory computing for neural networks is to overcome the von Neumann bottleneck by eliminating unnecessary data movement. This approach aims to achieve orders of magnitude improvements in energy efficiency and computational throughput for matrix-vector operations, which constitute over 90% of neural network inference computations.
Another critical goal is to enable edge AI applications by reducing the power consumption of neural network inference to levels compatible with battery-powered devices. This would allow sophisticated AI models to run locally on IoT devices, smartphones, and wearables without requiring cloud connectivity, thereby enhancing privacy and reducing latency.
The technology also seeks to address the increasing memory bandwidth requirements of modern neural networks, which have grown exponentially in size. By performing computations within memory, the architecture can potentially scale to accommodate larger models without corresponding increases in energy consumption or processing time.
Looking forward, in-memory computing aims to support more complex neural network architectures and training operations, not just inference. Researchers are exploring techniques to implement backpropagation and weight updates directly within memory arrays, which could revolutionize how neural networks are trained and deployed.
Market Demand for Efficient Neural Network Acceleration
The global market for neural network acceleration technologies has witnessed exponential growth in recent years, driven primarily by the increasing complexity of AI models and the computational demands they place on hardware systems. According to industry reports, the AI chip market reached $15 billion in 2022 and is projected to grow at a CAGR of 35% through 2027, highlighting the urgent need for more efficient neural network processing solutions.
Matrix-vector multiplication operations constitute approximately 90% of computational workload in modern neural networks, making them a critical bottleneck in AI system performance. This has created substantial market demand for specialized hardware accelerators that can perform these operations more efficiently than traditional CPU and GPU architectures.
Enterprise customers across various sectors are increasingly seeking neural network acceleration solutions that offer lower latency and higher energy efficiency. Cloud service providers report that AI workloads now consume over 25% of their total computational resources, with this figure expected to reach 40% by 2025. This trend has intensified the search for novel computing paradigms that can deliver performance improvements while reducing power consumption.
In-memory computing has emerged as a particularly promising approach to address these market needs. By eliminating the energy-intensive data movement between memory and processing units, in-memory computing architectures can potentially reduce energy consumption by up to 90% for matrix operations while simultaneously increasing computational throughput by orders of magnitude.
The automotive and edge computing sectors represent rapidly growing markets for efficient neural network acceleration. With autonomous vehicles requiring real-time processing of sensor data through neural networks, and edge devices needing to run AI models with limited power budgets, these segments are driving demand for specialized hardware solutions that can deliver high performance per watt.
Healthcare applications of AI are creating another significant market segment for neural network acceleration. Medical imaging analysis, drug discovery, and genomic sequencing all leverage increasingly complex neural network models, creating demand for high-performance, energy-efficient computing solutions in clinical and research settings.
The financial services industry has also emerged as a major consumer of neural network acceleration technology, with applications in fraud detection, algorithmic trading, and risk assessment requiring both high throughput and low latency. Banks and financial institutions are investing heavily in specialized hardware to gain competitive advantages through faster AI processing capabilities.
Matrix-vector multiplication operations constitute approximately 90% of computational workload in modern neural networks, making them a critical bottleneck in AI system performance. This has created substantial market demand for specialized hardware accelerators that can perform these operations more efficiently than traditional CPU and GPU architectures.
Enterprise customers across various sectors are increasingly seeking neural network acceleration solutions that offer lower latency and higher energy efficiency. Cloud service providers report that AI workloads now consume over 25% of their total computational resources, with this figure expected to reach 40% by 2025. This trend has intensified the search for novel computing paradigms that can deliver performance improvements while reducing power consumption.
In-memory computing has emerged as a particularly promising approach to address these market needs. By eliminating the energy-intensive data movement between memory and processing units, in-memory computing architectures can potentially reduce energy consumption by up to 90% for matrix operations while simultaneously increasing computational throughput by orders of magnitude.
The automotive and edge computing sectors represent rapidly growing markets for efficient neural network acceleration. With autonomous vehicles requiring real-time processing of sensor data through neural networks, and edge devices needing to run AI models with limited power budgets, these segments are driving demand for specialized hardware solutions that can deliver high performance per watt.
Healthcare applications of AI are creating another significant market segment for neural network acceleration. Medical imaging analysis, drug discovery, and genomic sequencing all leverage increasingly complex neural network models, creating demand for high-performance, energy-efficient computing solutions in clinical and research settings.
The financial services industry has also emerged as a major consumer of neural network acceleration technology, with applications in fraud detection, algorithmic trading, and risk assessment requiring both high throughput and low latency. Banks and financial institutions are investing heavily in specialized hardware to gain competitive advantages through faster AI processing capabilities.
Current Challenges in Matrix-Vector Multiplication
Matrix-vector multiplication (MVM) operations are fundamental to neural network computations, accounting for over 90% of the computational workload in many deep learning models. Despite their importance, current implementations face significant challenges that limit the efficiency and scalability of neural network deployments.
The von Neumann bottleneck represents the most critical challenge in MVM operations. The physical separation between processing units and memory creates a data transfer bottleneck, resulting in substantial energy consumption and latency issues. For large neural networks, this bottleneck becomes particularly problematic as data must constantly shuttle between memory and processing units, creating a performance ceiling that conventional architectures struggle to overcome.
Memory bandwidth limitations further exacerbate these challenges. Modern neural networks often require billions of parameters, and the limited bandwidth between memory and processing units restricts the speed at which matrix-vector operations can be performed. This limitation becomes increasingly problematic as model sizes continue to grow exponentially, with state-of-the-art models now containing hundreds of billions of parameters.
Power consumption presents another significant hurdle. The energy cost of data movement between memory and processing units often exceeds the energy required for the actual computations by an order of magnitude. This inefficiency becomes particularly problematic in edge computing scenarios where power constraints are strict, limiting the deployment of sophisticated neural network models on mobile and IoT devices.
Precision requirements add another layer of complexity. While reduced precision (such as 8-bit integers) can accelerate computations, many neural network applications require higher precision to maintain accuracy. This creates a challenging trade-off between computational efficiency and model performance that current architectures struggle to balance effectively.
Scalability issues also plague current MVM implementations. As neural networks grow in size and complexity, the computational demands increase non-linearly. Traditional computing architectures face diminishing returns when scaling to accommodate larger models, creating a ceiling effect on performance improvements despite increased hardware investments.
Latency requirements for real-time applications present additional challenges. Many applications, such as autonomous driving or real-time translation, require near-instantaneous processing of neural network operations. Current MVM implementations often cannot meet these stringent latency requirements while maintaining the necessary computational throughput and accuracy.
The von Neumann bottleneck represents the most critical challenge in MVM operations. The physical separation between processing units and memory creates a data transfer bottleneck, resulting in substantial energy consumption and latency issues. For large neural networks, this bottleneck becomes particularly problematic as data must constantly shuttle between memory and processing units, creating a performance ceiling that conventional architectures struggle to overcome.
Memory bandwidth limitations further exacerbate these challenges. Modern neural networks often require billions of parameters, and the limited bandwidth between memory and processing units restricts the speed at which matrix-vector operations can be performed. This limitation becomes increasingly problematic as model sizes continue to grow exponentially, with state-of-the-art models now containing hundreds of billions of parameters.
Power consumption presents another significant hurdle. The energy cost of data movement between memory and processing units often exceeds the energy required for the actual computations by an order of magnitude. This inefficiency becomes particularly problematic in edge computing scenarios where power constraints are strict, limiting the deployment of sophisticated neural network models on mobile and IoT devices.
Precision requirements add another layer of complexity. While reduced precision (such as 8-bit integers) can accelerate computations, many neural network applications require higher precision to maintain accuracy. This creates a challenging trade-off between computational efficiency and model performance that current architectures struggle to balance effectively.
Scalability issues also plague current MVM implementations. As neural networks grow in size and complexity, the computational demands increase non-linearly. Traditional computing architectures face diminishing returns when scaling to accommodate larger models, creating a ceiling effect on performance improvements despite increased hardware investments.
Latency requirements for real-time applications present additional challenges. Many applications, such as autonomous driving or real-time translation, require near-instantaneous processing of neural network operations. Current MVM implementations often cannot meet these stringent latency requirements while maintaining the necessary computational throughput and accuracy.
Current In-Memory Computing Architectures
01 In-Memory Processing Architectures for Matrix-Vector Multiplication
In-memory computing architectures enable matrix-vector multiplication operations to be performed directly within memory arrays, eliminating the need to transfer data between memory and processing units. These architectures leverage memory cells as computational elements, allowing for parallel processing of matrix operations. By performing computations where data resides, these systems significantly reduce energy consumption and latency associated with data movement, which is particularly beneficial for matrix-vector multiplication operations in machine learning and neural network applications.- In-Memory Processing Architectures for Matrix-Vector Multiplication: In-memory computing architectures specifically designed for matrix-vector multiplication operations reduce data movement between memory and processing units. These architectures integrate computation directly within memory arrays, enabling parallel processing of matrix operations and significantly improving computational efficiency for matrix-vector multiplications. By performing calculations where data resides, these systems minimize the memory bottleneck that typically limits performance in traditional computing architectures.
- Memristor-Based Computing for Matrix Operations: Memristor-based computing systems utilize non-volatile memory elements to perform matrix-vector multiplication operations directly within memory. These systems leverage the analog characteristics of memristors to perform multiplication and accumulation operations in a highly parallel manner. The resistance states of memristors can represent matrix weights, allowing for efficient implementation of matrix-vector multiplication without the need to move large amounts of data between separate memory and processing units.
- Processing-in-Memory Techniques for Neural Networks: Processing-in-memory techniques specifically optimized for neural network computations focus on efficient matrix-vector multiplication operations that form the core of neural network inference and training. These techniques implement specialized memory arrays with integrated computational capabilities to accelerate neural network operations. By performing matrix-vector multiplications directly within memory, these systems significantly reduce energy consumption and increase throughput for AI applications.
- Parallel Processing Algorithms for Matrix Computations: Advanced algorithms designed for parallel processing of matrix-vector multiplication operations optimize workload distribution across multiple processing elements. These algorithms focus on data partitioning, scheduling, and synchronization techniques to maximize throughput and minimize latency. By efficiently mapping matrix-vector operations to parallel computing resources, these approaches achieve significant performance improvements for large-scale matrix computations in memory-constrained environments.
- Memory-Centric Computing Systems for Linear Algebra: Memory-centric computing systems specifically designed for linear algebra operations prioritize efficient matrix-vector multiplication through specialized memory hierarchies and data flow architectures. These systems feature custom memory organizations that minimize data movement costs while maximizing computational throughput for matrix operations. By optimizing memory access patterns and data locality, these architectures achieve significant performance and energy efficiency improvements for matrix-vector multiplication workloads.
02 Memristor-Based Computing for Matrix Operations
Memristor-based computing systems utilize crossbar arrays of memristive devices to perform matrix-vector multiplication operations with high efficiency. These non-volatile memory elements can store matrix weights while simultaneously performing multiplication and accumulation operations through their inherent physical properties. The analog nature of memristors allows for direct computation of dot products in the analog domain, enabling highly parallel matrix operations with significantly reduced power consumption compared to conventional digital approaches.Expand Specific Solutions03 FPGA and ASIC Implementations for Matrix Computation
Field-Programmable Gate Arrays (FPGAs) and Application-Specific Integrated Circuits (ASICs) provide hardware acceleration for matrix-vector multiplication through custom dataflow architectures. These implementations feature specialized processing elements arranged in systolic arrays or other parallel structures to efficiently handle matrix operations. By utilizing dedicated hardware resources and optimized data paths, these solutions achieve higher throughput and energy efficiency compared to general-purpose processors, making them suitable for computationally intensive applications requiring real-time matrix processing.Expand Specific Solutions04 Memory-Centric Computing Algorithms and Optimization
Specialized algorithms and optimization techniques have been developed to enhance the efficiency of matrix-vector multiplication in memory-centric computing systems. These approaches include data layout optimization, workload partitioning, and computation scheduling to maximize parallelism and minimize data movement. Advanced techniques such as approximate computing, precision scaling, and sparse matrix optimizations further improve performance and energy efficiency. These algorithmic innovations work in conjunction with hardware architectures to overcome bandwidth limitations and fully exploit the potential of in-memory computing for matrix operations.Expand Specific Solutions05 3D Memory Integration for Enhanced Matrix Processing
Three-dimensional memory integration technologies enable advanced architectures for matrix-vector multiplication by stacking memory and processing layers vertically. This approach significantly increases memory bandwidth and reduces interconnect distances between computational units and data storage. Through-silicon vias (TSVs) and other 3D integration techniques allow for massive parallelism in matrix operations while maintaining low power consumption. These 3D architectures support high-throughput matrix processing for applications such as deep learning inference, scientific computing, and real-time signal processing.Expand Specific Solutions
Leading Companies in In-Memory Computing Hardware
In-Memory Computing for matrix-vector multiplication in neural networks is evolving rapidly in a market transitioning from early adoption to growth phase. The global market is expanding significantly as AI applications proliferate, with projections indicating substantial growth over the next five years. Technologically, major semiconductor players like Samsung, Intel, Micron, and TSMC are advancing commercial solutions, while specialized companies such as GSI Technology, Rain Neuromorphics, and Synthara are developing innovative architectures. Research institutions including Peking University, USC, and Beihang University are contributing fundamental breakthroughs. The technology is approaching maturity for specific applications, with companies like Qualcomm and IBM integrating in-memory computing into their AI acceleration strategies, though challenges in scalability and standardization remain.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has pioneered Processing-In-Memory (PIM) technology specifically optimized for neural network matrix-vector multiplication operations. Their HBM-PIM (High Bandwidth Memory with Processing-In-Memory) architecture integrates computational units directly within memory banks, enabling parallel processing of matrix operations without data movement between separate memory and processing components[2]. Samsung's implementation features specialized unit cells that can perform multiply-accumulate operations directly within the memory array, with recent demonstrations showing up to 2x performance improvement and 70% energy reduction for neural network workloads[4]. Their architecture employs a hybrid approach where certain computational elements are embedded within the memory hierarchy while maintaining compatibility with existing memory interfaces. Samsung has also developed software frameworks that allow seamless integration with popular deep learning libraries, enabling automatic offloading of matrix operations to their PIM hardware without requiring extensive code modifications[6]. Recent implementations have focused on optimizing transformer model inference, where matrix operations dominate computational requirements.
Strengths: Maintains compatibility with existing memory interfaces while adding computational capabilities, enabling easier adoption. Offers significant energy efficiency improvements for memory-bound neural network operations. Weaknesses: Current implementations have limitations in computational precision compared to dedicated processors. The technology requires specific hardware support that may not be universally available across all computing platforms.
Intel Corp.
Technical Solution: Intel has developed a comprehensive in-memory computing architecture called "IMEC" (In-Memory Enhanced Computing) specifically targeting neural network acceleration. Their approach combines traditional CMOS technology with emerging non-volatile memory to create hybrid computational memory arrays optimized for matrix-vector multiplication operations[3]. Intel's solution features a hierarchical memory design where different memory technologies are employed at various levels to balance performance, energy efficiency, and reliability. At the core of their architecture are specialized crossbar arrays using resistive RAM (ReRAM) or phase-change memory (PCM) technologies that can perform analog multiply-accumulate operations in parallel[5]. Intel has demonstrated significant performance improvements, with their latest prototypes achieving up to 8x throughput and 5x energy efficiency improvements for convolutional neural networks compared to conventional architectures[7]. Their implementation includes specialized peripheral circuits for analog-to-digital conversion and precision management, addressing key challenges in analog computing. Intel has also developed compiler support to automatically map neural network operations to their in-memory computing hardware.
Strengths: Leverages Intel's manufacturing expertise to create highly integrated solutions combining memory and logic. Provides comprehensive software support for major deep learning frameworks. Weaknesses: Analog computing elements introduce variability challenges that can affect computational precision. The technology requires specialized hardware that may increase manufacturing complexity and cost.
Core Technologies for Matrix-Vector Optimization
In memory matrix multiplication and its usage in neural networks
PatentActiveUS20230359698A1
Innovation
- The method involves storing a multiplier matrix in a memory array with sections such as volatile or non-volatile memory, and performing in-memory vector-matrix multiplication by arranging operands on the same column, allowing concurrent computation and reducing the number of connections between operands, thereby achieving linear or constant complexity.

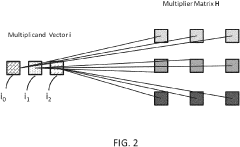
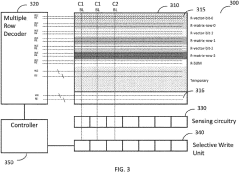
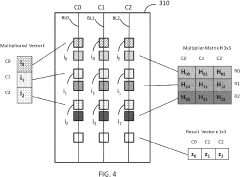
In-memory computing (IMC) memory device and in-memory computing method
PatentActiveUS20240355387A1
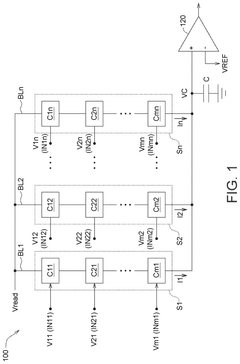
Innovation
- An in-memory computing (IMC) memory device and method that utilizes a plurality of computing memory cells forming memory strings, with a loading capacitor and measurement circuit to sum cell currents and determine operation results based on the relationship between capacitor voltage, delay time, and predetermined voltage, allowing for efficient calculation of input and weight value products.
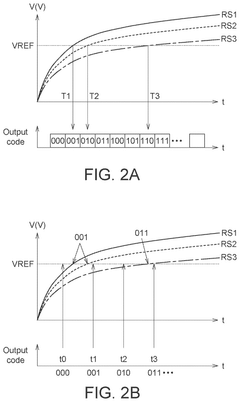
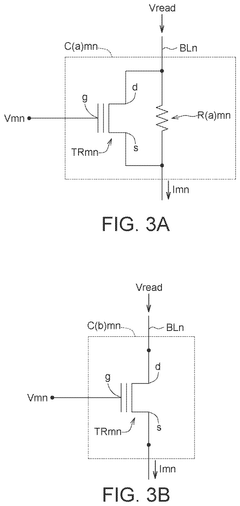
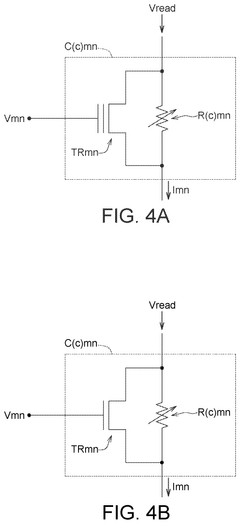
Energy Efficiency and Performance Metrics
Energy efficiency and performance metrics are critical considerations when evaluating in-memory computing solutions for matrix-vector multiplication in neural networks. Traditional von Neumann architectures suffer from significant energy consumption due to the constant data movement between memory and processing units, creating a bottleneck known as the "memory wall." In-memory computing architectures fundamentally address this issue by performing computations directly within memory, dramatically reducing energy expenditure associated with data transfer.
Recent benchmarks indicate that in-memory computing implementations can achieve energy efficiency improvements of 10-100× compared to conventional GPU and CPU implementations for matrix-vector operations. This efficiency gain stems primarily from the elimination of redundant data movement, which typically accounts for 60-80% of the total energy consumption in neural network inference tasks. The energy-per-operation metric (measured in pJ/op) has shown remarkable improvement, with some resistive RAM-based in-memory computing solutions demonstrating sub-pJ/op performance for 8-bit precision operations.
Performance metrics for in-memory computing extend beyond mere energy efficiency. Computational density, measured in operations per second per unit area (TOPS/mm²), represents another crucial metric that has seen substantial improvements. Current in-memory computing prototypes demonstrate 10-20 TOPS/mm² for 8-bit operations, significantly outperforming traditional digital accelerators that typically achieve 1-5 TOPS/mm².
Latency characteristics also show promising results, with in-memory computing solutions reducing end-to-end processing time for matrix-vector multiplications by eliminating the memory access bottleneck. This translates to throughput improvements of 5-15× for typical neural network workloads compared to optimized GPU implementations.
However, these performance gains come with important trade-offs. The precision-energy relationship in in-memory computing follows a non-linear curve, where higher precision operations (>8-bit) often result in disproportionately higher energy consumption. This creates an important design consideration for neural network implementations, where precision requirements must be carefully balanced against energy constraints.
Temperature sensitivity represents another critical performance factor, as many in-memory computing technologies (particularly those based on resistive or phase-change materials) exhibit performance variations across operating temperature ranges. This necessitates robust calibration mechanisms to maintain computational accuracy across diverse deployment environments.
As the field matures, standardized benchmarking methodologies are emerging to enable fair comparisons between different in-memory computing approaches, considering not just raw performance metrics but also reliability, endurance, and integration complexity with existing digital systems.
Recent benchmarks indicate that in-memory computing implementations can achieve energy efficiency improvements of 10-100× compared to conventional GPU and CPU implementations for matrix-vector operations. This efficiency gain stems primarily from the elimination of redundant data movement, which typically accounts for 60-80% of the total energy consumption in neural network inference tasks. The energy-per-operation metric (measured in pJ/op) has shown remarkable improvement, with some resistive RAM-based in-memory computing solutions demonstrating sub-pJ/op performance for 8-bit precision operations.
Performance metrics for in-memory computing extend beyond mere energy efficiency. Computational density, measured in operations per second per unit area (TOPS/mm²), represents another crucial metric that has seen substantial improvements. Current in-memory computing prototypes demonstrate 10-20 TOPS/mm² for 8-bit operations, significantly outperforming traditional digital accelerators that typically achieve 1-5 TOPS/mm².
Latency characteristics also show promising results, with in-memory computing solutions reducing end-to-end processing time for matrix-vector multiplications by eliminating the memory access bottleneck. This translates to throughput improvements of 5-15× for typical neural network workloads compared to optimized GPU implementations.
However, these performance gains come with important trade-offs. The precision-energy relationship in in-memory computing follows a non-linear curve, where higher precision operations (>8-bit) often result in disproportionately higher energy consumption. This creates an important design consideration for neural network implementations, where precision requirements must be carefully balanced against energy constraints.
Temperature sensitivity represents another critical performance factor, as many in-memory computing technologies (particularly those based on resistive or phase-change materials) exhibit performance variations across operating temperature ranges. This necessitates robust calibration mechanisms to maintain computational accuracy across diverse deployment environments.
As the field matures, standardized benchmarking methodologies are emerging to enable fair comparisons between different in-memory computing approaches, considering not just raw performance metrics but also reliability, endurance, and integration complexity with existing digital systems.
Hardware-Software Co-Design Approaches
Hardware-software co-design approaches represent a critical paradigm in optimizing in-memory computing for matrix-vector multiplication in neural networks. This methodology bridges the gap between hardware architecture and software algorithms, creating synergistic solutions that maximize performance while minimizing energy consumption. Traditional computing architectures suffer from the von Neumann bottleneck, where data transfer between memory and processing units creates significant latency and energy overhead, particularly detrimental for computation-intensive neural network operations.
Effective co-design approaches begin with hardware-aware algorithm development, where neural network architectures and training procedures are specifically tailored to the constraints and capabilities of in-memory computing hardware. This includes quantization techniques that reduce precision requirements without significant accuracy loss, enabling more efficient implementation on analog or mixed-signal computing arrays. Pruning strategies can also be employed to create sparse neural networks that require fewer memory accesses and computational operations.
From the hardware perspective, specialized memory architectures are being developed with computational capabilities embedded directly within memory arrays. These include resistive RAM (RRAM), phase-change memory (PCM), and SRAM-based computational memory, each offering different trade-offs between speed, energy efficiency, and integration complexity. The design of peripheral circuits plays a crucial role in determining the overall system performance, with innovations in analog-to-digital converters and sensing amplifiers significantly impacting computational accuracy and energy efficiency.
Software frameworks and compilers that understand the unique characteristics of in-memory computing hardware represent another essential component of co-design approaches. These tools automatically map neural network operations to the underlying hardware, optimizing data flow and computation scheduling. Advanced mapping techniques can exploit parallelism at different levels, from fine-grained parallelism within memory arrays to coarse-grained parallelism across multiple arrays.
Runtime systems that dynamically adapt to changing workloads and hardware conditions further enhance the efficiency of in-memory computing solutions. These systems can make intelligent decisions about resource allocation, power management, and precision requirements based on application needs and hardware status, ensuring optimal performance across diverse operating conditions.
The co-design methodology necessitates close collaboration between hardware engineers, algorithm developers, and system architects throughout the development process. This interdisciplinary approach has yielded promising results, with recent demonstrations showing orders of magnitude improvements in energy efficiency for neural network inference tasks compared to conventional computing architectures.
Effective co-design approaches begin with hardware-aware algorithm development, where neural network architectures and training procedures are specifically tailored to the constraints and capabilities of in-memory computing hardware. This includes quantization techniques that reduce precision requirements without significant accuracy loss, enabling more efficient implementation on analog or mixed-signal computing arrays. Pruning strategies can also be employed to create sparse neural networks that require fewer memory accesses and computational operations.
From the hardware perspective, specialized memory architectures are being developed with computational capabilities embedded directly within memory arrays. These include resistive RAM (RRAM), phase-change memory (PCM), and SRAM-based computational memory, each offering different trade-offs between speed, energy efficiency, and integration complexity. The design of peripheral circuits plays a crucial role in determining the overall system performance, with innovations in analog-to-digital converters and sensing amplifiers significantly impacting computational accuracy and energy efficiency.
Software frameworks and compilers that understand the unique characteristics of in-memory computing hardware represent another essential component of co-design approaches. These tools automatically map neural network operations to the underlying hardware, optimizing data flow and computation scheduling. Advanced mapping techniques can exploit parallelism at different levels, from fine-grained parallelism within memory arrays to coarse-grained parallelism across multiple arrays.
Runtime systems that dynamically adapt to changing workloads and hardware conditions further enhance the efficiency of in-memory computing solutions. These systems can make intelligent decisions about resource allocation, power management, and precision requirements based on application needs and hardware status, ensuring optimal performance across diverse operating conditions.
The co-design methodology necessitates close collaboration between hardware engineers, algorithm developers, and system architects throughout the development process. This interdisciplinary approach has yielded promising results, with recent demonstrations showing orders of magnitude improvements in energy efficiency for neural network inference tasks compared to conventional computing architectures.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!