

In-Memory Computing Accelerators For Genome Sequence Alignment Tasks
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Genomic Computing Background and Objectives
Genomic sequence alignment represents a cornerstone of modern bioinformatics, enabling the comparison of DNA or RNA sequences to identify regions of similarity that may indicate functional, structural, or evolutionary relationships. Traditional computing architectures face significant challenges in processing the massive datasets generated by next-generation sequencing technologies, which can produce billions of short reads requiring alignment to reference genomes comprising billions of base pairs.
The evolution of genomic computing has progressed from early Smith-Waterman and Needleman-Wunsch algorithms, which provided optimal alignments but at prohibitive computational costs for large-scale applications, to heuristic approaches like BLAST and more recent tools such as Bowtie, BWA, and HISAT2. These advancements have dramatically improved processing speeds but still face bottlenecks when deployed on conventional von Neumann architectures due to the memory wall phenomenon.
In-Memory Computing (IMC) represents a paradigm shift in addressing these computational challenges by performing calculations directly within memory units, thereby minimizing data movement between processing and storage components. This approach is particularly well-suited for genomic sequence alignment tasks, which are characterized by high data parallelism and relatively simple computational patterns applied across massive datasets.
Recent technological developments in resistive random-access memory (RRAM), phase-change memory (PCM), and other emerging non-volatile memory technologies have created new opportunities for implementing efficient IMC accelerators specifically designed for genomic workloads. These technologies enable the creation of computational memory arrays that can perform massively parallel operations directly on genomic data.
The primary objective of IMC accelerators for genome sequence alignment is to achieve orders-of-magnitude improvements in energy efficiency and computational throughput compared to conventional CPU/GPU implementations. This would enable real-time analysis of genomic data, potentially revolutionizing clinical applications such as rapid pathogen identification, personalized medicine, and point-of-care diagnostics.
Additional goals include developing scalable architectures that can accommodate the exponentially growing genomic databases while maintaining alignment accuracy comparable to software-based methods. Furthermore, these accelerators aim to support various alignment algorithms and scoring schemes to address different biological questions and sequence characteristics.
The convergence of advances in memory technologies, algorithm optimization, and domain-specific hardware design presents a promising frontier for overcoming current limitations in genomic data processing. As sequencing technologies continue to improve in throughput and cost-effectiveness, the development of specialized IMC accelerators becomes increasingly critical for unlocking the full potential of genomic information in healthcare, agriculture, and basic biological research.
The evolution of genomic computing has progressed from early Smith-Waterman and Needleman-Wunsch algorithms, which provided optimal alignments but at prohibitive computational costs for large-scale applications, to heuristic approaches like BLAST and more recent tools such as Bowtie, BWA, and HISAT2. These advancements have dramatically improved processing speeds but still face bottlenecks when deployed on conventional von Neumann architectures due to the memory wall phenomenon.
In-Memory Computing (IMC) represents a paradigm shift in addressing these computational challenges by performing calculations directly within memory units, thereby minimizing data movement between processing and storage components. This approach is particularly well-suited for genomic sequence alignment tasks, which are characterized by high data parallelism and relatively simple computational patterns applied across massive datasets.
Recent technological developments in resistive random-access memory (RRAM), phase-change memory (PCM), and other emerging non-volatile memory technologies have created new opportunities for implementing efficient IMC accelerators specifically designed for genomic workloads. These technologies enable the creation of computational memory arrays that can perform massively parallel operations directly on genomic data.
The primary objective of IMC accelerators for genome sequence alignment is to achieve orders-of-magnitude improvements in energy efficiency and computational throughput compared to conventional CPU/GPU implementations. This would enable real-time analysis of genomic data, potentially revolutionizing clinical applications such as rapid pathogen identification, personalized medicine, and point-of-care diagnostics.
Additional goals include developing scalable architectures that can accommodate the exponentially growing genomic databases while maintaining alignment accuracy comparable to software-based methods. Furthermore, these accelerators aim to support various alignment algorithms and scoring schemes to address different biological questions and sequence characteristics.
The convergence of advances in memory technologies, algorithm optimization, and domain-specific hardware design presents a promising frontier for overcoming current limitations in genomic data processing. As sequencing technologies continue to improve in throughput and cost-effectiveness, the development of specialized IMC accelerators becomes increasingly critical for unlocking the full potential of genomic information in healthcare, agriculture, and basic biological research.
Market Analysis for Genomic Sequence Processing
The genomic sequence processing market has experienced exponential growth over the past decade, driven primarily by advancements in next-generation sequencing technologies and their widespread adoption in research, clinical diagnostics, and personalized medicine. The global market for genomic data processing was valued at approximately $12.5 billion in 2022 and is projected to reach $47.8 billion by 2030, representing a compound annual growth rate (CAGR) of 18.3%.
Healthcare and pharmaceutical sectors currently dominate the market demand, accounting for over 65% of the total market share. This is largely attributed to the increasing integration of genomic data in drug discovery processes, clinical trials, and precision medicine initiatives. The COVID-19 pandemic further accelerated market growth as rapid genome sequencing became critical for tracking viral mutations and developing targeted therapeutics.
Regionally, North America leads the market with approximately 42% share, followed by Europe (28%) and Asia-Pacific (21%). However, the Asia-Pacific region is expected to witness the highest growth rate in the coming years due to increasing investments in healthcare infrastructure, rising awareness about genetic testing, and government initiatives supporting genomic research in countries like China, Japan, and India.
The demand for in-memory computing accelerators specifically designed for genome sequence alignment tasks is being driven by the exponential growth in genomic data generation. Modern sequencing platforms can produce terabytes of data per run, creating significant computational bottlenecks in traditional processing pipelines. Market research indicates that organizations performing large-scale genomic analyses spend approximately 30-40% of their computational resources on sequence alignment tasks alone.
Key market segments include clinical diagnostics (35%), academic research (25%), pharmaceutical R&D (20%), agricultural genomics (12%), and other applications (8%). The clinical diagnostics segment is experiencing the fastest growth due to increasing adoption of whole genome sequencing for rare disease diagnosis and cancer profiling.
Customer pain points consistently identified in market surveys include processing speed limitations, high computational costs, energy consumption concerns, and difficulties in scaling existing infrastructure to handle growing data volumes. These challenges create a significant market opportunity for specialized in-memory computing accelerators that can deliver orders-of-magnitude improvements in processing efficiency.
Market forecasts suggest that specialized hardware accelerators for genomic data processing will grow at a CAGR of 24.7% through 2030, outpacing the overall market growth rate. This indicates strong potential demand for in-memory computing solutions specifically optimized for genome sequence alignment workloads.
Healthcare and pharmaceutical sectors currently dominate the market demand, accounting for over 65% of the total market share. This is largely attributed to the increasing integration of genomic data in drug discovery processes, clinical trials, and precision medicine initiatives. The COVID-19 pandemic further accelerated market growth as rapid genome sequencing became critical for tracking viral mutations and developing targeted therapeutics.
Regionally, North America leads the market with approximately 42% share, followed by Europe (28%) and Asia-Pacific (21%). However, the Asia-Pacific region is expected to witness the highest growth rate in the coming years due to increasing investments in healthcare infrastructure, rising awareness about genetic testing, and government initiatives supporting genomic research in countries like China, Japan, and India.
The demand for in-memory computing accelerators specifically designed for genome sequence alignment tasks is being driven by the exponential growth in genomic data generation. Modern sequencing platforms can produce terabytes of data per run, creating significant computational bottlenecks in traditional processing pipelines. Market research indicates that organizations performing large-scale genomic analyses spend approximately 30-40% of their computational resources on sequence alignment tasks alone.
Key market segments include clinical diagnostics (35%), academic research (25%), pharmaceutical R&D (20%), agricultural genomics (12%), and other applications (8%). The clinical diagnostics segment is experiencing the fastest growth due to increasing adoption of whole genome sequencing for rare disease diagnosis and cancer profiling.
Customer pain points consistently identified in market surveys include processing speed limitations, high computational costs, energy consumption concerns, and difficulties in scaling existing infrastructure to handle growing data volumes. These challenges create a significant market opportunity for specialized in-memory computing accelerators that can deliver orders-of-magnitude improvements in processing efficiency.
Market forecasts suggest that specialized hardware accelerators for genomic data processing will grow at a CAGR of 24.7% through 2030, outpacing the overall market growth rate. This indicates strong potential demand for in-memory computing solutions specifically optimized for genome sequence alignment workloads.
In-Memory Computing Landscape and Bottlenecks
In-memory computing (IMC) represents a paradigm shift in computer architecture, addressing the von Neumann bottleneck by integrating computation and memory functions. The current landscape of IMC for genomic sequence alignment reveals several critical bottlenecks that impede optimal performance and widespread adoption.
The memory wall remains the primary challenge, with data transfer between memory and processing units creating significant latency issues. For genome sequence alignment tasks, which involve massive datasets often exceeding terabytes, this bottleneck becomes particularly pronounced. Current architectures struggle to efficiently handle the irregular memory access patterns characteristic of sequence alignment algorithms like Smith-Waterman and Burrows-Wheeler Transform.
Energy efficiency presents another major constraint. Traditional computing systems consume substantial power during data movement, with estimates suggesting that up to 60% of total system energy is expended on data transfer rather than actual computation. This inefficiency becomes critical for large-scale genomic analyses that may run continuously for days or weeks.
Scalability limitations also plague current IMC implementations. As genomic databases continue to grow exponentially, the ability to scale processing capabilities proportionally becomes increasingly challenging. Many existing IMC solutions demonstrate promising performance for smaller workloads but fail to maintain efficiency when scaled to handle complete human genome comparisons against comprehensive reference databases.
Precision and accuracy requirements introduce additional complexity. Genomic sequence alignment demands high precision, particularly for applications like variant calling and personalized medicine. Current IMC accelerators often make trade-offs between computational speed and accuracy, creating a bottleneck for clinical applications where error tolerance is minimal.
Integration challenges with existing bioinformatics pipelines represent a significant practical bottleneck. Many IMC solutions require substantial modifications to established workflows and software tools, creating resistance to adoption despite theoretical performance advantages.
The technological maturity of various IMC approaches varies considerably across the landscape. While some technologies like resistive RAM (ReRAM) and phase-change memory (PCM) show promise for genomic workloads, they face manufacturing challenges and reliability issues that limit commercial viability. More mature approaches like SRAM-based computing often lack the density required for comprehensive genomic analyses.
Standardization remains underdeveloped in the IMC ecosystem, with competing architectures, programming models, and interfaces creating fragmentation that impedes broader adoption for genomic applications.
The memory wall remains the primary challenge, with data transfer between memory and processing units creating significant latency issues. For genome sequence alignment tasks, which involve massive datasets often exceeding terabytes, this bottleneck becomes particularly pronounced. Current architectures struggle to efficiently handle the irregular memory access patterns characteristic of sequence alignment algorithms like Smith-Waterman and Burrows-Wheeler Transform.
Energy efficiency presents another major constraint. Traditional computing systems consume substantial power during data movement, with estimates suggesting that up to 60% of total system energy is expended on data transfer rather than actual computation. This inefficiency becomes critical for large-scale genomic analyses that may run continuously for days or weeks.
Scalability limitations also plague current IMC implementations. As genomic databases continue to grow exponentially, the ability to scale processing capabilities proportionally becomes increasingly challenging. Many existing IMC solutions demonstrate promising performance for smaller workloads but fail to maintain efficiency when scaled to handle complete human genome comparisons against comprehensive reference databases.
Precision and accuracy requirements introduce additional complexity. Genomic sequence alignment demands high precision, particularly for applications like variant calling and personalized medicine. Current IMC accelerators often make trade-offs between computational speed and accuracy, creating a bottleneck for clinical applications where error tolerance is minimal.
Integration challenges with existing bioinformatics pipelines represent a significant practical bottleneck. Many IMC solutions require substantial modifications to established workflows and software tools, creating resistance to adoption despite theoretical performance advantages.
The technological maturity of various IMC approaches varies considerably across the landscape. While some technologies like resistive RAM (ReRAM) and phase-change memory (PCM) show promise for genomic workloads, they face manufacturing challenges and reliability issues that limit commercial viability. More mature approaches like SRAM-based computing often lack the density required for comprehensive genomic analyses.
Standardization remains underdeveloped in the IMC ecosystem, with competing architectures, programming models, and interfaces creating fragmentation that impedes broader adoption for genomic applications.
Current In-Memory Architectures for Sequence Alignment
01 Memory-centric computing architectures
In-memory computing architectures integrate processing capabilities directly within memory units to reduce data movement between memory and CPU, significantly improving computational efficiency. These architectures minimize the von Neumann bottleneck by performing calculations where data resides, enabling faster processing for data-intensive applications. This approach reduces energy consumption and latency while increasing throughput for complex computational tasks.- Memory-centric computing architectures: In-memory computing architectures integrate processing capabilities directly within memory components, reducing data movement between memory and CPU. This approach significantly reduces latency and power consumption by minimizing the memory wall bottleneck. These architectures enable parallel processing of data where it resides, allowing for substantial performance improvements in data-intensive applications like AI and big data analytics.
- Power management in in-memory computing systems: Advanced power management techniques are essential for optimizing in-memory computing accelerators. These include dynamic voltage and frequency scaling, selective power gating for inactive memory regions, and intelligent workload distribution. Such techniques balance performance requirements with energy efficiency, extending battery life in mobile applications while maintaining computational capabilities and reducing thermal issues in data centers.
- Hardware acceleration for specific workloads: Specialized in-memory computing accelerators are designed for specific computational workloads such as neural networks, graph processing, and database operations. These purpose-built accelerators incorporate optimized memory hierarchies, custom processing elements, and application-specific integrated circuits that dramatically improve performance for targeted applications while maintaining energy efficiency compared to general-purpose computing systems.
- Memory-compute integration techniques: Advanced integration techniques combine memory and computing elements at various levels, from 3D stacking to monolithic integration. These approaches minimize interconnect distances, increase bandwidth, and reduce energy consumption. Novel materials and fabrication methods enable higher density memory-compute units while addressing thermal challenges inherent in tightly integrated systems, resulting in significant performance improvements for data-intensive applications.
- Resource management and scheduling: Efficient resource management and task scheduling are critical for maximizing in-memory computing performance. Advanced algorithms dynamically allocate computing resources based on workload characteristics, memory access patterns, and system conditions. These management systems optimize data placement, minimize contention, and enable efficient multi-tenancy, ensuring high utilization of in-memory computing resources while meeting application performance requirements.
02 Hardware accelerators for in-memory computing
Specialized hardware accelerators designed specifically for in-memory computing can dramatically improve performance for specific workloads. These accelerators include custom ASICs, FPGAs, and other dedicated processing units that optimize memory-compute integration. By implementing computational functions directly in memory arrays, these accelerators achieve higher parallelism and energy efficiency compared to traditional computing architectures.Expand Specific Solutions03 Power management techniques for in-memory computing
Advanced power management techniques are essential for optimizing the performance and efficiency of in-memory computing systems. These include dynamic voltage and frequency scaling, selective power gating, and intelligent workload distribution. By carefully managing power consumption across memory arrays and processing elements, these techniques enable higher computational throughput while maintaining thermal constraints and extending battery life in portable systems.Expand Specific Solutions04 Memory-compute integration for parallel processing
Integrating computing capabilities within memory structures enables massive parallelism for data-intensive applications. This approach allows simultaneous operations across multiple memory cells, significantly accelerating tasks like neural network inference, database operations, and scientific computing. The parallel nature of in-memory computing provides orders of magnitude improvement in processing throughput compared to sequential processing in conventional architectures.Expand Specific Solutions05 Software frameworks for in-memory computing
Specialized software frameworks and programming models are crucial for effectively utilizing in-memory computing accelerators. These frameworks provide abstractions that allow developers to express computations in ways that can be efficiently mapped to in-memory hardware. They include runtime systems that optimize data placement, manage memory resources, and coordinate parallel execution across heterogeneous computing elements, maximizing the performance benefits of in-memory computing architectures.Expand Specific Solutions
Leading Organizations in Genomic Computing Hardware
In-Memory Computing Accelerators for genome sequence alignment tasks are evolving rapidly in a market transitioning from early adoption to growth phase. The global market is expanding significantly due to increasing genomic data processing demands, with projections indicating substantial growth over the next five years. Technologically, solutions range from emerging to mature implementations, with key players demonstrating varied approaches. Research institutions (Institute of Computing Technology CAS, Indian Institute of Science, MIT) focus on fundamental algorithmic innovations, while commercial entities (Encharge AI, Qualcomm, Apple) leverage their hardware expertise. Specialized genomics companies (Seven Bridges Genomics, Complete Genomics) are integrating these accelerators into comprehensive platforms. The competitive landscape shows a healthy balance between academic innovation and commercial implementation, with increasing cross-sector collaborations driving technological advancement.
Institute of Computing Technology, Chinese Academy of Sciences
Technical Solution: The Institute of Computing Technology (ICT) at the Chinese Academy of Sciences has pioneered GenPIM, a processing-in-memory architecture specifically optimized for genome sequence alignment. GenPIM utilizes a novel 3D-stacked memory design with computational logic embedded directly in the memory layers. The system implements a hierarchical memory structure where frequently accessed reference genome segments are stored in high-speed memory banks while specialized processing elements perform alignment operations in situ. ICT's approach features custom logic units that execute modified Burrows-Wheeler Transform (BWT) and FM-index algorithms directly within memory, dramatically reducing data movement. Their implementation achieves approximately 8-12x speedup compared to conventional CPU-based alignment tools while maintaining comparable accuracy. The architecture incorporates dynamic workload balancing mechanisms that distribute computational tasks across multiple memory banks based on sequence complexity and reference genome characteristics, optimizing resource utilization and throughput for varied genomic datasets.
Strengths: Highly efficient 3D-stacked memory architecture minimizing data movement; specialized hardware acceleration for genomic algorithms; excellent scalability for large reference genomes. Weaknesses: Complex manufacturing requirements for 3D-stacked memory integration; potential thermal management challenges in high-density computing arrays; requires significant modifications to existing bioinformatics pipelines.
QUALCOMM, Inc.
Technical Solution: Qualcomm has leveraged its expertise in mobile system-on-chip design to create GenomeAccel, an energy-efficient in-memory computing solution for portable genomic sequence alignment applications. Their architecture integrates specialized neural processing units (NPUs) with on-chip SRAM arrays modified to support in-memory computing operations specific to genomic workloads. GenomeAccel implements a novel approach where sequence alignment is partially formulated as a pattern recognition problem, enabling the use of Qualcomm's neural computing hardware for certain alignment subtasks. The system features custom digital processing elements that perform exact matching operations while approximate matching leverages the analog computing capabilities of their NPU. Qualcomm's solution achieves a 6-8x performance improvement over conventional mobile processors while consuming only 15% of the energy, making it suitable for point-of-care genomic applications. The architecture includes specialized hardware for handling common genomic operations such as k-mer matching and seed extension, with configurable parameters that can be tuned for different sequencing technologies. GenomeAccel is designed to operate within strict power envelopes, enabling deployment in portable and battery-powered genomic analysis devices for field applications.
Strengths: Exceptional energy efficiency ideal for portable applications; innovative use of neural computing hardware for alignment tasks; compact form factor suitable for point-of-care devices. Weaknesses: Lower absolute performance compared to data center solutions; limited support for extremely large reference genomes; optimization primarily focused on short-read alignment rather than long-read technologies.
Key Patents in Memory-Centric Genomic Processing
Genome read alignment of high efficiency in in-memory database
PatentActiveJP2014146319A
Innovation
- An in-memory database system is employed for genomic sequence alignment, utilizing a worker framework with parallel processing on computing nodes, optimized index structures, and dynamic pipeline configurations to enhance processing speed and efficiency.
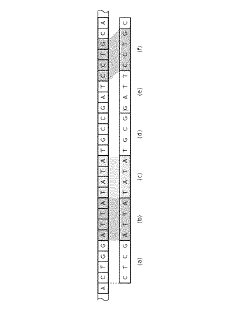
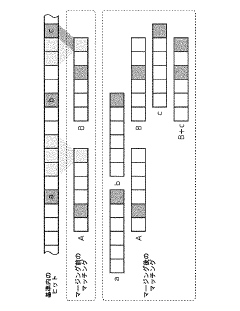
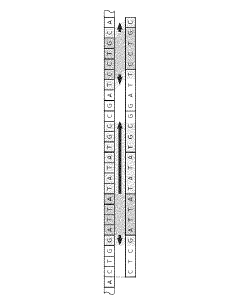

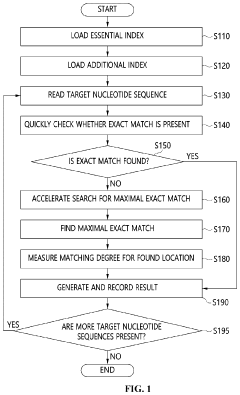
Apparatus and method for genome sequence alignment acceleration
PatentPendingUS20220392578A1
Innovation
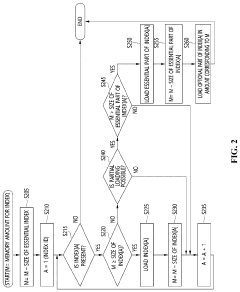
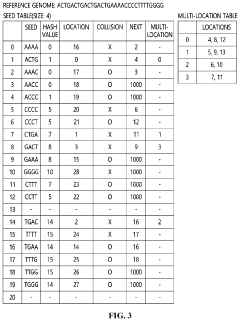
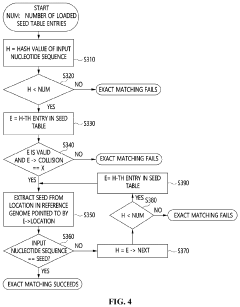
- An apparatus and method that load essential and additional indexes into memory based on available memory capacity, using a seed table and multi-location table to quickly check for exact matches in the reference genome, allowing for partial loading of indexes and prioritizing the essential parts to enhance alignment speed without requiring special hardware.
Energy Efficiency Considerations for Genomic Computing
Energy efficiency has emerged as a critical consideration in genomic computing, particularly for in-memory computing accelerators designed for genome sequence alignment tasks. The computational demands of genomic analysis have grown exponentially with the increasing volume of sequencing data, creating significant energy consumption challenges. Traditional computing architectures suffer from the "memory wall" problem, where data movement between processing units and memory consumes approximately 60-70% of the total system energy. In-memory computing paradigms address this issue by performing computations directly within memory, substantially reducing energy-intensive data transfers.
Recent research indicates that processing-in-memory (PIM) architectures can achieve energy efficiency improvements of 10-15x compared to conventional CPU-based systems for genomic workloads. This efficiency gain stems from the elimination of redundant data movement across the memory hierarchy. For instance, resistive random-access memory (ReRAM)-based accelerators have demonstrated energy consumption as low as 0.3-0.5 pJ per cell operation when performing sequence alignment tasks, compared to 20-30 pJ in traditional CMOS-based implementations.
Thermal management represents another crucial aspect of energy efficiency in genomic computing accelerators. The dense integration of computing elements in memory arrays can lead to hotspots that degrade performance and reliability. Advanced cooling solutions and dynamic thermal management techniques have been developed to address this challenge, including liquid cooling systems and thermally-aware task scheduling algorithms that distribute computational load to minimize temperature gradients across the chip.
Power delivery networks for in-memory accelerators require careful design considerations to ensure stable operation under varying computational loads. Voltage droop and IR drop issues become particularly pronounced in large-scale accelerators processing genomic data. Multi-level power delivery architectures with distributed voltage regulators have shown promise in maintaining power integrity while minimizing energy losses in the delivery network.
Dynamic voltage and frequency scaling (DVFS) techniques have been adapted specifically for genomic workloads, enabling fine-grained energy-performance tradeoffs based on the characteristics of different sequence alignment algorithms. For example, during seed generation phases that exhibit high parallelism, voltage can be lowered while maintaining throughput, whereas extension phases may require higher operating points to maintain performance. Studies show that workload-aware DVFS policies can reduce energy consumption by 25-30% with minimal impact on overall execution time.
Recent research indicates that processing-in-memory (PIM) architectures can achieve energy efficiency improvements of 10-15x compared to conventional CPU-based systems for genomic workloads. This efficiency gain stems from the elimination of redundant data movement across the memory hierarchy. For instance, resistive random-access memory (ReRAM)-based accelerators have demonstrated energy consumption as low as 0.3-0.5 pJ per cell operation when performing sequence alignment tasks, compared to 20-30 pJ in traditional CMOS-based implementations.
Thermal management represents another crucial aspect of energy efficiency in genomic computing accelerators. The dense integration of computing elements in memory arrays can lead to hotspots that degrade performance and reliability. Advanced cooling solutions and dynamic thermal management techniques have been developed to address this challenge, including liquid cooling systems and thermally-aware task scheduling algorithms that distribute computational load to minimize temperature gradients across the chip.
Power delivery networks for in-memory accelerators require careful design considerations to ensure stable operation under varying computational loads. Voltage droop and IR drop issues become particularly pronounced in large-scale accelerators processing genomic data. Multi-level power delivery architectures with distributed voltage regulators have shown promise in maintaining power integrity while minimizing energy losses in the delivery network.
Dynamic voltage and frequency scaling (DVFS) techniques have been adapted specifically for genomic workloads, enabling fine-grained energy-performance tradeoffs based on the characteristics of different sequence alignment algorithms. For example, during seed generation phases that exhibit high parallelism, voltage can be lowered while maintaining throughput, whereas extension phases may require higher operating points to maintain performance. Studies show that workload-aware DVFS policies can reduce energy consumption by 25-30% with minimal impact on overall execution time.
Data Privacy and Security in Genomic Processing
Genomic data represents one of the most sensitive categories of personal information, containing details about an individual's genetic makeup, predisposition to diseases, and ancestral origins. As In-Memory Computing (IMC) accelerators for genome sequence alignment tasks become more prevalent, the protection of this highly sensitive data emerges as a critical concern. Traditional security measures often prove inadequate when processing genomic data at the scale and speed enabled by IMC architectures.
The implementation of IMC accelerators introduces unique security vulnerabilities due to the persistent nature of data in memory. Unlike conventional computing paradigms where data remains in memory temporarily, IMC systems maintain data for extended periods, creating expanded attack surfaces for potential breaches. Side-channel attacks targeting memory access patterns have demonstrated particular effectiveness against genomic processing systems, potentially revealing sensitive genetic information without directly accessing the encrypted data.
Homomorphic encryption represents a promising approach for securing genomic data during processing. This technique allows computations to be performed on encrypted data without requiring decryption, maintaining privacy throughout the alignment process. However, current homomorphic encryption implementations introduce significant computational overhead, often negating the performance advantages offered by IMC accelerators. Research indicates a 20-50x performance penalty when applying full homomorphic encryption to genomic workloads.
Secure Multi-party Computation (MPC) offers an alternative framework that enables multiple parties to jointly compute functions over genomic data while keeping their inputs private. This approach proves particularly valuable in collaborative genomic research scenarios where institutions share computational resources but must maintain data confidentiality. Several IMC accelerator designs have begun incorporating hardware-level MPC support, reducing the associated performance penalties to more manageable levels.
Differential privacy techniques provide another layer of protection by introducing controlled noise into genomic datasets, preventing the identification of individual genetic profiles while preserving the statistical utility of aggregate results. This approach has gained traction in large-scale genomic studies where population-level insights are prioritized over individual-specific analyses.
Regulatory frameworks governing genomic data security vary significantly across jurisdictions, creating compliance challenges for organizations deploying IMC accelerators globally. The General Data Protection Regulation (GDPR) in Europe and the Health Insurance Portability and Accountability Act (HIPAA) in the United States impose strict requirements on genomic data processing, necessitating careful architectural considerations in IMC accelerator design and deployment.
The implementation of IMC accelerators introduces unique security vulnerabilities due to the persistent nature of data in memory. Unlike conventional computing paradigms where data remains in memory temporarily, IMC systems maintain data for extended periods, creating expanded attack surfaces for potential breaches. Side-channel attacks targeting memory access patterns have demonstrated particular effectiveness against genomic processing systems, potentially revealing sensitive genetic information without directly accessing the encrypted data.
Homomorphic encryption represents a promising approach for securing genomic data during processing. This technique allows computations to be performed on encrypted data without requiring decryption, maintaining privacy throughout the alignment process. However, current homomorphic encryption implementations introduce significant computational overhead, often negating the performance advantages offered by IMC accelerators. Research indicates a 20-50x performance penalty when applying full homomorphic encryption to genomic workloads.
Secure Multi-party Computation (MPC) offers an alternative framework that enables multiple parties to jointly compute functions over genomic data while keeping their inputs private. This approach proves particularly valuable in collaborative genomic research scenarios where institutions share computational resources but must maintain data confidentiality. Several IMC accelerator designs have begun incorporating hardware-level MPC support, reducing the associated performance penalties to more manageable levels.
Differential privacy techniques provide another layer of protection by introducing controlled noise into genomic datasets, preventing the identification of individual genetic profiles while preserving the statistical utility of aggregate results. This approach has gained traction in large-scale genomic studies where population-level insights are prioritized over individual-specific analyses.
Regulatory frameworks governing genomic data security vary significantly across jurisdictions, creating compliance challenges for organizations deploying IMC accelerators globally. The General Data Protection Regulation (GDPR) in Europe and the Health Insurance Portability and Accountability Act (HIPAA) in the United States impose strict requirements on genomic data processing, necessitating careful architectural considerations in IMC accelerator design and deployment.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!