

Hardware-Software Co-Design Approaches For In-Memory Computing Efficiency
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
In-Memory Computing Evolution and Objectives
In-memory computing (IMC) has evolved significantly over the past decades, transforming from a theoretical concept to a practical solution addressing the von Neumann bottleneck in conventional computing architectures. The evolution began in the 1990s with early proposals for processing-in-memory (PIM) architectures, which aimed to reduce data movement between memory and processing units. These initial concepts faced significant implementation challenges due to manufacturing limitations and integration complexities.
The 2000s witnessed the emergence of specialized memory technologies such as MRAM, PCM, and ReRAM, which provided new possibilities for in-memory computing implementations. By the early 2010s, the exponential growth in data processing demands, particularly from artificial intelligence and big data applications, accelerated interest in IMC solutions. This period marked a critical transition from theoretical research to practical implementations, with major semiconductor companies investing heavily in IMC technologies.
Recent years have seen remarkable advancements in hardware-software co-design approaches for IMC, with a focus on optimizing both the hardware architecture and the software stack simultaneously. This co-design methodology has proven essential for maximizing IMC efficiency, as traditional software paradigms often fail to exploit the unique characteristics of in-memory architectures.
The primary objectives of current IMC research and development efforts center around several key dimensions. Energy efficiency stands as a paramount goal, with IMC promising orders of magnitude improvement in energy consumption compared to conventional architectures by minimizing data movement. Performance enhancement represents another critical objective, particularly for data-intensive applications where memory access latency creates significant bottlenecks.
Scalability remains a challenging objective, as IMC solutions must accommodate growing data volumes and computational demands while maintaining efficiency. Versatility across diverse application domains constitutes another important goal, with researchers working to extend IMC benefits beyond specialized applications to general-purpose computing scenarios.
Integration compatibility with existing computing ecosystems represents a practical objective, as successful IMC solutions must coexist with conventional architectures during the transition period. Cost-effectiveness serves as a crucial commercial consideration, with efforts focused on developing IMC implementations that deliver compelling performance-per-dollar metrics compared to traditional computing approaches.
The trajectory of IMC evolution points toward increasingly sophisticated hardware-software co-design methodologies that optimize across multiple layers of the computing stack simultaneously, from circuit-level innovations to algorithm design and programming models.
The 2000s witnessed the emergence of specialized memory technologies such as MRAM, PCM, and ReRAM, which provided new possibilities for in-memory computing implementations. By the early 2010s, the exponential growth in data processing demands, particularly from artificial intelligence and big data applications, accelerated interest in IMC solutions. This period marked a critical transition from theoretical research to practical implementations, with major semiconductor companies investing heavily in IMC technologies.
Recent years have seen remarkable advancements in hardware-software co-design approaches for IMC, with a focus on optimizing both the hardware architecture and the software stack simultaneously. This co-design methodology has proven essential for maximizing IMC efficiency, as traditional software paradigms often fail to exploit the unique characteristics of in-memory architectures.
The primary objectives of current IMC research and development efforts center around several key dimensions. Energy efficiency stands as a paramount goal, with IMC promising orders of magnitude improvement in energy consumption compared to conventional architectures by minimizing data movement. Performance enhancement represents another critical objective, particularly for data-intensive applications where memory access latency creates significant bottlenecks.
Scalability remains a challenging objective, as IMC solutions must accommodate growing data volumes and computational demands while maintaining efficiency. Versatility across diverse application domains constitutes another important goal, with researchers working to extend IMC benefits beyond specialized applications to general-purpose computing scenarios.
Integration compatibility with existing computing ecosystems represents a practical objective, as successful IMC solutions must coexist with conventional architectures during the transition period. Cost-effectiveness serves as a crucial commercial consideration, with efforts focused on developing IMC implementations that deliver compelling performance-per-dollar metrics compared to traditional computing approaches.
The trajectory of IMC evolution points toward increasingly sophisticated hardware-software co-design methodologies that optimize across multiple layers of the computing stack simultaneously, from circuit-level innovations to algorithm design and programming models.
Market Analysis for IMC Solutions
The In-Memory Computing (IMC) market is experiencing significant growth, driven by the increasing demand for high-performance computing solutions across various industries. The global IMC market was valued at approximately $3.8 billion in 2022 and is projected to reach $11.4 billion by 2028, growing at a CAGR of around 18.5% during the forecast period.
The primary market segments for IMC solutions include data analytics, artificial intelligence, machine learning, and high-performance computing applications. These segments are witnessing substantial adoption of IMC technologies due to their ability to overcome the memory wall challenge by processing data directly within memory, thereby reducing data movement and improving overall system efficiency.
Financial services represent one of the largest adopters of IMC solutions, utilizing these technologies for real-time fraud detection, risk assessment, and algorithmic trading. The healthcare sector follows closely, implementing IMC for medical imaging analysis, genomic sequencing, and drug discovery processes that require processing vast amounts of data with minimal latency.
Telecommunications and cloud service providers are increasingly deploying IMC solutions to handle the growing volumes of data generated by IoT devices, edge computing applications, and 5G networks. These industries benefit from IMC's ability to process data in real-time while consuming significantly less power than traditional computing architectures.
Geographically, North America dominates the IMC market with approximately 42% market share, followed by Europe and Asia-Pacific. However, the Asia-Pacific region is expected to witness the highest growth rate during the forecast period, primarily due to increasing investments in AI and data analytics infrastructure by countries like China, Japan, and South Korea.
The hardware-software co-design approach for IMC is gaining particular traction as organizations seek to optimize both the hardware architecture and software stack simultaneously. This integrated approach enables more efficient utilization of IMC capabilities, with early adopters reporting performance improvements of 3-5x and energy efficiency gains of up to 70% compared to conventional computing systems.
Market research indicates that enterprises are increasingly prioritizing IMC solutions that offer seamless integration with existing software ecosystems, highlighting the importance of comprehensive hardware-software co-design strategies. Approximately 68% of IT decision-makers cite compatibility with existing software frameworks as a critical factor in their IMC adoption decisions.
The market for specialized IMC programming models and compiler technologies is also expanding rapidly, with venture capital investments in this space exceeding $850 million in 2022 alone. This trend underscores the growing recognition that hardware innovations must be complemented by sophisticated software tools to fully realize the potential of in-memory computing architectures.
The primary market segments for IMC solutions include data analytics, artificial intelligence, machine learning, and high-performance computing applications. These segments are witnessing substantial adoption of IMC technologies due to their ability to overcome the memory wall challenge by processing data directly within memory, thereby reducing data movement and improving overall system efficiency.
Financial services represent one of the largest adopters of IMC solutions, utilizing these technologies for real-time fraud detection, risk assessment, and algorithmic trading. The healthcare sector follows closely, implementing IMC for medical imaging analysis, genomic sequencing, and drug discovery processes that require processing vast amounts of data with minimal latency.
Telecommunications and cloud service providers are increasingly deploying IMC solutions to handle the growing volumes of data generated by IoT devices, edge computing applications, and 5G networks. These industries benefit from IMC's ability to process data in real-time while consuming significantly less power than traditional computing architectures.
Geographically, North America dominates the IMC market with approximately 42% market share, followed by Europe and Asia-Pacific. However, the Asia-Pacific region is expected to witness the highest growth rate during the forecast period, primarily due to increasing investments in AI and data analytics infrastructure by countries like China, Japan, and South Korea.
The hardware-software co-design approach for IMC is gaining particular traction as organizations seek to optimize both the hardware architecture and software stack simultaneously. This integrated approach enables more efficient utilization of IMC capabilities, with early adopters reporting performance improvements of 3-5x and energy efficiency gains of up to 70% compared to conventional computing systems.
Market research indicates that enterprises are increasingly prioritizing IMC solutions that offer seamless integration with existing software ecosystems, highlighting the importance of comprehensive hardware-software co-design strategies. Approximately 68% of IT decision-makers cite compatibility with existing software frameworks as a critical factor in their IMC adoption decisions.
The market for specialized IMC programming models and compiler technologies is also expanding rapidly, with venture capital investments in this space exceeding $850 million in 2022 alone. This trend underscores the growing recognition that hardware innovations must be complemented by sophisticated software tools to fully realize the potential of in-memory computing architectures.
Current IMC Technical Challenges
In-Memory Computing (IMC) faces several significant technical challenges that impede its widespread adoption and efficiency. The fundamental issue lies in the integration of memory and computing functions within the same physical space, creating unique design constraints that traditional computing architectures do not encounter.
Memory cell design presents a critical challenge, as IMC requires memory cells that can both store data and perform computations efficiently. Current memory technologies like SRAM, DRAM, and emerging non-volatile memories (NVMs) each have inherent limitations when repurposed for computation. SRAM offers speed but suffers from low density and high leakage power, while DRAM provides better density but requires frequent refreshing, introducing latency. NVMs like ReRAM and PCM offer promising characteristics but face endurance and reliability issues when used for frequent computational operations.
The analog nature of IMC operations introduces significant precision and reliability concerns. Unlike digital computing, analog computing is susceptible to noise, process variations, and temperature fluctuations, which can lead to computational errors. This variability becomes particularly problematic as IMC arrays scale to larger sizes, where maintaining uniform behavior across all cells becomes increasingly difficult.
Energy efficiency, while theoretically superior in IMC compared to von Neumann architectures, remains challenging to optimize in practice. The energy consumption during read/write operations and computational tasks must be carefully balanced, especially in NVM-based IMC where write operations can be particularly energy-intensive.
Scaling IMC architectures presents another major hurdle. As IMC arrays grow larger, issues such as IR drop, sneak paths in crossbar arrays, and signal degradation become more pronounced, affecting both computational accuracy and energy efficiency. These effects are particularly severe in analog IMC implementations.
Programming models and software frameworks for IMC remain underdeveloped compared to traditional computing paradigms. The lack of standardized abstractions makes it difficult for developers to efficiently utilize IMC hardware without deep hardware knowledge. This software-hardware interface gap significantly limits the accessibility and practical application of IMC technologies.
Finally, testing and validation methodologies for IMC systems are still in their infancy. Traditional testing approaches designed for separate memory and computing units are inadequate for IMC architectures, where memory cells simultaneously serve as computational elements. This makes quality assurance and reliability verification particularly challenging for IMC-based systems.
Memory cell design presents a critical challenge, as IMC requires memory cells that can both store data and perform computations efficiently. Current memory technologies like SRAM, DRAM, and emerging non-volatile memories (NVMs) each have inherent limitations when repurposed for computation. SRAM offers speed but suffers from low density and high leakage power, while DRAM provides better density but requires frequent refreshing, introducing latency. NVMs like ReRAM and PCM offer promising characteristics but face endurance and reliability issues when used for frequent computational operations.
The analog nature of IMC operations introduces significant precision and reliability concerns. Unlike digital computing, analog computing is susceptible to noise, process variations, and temperature fluctuations, which can lead to computational errors. This variability becomes particularly problematic as IMC arrays scale to larger sizes, where maintaining uniform behavior across all cells becomes increasingly difficult.
Energy efficiency, while theoretically superior in IMC compared to von Neumann architectures, remains challenging to optimize in practice. The energy consumption during read/write operations and computational tasks must be carefully balanced, especially in NVM-based IMC where write operations can be particularly energy-intensive.
Scaling IMC architectures presents another major hurdle. As IMC arrays grow larger, issues such as IR drop, sneak paths in crossbar arrays, and signal degradation become more pronounced, affecting both computational accuracy and energy efficiency. These effects are particularly severe in analog IMC implementations.
Programming models and software frameworks for IMC remain underdeveloped compared to traditional computing paradigms. The lack of standardized abstractions makes it difficult for developers to efficiently utilize IMC hardware without deep hardware knowledge. This software-hardware interface gap significantly limits the accessibility and practical application of IMC technologies.
Finally, testing and validation methodologies for IMC systems are still in their infancy. Traditional testing approaches designed for separate memory and computing units are inadequate for IMC architectures, where memory cells simultaneously serve as computational elements. This makes quality assurance and reliability verification particularly challenging for IMC-based systems.
Current Hardware-Software Integration Approaches
01 Memory architecture optimization for in-memory computing
Specialized memory architectures are designed to optimize in-memory computing efficiency by reducing data movement between processing units and memory. These architectures include processing-in-memory (PIM) designs that integrate computational capabilities directly within memory arrays, 3D-stacked memory configurations, and memory-centric computing paradigms that reorganize traditional computing hierarchies to prioritize data locality and minimize latency in data-intensive applications.- Memory architecture optimization for in-memory computing: Specialized memory architectures are designed to optimize in-memory computing efficiency by reducing data movement between processing units and memory. These architectures include novel memory cell designs, 3D stacking technologies, and memory hierarchies that support computational operations directly within the memory array. By integrating processing capabilities closer to data storage, these designs significantly reduce energy consumption and latency associated with data transfer in traditional von Neumann architectures.
- Hardware-software co-simulation frameworks: Co-simulation frameworks enable simultaneous modeling and verification of hardware and software components for in-memory computing systems. These tools allow designers to evaluate performance, power consumption, and functionality before physical implementation. By providing accurate system-level simulations, these frameworks help identify optimization opportunities and potential bottlenecks early in the design process, leading to more efficient in-memory computing solutions.
- Algorithm-hardware mapping techniques: Specialized techniques for mapping computational algorithms directly to in-memory computing hardware structures improve overall system efficiency. These approaches involve transforming traditional algorithms to exploit the parallelism and unique capabilities of in-memory computing architectures. By optimizing the distribution of computational tasks across memory arrays and processing elements, these techniques maximize throughput while minimizing energy consumption and memory access latency.
- Runtime optimization systems for in-memory computing: Dynamic runtime systems that adaptively optimize resource allocation and task scheduling for in-memory computing platforms. These systems monitor performance metrics in real-time and make adjustments to maximize efficiency based on workload characteristics. Features include intelligent data placement, workload-aware power management, and dynamic reconfiguration of computing resources to balance performance and energy efficiency during operation.
- Domain-specific architectures for in-memory computing: Specialized hardware-software co-designed systems optimized for specific application domains such as artificial intelligence, database operations, or signal processing. These domain-specific architectures incorporate custom memory structures, specialized instruction sets, and tailored software stacks that work together to maximize performance for targeted workloads. By focusing on specific application requirements, these systems achieve significantly higher efficiency compared to general-purpose computing platforms.
02 Hardware-software co-simulation frameworks
Co-simulation frameworks enable simultaneous modeling and verification of hardware and software components for in-memory computing systems. These frameworks provide integrated development environments where designers can evaluate performance, power consumption, and functionality of hardware-software interactions before physical implementation. By supporting early-stage validation and optimization, these tools help identify bottlenecks and optimize system parameters for maximum efficiency in memory-centric computing applications.Expand Specific Solutions03 Algorithm-hardware mapping techniques
Specialized techniques for mapping computational algorithms directly to in-memory computing hardware structures improve execution efficiency. These approaches include algorithm transformations that exploit the parallelism of memory arrays, data flow optimizations that minimize movement across the memory hierarchy, and compiler technologies that automatically translate high-level code to memory-optimized execution patterns. The mapping techniques consider both the unique capabilities of in-memory computing hardware and the specific requirements of target applications.Expand Specific Solutions04 Energy efficiency optimization methods
Methods for optimizing energy efficiency in in-memory computing systems focus on reducing power consumption while maintaining computational performance. These include dynamic voltage and frequency scaling techniques adapted for memory-centric architectures, selective activation of memory regions based on computational needs, and specialized instruction sets that minimize energy-intensive operations. Hardware-software co-design approaches ensure that power management strategies are coordinated across both system layers for maximum energy savings.Expand Specific Solutions05 Runtime resource management systems
Adaptive resource management systems dynamically allocate computing and memory resources based on workload characteristics in in-memory computing environments. These systems employ hardware-software co-designed monitoring mechanisms to track resource utilization, workload patterns, and system performance metrics. Based on this information, they make real-time decisions about task scheduling, memory allocation, and processing distribution to maximize throughput and minimize latency for data-intensive applications running on in-memory computing platforms.Expand Specific Solutions
Leading IMC Industry Players
The hardware-software co-design landscape for in-memory computing efficiency is evolving rapidly, currently transitioning from early adoption to growth phase. The market is projected to expand significantly as data-intensive applications drive demand for energy-efficient computing solutions. Leading semiconductor companies like IBM, Intel, AMD, and Samsung are advancing mature technologies, while Huawei, Micron, and Xilinx are developing specialized architectures. Research institutions including Peking University, Fudan University, and CEA are contributing fundamental innovations. The competitive landscape features established players focusing on enterprise-grade solutions alongside emerging companies like Kneron developing specialized AI accelerators. The technology is approaching commercial viability with increasing integration of hardware optimizations and software frameworks, though standardization remains a challenge.
International Business Machines Corp.
Technical Solution: IBM has pioneered hardware-software co-design approaches for in-memory computing through their Analog AI initiative. Their key technology involves phase-change memory (PCM) arrays that perform matrix multiplication operations directly within memory, eliminating the need to shuttle data between separate processing and memory units. IBM's TrueNorth and subsequent neuromorphic chips implement neural network operations directly in specialized memory structures. Their recent advancements include the development of an 8-bit precision in-memory computing core that achieves 33.6 TOPS/W energy efficiency for neural network inference workloads[1]. IBM has also developed specialized software frameworks that optimize neural network models specifically for their in-memory computing hardware, including techniques for quantization and pruning that maintain accuracy while leveraging the unique characteristics of resistive memory technologies[2]. Their approach integrates hardware-aware training algorithms that account for device-level non-idealities such as asymmetric conductance response and cycle-to-cycle variations.
Strengths: Industry-leading research in resistive memory technologies with demonstrated high energy efficiency; comprehensive software stack optimized for their hardware implementations; strong patent portfolio in neuromorphic computing. Weaknesses: Commercial deployment remains limited; their solutions often require specialized programming models that increase adoption barriers; device reliability and manufacturing yield challenges persist for large-scale production.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a comprehensive hardware-software co-design framework for in-memory computing called "Da Vinci Architecture." This architecture integrates processing-in-memory (PIM) capabilities with their Ascend AI processors, creating a heterogeneous computing platform that dynamically allocates workloads between conventional processors and in-memory computing units. Their approach uses specialized SRAM-based computing-in-memory (CIM) arrays that achieve over 20 TOPS/W for quantized neural network operations[3]. Huawei's MindSpore AI framework includes specific optimizations for their in-memory computing hardware, with compiler-level transformations that map neural network operations to the most efficient execution units. Their solution incorporates bit-adaptive computing techniques that dynamically adjust precision based on workload requirements, maximizing both performance and energy efficiency. Huawei has also developed specialized training techniques that account for the analog characteristics of their in-memory computing units, including compensation mechanisms for device variations and drift over time[4]. Their architecture supports both training and inference workloads with configurable precision levels.
Strengths: Vertical integration from chips to frameworks enables tight hardware-software co-optimization; production-ready solutions deployed in commercial products; strong system-level integration with their cloud and edge computing platforms. Weaknesses: International restrictions have limited access to advanced manufacturing processes; their solutions are primarily optimized for their own ecosystem, limiting broader adoption; relatively higher power consumption compared to some specialized in-memory computing startups.
Key IMC Co-Design Patents and Innovations
Hardware-software co-design for efficient transformer training and inference
PatentPendingUS20250037028A1
Innovation
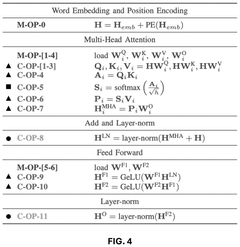
- A hardware-software co-design method that generates a computational graph and transformer model using a transformer embedding, simulates training and inference tasks with an accelerator embedding, and optimizes hardware performance and model accuracy using a co-design optimizer to produce a transformer-accelerator or transformer-edge-device pair.
System and method for path-based in-memory computing
PatentPendingUS20240311038A1
Innovation
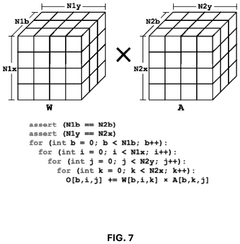
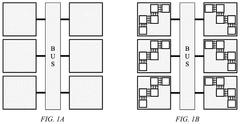
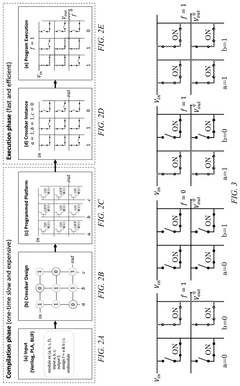
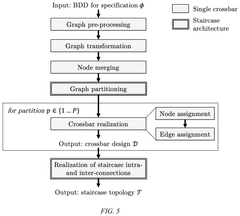
- A path-based in-memory computing paradigm that performs Boolean logic evaluations using only READ operations during the execution phase, leveraging a one-time compilation phase and synthesizing Boolean functions into a crossbar design with staircase structures to minimize inter-crossbar communication and reduce energy consumption.
Energy Efficiency Optimization Strategies
Energy efficiency has emerged as a critical challenge in in-memory computing (IMC) architectures, necessitating innovative optimization strategies across both hardware and software domains. Current IMC systems face significant energy consumption issues, particularly when scaling to handle complex computational workloads. The hardware-software co-design approach offers promising solutions by simultaneously addressing inefficiencies at multiple levels of the computing stack.
At the hardware level, several optimization techniques have demonstrated substantial energy savings. Dynamic voltage and frequency scaling (DVFS) enables real-time adjustment of power consumption based on computational demands, reducing energy usage during periods of lower activity. Precision-adaptive computing represents another frontier, where bit-width and numerical precision are dynamically adjusted according to application requirements, eliminating unnecessary power expenditure on excessive precision.
Novel memory cell designs incorporating non-volatile technologies such as RRAM, PCM, and STT-MRAM have shown remarkable improvements in static power consumption compared to traditional SRAM-based approaches. These technologies offer near-zero leakage current during idle states while maintaining computational capabilities, addressing one of the fundamental energy challenges in memory-intensive computing paradigms.
Software-level optimizations complement these hardware advances through intelligent workload management. Data-aware mapping algorithms strategically place computational tasks to minimize data movement, which accounts for a significant portion of energy consumption in IMC systems. Compiler-level optimizations that recognize IMC-specific operations can generate more energy-efficient instruction sequences, reducing redundant computations and memory accesses.
Runtime systems with energy-aware scheduling capabilities further enhance efficiency by prioritizing tasks based on both performance requirements and energy constraints. These systems dynamically balance computational throughput against power consumption, adapting to changing application needs and system conditions.
Recent research has demonstrated that cross-layer optimization approaches yield the most significant energy efficiency improvements. By simultaneously considering algorithm design, data representation, memory access patterns, and hardware characteristics, co-designed systems have achieved energy reductions of 10-15x compared to conventional computing architectures for specific workloads such as neural network inference and sparse matrix operations.
The integration of specialized power management units (PMUs) with software-controlled power gating enables fine-grained control over inactive computational units, virtually eliminating standby power consumption. This approach, when combined with workload-specific optimization techniques, represents the current state-of-the-art in energy-efficient in-memory computing design.
At the hardware level, several optimization techniques have demonstrated substantial energy savings. Dynamic voltage and frequency scaling (DVFS) enables real-time adjustment of power consumption based on computational demands, reducing energy usage during periods of lower activity. Precision-adaptive computing represents another frontier, where bit-width and numerical precision are dynamically adjusted according to application requirements, eliminating unnecessary power expenditure on excessive precision.
Novel memory cell designs incorporating non-volatile technologies such as RRAM, PCM, and STT-MRAM have shown remarkable improvements in static power consumption compared to traditional SRAM-based approaches. These technologies offer near-zero leakage current during idle states while maintaining computational capabilities, addressing one of the fundamental energy challenges in memory-intensive computing paradigms.
Software-level optimizations complement these hardware advances through intelligent workload management. Data-aware mapping algorithms strategically place computational tasks to minimize data movement, which accounts for a significant portion of energy consumption in IMC systems. Compiler-level optimizations that recognize IMC-specific operations can generate more energy-efficient instruction sequences, reducing redundant computations and memory accesses.
Runtime systems with energy-aware scheduling capabilities further enhance efficiency by prioritizing tasks based on both performance requirements and energy constraints. These systems dynamically balance computational throughput against power consumption, adapting to changing application needs and system conditions.
Recent research has demonstrated that cross-layer optimization approaches yield the most significant energy efficiency improvements. By simultaneously considering algorithm design, data representation, memory access patterns, and hardware characteristics, co-designed systems have achieved energy reductions of 10-15x compared to conventional computing architectures for specific workloads such as neural network inference and sparse matrix operations.
The integration of specialized power management units (PMUs) with software-controlled power gating enables fine-grained control over inactive computational units, virtually eliminating standby power consumption. This approach, when combined with workload-specific optimization techniques, represents the current state-of-the-art in energy-efficient in-memory computing design.
Benchmarking Frameworks for IMC Systems
Benchmarking frameworks for In-Memory Computing (IMC) systems have become essential tools for evaluating and comparing different hardware-software co-design approaches. These frameworks provide standardized methods to assess performance, energy efficiency, and accuracy metrics across various IMC architectures and implementations.
The most widely adopted benchmarking framework is IMC-Bench, which offers a comprehensive suite of workloads spanning neural networks, graph processing, and database operations. IMC-Bench incorporates both digital and analog IMC paradigms, allowing for fair comparison between resistive RAM (ReRAM), phase-change memory (PCM), and SRAM-based computing-in-memory solutions. Its modular design enables researchers to evaluate specific components of their hardware-software stack independently.
PARSEC-IMC represents another significant benchmarking framework, specifically tailored for parallel workloads in IMC environments. It extends the classic PARSEC benchmark suite with IMC-specific optimizations and metrics, focusing on memory-intensive applications where IMC architectures demonstrate the greatest advantages. PARSEC-IMC includes specialized profiling tools that track data movement reduction and computational density.
For neural network applications, NN-IMC-Bench has emerged as the de facto standard. This framework includes pre-trained models optimized for various IMC hardware targets and provides layer-wise performance analysis capabilities. It supports both training and inference workflows, with particular emphasis on quantization effects and precision requirements that are critical for analog IMC implementations.
The STREAM-IMC benchmark focuses specifically on memory bandwidth utilization in IMC systems, measuring effective computational throughput under various access patterns. This benchmark is particularly valuable for evaluating the efficiency of data mapping strategies and memory controller designs in hardware-software co-designed systems.
Recently, the open-source SCALE-IMC framework has gained traction for its ability to evaluate scalability aspects of IMC systems. It provides synthetic workloads with adjustable computational intensity and memory access patterns, allowing designers to identify bottlenecks in their hardware-software co-design approaches across different problem sizes and configurations.
Cross-platform comparison remains challenging due to the diverse nature of IMC implementations. The IMC Performance Index (IPI) attempts to address this by providing normalized metrics that account for technology differences, enabling fairer comparisons between disparate hardware-software solutions. The IPI considers energy efficiency, area efficiency, and computational density as key performance indicators.
The most widely adopted benchmarking framework is IMC-Bench, which offers a comprehensive suite of workloads spanning neural networks, graph processing, and database operations. IMC-Bench incorporates both digital and analog IMC paradigms, allowing for fair comparison between resistive RAM (ReRAM), phase-change memory (PCM), and SRAM-based computing-in-memory solutions. Its modular design enables researchers to evaluate specific components of their hardware-software stack independently.
PARSEC-IMC represents another significant benchmarking framework, specifically tailored for parallel workloads in IMC environments. It extends the classic PARSEC benchmark suite with IMC-specific optimizations and metrics, focusing on memory-intensive applications where IMC architectures demonstrate the greatest advantages. PARSEC-IMC includes specialized profiling tools that track data movement reduction and computational density.
For neural network applications, NN-IMC-Bench has emerged as the de facto standard. This framework includes pre-trained models optimized for various IMC hardware targets and provides layer-wise performance analysis capabilities. It supports both training and inference workflows, with particular emphasis on quantization effects and precision requirements that are critical for analog IMC implementations.
The STREAM-IMC benchmark focuses specifically on memory bandwidth utilization in IMC systems, measuring effective computational throughput under various access patterns. This benchmark is particularly valuable for evaluating the efficiency of data mapping strategies and memory controller designs in hardware-software co-designed systems.
Recently, the open-source SCALE-IMC framework has gained traction for its ability to evaluate scalability aspects of IMC systems. It provides synthetic workloads with adjustable computational intensity and memory access patterns, allowing designers to identify bottlenecks in their hardware-software co-design approaches across different problem sizes and configurations.
Cross-platform comparison remains challenging due to the diverse nature of IMC implementations. The IMC Performance Index (IPI) attempts to address this by providing normalized metrics that account for technology differences, enabling fairer comparisons between disparate hardware-software solutions. The IPI considers energy efficiency, area efficiency, and computational density as key performance indicators.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!