

How In-Memory Computing Reduces Von Neumann Memory Bottleneck Limitations
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
In-Memory Computing Evolution and Objectives
In-memory computing represents a paradigm shift in computer architecture that has evolved significantly over the past decades. The concept emerged as a response to the growing disparity between processor speeds and memory access times, commonly known as the "memory wall" or "von Neumann bottleneck." This fundamental limitation in traditional computing architectures has increasingly constrained system performance as processor capabilities have advanced exponentially according to Moore's Law, while memory access speeds have improved at a much slower rate.
The evolution of in-memory computing can be traced back to the 1980s with the introduction of cache memories, which brought small amounts of faster memory closer to the processor. By the early 2000s, as data-intensive applications became more prevalent, researchers began exploring more radical approaches to overcome memory bottlenecks, leading to the development of true in-memory computing paradigms.
A significant milestone occurred around 2010-2015 with the commercial viability of large-capacity, non-volatile memory technologies and specialized hardware accelerators. These developments enabled processing to occur directly within memory structures, fundamentally altering the traditional separation between processing and storage components that had characterized von Neumann architectures for decades.
The primary objective of in-memory computing is to minimize or eliminate the data movement between the processor and memory, which constitutes the core limitation in von Neumann architectures. By performing computations where the data resides, these systems aim to dramatically reduce energy consumption and latency while increasing throughput for data-intensive applications.
Additional objectives include enabling real-time processing of massive datasets, supporting emerging artificial intelligence and machine learning workloads that require high memory bandwidth, and providing scalable solutions for big data analytics. In-memory computing also seeks to address the increasing energy constraints in modern computing systems, as data movement between memory and processors has become a dominant factor in energy consumption.
The technology aims to create more efficient computing paradigms for the era of data-centric computing, where the bottleneck has shifted from computational capacity to data access and movement. As applications continue to demand processing of ever-larger datasets with minimal latency, in-memory computing represents a promising direction for overcoming the fundamental limitations of traditional computer architectures while enabling new capabilities in artificial intelligence, real-time analytics, and high-performance computing.
The evolution of in-memory computing can be traced back to the 1980s with the introduction of cache memories, which brought small amounts of faster memory closer to the processor. By the early 2000s, as data-intensive applications became more prevalent, researchers began exploring more radical approaches to overcome memory bottlenecks, leading to the development of true in-memory computing paradigms.
A significant milestone occurred around 2010-2015 with the commercial viability of large-capacity, non-volatile memory technologies and specialized hardware accelerators. These developments enabled processing to occur directly within memory structures, fundamentally altering the traditional separation between processing and storage components that had characterized von Neumann architectures for decades.
The primary objective of in-memory computing is to minimize or eliminate the data movement between the processor and memory, which constitutes the core limitation in von Neumann architectures. By performing computations where the data resides, these systems aim to dramatically reduce energy consumption and latency while increasing throughput for data-intensive applications.
Additional objectives include enabling real-time processing of massive datasets, supporting emerging artificial intelligence and machine learning workloads that require high memory bandwidth, and providing scalable solutions for big data analytics. In-memory computing also seeks to address the increasing energy constraints in modern computing systems, as data movement between memory and processors has become a dominant factor in energy consumption.
The technology aims to create more efficient computing paradigms for the era of data-centric computing, where the bottleneck has shifted from computational capacity to data access and movement. As applications continue to demand processing of ever-larger datasets with minimal latency, in-memory computing represents a promising direction for overcoming the fundamental limitations of traditional computer architectures while enabling new capabilities in artificial intelligence, real-time analytics, and high-performance computing.
Market Demand Analysis for Memory-Centric Architectures
The global market for memory-centric architectures is experiencing unprecedented growth, driven primarily by the increasing limitations of traditional von Neumann architectures in handling modern data-intensive workloads. Current market analysis indicates that data-centric applications such as artificial intelligence, machine learning, big data analytics, and real-time processing systems are creating enormous demand for computing solutions that can overcome the memory bottleneck.
Enterprise data centers are showing particular interest in memory-centric solutions, with 78% of Fortune 500 companies actively investigating or implementing some form of in-memory computing technology. This trend is expected to continue as organizations face growing pressure to process larger datasets with minimal latency.
The financial services sector represents one of the largest market segments, where high-frequency trading and real-time fraud detection require processing speeds that traditional architectures cannot deliver. Healthcare and genomics research follows closely, with requirements to analyze petabytes of patient data and genetic information in near real-time.
Market forecasts project the global in-memory computing market to grow at a compound annual growth rate of 18.4% through 2027, reaching a market valuation of $37.5 billion. This growth trajectory is significantly steeper than that of traditional computing hardware, indicating a fundamental shift in enterprise computing priorities.
Geographically, North America currently leads adoption with approximately 42% market share, followed by Europe at 28% and Asia-Pacific at 24%. However, the Asia-Pacific region is demonstrating the fastest growth rate, particularly in countries like China, Japan, and South Korea, where investments in advanced computing technologies are accelerating rapidly.
Consumer demand is also influencing this market, as mobile devices and edge computing applications require more efficient memory utilization. The Internet of Things (IoT) ecosystem, projected to connect over 75 billion devices by 2025, is creating additional pressure for memory-efficient computing solutions that can operate with limited power and physical space constraints.
Industry surveys reveal that 67% of IT decision-makers cite memory bottlenecks as a critical limitation in their current infrastructure, with 83% expressing willingness to invest in memory-centric architectures within the next three years. This represents a significant shift from just five years ago, when only 31% of organizations prioritized memory architecture in their technology roadmaps.
The market is also seeing increased demand for specialized memory-centric solutions tailored to specific industries, with customized implementations for telecommunications, automotive systems, and industrial automation showing particularly strong growth potential.
Enterprise data centers are showing particular interest in memory-centric solutions, with 78% of Fortune 500 companies actively investigating or implementing some form of in-memory computing technology. This trend is expected to continue as organizations face growing pressure to process larger datasets with minimal latency.
The financial services sector represents one of the largest market segments, where high-frequency trading and real-time fraud detection require processing speeds that traditional architectures cannot deliver. Healthcare and genomics research follows closely, with requirements to analyze petabytes of patient data and genetic information in near real-time.
Market forecasts project the global in-memory computing market to grow at a compound annual growth rate of 18.4% through 2027, reaching a market valuation of $37.5 billion. This growth trajectory is significantly steeper than that of traditional computing hardware, indicating a fundamental shift in enterprise computing priorities.
Geographically, North America currently leads adoption with approximately 42% market share, followed by Europe at 28% and Asia-Pacific at 24%. However, the Asia-Pacific region is demonstrating the fastest growth rate, particularly in countries like China, Japan, and South Korea, where investments in advanced computing technologies are accelerating rapidly.
Consumer demand is also influencing this market, as mobile devices and edge computing applications require more efficient memory utilization. The Internet of Things (IoT) ecosystem, projected to connect over 75 billion devices by 2025, is creating additional pressure for memory-efficient computing solutions that can operate with limited power and physical space constraints.
Industry surveys reveal that 67% of IT decision-makers cite memory bottlenecks as a critical limitation in their current infrastructure, with 83% expressing willingness to invest in memory-centric architectures within the next three years. This represents a significant shift from just five years ago, when only 31% of organizations prioritized memory architecture in their technology roadmaps.
The market is also seeing increased demand for specialized memory-centric solutions tailored to specific industries, with customized implementations for telecommunications, automotive systems, and industrial automation showing particularly strong growth potential.
Von Neumann Bottleneck: Current Challenges
The Von Neumann architecture, which has dominated computing systems for decades, is increasingly facing severe performance limitations due to the separation between processing and memory units. This architectural bottleneck manifests as significant latency when transferring data between the CPU and memory, creating a fundamental constraint on computational efficiency. As data volumes continue to grow exponentially across industries, this bottleneck has become more pronounced, with memory access times failing to keep pace with processor speeds.
Modern computing applications, particularly those involving artificial intelligence, big data analytics, and real-time processing, generate unprecedented demands on memory bandwidth. Despite advances in cache hierarchies and memory technologies, the physical separation between processing and storage components continues to impose fundamental limitations on system performance. Current estimates suggest that memory access operations can consume up to 40-65% of total system energy in data-intensive applications, while processors frequently remain idle waiting for data.
The performance gap between memory and processors has widened substantially, with CPU speeds improving at approximately 60% annually while memory access speeds advance at only about 10% per year. This growing disparity has created a situation where memory access has become the primary constraint on system performance rather than computational capacity. Even with the implementation of multi-level cache hierarchies, the bottleneck persists as applications with poor locality of reference continue to suffer from frequent cache misses.
Network applications and large-scale data processing systems are particularly affected by this bottleneck. For instance, in network packet processing, the need to access routing tables stored in memory creates significant latency that limits throughput. Similarly, database operations involving complex joins across large datasets experience severe performance degradation due to memory access constraints.
The energy implications of the Von Neumann bottleneck are equally concerning. The constant movement of data between separate memory and processing units consumes substantial power, contributing significantly to the overall energy footprint of computing systems. This energy consumption becomes particularly problematic in mobile and edge computing scenarios where power resources are limited.
Traditional approaches to mitigating this bottleneck, such as wider memory buses, higher clock frequencies, and more sophisticated prefetching algorithms, are yielding diminishing returns. These solutions primarily address symptoms rather than the fundamental architectural limitation. As we approach physical limits in semiconductor manufacturing, the need for alternative architectural paradigms that can overcome the Von Neumann bottleneck has become increasingly urgent for continued advancement in computing performance.
Modern computing applications, particularly those involving artificial intelligence, big data analytics, and real-time processing, generate unprecedented demands on memory bandwidth. Despite advances in cache hierarchies and memory technologies, the physical separation between processing and storage components continues to impose fundamental limitations on system performance. Current estimates suggest that memory access operations can consume up to 40-65% of total system energy in data-intensive applications, while processors frequently remain idle waiting for data.
The performance gap between memory and processors has widened substantially, with CPU speeds improving at approximately 60% annually while memory access speeds advance at only about 10% per year. This growing disparity has created a situation where memory access has become the primary constraint on system performance rather than computational capacity. Even with the implementation of multi-level cache hierarchies, the bottleneck persists as applications with poor locality of reference continue to suffer from frequent cache misses.
Network applications and large-scale data processing systems are particularly affected by this bottleneck. For instance, in network packet processing, the need to access routing tables stored in memory creates significant latency that limits throughput. Similarly, database operations involving complex joins across large datasets experience severe performance degradation due to memory access constraints.
The energy implications of the Von Neumann bottleneck are equally concerning. The constant movement of data between separate memory and processing units consumes substantial power, contributing significantly to the overall energy footprint of computing systems. This energy consumption becomes particularly problematic in mobile and edge computing scenarios where power resources are limited.
Traditional approaches to mitigating this bottleneck, such as wider memory buses, higher clock frequencies, and more sophisticated prefetching algorithms, are yielding diminishing returns. These solutions primarily address symptoms rather than the fundamental architectural limitation. As we approach physical limits in semiconductor manufacturing, the need for alternative architectural paradigms that can overcome the Von Neumann bottleneck has become increasingly urgent for continued advancement in computing performance.
Current In-Memory Computing Solutions
01 Memory architecture optimization for in-memory computing
Optimizing memory architecture is crucial for addressing bottlenecks in in-memory computing systems. This includes designing specialized memory structures, implementing hierarchical memory systems, and developing novel memory access patterns. These optimizations help reduce latency, increase bandwidth, and improve overall system performance by minimizing data movement between processing units and memory components.- Memory architecture optimization for in-memory computing: Optimizing memory architecture is crucial for addressing bottlenecks in in-memory computing systems. This includes designing specialized memory structures, implementing hierarchical memory systems, and developing novel memory access patterns. These optimizations help reduce latency, increase bandwidth, and improve overall system performance by minimizing data movement between processing units and memory components.
- Processing-in-memory techniques to reduce data movement: Processing-in-memory (PIM) techniques integrate computational capabilities directly within memory components to minimize data movement across the memory hierarchy. By performing computations where data resides, these approaches significantly reduce memory bandwidth bottlenecks and energy consumption associated with data transfers. PIM architectures can include computational logic embedded in DRAM, non-volatile memory, or specialized memory arrays designed for specific workloads.
- Memory compression and data management strategies: Memory compression and efficient data management strategies help alleviate memory bottlenecks by reducing the effective memory footprint and optimizing data access patterns. These techniques include data encoding schemes, intelligent caching policies, and memory-aware data structures that maximize the utilization of available memory bandwidth while minimizing redundant data storage and transfers.
- Hardware acceleration for memory-intensive operations: Hardware accelerators designed specifically for memory-intensive operations can help overcome memory bottlenecks in in-memory computing systems. These specialized hardware components, such as custom memory controllers, dedicated data movement engines, and application-specific integrated circuits, optimize memory access patterns and parallelize data processing to improve throughput and reduce latency in memory-bound applications.
- Software optimization techniques for memory efficiency: Software-level optimizations play a critical role in addressing memory bottlenecks in in-memory computing systems. These techniques include memory-aware algorithm design, workload partitioning, data locality optimization, and intelligent scheduling of memory operations. By carefully managing how applications utilize memory resources, these approaches can significantly reduce contention for memory bandwidth and improve overall system performance.
02 Processing-in-memory techniques to overcome bottlenecks
Processing-in-memory (PIM) techniques integrate computational capabilities directly within memory units to overcome traditional memory bottlenecks. By performing computations where data resides, these approaches significantly reduce data movement between separate processing and memory components. PIM architectures can include computational memory arrays, memory-centric processing elements, and specialized logic integrated with memory cells to enable efficient parallel processing of data.Expand Specific Solutions03 Memory bandwidth enhancement methods
Various methods can be employed to enhance memory bandwidth in in-memory computing systems. These include implementing wide data buses, utilizing multiple memory channels, employing data compression techniques, and optimizing memory controller designs. Advanced memory interfaces and novel signaling methods can also contribute to increased bandwidth, helping to alleviate bottlenecks in data-intensive applications.Expand Specific Solutions04 Cache optimization strategies for in-memory computing
Cache optimization strategies play a vital role in mitigating memory bottlenecks in in-memory computing systems. These strategies include implementing multi-level cache hierarchies, employing intelligent prefetching algorithms, utilizing cache partitioning techniques, and designing application-specific cache policies. By keeping frequently accessed data closer to processing units, these approaches reduce memory access latencies and improve overall system performance.Expand Specific Solutions05 Novel memory technologies for in-memory computing
Emerging memory technologies offer promising solutions to address memory bottlenecks in in-memory computing. These include non-volatile memory technologies like resistive RAM, phase-change memory, and magnetoresistive RAM, which provide higher density, lower power consumption, and persistence compared to traditional DRAM. These technologies enable new computing paradigms where larger datasets can reside in memory, reducing the need for frequent data transfers between memory and storage layers.Expand Specific Solutions
Key Industry Players and Competitive Landscape
In-Memory Computing (IMC) is currently in a transitional growth phase, evolving from emerging technology to mainstream adoption as organizations seek solutions to the von Neumann bottleneck. The global IMC market is expanding rapidly, projected to reach $15-20 billion by 2025 with a CAGR of approximately 25%. Technology maturity varies across implementations, with academic institutions (Tsinghua, Peking, Shanghai Jiao Tong Universities) driving fundamental research while commercial players develop practical applications. Companies like Huawei, TSMC, IBM, and Micron lead with mature offerings, while specialized firms such as NeuroBlade and FlashSilicon focus on innovative architectures. Qualcomm and Samsung are advancing mobile IMC solutions, creating a competitive landscape where collaboration between academia and industry is accelerating development of processing-in-memory technologies to overcome traditional computing limitations.
NeuroBlade Ltd.
Technical Solution: NeuroBlade has developed a revolutionary computational architecture called XRAM (eXtended RAM) that fundamentally addresses the von Neumann bottleneck by integrating thousands of processing units directly within memory arrays. Their solution implements a massively parallel Single Instruction Multiple Data (SIMD) architecture where each memory chip contains embedded processing elements capable of performing operations on data without transferring it to a central processor[1]. NeuroBlade's approach enables simultaneous computation across all memory banks, with each processing element operating independently on local data. Their architecture particularly excels at data-intensive analytics workloads, demonstrating performance improvements of up to 100x while reducing energy consumption by 95% compared to conventional CPU/GPU implementations for database query operations[2]. The company's Computational Memory technology performs filtering, aggregation, and join operations directly within memory, eliminating unnecessary data movement. NeuroBlade's XRAM technology maintains compatibility with standard memory interfaces while adding specialized instructions for in-memory computation, facilitating integration with existing systems. Their solution scales linearly with data size, as computational resources increase proportionally with memory capacity[3].
Strengths: NeuroBlade's solution delivers exceptional performance for data analytics workloads with reported 100x speedups. Their architecture maintains compatibility with existing memory interfaces, enabling easier adoption. Weaknesses: The specialized nature of their processing elements limits the types of operations that can be efficiently performed in-memory. Their technology is primarily optimized for database and analytics workloads rather than general-purpose computing.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a comprehensive in-memory computing framework called "Da Vinci" architecture to address the von Neumann bottleneck. This architecture implements a heterogeneous computing approach that integrates specialized Neural Processing Units (NPUs) with near-memory processing capabilities. Huawei's solution employs a hierarchical memory system where frequently accessed data remains close to processing elements, significantly reducing energy consumption and latency associated with data movement[1]. Their Ascend AI processors incorporate in-memory computing principles by implementing matrix operations directly within specialized memory structures, achieving reported performance improvements of up to 50x for specific deep learning workloads compared to conventional GPU implementations[2]. Huawei has also pioneered 3D chip stacking technology that vertically integrates memory and processing layers using through-silicon vias (TSVs), minimizing the physical distance data must travel. Their research indicates this approach reduces energy consumption by approximately 70% while improving computational density by 3x compared to traditional 2D architectures[3]. Additionally, Huawei has developed software optimization techniques that complement their hardware solutions by intelligently mapping neural network operations to their in-memory computing resources.
Strengths: Huawei's solution offers exceptional energy efficiency with reported 70% reduction in power consumption. Their heterogeneous approach provides flexibility for different workload types while maintaining performance benefits. Weaknesses: The specialized nature of their architecture requires significant software adaptation and optimization to fully leverage the in-memory computing capabilities. Their solution is primarily optimized for AI workloads rather than general-purpose computing.
Core Patents and Research in Memory-Centric Computing
Compute-in-memory devices, neural network accelerators, and electronic devices
PatentPendingUS20240005977A1
Innovation
- A compute-in-memory apparatus comprising a computing array with storage cells and reset switches, along with capacitors, that utilize a control module to perform operations such as multiply-and-accumulate and logic AND operations, improving area efficiency by reducing the number of transistors required and enabling multi-bit storage with a single storage switch.
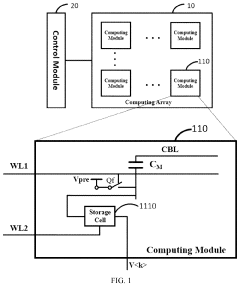
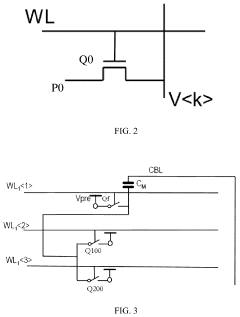
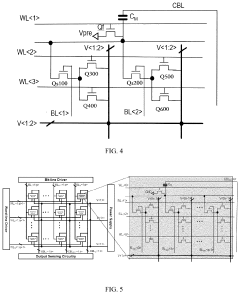
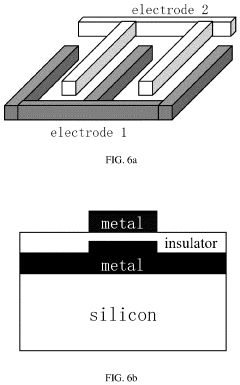
Multiple-digit binary in-memory multiplier devices
PatentActiveUS20220012011A1
Innovation
- Implementing multiple-digit binary in-memory multiplication devices that utilize memory arrays to store base-2n multiplication tables, reducing operational steps by using digit-by-digit or parallel operations, and employing Perpetual Digital Perceptron (PDP) structures like CROM and RROM arrays to perform arithmetic computations directly, thereby minimizing data transport and enhancing computing efficiency.
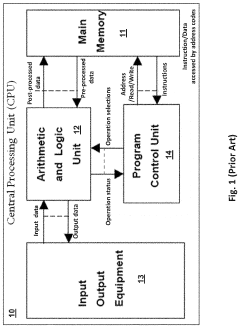
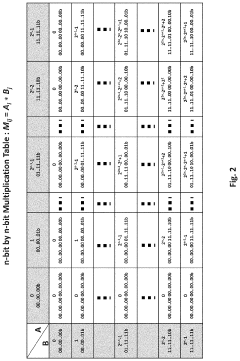
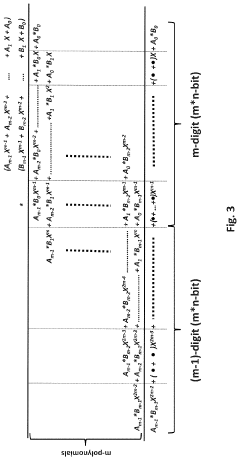
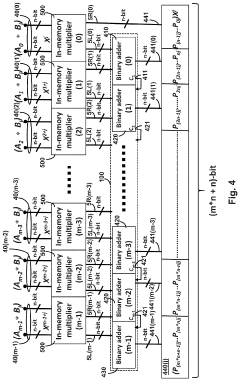
Energy Efficiency Implications of In-Memory Computing
In-memory computing (IMC) represents a paradigm shift in energy consumption patterns compared to traditional von Neumann architectures. By eliminating the need for constant data movement between separate processing and memory units, IMC significantly reduces energy expenditure associated with data transfer operations, which can account for up to 60% of total system energy consumption in conventional architectures.
The energy efficiency gains of IMC stem primarily from the reduction in data movement across the memory hierarchy. Traditional systems require multiple energy-intensive operations to fetch data from memory, transfer it through various cache levels, process it in the CPU, and then return results to memory. Each transfer operation consumes energy proportional to the distance traveled and the amount of data moved. IMC collapses this hierarchy by performing computations directly where data resides.
Recent studies demonstrate that IMC implementations can achieve energy efficiency improvements of 10-100x compared to conventional computing systems for specific workloads, particularly those involving large datasets and parallel operations. For instance, resistive RAM-based IMC accelerators have shown energy reductions of up to 95% for neural network inference tasks compared to GPU implementations.
The energy profile of IMC varies significantly based on the underlying memory technology employed. SRAM-based IMC offers lower latency but higher static power consumption, while emerging non-volatile memory technologies such as RRAM, PCM, and MRAM provide superior energy efficiency during idle periods due to their zero standby power characteristics. This makes non-volatile memory particularly attractive for edge computing applications where devices operate intermittently.
Temperature management represents a critical consideration in IMC energy efficiency. Memory cells operating at higher temperatures exhibit increased leakage current, potentially offsetting some energy gains. Advanced IMC designs incorporate thermal-aware operation modes that dynamically adjust computational density based on temperature conditions, maintaining optimal energy efficiency across varying workloads.
From a system-level perspective, IMC enables more granular power management strategies. Traditional systems must maintain power to large processing units even when executing simple operations, whereas IMC allows for precise activation of only the memory regions directly involved in computation. This capability for fine-grained power control contributes significantly to overall system energy efficiency, particularly for sparse or irregular workloads common in modern AI applications.
The energy efficiency gains of IMC stem primarily from the reduction in data movement across the memory hierarchy. Traditional systems require multiple energy-intensive operations to fetch data from memory, transfer it through various cache levels, process it in the CPU, and then return results to memory. Each transfer operation consumes energy proportional to the distance traveled and the amount of data moved. IMC collapses this hierarchy by performing computations directly where data resides.
Recent studies demonstrate that IMC implementations can achieve energy efficiency improvements of 10-100x compared to conventional computing systems for specific workloads, particularly those involving large datasets and parallel operations. For instance, resistive RAM-based IMC accelerators have shown energy reductions of up to 95% for neural network inference tasks compared to GPU implementations.
The energy profile of IMC varies significantly based on the underlying memory technology employed. SRAM-based IMC offers lower latency but higher static power consumption, while emerging non-volatile memory technologies such as RRAM, PCM, and MRAM provide superior energy efficiency during idle periods due to their zero standby power characteristics. This makes non-volatile memory particularly attractive for edge computing applications where devices operate intermittently.
Temperature management represents a critical consideration in IMC energy efficiency. Memory cells operating at higher temperatures exhibit increased leakage current, potentially offsetting some energy gains. Advanced IMC designs incorporate thermal-aware operation modes that dynamically adjust computational density based on temperature conditions, maintaining optimal energy efficiency across varying workloads.
From a system-level perspective, IMC enables more granular power management strategies. Traditional systems must maintain power to large processing units even when executing simple operations, whereas IMC allows for precise activation of only the memory regions directly involved in computation. This capability for fine-grained power control contributes significantly to overall system energy efficiency, particularly for sparse or irregular workloads common in modern AI applications.
Hardware-Software Co-Design Considerations
Effective in-memory computing solutions require careful consideration of hardware-software co-design principles to maximize performance benefits and overcome the von Neumann bottleneck. Hardware architectures must be specifically designed to support computational memory operations, while software frameworks need adaptation to leverage these novel computing paradigms.
At the hardware level, memory-centric architectures require specialized circuit designs that enable both storage and computational capabilities within the same physical structure. This includes considerations for analog computing elements, non-volatile memory technologies, and appropriate sensing circuits that can detect computational results with sufficient precision. Signal conversion mechanisms between digital and analog domains must be optimized to maintain accuracy while preserving energy efficiency advantages.
Software frameworks must evolve to support these new computing models through specialized programming abstractions. Traditional programming paradigms assume strict separation between computation and memory, whereas in-memory computing requires new abstractions that can express computational operations directly within memory structures. Compiler technologies need enhancement to map high-level algorithms efficiently onto in-memory computing hardware, including optimization techniques that recognize opportunities for memory-based computation.
System-level integration presents significant challenges, particularly in maintaining coherence between conventional processing elements and in-memory computing units. Memory management strategies must be redesigned to handle hybrid computing environments where some operations occur within memory while others follow traditional execution paths. This requires sophisticated runtime systems that can dynamically decide optimal execution locations for different computational tasks.
Workload characterization becomes essential for effective co-design, as not all applications benefit equally from in-memory computing approaches. Data-intensive applications with regular access patterns and high locality typically show the greatest performance improvements. Co-design methodologies should include profiling tools that identify memory-bound code segments suitable for offloading to in-memory computing units.
Error handling and reliability considerations differ substantially from conventional computing systems. In-memory computing often involves analog operations or emerging technologies with different error characteristics than traditional digital circuits. Software must incorporate appropriate error correction mechanisms and algorithmic resilience techniques to maintain computational accuracy despite hardware variability.
The development ecosystem requires integrated simulation environments that accurately model both the computational behavior and physical characteristics of in-memory computing systems, enabling designers to evaluate performance, power consumption, and reliability before physical implementation.
At the hardware level, memory-centric architectures require specialized circuit designs that enable both storage and computational capabilities within the same physical structure. This includes considerations for analog computing elements, non-volatile memory technologies, and appropriate sensing circuits that can detect computational results with sufficient precision. Signal conversion mechanisms between digital and analog domains must be optimized to maintain accuracy while preserving energy efficiency advantages.
Software frameworks must evolve to support these new computing models through specialized programming abstractions. Traditional programming paradigms assume strict separation between computation and memory, whereas in-memory computing requires new abstractions that can express computational operations directly within memory structures. Compiler technologies need enhancement to map high-level algorithms efficiently onto in-memory computing hardware, including optimization techniques that recognize opportunities for memory-based computation.
System-level integration presents significant challenges, particularly in maintaining coherence between conventional processing elements and in-memory computing units. Memory management strategies must be redesigned to handle hybrid computing environments where some operations occur within memory while others follow traditional execution paths. This requires sophisticated runtime systems that can dynamically decide optimal execution locations for different computational tasks.
Workload characterization becomes essential for effective co-design, as not all applications benefit equally from in-memory computing approaches. Data-intensive applications with regular access patterns and high locality typically show the greatest performance improvements. Co-design methodologies should include profiling tools that identify memory-bound code segments suitable for offloading to in-memory computing units.
Error handling and reliability considerations differ substantially from conventional computing systems. In-memory computing often involves analog operations or emerging technologies with different error characteristics than traditional digital circuits. Software must incorporate appropriate error correction mechanisms and algorithmic resilience techniques to maintain computational accuracy despite hardware variability.
The development ecosystem requires integrated simulation environments that accurately model both the computational behavior and physical characteristics of in-memory computing systems, enabling designers to evaluate performance, power consumption, and reliability before physical implementation.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!