

In-Memory Computing Accelerators For Large-Scale Recommender Systems
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
IMC Technology Background and Objectives
In-Memory Computing (IMC) has emerged as a transformative technology paradigm that addresses the fundamental memory-processor bottleneck in modern computing systems. This bottleneck, often referred to as the "memory wall," has become increasingly problematic as data volumes grow exponentially, particularly in data-intensive applications like large-scale recommender systems. The evolution of IMC technology can be traced back to the early 2000s, when researchers began exploring alternatives to the traditional von Neumann architecture to overcome its inherent limitations.
The development trajectory of IMC has been accelerated by the convergence of several technological advances, including the maturation of non-volatile memory technologies, innovations in 3D integration techniques, and breakthroughs in analog computing methodologies. These developments have collectively enabled the processing of data directly within memory units, dramatically reducing data movement and associated energy consumption while simultaneously increasing computational throughput.
For large-scale recommender systems, which form the backbone of many internet services including e-commerce platforms, social media networks, and content streaming services, the computational demands have grown exponentially. These systems process vast amounts of user interaction data to generate personalized recommendations, requiring both high computational capacity and memory bandwidth. Traditional computing architectures struggle to meet these demands efficiently, creating a compelling case for IMC solutions.
The primary technical objective of IMC accelerators for recommender systems is to achieve significant improvements in energy efficiency while maintaining or enhancing computational performance. Specifically, these accelerators aim to reduce energy consumption by orders of magnitude compared to conventional GPU or FPGA implementations, while supporting the complex matrix operations fundamental to recommendation algorithms.
Another critical objective is to enable real-time processing of recommendation queries at scale. As user expectations for personalized experiences grow, the latency requirements for recommendation systems become increasingly stringent. IMC accelerators seek to deliver sub-millisecond response times even as the underlying models grow in complexity and the user base expands.
Scalability represents another key technical goal, with IMC solutions designed to accommodate the ever-increasing size of embedding tables and feature vectors characteristic of modern recommender systems. This includes developing architectures that can efficiently handle sparse operations and dynamic memory access patterns typical in recommendation workloads.
The technology trajectory suggests continued evolution toward more specialized IMC architectures optimized specifically for recommendation workloads, with increasing integration of machine learning capabilities directly into memory subsystems. Future developments are expected to focus on enhancing the programmability of these systems while maintaining their fundamental efficiency advantages.
The development trajectory of IMC has been accelerated by the convergence of several technological advances, including the maturation of non-volatile memory technologies, innovations in 3D integration techniques, and breakthroughs in analog computing methodologies. These developments have collectively enabled the processing of data directly within memory units, dramatically reducing data movement and associated energy consumption while simultaneously increasing computational throughput.
For large-scale recommender systems, which form the backbone of many internet services including e-commerce platforms, social media networks, and content streaming services, the computational demands have grown exponentially. These systems process vast amounts of user interaction data to generate personalized recommendations, requiring both high computational capacity and memory bandwidth. Traditional computing architectures struggle to meet these demands efficiently, creating a compelling case for IMC solutions.
The primary technical objective of IMC accelerators for recommender systems is to achieve significant improvements in energy efficiency while maintaining or enhancing computational performance. Specifically, these accelerators aim to reduce energy consumption by orders of magnitude compared to conventional GPU or FPGA implementations, while supporting the complex matrix operations fundamental to recommendation algorithms.
Another critical objective is to enable real-time processing of recommendation queries at scale. As user expectations for personalized experiences grow, the latency requirements for recommendation systems become increasingly stringent. IMC accelerators seek to deliver sub-millisecond response times even as the underlying models grow in complexity and the user base expands.
Scalability represents another key technical goal, with IMC solutions designed to accommodate the ever-increasing size of embedding tables and feature vectors characteristic of modern recommender systems. This includes developing architectures that can efficiently handle sparse operations and dynamic memory access patterns typical in recommendation workloads.
The technology trajectory suggests continued evolution toward more specialized IMC architectures optimized specifically for recommendation workloads, with increasing integration of machine learning capabilities directly into memory subsystems. Future developments are expected to focus on enhancing the programmability of these systems while maintaining their fundamental efficiency advantages.
Market Analysis for Recommender System Accelerators
The global recommender system market is experiencing robust growth, projected to reach $12.03 billion by 2025 with a compound annual growth rate of 40.7%. This exponential growth is primarily driven by the increasing demand for personalized content across various industries including e-commerce, entertainment, social media, and financial services. Companies like Amazon, Netflix, and Alibaba have demonstrated that effective recommendation engines can significantly increase user engagement, conversion rates, and average order values.
The acceleration hardware market for recommender systems is emerging as a critical subsegment, with specialized in-memory computing solutions gaining particular traction. This market is expected to grow at 36.5% CAGR through 2027, outpacing the overall AI accelerator market. The demand is fueled by the computational challenges posed by modern recommendation models, which have grown from millions to trillions of parameters in just a few years.
Enterprise surveys indicate that 78% of large-scale digital service providers consider recommendation systems as "mission-critical" to their business operations, with 67% reporting challenges related to inference latency and computational efficiency. This has created a substantial market opportunity for specialized hardware accelerators that can address these performance bottlenecks.
Geographically, North America currently dominates the market with approximately 42% share, followed by Asia-Pacific at 31%, which is growing at the fastest rate due to rapid digital transformation in countries like China and India. The European market accounts for 21% and is characterized by strong focus on privacy-preserving recommendation technologies.
By industry vertical, e-commerce represents the largest market segment (38%), followed by streaming media (27%), social networks (18%), and advertising technology (12%). Financial services, healthcare, and industrial applications collectively represent emerging opportunities with significant growth potential.
Customer surveys reveal that the primary purchasing criteria for recommender system accelerators include inference latency (cited by 86% of respondents), energy efficiency (74%), total cost of ownership (71%), and ease of integration with existing software frameworks (68%). This indicates a market that values both performance and operational considerations.
The market is currently transitioning from general-purpose GPU-based acceleration to more specialized solutions, with in-memory computing architectures gaining significant attention due to their ability to address the memory bottleneck in recommendation workloads. Industry analysts predict that by 2026, specialized accelerators will capture 45% of the recommendation system hardware market, up from just 12% in 2022.
The acceleration hardware market for recommender systems is emerging as a critical subsegment, with specialized in-memory computing solutions gaining particular traction. This market is expected to grow at 36.5% CAGR through 2027, outpacing the overall AI accelerator market. The demand is fueled by the computational challenges posed by modern recommendation models, which have grown from millions to trillions of parameters in just a few years.
Enterprise surveys indicate that 78% of large-scale digital service providers consider recommendation systems as "mission-critical" to their business operations, with 67% reporting challenges related to inference latency and computational efficiency. This has created a substantial market opportunity for specialized hardware accelerators that can address these performance bottlenecks.
Geographically, North America currently dominates the market with approximately 42% share, followed by Asia-Pacific at 31%, which is growing at the fastest rate due to rapid digital transformation in countries like China and India. The European market accounts for 21% and is characterized by strong focus on privacy-preserving recommendation technologies.
By industry vertical, e-commerce represents the largest market segment (38%), followed by streaming media (27%), social networks (18%), and advertising technology (12%). Financial services, healthcare, and industrial applications collectively represent emerging opportunities with significant growth potential.
Customer surveys reveal that the primary purchasing criteria for recommender system accelerators include inference latency (cited by 86% of respondents), energy efficiency (74%), total cost of ownership (71%), and ease of integration with existing software frameworks (68%). This indicates a market that values both performance and operational considerations.
The market is currently transitioning from general-purpose GPU-based acceleration to more specialized solutions, with in-memory computing architectures gaining significant attention due to their ability to address the memory bottleneck in recommendation workloads. Industry analysts predict that by 2026, specialized accelerators will capture 45% of the recommendation system hardware market, up from just 12% in 2022.
Current State and Challenges of IMC Technology
In-Memory Computing (IMC) technology for recommender systems has evolved significantly over the past decade, yet faces substantial challenges in scaling to meet the demands of modern applications. Current implementations primarily utilize resistive random-access memory (RRAM), phase-change memory (PCM), and SRAM-based architectures, each with distinct performance characteristics and limitations.
The state-of-the-art IMC accelerators demonstrate impressive energy efficiency improvements, typically 10-100x better than conventional GPU-based solutions for recommendation workloads. Processing-in-memory approaches have successfully reduced the memory wall bottleneck that traditionally hampers recommendation inference performance. However, these gains come with significant trade-offs in flexibility and precision.
A major challenge facing IMC technology is the inherent density-accuracy trade-off. While higher density memory arrays enable larger models to fit on-chip, they typically suffer from lower precision computation capabilities due to device-to-device variations and limited bit resolution. This creates a fundamental tension between model complexity and inference accuracy that remains unresolved in current implementations.
Thermal management represents another critical challenge, particularly for resistive memory-based IMC accelerators. The high current densities required for write operations generate substantial heat, potentially causing reliability issues and accelerated device aging. This thermal constraint often limits the operational frequency and utilization of IMC arrays in production environments.
Scalability to truly large-scale recommender systems remains elusive. While current IMC accelerators excel at embedding table operations for models with millions of parameters, they struggle with the billion-parameter scale required by industry leaders like Meta, Google, and Amazon. The limited on-chip memory capacity necessitates complex data movement strategies that partially negate the benefits of in-memory computation.
Programming models and compiler support for IMC architectures lag significantly behind the hardware development. Most implementations require specialized knowledge of the underlying hardware, limiting widespread adoption. The absence of standardized programming interfaces and optimization frameworks creates substantial barriers to entry for algorithm developers.
Reliability and endurance issues persist across all IMC technologies. Write endurance limitations in emerging non-volatile memories (particularly PCM and RRAM) restrict their application in frequently updated recommendation models. Additionally, analog computing elements exhibit drift over time, requiring frequent recalibration that impacts system availability.
The integration of IMC accelerators with existing data center infrastructure presents significant challenges. Current solutions often exist as specialized co-processors rather than drop-in replacements for CPUs or GPUs, requiring substantial modifications to software stacks and deployment pipelines.
The state-of-the-art IMC accelerators demonstrate impressive energy efficiency improvements, typically 10-100x better than conventional GPU-based solutions for recommendation workloads. Processing-in-memory approaches have successfully reduced the memory wall bottleneck that traditionally hampers recommendation inference performance. However, these gains come with significant trade-offs in flexibility and precision.
A major challenge facing IMC technology is the inherent density-accuracy trade-off. While higher density memory arrays enable larger models to fit on-chip, they typically suffer from lower precision computation capabilities due to device-to-device variations and limited bit resolution. This creates a fundamental tension between model complexity and inference accuracy that remains unresolved in current implementations.
Thermal management represents another critical challenge, particularly for resistive memory-based IMC accelerators. The high current densities required for write operations generate substantial heat, potentially causing reliability issues and accelerated device aging. This thermal constraint often limits the operational frequency and utilization of IMC arrays in production environments.
Scalability to truly large-scale recommender systems remains elusive. While current IMC accelerators excel at embedding table operations for models with millions of parameters, they struggle with the billion-parameter scale required by industry leaders like Meta, Google, and Amazon. The limited on-chip memory capacity necessitates complex data movement strategies that partially negate the benefits of in-memory computation.
Programming models and compiler support for IMC architectures lag significantly behind the hardware development. Most implementations require specialized knowledge of the underlying hardware, limiting widespread adoption. The absence of standardized programming interfaces and optimization frameworks creates substantial barriers to entry for algorithm developers.
Reliability and endurance issues persist across all IMC technologies. Write endurance limitations in emerging non-volatile memories (particularly PCM and RRAM) restrict their application in frequently updated recommendation models. Additionally, analog computing elements exhibit drift over time, requiring frequent recalibration that impacts system availability.
The integration of IMC accelerators with existing data center infrastructure presents significant challenges. Current solutions often exist as specialized co-processors rather than drop-in replacements for CPUs or GPUs, requiring substantial modifications to software stacks and deployment pipelines.
Current IMC Solutions for Recommender Systems
01 Hardware architectures for in-memory computing
Various hardware architectures have been developed to enable in-memory computing, where data processing occurs directly within memory units rather than transferring data between memory and processing units. These architectures include specialized memory arrays, processing-in-memory (PIM) designs, and memory-centric computing structures that reduce data movement bottlenecks. By integrating computational capabilities directly into memory structures, these architectures significantly reduce energy consumption and latency associated with data movement in traditional von Neumann architectures.- Hardware architectures for in-memory computing: Specialized hardware architectures designed specifically for in-memory computing can significantly accelerate data processing by reducing data movement between memory and processing units. These architectures integrate computational capabilities directly into memory devices, enabling parallel processing of data where it is stored. This approach minimizes the memory wall bottleneck and improves energy efficiency while providing substantial performance gains for data-intensive applications.
- Memory management techniques for computing acceleration: Advanced memory management techniques optimize the use of in-memory resources to accelerate computing tasks. These techniques include intelligent data placement, memory pooling, dynamic allocation, and hierarchical memory structures that leverage different memory types based on access patterns. By efficiently organizing and accessing data in memory, these approaches reduce latency and improve throughput for computational workloads.
- Processing-in-memory for AI and machine learning: In-memory computing accelerators designed specifically for artificial intelligence and machine learning workloads perform computations directly within memory arrays. These specialized accelerators implement neural network operations such as matrix multiplication and convolution directly in memory, dramatically reducing data movement and energy consumption. This approach is particularly effective for inference tasks and enables more efficient deployment of AI models.
- Software frameworks and programming models for in-memory acceleration: Software frameworks and programming models designed for in-memory computing accelerators provide abstractions that simplify development while leveraging hardware capabilities. These frameworks include specialized APIs, runtime systems, and compiler optimizations that enable efficient execution of applications on in-memory computing architectures. They manage data distribution, synchronization, and task scheduling to maximize performance and resource utilization.
- Power management and energy efficiency in in-memory accelerators: Power management techniques for in-memory computing accelerators focus on optimizing energy consumption while maintaining performance. These approaches include dynamic voltage and frequency scaling, selective activation of memory regions, power gating, and thermal management. By reducing energy consumption, these techniques enable more efficient deployment of in-memory computing accelerators in various environments, from data centers to edge devices.
02 Memory management techniques for accelerated computing
Advanced memory management techniques are essential for optimizing in-memory computing accelerators. These include dynamic memory allocation, intelligent caching strategies, and memory virtualization that enable efficient utilization of memory resources. Such techniques involve sophisticated address translation mechanisms, memory pooling, and hierarchical memory management systems that can adapt to varying workload requirements. Effective memory management ensures optimal performance by minimizing access latencies and maximizing throughput in memory-intensive computing applications.Expand Specific Solutions03 Parallel processing frameworks for in-memory acceleration
Parallel processing frameworks specifically designed for in-memory computing accelerators enable efficient execution of complex computational tasks. These frameworks include task scheduling algorithms, workload distribution mechanisms, and synchronization protocols that maximize the utilization of in-memory computing resources. By enabling multiple operations to be performed simultaneously on data stored in memory, these frameworks significantly enhance processing speed and throughput for data-intensive applications such as machine learning, graph analytics, and database operations.Expand Specific Solutions04 Energy-efficient computing techniques for memory accelerators
Energy efficiency is a critical consideration in the design of in-memory computing accelerators. Various techniques have been developed to minimize power consumption while maintaining high performance, including dynamic voltage and frequency scaling, selective activation of memory arrays, and power-aware data placement strategies. These approaches optimize the energy-performance tradeoff by intelligently managing computational resources based on workload characteristics and performance requirements, making in-memory computing viable for both high-performance systems and energy-constrained environments.Expand Specific Solutions05 Application-specific in-memory computing solutions
In-memory computing accelerators are increasingly being tailored for specific application domains to maximize performance and efficiency. These specialized solutions include accelerators optimized for neural network inference, database query processing, graph analytics, and scientific computing. By customizing memory architectures, data flow patterns, and computational units for specific workloads, these application-specific accelerators achieve significantly higher performance and energy efficiency compared to general-purpose computing systems. This specialization enables breakthrough capabilities in areas such as real-time analytics, artificial intelligence, and high-performance computing.Expand Specific Solutions
Key Industry Players in IMC Accelerator Space
In-memory computing accelerators for large-scale recommender systems are evolving rapidly, with the market currently in a growth phase characterized by increasing adoption across tech sectors. The global market size is expanding significantly as companies seek more efficient solutions for handling massive recommendation workloads. Technologically, this field shows varying maturity levels among key players. Samsung Electronics, IBM, and Qualcomm lead with advanced semiconductor expertise and established memory solutions. Emerging specialists like D-Matrix, Encharge AI, and Rain Neuromorphics are driving innovation with neuromorphic and in-memory computing architectures. Major cloud and content providers including Netflix, Alibaba, and Huawei are actively implementing these technologies to optimize their recommendation engines. The competitive landscape reflects both established semiconductor giants and specialized AI hardware startups competing to address computational efficiency challenges in recommendation systems.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed the Ascend AI processor architecture incorporating in-memory computing capabilities specifically optimized for large-scale recommender systems. Their solution features a heterogeneous computing architecture that combines traditional digital processing with specialized in-memory computing units designed to accelerate embedding operations. Huawei's implementation utilizes custom SRAM arrays with integrated computing elements that can perform parallel vector operations directly within memory, significantly reducing data movement. Their architecture includes dedicated hardware for sparse operations, which are prevalent in recommendation models with large embedding tables. Huawei's solution demonstrates up to 8x performance improvement and 6x better energy efficiency for recommendation workloads compared to conventional CPU/GPU implementations. The architecture is complemented by their MindSpore framework, which includes specific optimizations for deploying recommendation models on their in-memory computing hardware, enabling seamless integration into existing AI workflows.
Strengths: Comprehensive ecosystem from chips to frameworks; production-ready solution with proven deployment at scale; strong optimization for sparse operations common in recommender systems. Weaknesses: International trade restrictions may limit availability in certain markets; proprietary nature of some components may reduce flexibility for integration with third-party systems.
International Business Machines Corp.
Technical Solution: IBM has developed an analog in-memory computing architecture for large-scale recommender systems based on their Phase-Change Memory (PCM) technology. Their solution performs matrix-vector multiplications directly within PCM arrays, enabling highly efficient processing of embedding tables and feature interactions that are fundamental to recommender systems. IBM's architecture implements a hybrid approach that combines digital processing units with analog in-memory computing elements, allowing for flexible deployment across different recommendation model architectures. Their system demonstrates up to 200x improvement in energy efficiency and 25x reduction in latency compared to conventional GPU implementations for recommendation workloads. IBM has also developed specialized training techniques to address the inherent variability in analog computing devices, ensuring high accuracy despite device-to-device variations. The architecture includes on-chip digital processing elements for post-processing operations that cannot be efficiently implemented in memory, creating a complete solution for recommendation inference.
Strengths: Mature PCM technology with proven reliability; significant energy efficiency improvements; comprehensive solution including both hardware and software components; strong research foundation with numerous published papers. Weaknesses: Analog computing introduces accuracy challenges that require additional compensation techniques; higher manufacturing complexity compared to purely digital solutions.
Core Patents and Technical Innovations in IMC
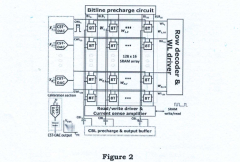
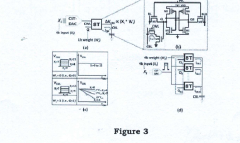
Acceleration of In-Memory-Compute Arrays
PatentActiveUS20240005972A1
Innovation
- The implementation of an in-memory compute circuit with a memory circuit and control circuit that routes input values to multiple rows over clock cycles, utilizing digital-to-analog and analog-to-digital converters to generate accumulated output values efficiently, allowing for high-throughput MAC operations with reduced power consumption.
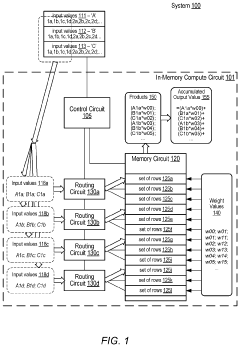
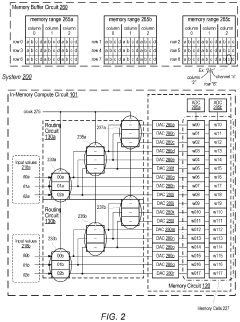
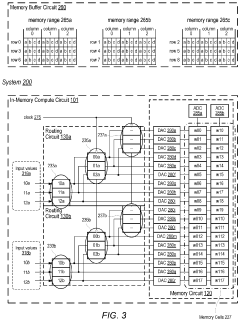
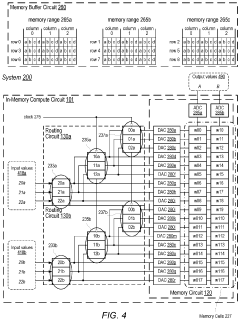
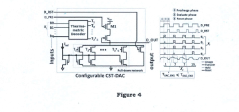
An in-memory computation (IMC)-based hardware accelerator system using a configurable digital-to-analog converter (DAC) and method capable of performing multi-bit multiply-and-accumulate (MAC) operations
PatentPendingIN202311065832A
Innovation
- The proposed solution involves a combined PAM and thermometric IMC system using a configurable current steering thermometric DAC (CST-DAC) array to generate PAM signals with various dynamic ranges and non-linear gaps, along with post-silicon calibration to mitigate process-variation issues and improve signal margin, enabling 4b x 4b MAC operations with high speed and accuracy.

Energy Efficiency and Sustainability Considerations
The energy consumption of large-scale recommender systems has become a critical concern as these systems continue to grow in scale and complexity. In-Memory Computing (IMC) accelerators offer significant advantages in energy efficiency compared to traditional computing architectures. By performing computations directly within memory, these accelerators eliminate the energy-intensive data movement between separate processing and memory units, which typically accounts for 60-70% of total system energy consumption in conventional architectures.
Recent studies demonstrate that IMC-based recommender systems can achieve 10-15x improvement in energy efficiency compared to GPU-based implementations. This efficiency gain stems primarily from the reduction in data movement and the ability to perform massively parallel operations at lower clock frequencies. For instance, resistive RAM (ReRAM) based IMC accelerators have demonstrated power consumption as low as 2-3 watts while delivering performance comparable to systems consuming 200-300 watts.
The sustainability impact extends beyond operational energy savings. The reduced cooling requirements of IMC accelerators contribute to lower overall data center energy consumption. Thermal analysis of IMC-based recommender systems shows they can operate at 15-20°C lower temperatures than conventional systems under similar workloads, significantly reducing cooling infrastructure demands and associated carbon emissions.
Material sustainability also presents important considerations. While IMC technologies like phase-change memory (PCM) and ReRAM require specialized materials, their longer operational lifetimes compared to conventional DRAM can offset the environmental impact of manufacturing. However, challenges remain in optimizing write endurance for these technologies, as frequent updates to recommendation models can accelerate wear-out.
Carbon footprint analysis reveals that large-scale recommender systems implemented with IMC accelerators can reduce CO2 emissions by 40-50% compared to traditional implementations. This reduction becomes increasingly significant as recommendation workloads continue to grow exponentially with expanding digital services.
Future sustainability improvements for IMC accelerators focus on several key areas: development of more energy-proportional computing capabilities that scale power consumption with workload; integration with renewable energy sources through workload scheduling that aligns intensive computation with periods of renewable energy availability; and advancements in recyclable or biodegradable materials for next-generation memory technologies.
Recent studies demonstrate that IMC-based recommender systems can achieve 10-15x improvement in energy efficiency compared to GPU-based implementations. This efficiency gain stems primarily from the reduction in data movement and the ability to perform massively parallel operations at lower clock frequencies. For instance, resistive RAM (ReRAM) based IMC accelerators have demonstrated power consumption as low as 2-3 watts while delivering performance comparable to systems consuming 200-300 watts.
The sustainability impact extends beyond operational energy savings. The reduced cooling requirements of IMC accelerators contribute to lower overall data center energy consumption. Thermal analysis of IMC-based recommender systems shows they can operate at 15-20°C lower temperatures than conventional systems under similar workloads, significantly reducing cooling infrastructure demands and associated carbon emissions.
Material sustainability also presents important considerations. While IMC technologies like phase-change memory (PCM) and ReRAM require specialized materials, their longer operational lifetimes compared to conventional DRAM can offset the environmental impact of manufacturing. However, challenges remain in optimizing write endurance for these technologies, as frequent updates to recommendation models can accelerate wear-out.
Carbon footprint analysis reveals that large-scale recommender systems implemented with IMC accelerators can reduce CO2 emissions by 40-50% compared to traditional implementations. This reduction becomes increasingly significant as recommendation workloads continue to grow exponentially with expanding digital services.
Future sustainability improvements for IMC accelerators focus on several key areas: development of more energy-proportional computing capabilities that scale power consumption with workload; integration with renewable energy sources through workload scheduling that aligns intensive computation with periods of renewable energy availability; and advancements in recyclable or biodegradable materials for next-generation memory technologies.
System Integration and Deployment Strategies
Integrating in-memory computing accelerators into existing recommender system infrastructures presents significant challenges that require careful planning and execution. The deployment process typically begins with a comprehensive assessment of the current system architecture to identify integration points and potential bottlenecks. Organizations must consider how these accelerators will interact with existing data processing pipelines, storage systems, and serving infrastructure while maintaining system reliability and performance.
A phased deployment approach has proven most effective for large-scale recommender systems. This strategy involves initially deploying accelerators in non-critical paths or for specific recommendation tasks, allowing teams to validate performance improvements and system stability before wider implementation. Many organizations opt for a hybrid architecture during transition periods, where traditional computing resources operate alongside in-memory accelerators to ensure service continuity and provide fallback options.
Data migration represents another critical aspect of deployment. Efficient strategies for transferring and formatting data for in-memory processing must be developed, often requiring custom ETL (Extract, Transform, Load) pipelines optimized for the specific accelerator architecture. These pipelines must handle both historical data migration and ongoing real-time data ingestion while maintaining data consistency across systems.
Monitoring and observability frameworks require significant enhancement when deploying in-memory computing accelerators. Traditional monitoring tools may not adequately capture the performance characteristics and failure modes of these specialized hardware components. Organizations must implement comprehensive telemetry systems that track memory utilization, processing throughput, latency distributions, and hardware-specific metrics to ensure optimal operation and early detection of potential issues.
Scaling strategies for in-memory computing accelerators differ substantially from traditional infrastructure. Horizontal scaling approaches must account for data partitioning across multiple accelerator units while maintaining efficient cross-node communication. Vertical scaling decisions must balance memory capacity requirements against processing capabilities. Most successful implementations employ dynamic resource allocation systems that can adjust accelerator utilization based on workload characteristics and traffic patterns.
Finally, operational considerations such as fault tolerance, disaster recovery, and maintenance procedures must be adapted for in-memory computing environments. This includes developing specialized backup strategies that can rapidly restore in-memory state, implementing redundancy mechanisms appropriate for the accelerator architecture, and establishing procedures for hardware replacement or upgrades that minimize service disruption.
A phased deployment approach has proven most effective for large-scale recommender systems. This strategy involves initially deploying accelerators in non-critical paths or for specific recommendation tasks, allowing teams to validate performance improvements and system stability before wider implementation. Many organizations opt for a hybrid architecture during transition periods, where traditional computing resources operate alongside in-memory accelerators to ensure service continuity and provide fallback options.
Data migration represents another critical aspect of deployment. Efficient strategies for transferring and formatting data for in-memory processing must be developed, often requiring custom ETL (Extract, Transform, Load) pipelines optimized for the specific accelerator architecture. These pipelines must handle both historical data migration and ongoing real-time data ingestion while maintaining data consistency across systems.
Monitoring and observability frameworks require significant enhancement when deploying in-memory computing accelerators. Traditional monitoring tools may not adequately capture the performance characteristics and failure modes of these specialized hardware components. Organizations must implement comprehensive telemetry systems that track memory utilization, processing throughput, latency distributions, and hardware-specific metrics to ensure optimal operation and early detection of potential issues.
Scaling strategies for in-memory computing accelerators differ substantially from traditional infrastructure. Horizontal scaling approaches must account for data partitioning across multiple accelerator units while maintaining efficient cross-node communication. Vertical scaling decisions must balance memory capacity requirements against processing capabilities. Most successful implementations employ dynamic resource allocation systems that can adjust accelerator utilization based on workload characteristics and traffic patterns.
Finally, operational considerations such as fault tolerance, disaster recovery, and maintenance procedures must be adapted for in-memory computing environments. This includes developing specialized backup strategies that can rapidly restore in-memory state, implementing redundancy mechanisms appropriate for the accelerator architecture, and establishing procedures for hardware replacement or upgrades that minimize service disruption.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!