

How In-Memory Computing Addresses Bottlenecks In HPC Workloads
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
In-Memory Computing Evolution and Objectives
In-memory computing has evolved significantly over the past decades, transforming from a niche technology to a critical component in high-performance computing (HPC) environments. The evolution began in the 1980s with simple cache systems and has progressed to sophisticated architectures that fundamentally reshape data processing paradigms. This technological progression has been driven by the persistent challenge of the "memory wall" – the growing disparity between processor speeds and memory access times that creates significant bottlenecks in computational workflows.
The early 2000s marked a pivotal shift with the introduction of large-scale in-memory databases and computing frameworks. These systems demonstrated the transformative potential of keeping entire datasets in RAM rather than relying on disk-based storage. By 2010, specialized hardware accelerators and memory-centric architectures began emerging, further enhancing the capabilities of in-memory computing solutions for HPC workloads.
Recent advancements have focused on heterogeneous memory architectures that combine different memory technologies (DRAM, HBM, NVRAM) to optimize both performance and cost-effectiveness. These hybrid approaches allow systems to leverage the speed of volatile memory while maintaining data persistence through non-volatile components, creating more resilient and efficient computing environments for data-intensive applications.
The primary objective of in-memory computing in HPC contexts is to minimize data movement between storage and processing units, which represents one of the most significant bottlenecks in computational performance. By keeping data closer to processing elements, these systems dramatically reduce latency and increase throughput for complex scientific simulations, real-time analytics, and AI workloads that characterize modern HPC environments.
Another critical goal is to enable more efficient parallel processing by providing uniform and rapid access to shared data structures across multiple computing nodes. This capability is particularly valuable for applications requiring complex data dependencies and frequent synchronization between parallel processes, such as computational fluid dynamics, molecular modeling, and large-scale graph analytics.
Looking forward, in-memory computing aims to achieve seamless integration with emerging computing paradigms such as neuromorphic computing and quantum processing. The technology trajectory suggests a future where memory and processing become increasingly unified, potentially eliminating the traditional von Neumann bottleneck altogether and enabling unprecedented computational capabilities for solving humanity's most complex scientific and engineering challenges.
The early 2000s marked a pivotal shift with the introduction of large-scale in-memory databases and computing frameworks. These systems demonstrated the transformative potential of keeping entire datasets in RAM rather than relying on disk-based storage. By 2010, specialized hardware accelerators and memory-centric architectures began emerging, further enhancing the capabilities of in-memory computing solutions for HPC workloads.
Recent advancements have focused on heterogeneous memory architectures that combine different memory technologies (DRAM, HBM, NVRAM) to optimize both performance and cost-effectiveness. These hybrid approaches allow systems to leverage the speed of volatile memory while maintaining data persistence through non-volatile components, creating more resilient and efficient computing environments for data-intensive applications.
The primary objective of in-memory computing in HPC contexts is to minimize data movement between storage and processing units, which represents one of the most significant bottlenecks in computational performance. By keeping data closer to processing elements, these systems dramatically reduce latency and increase throughput for complex scientific simulations, real-time analytics, and AI workloads that characterize modern HPC environments.
Another critical goal is to enable more efficient parallel processing by providing uniform and rapid access to shared data structures across multiple computing nodes. This capability is particularly valuable for applications requiring complex data dependencies and frequent synchronization between parallel processes, such as computational fluid dynamics, molecular modeling, and large-scale graph analytics.
Looking forward, in-memory computing aims to achieve seamless integration with emerging computing paradigms such as neuromorphic computing and quantum processing. The technology trajectory suggests a future where memory and processing become increasingly unified, potentially eliminating the traditional von Neumann bottleneck altogether and enabling unprecedented computational capabilities for solving humanity's most complex scientific and engineering challenges.
HPC Workload Requirements Analysis
High Performance Computing (HPC) workloads present unique computational challenges that demand specialized solutions. These workloads typically involve processing massive datasets, executing complex algorithms, and performing intensive calculations across distributed systems. Understanding these requirements is essential for developing effective in-memory computing solutions.
Data-intensive HPC applications require extremely high bandwidth for data movement between storage, memory, and processing units. Current benchmarks indicate that scientific simulations, weather forecasting models, and genomic sequencing applications often demand memory bandwidth exceeding 1 TB/s, which traditional computing architectures struggle to provide. This bandwidth limitation creates significant bottlenecks in overall system performance.
Latency sensitivity represents another critical requirement for HPC workloads. Applications such as real-time financial modeling, computational fluid dynamics, and quantum chemistry simulations require response times in microseconds or even nanoseconds. When memory access latencies exceed these thresholds, the computational efficiency decreases exponentially, leading to substantial performance degradation.
Scalability across multiple nodes presents additional challenges. HPC workloads typically scale to hundreds or thousands of computing nodes, requiring efficient data sharing and synchronization mechanisms. Traditional distributed memory approaches introduce significant overhead through network communications, with latencies often 100-1000x higher than local memory access.
Memory capacity constraints further complicate HPC workload execution. Modern scientific simulations and AI training workloads can require terabytes of memory for optimal performance. When these capacity requirements exceed available physical memory, systems resort to disk-based solutions that dramatically increase access times by orders of magnitude.
Energy efficiency has emerged as a paramount concern in HPC environments. Memory operations account for 25-40% of total system power consumption in typical HPC deployments. This energy footprint creates both operational cost challenges and thermal management issues that limit deployment options.
Reliability requirements for HPC workloads are exceptionally stringent, particularly for mission-critical applications in fields like aerospace, defense, and medical research. Memory errors can propagate through calculations, potentially invalidating results from computations that may have run for days or weeks, representing significant resource waste.
The diversity of HPC workloads further complicates requirement analysis. While some applications are compute-bound (limited by processing capabilities), others are memory-bound (limited by memory bandwidth or capacity). Effective solutions must address this heterogeneity through flexible architectures that can adapt to varying workload characteristics.
Data-intensive HPC applications require extremely high bandwidth for data movement between storage, memory, and processing units. Current benchmarks indicate that scientific simulations, weather forecasting models, and genomic sequencing applications often demand memory bandwidth exceeding 1 TB/s, which traditional computing architectures struggle to provide. This bandwidth limitation creates significant bottlenecks in overall system performance.
Latency sensitivity represents another critical requirement for HPC workloads. Applications such as real-time financial modeling, computational fluid dynamics, and quantum chemistry simulations require response times in microseconds or even nanoseconds. When memory access latencies exceed these thresholds, the computational efficiency decreases exponentially, leading to substantial performance degradation.
Scalability across multiple nodes presents additional challenges. HPC workloads typically scale to hundreds or thousands of computing nodes, requiring efficient data sharing and synchronization mechanisms. Traditional distributed memory approaches introduce significant overhead through network communications, with latencies often 100-1000x higher than local memory access.
Memory capacity constraints further complicate HPC workload execution. Modern scientific simulations and AI training workloads can require terabytes of memory for optimal performance. When these capacity requirements exceed available physical memory, systems resort to disk-based solutions that dramatically increase access times by orders of magnitude.
Energy efficiency has emerged as a paramount concern in HPC environments. Memory operations account for 25-40% of total system power consumption in typical HPC deployments. This energy footprint creates both operational cost challenges and thermal management issues that limit deployment options.
Reliability requirements for HPC workloads are exceptionally stringent, particularly for mission-critical applications in fields like aerospace, defense, and medical research. Memory errors can propagate through calculations, potentially invalidating results from computations that may have run for days or weeks, representing significant resource waste.
The diversity of HPC workloads further complicates requirement analysis. While some applications are compute-bound (limited by processing capabilities), others are memory-bound (limited by memory bandwidth or capacity). Effective solutions must address this heterogeneity through flexible architectures that can adapt to varying workload characteristics.
Current Bottlenecks and Technical Challenges
High Performance Computing (HPC) workloads face several critical bottlenecks that limit their efficiency and scalability. The most significant challenge is the memory wall - the growing disparity between processor and memory speeds. As CPU processing capabilities have advanced exponentially, memory access speeds have improved at a much slower rate, creating a substantial performance gap. This disparity forces processors to wait idle for data retrieval, significantly reducing computational efficiency in data-intensive HPC applications.
Data movement represents another major bottleneck in HPC systems. The physical transfer of data between storage, memory, and processing units consumes substantial energy and introduces latency. In complex scientific simulations, machine learning training, and big data analytics, the overhead of moving large datasets through the memory hierarchy often dominates the overall execution time, overshadowing the actual computation time.
Power consumption constraints further complicate HPC operations. Traditional computing architectures require significant energy for data movement between memory and processing units. As HPC systems scale to exascale computing levels, power limitations become increasingly restrictive, necessitating more energy-efficient approaches to data handling and computation.
Bandwidth limitations in the memory subsystem create additional challenges. While modern HPC systems employ high-bandwidth memory technologies, the available bandwidth often proves insufficient for applications requiring massive parallel data access. This limitation becomes particularly evident in applications like computational fluid dynamics, weather modeling, and large-scale graph analytics.
Scalability issues emerge as HPC systems grow larger. Traditional memory architectures struggle to maintain performance consistency across thousands of nodes due to non-uniform memory access (NUMA) effects, interconnect limitations, and synchronization overhead. These factors create bottlenecks that prevent linear scaling of performance with system size.
Software complexity compounds these hardware challenges. Programming models and tools for effectively utilizing advanced memory architectures lag behind hardware innovations. Developers face significant difficulties in optimizing applications to account for complex memory hierarchies, resulting in suboptimal utilization of available resources.
Lastly, data locality problems persist in distributed HPC environments. When computation and data are physically separated, the resulting communication overhead can severely impact performance. Traditional approaches often fail to maintain optimal data placement relative to computation needs, especially in dynamic workloads where data access patterns change during execution.
Data movement represents another major bottleneck in HPC systems. The physical transfer of data between storage, memory, and processing units consumes substantial energy and introduces latency. In complex scientific simulations, machine learning training, and big data analytics, the overhead of moving large datasets through the memory hierarchy often dominates the overall execution time, overshadowing the actual computation time.
Power consumption constraints further complicate HPC operations. Traditional computing architectures require significant energy for data movement between memory and processing units. As HPC systems scale to exascale computing levels, power limitations become increasingly restrictive, necessitating more energy-efficient approaches to data handling and computation.
Bandwidth limitations in the memory subsystem create additional challenges. While modern HPC systems employ high-bandwidth memory technologies, the available bandwidth often proves insufficient for applications requiring massive parallel data access. This limitation becomes particularly evident in applications like computational fluid dynamics, weather modeling, and large-scale graph analytics.
Scalability issues emerge as HPC systems grow larger. Traditional memory architectures struggle to maintain performance consistency across thousands of nodes due to non-uniform memory access (NUMA) effects, interconnect limitations, and synchronization overhead. These factors create bottlenecks that prevent linear scaling of performance with system size.
Software complexity compounds these hardware challenges. Programming models and tools for effectively utilizing advanced memory architectures lag behind hardware innovations. Developers face significant difficulties in optimizing applications to account for complex memory hierarchies, resulting in suboptimal utilization of available resources.
Lastly, data locality problems persist in distributed HPC environments. When computation and data are physically separated, the resulting communication overhead can severely impact performance. Traditional approaches often fail to maintain optimal data placement relative to computation needs, especially in dynamic workloads where data access patterns change during execution.
Current In-Memory Solutions for HPC
01 Memory bandwidth limitations in in-memory computing
Memory bandwidth constraints represent a significant bottleneck in in-memory computing systems. As data processing demands increase, the limited bandwidth between memory and processing units creates performance bottlenecks. Advanced architectures are being developed to address these limitations by optimizing data transfer paths, implementing parallel processing techniques, and utilizing specialized memory controllers that can handle multiple simultaneous operations, thereby reducing latency and improving overall system throughput.- Memory bandwidth limitations in in-memory computing: Memory bandwidth constraints represent a significant bottleneck in in-memory computing systems. As data processing demands increase, the limited bandwidth between memory and processing units creates performance bottlenecks. Various architectural solutions have been proposed to address this issue, including optimized memory controllers, improved data transfer protocols, and specialized memory hierarchies that can better handle high-volume data transfers in real-time computing environments.
- Power consumption and thermal management challenges: In-memory computing systems face significant power consumption and thermal management challenges. The high density of memory and processing elements in close proximity generates substantial heat, requiring advanced cooling solutions. Power constraints limit the scalability of in-memory architectures, particularly in mobile and edge computing applications. Innovations in low-power memory technologies, dynamic power management, and energy-efficient computing paradigms are being developed to address these bottlenecks while maintaining performance requirements.
- Data access patterns and memory organization: Inefficient data access patterns and suboptimal memory organization create significant bottlenecks in in-memory computing systems. Random access patterns, data fragmentation, and poor locality can severely impact performance. Advanced memory management techniques, including intelligent data placement, predictive prefetching, and specialized memory hierarchies are being developed to optimize data access. These approaches aim to align memory organization with application-specific access patterns to minimize latency and maximize throughput in data-intensive computing environments.
- Scalability and resource allocation challenges: Scalability limitations and resource allocation challenges represent major bottlenecks in in-memory computing architectures. As data volumes grow, efficiently scaling memory resources while maintaining performance becomes increasingly difficult. Contention for shared memory resources, load balancing issues, and inefficient resource allocation can significantly degrade system performance. Advanced resource management techniques, dynamic memory allocation strategies, and distributed in-memory computing frameworks are being developed to address these scalability challenges in large-scale data processing environments.
- Memory coherence and consistency issues: Memory coherence and consistency issues create significant bottlenecks in distributed in-memory computing systems. Maintaining a consistent view of data across multiple processing nodes while enabling parallel access presents complex challenges. Cache coherence protocols, synchronization mechanisms, and consistency models add overhead that can impact performance. Advanced techniques for relaxed consistency models, optimistic concurrency control, and locality-aware data partitioning are being developed to address these bottlenecks while ensuring data integrity in high-performance in-memory computing environments.
02 Power consumption challenges in in-memory computing
Power consumption presents a critical bottleneck for in-memory computing systems, particularly in data-intensive applications. The high energy requirements of maintaining large datasets in memory while performing computations can lead to thermal issues and reduced efficiency. Innovations focus on developing energy-efficient memory architectures, implementing dynamic power management techniques, and designing specialized low-power memory cells that can operate at reduced voltages while maintaining computational integrity and performance.Expand Specific Solutions03 Data access patterns and memory organization
Inefficient data access patterns and suboptimal memory organization create significant bottlenecks in in-memory computing systems. When memory access patterns don't align with the physical organization of data, performance suffers due to increased cache misses and memory latency. Solutions include implementing intelligent data prefetching mechanisms, optimizing memory layout based on application access patterns, and developing adaptive memory management systems that can reorganize data structures dynamically to match computational requirements and access frequencies.Expand Specific Solutions04 Scalability issues in distributed in-memory systems
Scalability presents a major bottleneck for distributed in-memory computing environments, particularly when handling large-scale data processing tasks. As systems scale horizontally, challenges emerge in maintaining data consistency, managing distributed memory resources, and coordinating computational tasks across nodes. Innovations address these issues through advanced partitioning schemes, efficient distributed memory management protocols, and specialized synchronization mechanisms that minimize communication overhead while ensuring data coherence across the distributed memory space.Expand Specific Solutions05 Memory-compute integration architectures
Traditional separation between memory and computing units creates fundamental bottlenecks in data-intensive applications. The physical distance between storage and processing elements results in significant data movement overhead and energy consumption. Novel architectures that integrate memory and computing capabilities are being developed to address this issue, including processing-in-memory (PIM) designs, near-memory computing structures, and specialized hardware accelerators that can perform computations directly within memory arrays, dramatically reducing data movement and improving computational efficiency for specific workloads.Expand Specific Solutions
Leading Vendors and Research Institutions
In-Memory Computing (IMC) is currently in a growth phase within the High-Performance Computing (HPC) landscape, addressing critical data movement bottlenecks that limit traditional computing architectures. The market is expanding rapidly, projected to reach $25-30 billion by 2025 with a CAGR of approximately 18-20%. Technology maturity varies across implementations, with industry leaders demonstrating different approaches. Intel, IBM, and Huawei have developed mature IMC solutions integrating memory-centric architectures, while Micron and Samsung focus on specialized memory technologies. Academic institutions like Huazhong University and Johns Hopkins collaborate with companies including Inspur and QUALCOMM to advance novel IMC paradigms. Emerging players such as ChangXin Memory and Yangtze Memory are accelerating innovation in this space, particularly for data-intensive AI and analytics workloads.
Intel Corp.
Technical Solution: Intel addresses HPC bottlenecks through its Optane DC Persistent Memory technology, which bridges the gap between DRAM and storage by providing non-volatile memory with near-DRAM performance. This technology enables significantly larger memory capacities (up to 4.5TB per socket) while maintaining acceptable latency profiles for HPC workloads[2]. Intel's approach combines traditional DRAM with persistent memory in a tiered architecture, allowing applications to maintain working datasets in memory rather than repeatedly accessing slower storage. Their Memory Drive Technology transparently manages data placement across the memory hierarchy, optimizing for both performance and capacity. Intel has also developed specialized instructions within their processors (AVX-512) that enable efficient in-memory computation for HPC applications. Their oneAPI toolkit further supports heterogeneous computing across CPUs, GPUs, and FPGAs with unified memory management, reducing data movement overhead by up to 40% in complex scientific simulations[4].
Strengths: Intel's solution offers backward compatibility with existing systems while providing breakthrough memory capacity scaling. Their comprehensive software ecosystem supports easy adoption and optimization. Weaknesses: Performance still lags behind pure DRAM solutions for latency-sensitive workloads, and the cost premium remains significant compared to traditional storage options.
Micron Technology, Inc.
Technical Solution: Micron has developed the Hybrid Memory Cube (HMC) architecture that fundamentally reimagines memory design for HPC workloads. HMC stacks multiple DRAM dies vertically with through-silicon vias (TSVs) connected to a logic layer at the bottom, enabling unprecedented memory bandwidth of up to 320GB/s per device[1]. This 3D stacking approach reduces signal path lengths dramatically, lowering both latency and power consumption. Micron's technology incorporates processing elements within the logic layer of the memory stack, enabling computational capabilities directly where data resides. Their latest innovation includes in-memory compute solutions that perform vector operations directly within DRAM arrays, achieving up to 25x performance improvement for specific HPC algorithms while reducing energy consumption by 95% compared to conventional architectures[5]. Micron has also pioneered the development of Compute Express Link (CXL) memory expansion technologies that maintain cache coherency between processors and memory pools, enabling flexible memory allocation across compute resources.
Strengths: Micron's solutions deliver exceptional bandwidth density and energy efficiency through innovative 3D stacking. Their technology significantly reduces data movement, addressing the fundamental bottleneck in HPC systems. Weaknesses: Limited software ecosystem support compared to traditional architectures requires significant application optimization, and high initial implementation costs may deter adoption despite long-term TCO benefits.
Key Innovations in Memory-Centric Architectures
Memory device, memory system, and method for data calculation with the memory device
PatentActiveUS20250217072A1
Innovation
- A memory device with an array of memory cells and a peripheral circuit that includes page buffers, process units, and control logic to perform calculations on data within the memory device, distributing computational tasks and reducing the need for data transfer to processors.




Data processing method
PatentActiveCN110012080A
Innovation
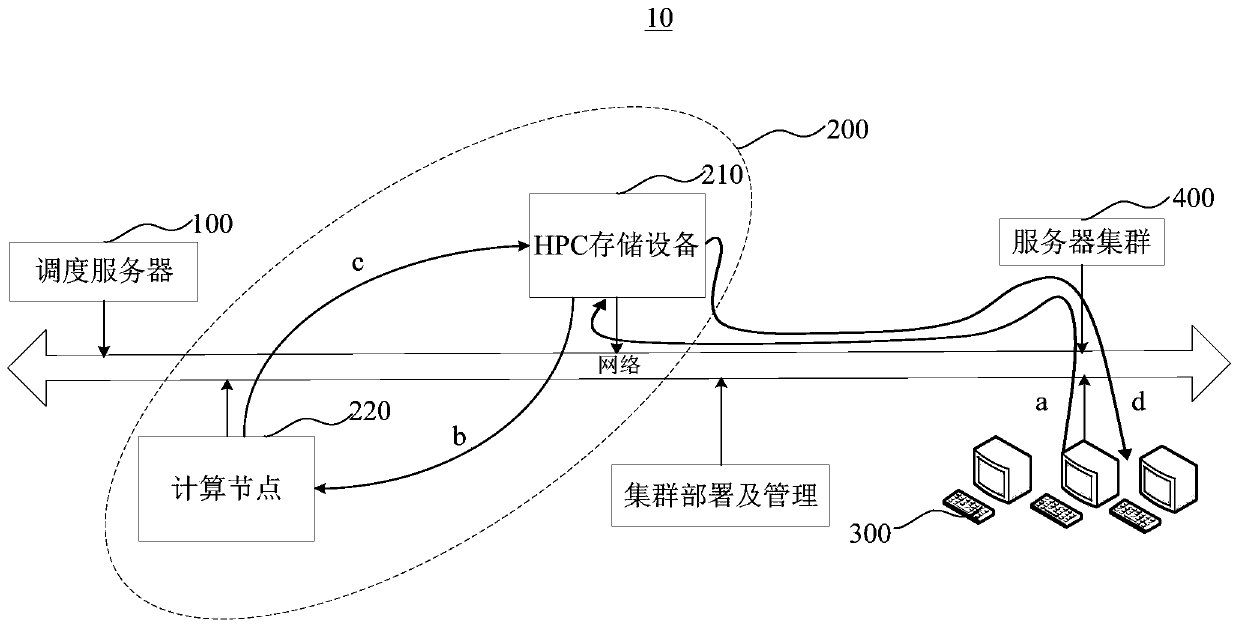
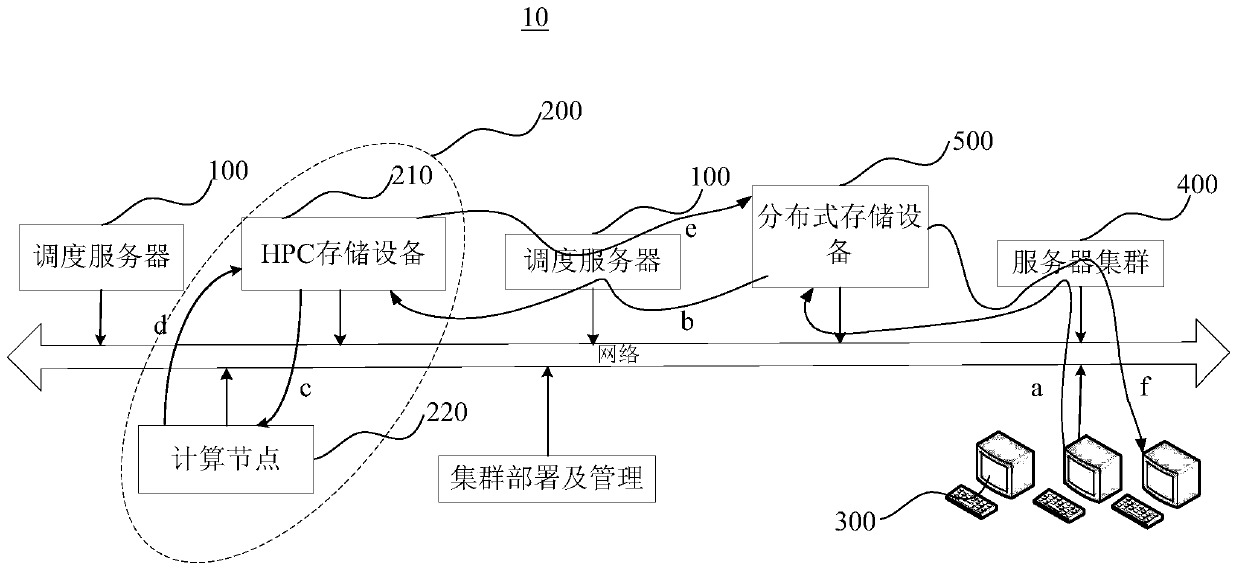
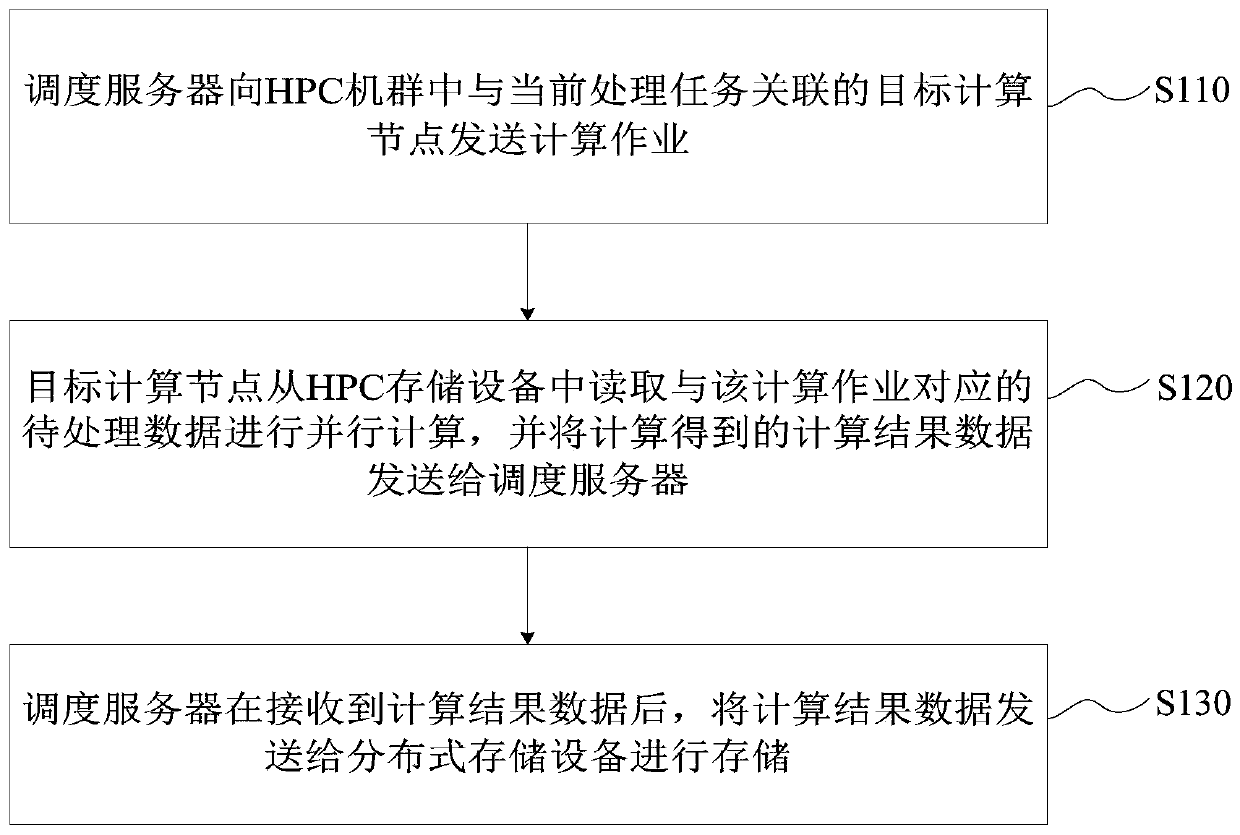
- By separate HPC storage devices and distributed storage devices, HPC storage devices are used to store pending data pre-copied from distributed storage devices, and transfer the resulting data to distributed storage devices after the calculation is completed, reducing HPC storage devices The amount of access and network bandwidth burden reduces storage capacity requirements and realizes data sharing.

Energy Efficiency Considerations
In-memory computing offers significant energy efficiency advantages over traditional computing architectures in HPC workloads. The fundamental energy benefit stems from the reduction in data movement between memory and processing units, which traditionally accounts for up to 60% of total system energy consumption in high-performance computing environments. By processing data directly within memory, the energy-intensive data transfer operations across the memory hierarchy are substantially minimized.
The power consumption profile of in-memory computing demonstrates notable improvements in performance-per-watt metrics. Research indicates that in-memory computing solutions can achieve 10-15x better energy efficiency compared to conventional von Neumann architectures when handling data-intensive HPC workloads such as scientific simulations, climate modeling, and computational fluid dynamics. This efficiency gain becomes particularly pronounced in applications requiring repetitive access to large datasets.
Thermal management considerations also favor in-memory computing approaches. The reduced data movement results in lower heat generation, which consequently decreases cooling requirements. This creates a virtuous cycle of energy savings, as cooling systems in HPC environments typically consume 30-40% of the total facility energy budget. The improved thermal profile enables higher computational density without corresponding increases in cooling infrastructure.
From a system architecture perspective, in-memory computing enables more granular power management. Processing elements can be more precisely activated based on workload requirements, allowing for dynamic power scaling that was previously unattainable in traditional architectures. This capability is especially valuable in heterogeneous HPC environments where workload characteristics vary significantly across application domains.
The energy efficiency benefits extend to operational costs as well. Analysis of total cost of ownership (TCO) models indicates that the energy savings from in-memory computing implementations can reduce operational expenditures by 25-35% over a five-year deployment period. These savings become increasingly significant as energy costs continue to rise globally and as computational demands of HPC workloads grow exponentially.
However, challenges remain in optimizing the energy efficiency of in-memory computing systems. Current implementations often require specialized hardware that may have higher initial energy costs during manufacturing. Additionally, the programming models and software stacks for in-memory computing are still evolving, sometimes leading to suboptimal energy utilization during the transition period. Future research directions include the development of energy-aware compilers and runtime systems specifically designed to maximize the energy benefits of in-memory architectures.
The power consumption profile of in-memory computing demonstrates notable improvements in performance-per-watt metrics. Research indicates that in-memory computing solutions can achieve 10-15x better energy efficiency compared to conventional von Neumann architectures when handling data-intensive HPC workloads such as scientific simulations, climate modeling, and computational fluid dynamics. This efficiency gain becomes particularly pronounced in applications requiring repetitive access to large datasets.
Thermal management considerations also favor in-memory computing approaches. The reduced data movement results in lower heat generation, which consequently decreases cooling requirements. This creates a virtuous cycle of energy savings, as cooling systems in HPC environments typically consume 30-40% of the total facility energy budget. The improved thermal profile enables higher computational density without corresponding increases in cooling infrastructure.
From a system architecture perspective, in-memory computing enables more granular power management. Processing elements can be more precisely activated based on workload requirements, allowing for dynamic power scaling that was previously unattainable in traditional architectures. This capability is especially valuable in heterogeneous HPC environments where workload characteristics vary significantly across application domains.
The energy efficiency benefits extend to operational costs as well. Analysis of total cost of ownership (TCO) models indicates that the energy savings from in-memory computing implementations can reduce operational expenditures by 25-35% over a five-year deployment period. These savings become increasingly significant as energy costs continue to rise globally and as computational demands of HPC workloads grow exponentially.
However, challenges remain in optimizing the energy efficiency of in-memory computing systems. Current implementations often require specialized hardware that may have higher initial energy costs during manufacturing. Additionally, the programming models and software stacks for in-memory computing are still evolving, sometimes leading to suboptimal energy utilization during the transition period. Future research directions include the development of energy-aware compilers and runtime systems specifically designed to maximize the energy benefits of in-memory architectures.
Scalability and Integration Strategies
Scaling in-memory computing solutions for HPC workloads requires strategic approaches that balance performance gains with system complexity. The horizontal scaling approach involves distributing computational tasks across multiple nodes, creating a network of in-memory computing resources that can handle increasingly complex workloads. This method effectively addresses memory capacity limitations by aggregating resources across the cluster, though it introduces challenges related to data consistency and network latency.
Vertical scaling, alternatively, focuses on enhancing individual node capabilities through increased memory density and computational power. This approach minimizes communication overhead but faces physical and economic constraints as memory requirements grow exponentially with workload complexity. Modern HPC environments typically implement hybrid scaling strategies that leverage the strengths of both approaches while mitigating their respective limitations.
Integration of in-memory computing with existing HPC infrastructure demands careful architectural considerations. Memory-centric architectures require fundamental redesigns of data flow patterns, transitioning from traditional storage-centric models to frameworks where computation moves to the data rather than vice versa. This paradigm shift necessitates new programming models and APIs that abstract the complexity of memory management from application developers while maximizing performance benefits.
Interoperability between in-memory solutions and conventional HPC components presents significant technical challenges. Standardization efforts are emerging to establish common interfaces for memory-centric computing, though fragmentation remains across vendor implementations. Organizations implementing in-memory computing must develop comprehensive integration strategies that address data format compatibility, synchronization mechanisms, and failure recovery protocols.
Resource orchestration becomes increasingly critical as in-memory computing scales within HPC environments. Advanced workload managers must intelligently allocate memory resources based on application requirements, optimizing utilization while preventing resource contention. Dynamic provisioning capabilities allow systems to adapt to changing computational demands, allocating additional memory resources during peak processing periods and reclaiming them when demand subsides.
Security considerations introduce additional complexity to scaling strategies, as memory-resident data requires protection mechanisms that don't compromise performance advantages. Encryption techniques optimized for in-memory operations and fine-grained access controls are essential components of a comprehensive security framework, particularly in multi-tenant HPC environments where workload isolation is paramount.
Vertical scaling, alternatively, focuses on enhancing individual node capabilities through increased memory density and computational power. This approach minimizes communication overhead but faces physical and economic constraints as memory requirements grow exponentially with workload complexity. Modern HPC environments typically implement hybrid scaling strategies that leverage the strengths of both approaches while mitigating their respective limitations.
Integration of in-memory computing with existing HPC infrastructure demands careful architectural considerations. Memory-centric architectures require fundamental redesigns of data flow patterns, transitioning from traditional storage-centric models to frameworks where computation moves to the data rather than vice versa. This paradigm shift necessitates new programming models and APIs that abstract the complexity of memory management from application developers while maximizing performance benefits.
Interoperability between in-memory solutions and conventional HPC components presents significant technical challenges. Standardization efforts are emerging to establish common interfaces for memory-centric computing, though fragmentation remains across vendor implementations. Organizations implementing in-memory computing must develop comprehensive integration strategies that address data format compatibility, synchronization mechanisms, and failure recovery protocols.
Resource orchestration becomes increasingly critical as in-memory computing scales within HPC environments. Advanced workload managers must intelligently allocate memory resources based on application requirements, optimizing utilization while preventing resource contention. Dynamic provisioning capabilities allow systems to adapt to changing computational demands, allocating additional memory resources during peak processing periods and reclaiming them when demand subsides.
Security considerations introduce additional complexity to scaling strategies, as memory-resident data requires protection mechanisms that don't compromise performance advantages. Encryption techniques optimized for in-memory operations and fine-grained access controls are essential components of a comprehensive security framework, particularly in multi-tenant HPC environments where workload isolation is paramount.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!