Directional web data extraction method
A technology of webpage data and data, which is applied in the field of network technology and search engines, can solve the problems of inability to provide directional capture of webpage data and limited application fields, and achieve the effect of simple operation, wide application range and strong operability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
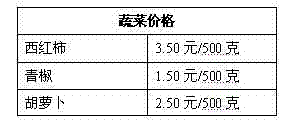
[0051] In order to provide users with vegetable price information services, the server that provides the corresponding services needs to target and grab vegetable price data from a professional price information website. The web pages contained in the price information website are in HTML (Hyper Text Markup Language) format; the URL (Uniform Resource Locator) address of the web page containing vegetable price information is "http: / / www .feinno.com / commodity-price / 016", the price of vegetables on this webpage is presented as a table structure as shown in Table 1:
[0052] Table 1
[0053]
[0054] In Table 1, the cell where the "vegetable price" is located is the header cell, and the other cells are data cells. Now, it is necessary to provide users with a special price quotation service for "green peppers". Therefore, the server needs to target the price data of green peppers from the webpage, ignoring other webpage data in the webpage; the method of the present invention is used f...
Embodiment 2
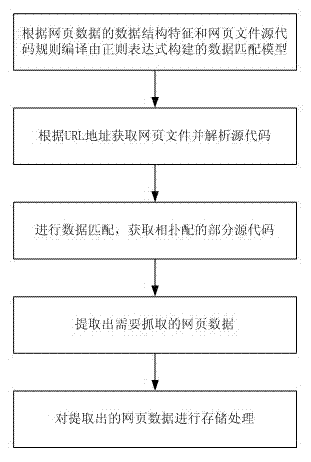
[0082] In order to provide users with vegetable price information services, the server that provides the corresponding services needs to grab vegetables from the webpage "http: / / www.feinno.com / commodity-price / 016" of the price information website described in Example 1. For price data, the presentation of vegetable prices on this webpage is shown in Table 1. Now it is necessary to provide users with the vegetable name data listed in this table and the corresponding price data of various vegetables. Therefore, the vegetable names on the webpage are "tomato", "green pepper", "carrot" and the corresponding vegetable price "3.50 yuan / 500 grams", "2.50 yuan / 500 grams", and "1.50 yuan / 500 grams" are the webpage data to be crawled; the method of the present invention is used for targeted crawling, and the flow chart is as follows figure 1 As shown, the specific method is as follows:
[0083] i) According to the data structure characteristics of the web page data to be captured in the w...
Embodiment 3
[0117] In the price information website, the content of the page whose URL address is "http: / / www.feinno.com / commodity-price / 016" has changed. The page not only provides the vegetable price information shown in Table 1, but also Another grain price information table with exactly the same structure as the table in Table 1, as shown in Table 4:
[0118] Table 4
[0119]
[0120] The vegetable name data listed in the vegetable price information table (shown in Table 1) and the corresponding price data of various vegetables are still provided to users. The vegetable name data "tomato", "green pepper", "Carrot" and the corresponding vegetable price data of the three are "3.50 yuan / 500g", "2.50 yuan / 500g", and "1.50 yuan / 500g".
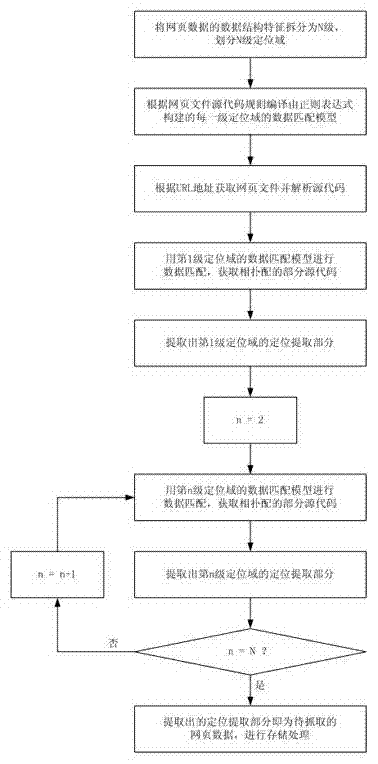
[0121] According to the table structure characteristics and HTML source code syntax rules in Table 1, it can be determined that the source code of the vegetable name data and vegetable price data to be crawled in the web file should at least contain the table tag...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More