

System and method for recognizing content posts of webpage
A web page and text technology, applied in the Internet field, can solve problems such as poor handling of multiple "floor" content, and achieve the effect of excellent reading experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
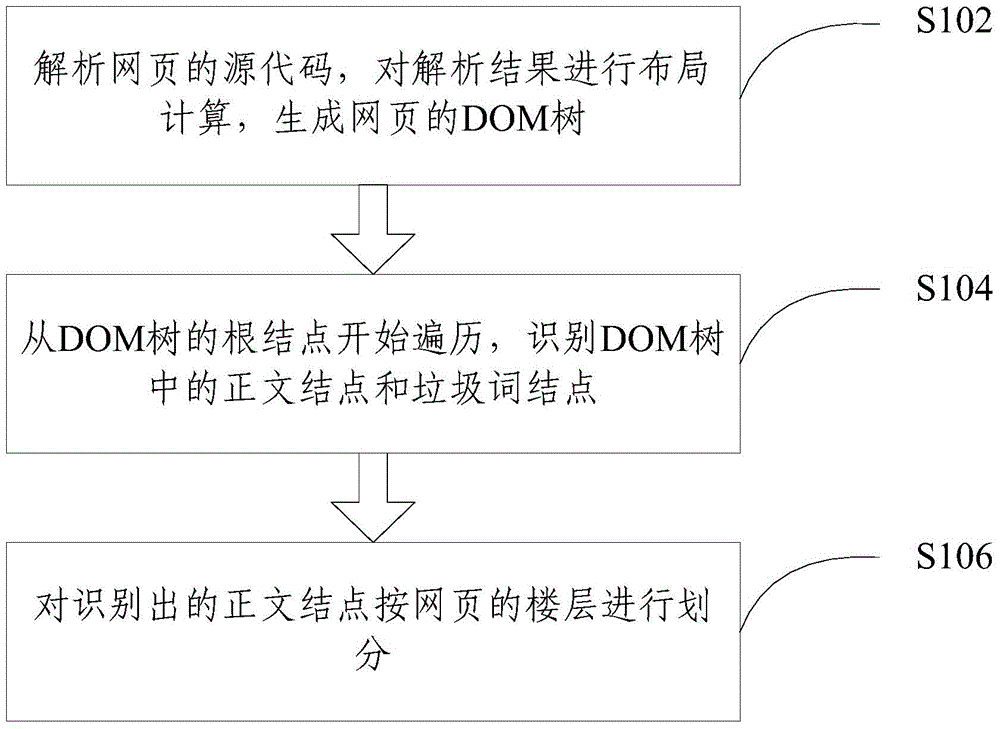
[0069] The specific embodiments of the present invention will be described in further detail below with reference to the accompanying drawings and embodiments. The following examples are suitable to illustrate the present invention, but are not intended to limit the scope of the present invention.
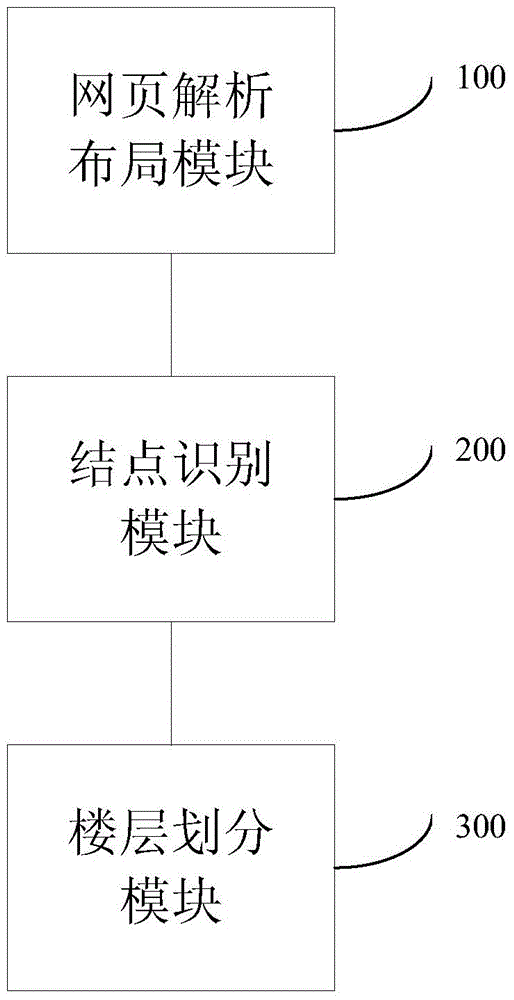
[0070] The structure diagram of the system provided by the present invention is as follows: figure 1 shown.
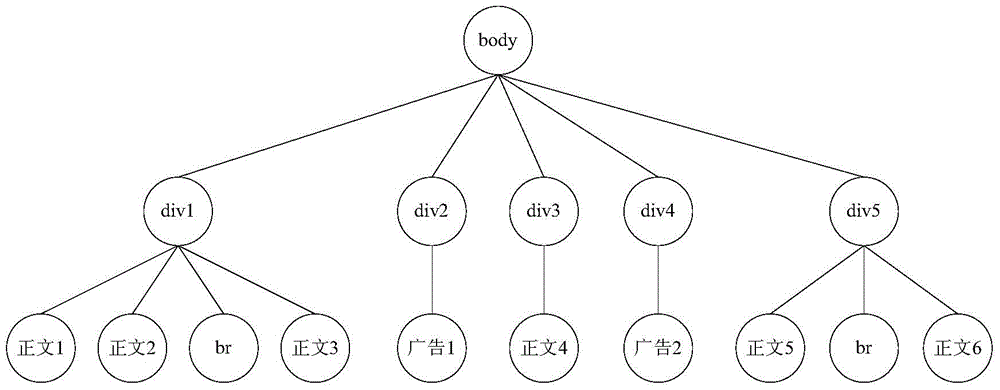
[0071] The webpage parsing and layout module 100 parses and calculates the layout of the webpage source code. The HTML parsing engine is used when parsing the HTML source code and layout. Commonly used open source HTML parsing engines such as webkit. The parsing and layout are based on the tags in the source code of the web page, but not limited to the div tag, to generate the DOM tree of the web page, and calculate the position and height of each node displayed when the web page is displayed. A DOM tree is generated such as image 3 shown.
[0072] Since it is difficult...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More