

System and method for automatically acquiring webpage data
A technology for web page data and specified data, which is applied in network data retrieval, network data indexing, digital data authentication, etc. It can solve the problems of inability to accurately collect and process data, and achieve customization of collected content and realization of customization. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
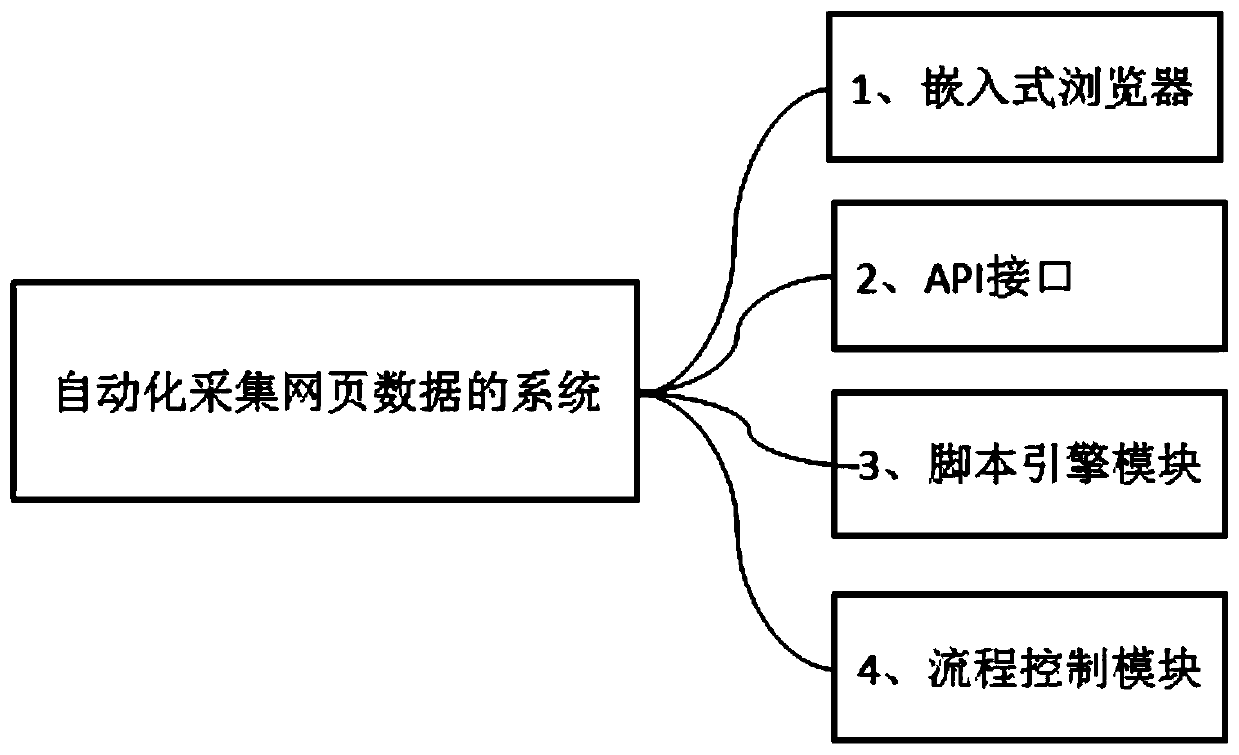
[0024] Example 1: Please see figure 1 , figure 1 This is a structural diagram of a system for automatically collecting webpage data according to Embodiment 1 of the present invention. The system for automatically collecting webpage data according to Embodiment 1 of the present invention includes an embedded browser 1, an API interface 2, a script engine module 3, and The process control module 4, the API interface 2, the script engine module 3, and the process control module 4 are respectively embedded in the embedded browser 1. The system for automatically collecting webpage data of the present invention combines the script engine module 3 and the process control module 4 to jointly realize the access to the specified webpage and the specified data collection.
[0025] Preferably, the script engine module 3 is used to load a JS script; the JS script contains a custom JS function for operating a webpage, and the execution of the webpage requires the interpretation and execution of...
Embodiment 2
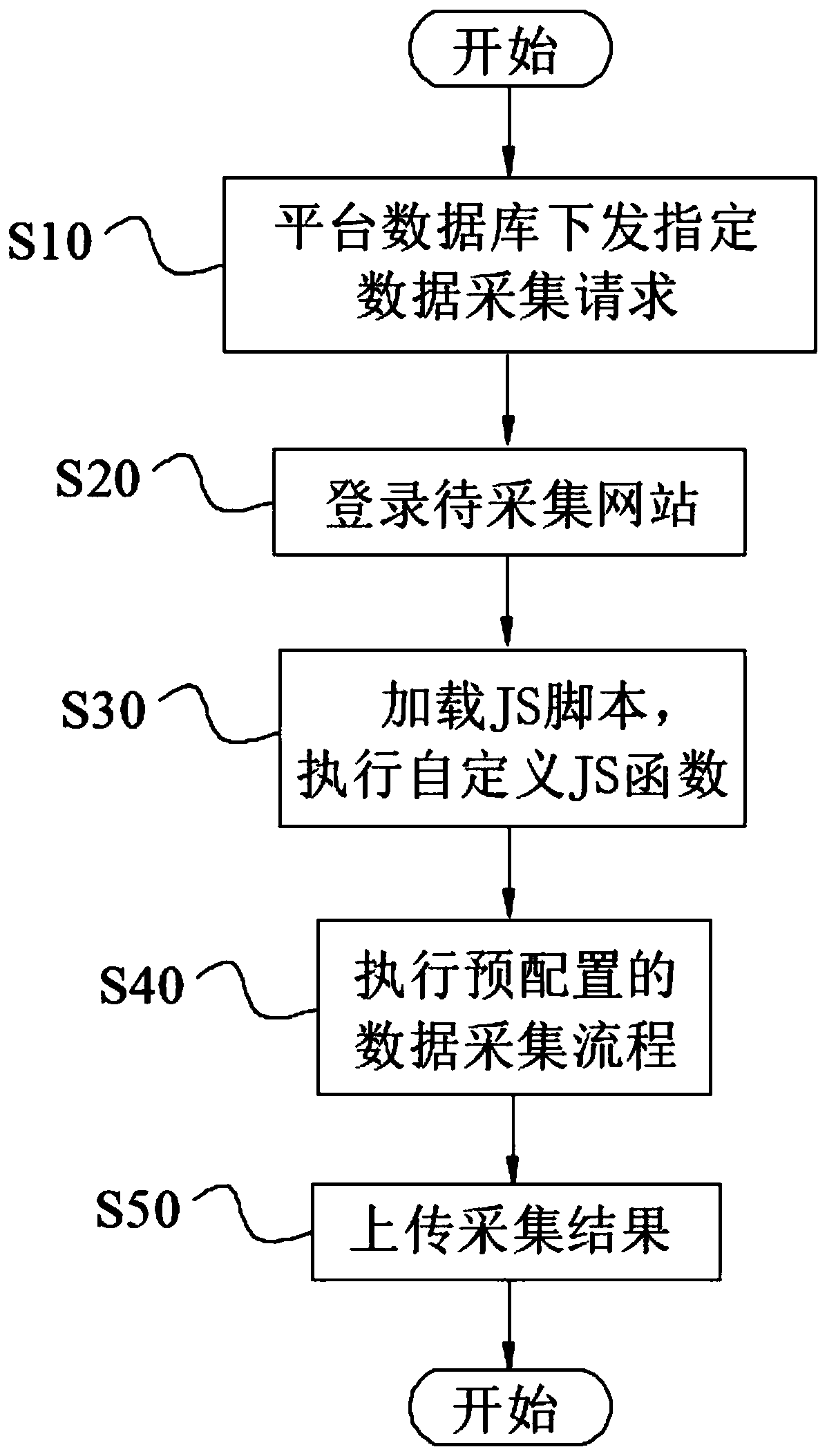
[0028] Embodiment 2: According to another aspect of the present invention, a method for automatically collecting webpage data is also provided, please refer to figure 2 , figure 2 This is a flowchart of a method for automatically collecting webpage data according to Embodiment 1 of the present invention. The method for automatically collecting webpage data according to Embodiment 1 of the present invention includes the following steps:
[0029] Step S10: the platform database issues a designated data collection request;
[0030] Step S20: Log in to the website to be collected: the embedded browser 1 receives the specified data collection request and visits the specified website to be collected, receives the page load event after the visit is successful, and obtains the memory address after the page is loaded;
[0031] Step S30: Load the JS script: the script engine module 3 loads the JS script for the current page, and executes the custom JS function in the memory address of the c...
Embodiment 3
[0035] Embodiment 3: The system and method for automatically collecting webpage data of the present invention has a wide range of application scenarios. For example, it can be applied to collect webpage data of taxation websites, provide customers with intelligent fiscal and taxation services, and use account information provided by customers to log in to the tax bureau website to collect relevant information. To obtain the basic information and financial information of customers on the taxation website, provide data support for intelligent fiscal and taxation services, and provide customers with various value-added services such as automated tax filing and risk assessment.
[0036] Next, we have collected data from the tax website as an example to introduce the workflow of the application.
[0037] The first step: The embedded browser visits the tax website. After the visit is successful, the page loading event is received, and the memory address after the page is loaded is also ob...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More