

Machine Learning Model Training With In-Memory Computing Hardware Accelerators
SEP 2, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
In-Memory Computing for ML: Background and Objectives
In-memory computing (IMC) represents a paradigm shift in computer architecture that addresses the fundamental "memory wall" challenge that has plagued traditional von Neumann architectures for decades. This bottleneck, characterized by the significant disparity between processing speeds and memory access times, has become particularly problematic for machine learning workloads that require massive data transfers between memory and processing units. The evolution of IMC technology can be traced back to early research on resistive RAM and memristive systems in the early 2000s, with significant acceleration in development occurring over the past decade as machine learning applications have proliferated across industries.
The core principle of IMC involves performing computational operations directly within memory arrays, eliminating the need for constant data movement between separate processing and storage units. This approach offers theoretical advantages of reduced power consumption by up to 1000x and performance improvements of similar magnitude for specific workloads compared to conventional architectures. For machine learning applications specifically, matrix multiplication operations that form the computational backbone of neural network training can be executed with unprecedented efficiency using IMC hardware accelerators.
Current technological trajectories indicate a convergence of several complementary technologies that enable practical IMC implementations, including advances in non-volatile memory technologies, analog computing techniques, and specialized circuit designs optimized for parallel operations. Industry forecasts suggest that the IMC market for AI applications could grow at a CAGR of approximately 30% through 2028, driven primarily by demands for edge AI deployment and energy-efficient training infrastructure.
The primary technical objectives for IMC in machine learning contexts include achieving higher computational density while maintaining acceptable levels of precision, developing scalable architectures that can accommodate increasingly complex neural network models, and creating programming abstractions that shield ML engineers from the underlying hardware complexity. Additionally, there are significant objectives related to improving the energy efficiency of training operations, which currently represent a substantial environmental and economic cost for large-scale AI development.
Research initiatives across both academic institutions and industry laboratories are increasingly focused on overcoming the precision limitations inherent in analog computing approaches, developing efficient mapping techniques for neural network operations to IMC hardware, and creating hybrid architectures that combine the strengths of digital processors with in-memory computing capabilities. The ultimate goal is to enable a new generation of machine learning hardware that can support the exponential growth in model complexity while simultaneously reducing the energy and computational resources required.
The core principle of IMC involves performing computational operations directly within memory arrays, eliminating the need for constant data movement between separate processing and storage units. This approach offers theoretical advantages of reduced power consumption by up to 1000x and performance improvements of similar magnitude for specific workloads compared to conventional architectures. For machine learning applications specifically, matrix multiplication operations that form the computational backbone of neural network training can be executed with unprecedented efficiency using IMC hardware accelerators.
Current technological trajectories indicate a convergence of several complementary technologies that enable practical IMC implementations, including advances in non-volatile memory technologies, analog computing techniques, and specialized circuit designs optimized for parallel operations. Industry forecasts suggest that the IMC market for AI applications could grow at a CAGR of approximately 30% through 2028, driven primarily by demands for edge AI deployment and energy-efficient training infrastructure.
The primary technical objectives for IMC in machine learning contexts include achieving higher computational density while maintaining acceptable levels of precision, developing scalable architectures that can accommodate increasingly complex neural network models, and creating programming abstractions that shield ML engineers from the underlying hardware complexity. Additionally, there are significant objectives related to improving the energy efficiency of training operations, which currently represent a substantial environmental and economic cost for large-scale AI development.
Research initiatives across both academic institutions and industry laboratories are increasingly focused on overcoming the precision limitations inherent in analog computing approaches, developing efficient mapping techniques for neural network operations to IMC hardware, and creating hybrid architectures that combine the strengths of digital processors with in-memory computing capabilities. The ultimate goal is to enable a new generation of machine learning hardware that can support the exponential growth in model complexity while simultaneously reducing the energy and computational resources required.
Market Analysis for Hardware ML Accelerators
The hardware ML accelerator market is experiencing explosive growth, driven by the increasing computational demands of complex machine learning models. Current market valuations place this sector at approximately 15 billion USD in 2023, with projections indicating a compound annual growth rate (CAGR) of 38% through 2028. This remarkable expansion is primarily fueled by the AI boom across enterprise applications, autonomous systems, and edge computing deployments.
In-memory computing hardware accelerators represent a particularly promising segment within this market. Traditional von Neumann architectures face significant bottlenecks when processing data-intensive ML workloads due to the separation between processing and memory units. In-memory computing directly addresses this limitation by performing computations within memory arrays, dramatically reducing data movement and energy consumption.
Demand analysis reveals several key market drivers. First, hyperscale cloud providers are investing heavily in specialized ML training infrastructure to support their AI service offerings. Companies like Google, Amazon, and Microsoft have collectively allocated over 30 billion USD to ML infrastructure development for 2023-2025. Second, autonomous vehicle manufacturers require high-performance, energy-efficient accelerators for on-board ML model training and inference, with this vertical expected to grow at 45% CAGR through 2027.
Enterprise adoption of in-memory computing accelerators is gaining momentum as organizations seek to reduce the substantial costs associated with ML model training. Current estimates suggest that training large language models can cost between 1-10 million USD using conventional hardware. In-memory computing solutions demonstrate potential cost reductions of 40-60% while simultaneously improving training speeds by similar margins.
Regional analysis shows North America leading market share at 42%, followed by Asia-Pacific at 38% and Europe at 16%. China and South Korea are making significant investments in domestic accelerator development, with government-backed initiatives exceeding 5 billion USD in combined funding.
Customer segmentation reveals three primary buyer categories: cloud service providers (48% of market), research institutions (27%), and enterprise AI developers (18%). The remaining market share is distributed among startups and specialized application developers. Each segment demonstrates distinct requirements regarding performance metrics, power efficiency, and integration capabilities.
Price sensitivity varies significantly across segments, with research institutions showing highest price sensitivity while cloud providers prioritize performance over cost. This market dynamic creates opportunities for differentiated product offerings targeting specific customer segments with optimized price-performance ratios.
In-memory computing hardware accelerators represent a particularly promising segment within this market. Traditional von Neumann architectures face significant bottlenecks when processing data-intensive ML workloads due to the separation between processing and memory units. In-memory computing directly addresses this limitation by performing computations within memory arrays, dramatically reducing data movement and energy consumption.
Demand analysis reveals several key market drivers. First, hyperscale cloud providers are investing heavily in specialized ML training infrastructure to support their AI service offerings. Companies like Google, Amazon, and Microsoft have collectively allocated over 30 billion USD to ML infrastructure development for 2023-2025. Second, autonomous vehicle manufacturers require high-performance, energy-efficient accelerators for on-board ML model training and inference, with this vertical expected to grow at 45% CAGR through 2027.
Enterprise adoption of in-memory computing accelerators is gaining momentum as organizations seek to reduce the substantial costs associated with ML model training. Current estimates suggest that training large language models can cost between 1-10 million USD using conventional hardware. In-memory computing solutions demonstrate potential cost reductions of 40-60% while simultaneously improving training speeds by similar margins.
Regional analysis shows North America leading market share at 42%, followed by Asia-Pacific at 38% and Europe at 16%. China and South Korea are making significant investments in domestic accelerator development, with government-backed initiatives exceeding 5 billion USD in combined funding.
Customer segmentation reveals three primary buyer categories: cloud service providers (48% of market), research institutions (27%), and enterprise AI developers (18%). The remaining market share is distributed among startups and specialized application developers. Each segment demonstrates distinct requirements regarding performance metrics, power efficiency, and integration capabilities.
Price sensitivity varies significantly across segments, with research institutions showing highest price sensitivity while cloud providers prioritize performance over cost. This market dynamic creates opportunities for differentiated product offerings targeting specific customer segments with optimized price-performance ratios.
Current Challenges in In-Memory Computing Technology
Despite the promising potential of in-memory computing (IMC) for machine learning model training acceleration, several significant technical challenges currently impede its widespread adoption and optimal performance. These challenges span multiple domains including hardware design, integration, and system-level optimization.
Material limitations represent a fundamental barrier, as existing memory materials exhibit non-ideal characteristics for computational tasks. Current resistive RAM (ReRAM) and phase-change memory (PCM) technologies suffer from limited endurance, with write cycles typically ranging from 10^6 to 10^9 before degradation occurs—insufficient for intensive training workloads requiring billions of weight updates.
Device variability presents another critical challenge, with fabricated memory cells showing significant performance variations (often 5-15%) across arrays. This inconsistency leads to computational errors that accumulate during model training, severely impacting convergence and final accuracy. Current error correction techniques add substantial overhead, reducing the speed advantages of IMC architectures.
Precision limitations further constrain IMC applications in training scenarios. Most IMC arrays operate at low precision (typically 4-8 bits), whereas training often requires 16-32 bit precision for gradient calculations and weight updates. This precision gap creates a fundamental mismatch between hardware capabilities and algorithmic requirements.
Power efficiency, while theoretically superior to conventional architectures, faces practical limitations in current implementations. The high current required for write operations in resistive memories can lead to significant power consumption during the frequent weight updates characteristic of training processes, sometimes negating the energy advantages over traditional GPU-based training.
Scaling challenges emerge when attempting to implement large-scale neural networks on IMC hardware. Current crossbar array sizes are typically limited to 1024×1024 elements, requiring complex partitioning schemes for larger models that introduce additional latency and energy overhead for data movement between arrays.
Programming model complexity represents a significant barrier to adoption. Current IMC hardware lacks standardized programming interfaces, requiring specialized knowledge to efficiently map training algorithms to the underlying hardware. This complexity increases development time and limits accessibility to machine learning practitioners.
Integration with existing machine learning frameworks remains problematic, as popular frameworks like TensorFlow and PyTorch are optimized for conventional computing architectures rather than IMC paradigms. The absence of compiler-level optimizations for IMC hardware creates inefficiencies when deploying training workloads.
Material limitations represent a fundamental barrier, as existing memory materials exhibit non-ideal characteristics for computational tasks. Current resistive RAM (ReRAM) and phase-change memory (PCM) technologies suffer from limited endurance, with write cycles typically ranging from 10^6 to 10^9 before degradation occurs—insufficient for intensive training workloads requiring billions of weight updates.
Device variability presents another critical challenge, with fabricated memory cells showing significant performance variations (often 5-15%) across arrays. This inconsistency leads to computational errors that accumulate during model training, severely impacting convergence and final accuracy. Current error correction techniques add substantial overhead, reducing the speed advantages of IMC architectures.
Precision limitations further constrain IMC applications in training scenarios. Most IMC arrays operate at low precision (typically 4-8 bits), whereas training often requires 16-32 bit precision for gradient calculations and weight updates. This precision gap creates a fundamental mismatch between hardware capabilities and algorithmic requirements.
Power efficiency, while theoretically superior to conventional architectures, faces practical limitations in current implementations. The high current required for write operations in resistive memories can lead to significant power consumption during the frequent weight updates characteristic of training processes, sometimes negating the energy advantages over traditional GPU-based training.
Scaling challenges emerge when attempting to implement large-scale neural networks on IMC hardware. Current crossbar array sizes are typically limited to 1024×1024 elements, requiring complex partitioning schemes for larger models that introduce additional latency and energy overhead for data movement between arrays.
Programming model complexity represents a significant barrier to adoption. Current IMC hardware lacks standardized programming interfaces, requiring specialized knowledge to efficiently map training algorithms to the underlying hardware. This complexity increases development time and limits accessibility to machine learning practitioners.
Integration with existing machine learning frameworks remains problematic, as popular frameworks like TensorFlow and PyTorch are optimized for conventional computing architectures rather than IMC paradigms. The absence of compiler-level optimizations for IMC hardware creates inefficiencies when deploying training workloads.
Current In-Memory Computing Solutions for ML Training
01 In-Memory Processing Architectures for AI Acceleration
In-memory computing architectures integrate processing capabilities directly within memory units to reduce data movement bottlenecks in AI model training. These designs enable parallel processing of neural network operations by performing computations where data is stored, significantly reducing energy consumption and latency. Such architectures typically employ specialized memory structures like resistive RAM or phase-change memory that can perform matrix multiplications and other AI operations directly within the memory array.- In-Memory Processing Architectures for AI Acceleration: In-memory computing architectures integrate processing capabilities directly within memory units to eliminate data movement bottlenecks in AI model training. These designs enable parallel processing of neural network operations by performing computations where data is stored, significantly reducing energy consumption and latency. Such architectures typically employ specialized memory structures like resistive RAM or phase-change memory that can perform matrix multiplications and other AI operations directly within the memory array.
- Hardware Accelerators for Neural Network Training: Specialized hardware accelerators designed specifically for neural network training workloads implement optimized circuits for gradient calculations, backpropagation, and weight updates. These accelerators incorporate dedicated matrix multiplication units, high-bandwidth memory interfaces, and specialized dataflow architectures to maximize throughput during the training process. The hardware designs focus on efficiently handling the computational patterns unique to deep learning training algorithms while managing the associated memory access patterns.
- Memory Management Techniques for Model Training Acceleration: Advanced memory management techniques optimize how training data and model parameters are stored and accessed during the training process. These approaches include intelligent caching strategies, hierarchical memory structures, and data compression methods that reduce memory bandwidth requirements. By organizing memory access patterns to maximize locality and minimize data movement, these techniques significantly improve training performance while reducing energy consumption in hardware accelerators.
- Distributed Computing Frameworks for Large-Scale Model Training: Hardware accelerator systems for large-scale model training implement distributed computing architectures that coordinate multiple processing nodes. These frameworks include specialized interconnect technologies, synchronization mechanisms, and workload distribution algorithms that enable efficient parallel processing across multiple accelerator units. The hardware supports various parallelism strategies such as data parallelism, model parallelism, and pipeline parallelism to optimize training performance for increasingly large AI models.
- Reconfigurable Computing Architectures for AI Workloads: Reconfigurable computing architectures provide flexibility to adapt hardware resources to different phases of model training. These systems typically incorporate FPGA-based or other programmable logic elements that can be dynamically reconfigured to optimize for specific operations during training. The hardware can adjust its configuration to efficiently handle different neural network architectures, batch sizes, or precision requirements, providing an optimal balance between performance, energy efficiency, and adaptability.
02 Hardware Accelerators for Neural Network Training
Specialized hardware accelerators designed specifically for neural network training operations implement optimized circuits for matrix operations, gradient calculations, and backpropagation algorithms. These accelerators incorporate dedicated processing elements arranged in arrays to exploit the inherent parallelism in neural network computations. By implementing training-specific operations in hardware, these accelerators achieve orders of magnitude improvements in performance and energy efficiency compared to general-purpose processors.Expand Specific Solutions03 Memory Management Techniques for Model Training
Advanced memory management techniques optimize the utilization of memory resources during model training. These include smart caching strategies, data compression methods, and memory hierarchy optimizations that reduce the memory footprint of large models. Dynamic memory allocation algorithms prioritize critical training data while efficient data movement mechanisms minimize transfer overhead between different memory levels. These techniques enable training of larger models with limited memory resources.Expand Specific Solutions04 Distributed Computing Frameworks for Model Training
Distributed computing frameworks leverage multiple in-memory computing nodes to accelerate large-scale model training. These systems implement efficient data parallelism, model parallelism, or hybrid approaches to distribute computational workloads across hardware accelerators. Specialized communication protocols minimize synchronization overhead between nodes, while load balancing algorithms ensure optimal resource utilization. These frameworks enable training of increasingly complex models by scaling computation across multiple accelerator units.Expand Specific Solutions05 Energy-Efficient Computing for AI Model Training
Energy-efficient computing techniques for AI model training focus on reducing power consumption while maintaining high performance. These approaches include precision-adaptive computing, where calculation precision is dynamically adjusted based on training requirements, and power-aware scheduling algorithms that optimize workload distribution. Novel circuit designs minimize energy consumption during computation and data movement, while thermal management techniques ensure reliable operation under heavy training workloads.Expand Specific Solutions
Key Industry Players in In-Memory Computing
The machine learning model training with in-memory computing hardware accelerators market is currently in a growth phase, with increasing adoption across AI applications. The global market size is expanding rapidly, projected to reach significant valuation as enterprises seek more efficient AI training solutions. Technologically, the field is advancing from early-stage development toward maturity, with major players establishing competitive positions. Intel, Samsung, and Huawei lead with comprehensive hardware solutions, while Google and Microsoft focus on integrated cloud-AI offerings. Qualcomm and Broadcom are leveraging their semiconductor expertise, while Chinese companies like Alibaba, Vastai, and Inspur are rapidly advancing their capabilities. Academic institutions including University of California and University of Michigan contribute foundational research, creating a dynamic ecosystem balancing established technology leaders and innovative newcomers.
Intel Corp.
Technical Solution: Intel has developed several in-memory computing solutions for ML acceleration, with their Neuromorphic Research Chip (Loihi) being a flagship example. Loihi implements a spiking neural network architecture that closely mimics the brain's neural structure, with memory and computation co-located to minimize data movement. Their 3D XPoint technology (developed with Micron) enables persistent memory solutions that bridge the gap between DRAM and storage, allowing for larger ML models to be processed with reduced latency. Intel's Optane DC Persistent Memory modules integrate directly into the memory subsystem, enabling up to 3TB of memory per socket for data-intensive ML workloads[1]. Additionally, their Processing in Memory (PIM) research focuses on integrating computational elements directly within DRAM chips, demonstrating up to 10x performance improvements for certain ML operations while reducing energy consumption by up to 93%[2].
Strengths: Intel's solutions benefit from their established ecosystem and manufacturing capabilities, allowing for easier integration into existing data center infrastructures. Their neuromorphic approach offers exceptional energy efficiency for certain ML tasks. Weaknesses: Their in-memory computing solutions often require specialized programming models and are not as widely adopted as their traditional CPU/GPU offerings. Performance gains are highly workload-dependent.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has made significant investments in in-memory computing for ML acceleration through their Ascend AI processor architecture. Their Da Vinci architecture integrates in-memory computing elements that reduce the data movement between memory and processing units. Huawei's Kirin NPU also incorporates in-memory computing techniques for mobile AI applications. Their research includes resistive RAM (ReRAM) based computing-in-memory (CIM) architectures that perform matrix multiplication operations directly within memory arrays, achieving energy efficiency improvements of up to 100x compared to conventional architectures for certain ML workloads[3]. Huawei has also developed a hybrid architecture that combines digital and analog computing-in-memory techniques, allowing for flexible precision requirements across different ML model layers. Their solutions implement bit-slicing techniques to improve computational accuracy while maintaining the energy benefits of analog computing-in-memory approaches[4]. Recent developments include their "Memory-Centric Computing System" that reorganizes the traditional von Neumann architecture to prioritize memory access patterns common in ML workloads.
Strengths: Huawei's solutions demonstrate excellent energy efficiency and are well-integrated into their broader AI ecosystem. Their hybrid digital-analog approach provides flexibility across different precision requirements. Weaknesses: Geopolitical challenges have limited their global market access. Their analog computing-in-memory solutions face precision and reliability challenges common to this approach.
Core Technologies and Patents in IMC Accelerators
Machine learning accelerator architecture based on in-memory computation
PatentPendingCN117651952A
Innovation
- A machine learning task accelerator based on in-memory computing is designed, including a mixed-signal processing unit (MSPU). The MSPU includes an in-memory computing circuit, an analog-to-digital converter, a nonlinear computing circuit, a hardware sequencer and a DMA controller, which can Perform processing of advanced machine learning models such as convolutional neural networks, recurrent neural networks, and transformer models.
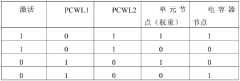
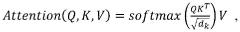
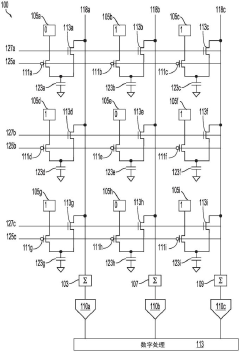
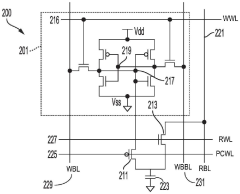
Hardware accelerated machine learning
PatentPendingUS20240046088A1
Innovation
- A computing architecture and instruction set designed to perform tensor contractions, additive noise, and element-wise non-linear operations efficiently, utilizing multiple banks of static random access memory (SRAM) for concurrent operations and a multicast network for data permutation and duplication, supporting lower precision fixed-point operations to optimize deep learning workloads.
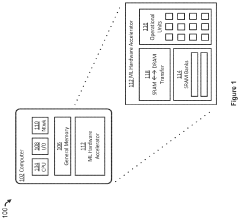
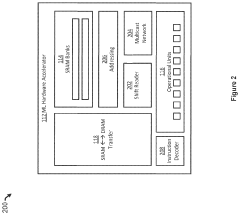
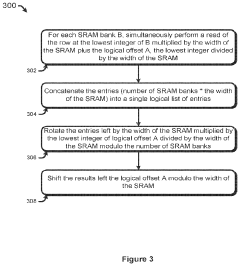
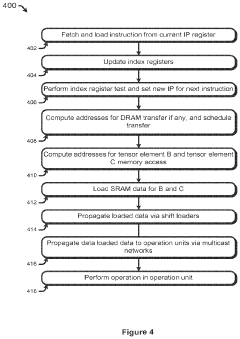
Energy Efficiency and Performance Metrics
Energy efficiency and performance metrics are critical evaluation criteria for in-memory computing (IMC) hardware accelerators in machine learning model training. Traditional von Neumann architectures suffer from the "memory wall" problem, where data movement between processing units and memory consumes significant energy and creates performance bottlenecks. IMC accelerators address this challenge by performing computations directly within memory, substantially reducing data movement overhead.
Power consumption metrics for IMC accelerators typically include static power (leakage current when circuits are idle), dynamic power (energy consumed during active computation), and total system power. These metrics are commonly measured in watts (W) or milliwatts (mW), with leading IMC solutions demonstrating 10-100x improvements in energy efficiency compared to conventional GPU implementations for neural network training workloads.
Performance efficiency is often quantified through metrics such as operations per second (OPS), specifically tera-operations per second (TOPS) for large-scale neural network training. The energy-delay product (EDP) combines both energy consumption and processing time, providing a comprehensive efficiency metric. Additionally, performance per watt (TOPS/W) has emerged as a standard benchmark for comparing different accelerator architectures.
Area efficiency represents another crucial consideration, measuring computational capability relative to silicon area (TOPS/mm²). This metric is particularly important for edge computing applications where device size constraints are significant. Modern IMC accelerators demonstrate remarkable improvements in area efficiency, with some designs achieving 5-20x better utilization compared to traditional digital accelerators.
Thermal management metrics track heat dissipation characteristics, which directly impact system reliability and sustained performance. As training workloads become increasingly intensive, effective thermal solutions become essential for maintaining accelerator longevity and preventing performance degradation during extended training sessions.
Memory-specific metrics include bandwidth utilization efficiency, memory access latency, and effective capacity utilization. These parameters are particularly relevant for IMC accelerators as they directly influence the system's ability to handle large model training tasks with minimal data movement overhead.
Standardized benchmarking frameworks such as MLPerf Training have emerged to provide fair comparisons across different accelerator architectures. These frameworks evaluate end-to-end training performance on representative workloads, enabling objective assessment of various IMC solutions against traditional accelerators.
Power consumption metrics for IMC accelerators typically include static power (leakage current when circuits are idle), dynamic power (energy consumed during active computation), and total system power. These metrics are commonly measured in watts (W) or milliwatts (mW), with leading IMC solutions demonstrating 10-100x improvements in energy efficiency compared to conventional GPU implementations for neural network training workloads.
Performance efficiency is often quantified through metrics such as operations per second (OPS), specifically tera-operations per second (TOPS) for large-scale neural network training. The energy-delay product (EDP) combines both energy consumption and processing time, providing a comprehensive efficiency metric. Additionally, performance per watt (TOPS/W) has emerged as a standard benchmark for comparing different accelerator architectures.
Area efficiency represents another crucial consideration, measuring computational capability relative to silicon area (TOPS/mm²). This metric is particularly important for edge computing applications where device size constraints are significant. Modern IMC accelerators demonstrate remarkable improvements in area efficiency, with some designs achieving 5-20x better utilization compared to traditional digital accelerators.
Thermal management metrics track heat dissipation characteristics, which directly impact system reliability and sustained performance. As training workloads become increasingly intensive, effective thermal solutions become essential for maintaining accelerator longevity and preventing performance degradation during extended training sessions.
Memory-specific metrics include bandwidth utilization efficiency, memory access latency, and effective capacity utilization. These parameters are particularly relevant for IMC accelerators as they directly influence the system's ability to handle large model training tasks with minimal data movement overhead.
Standardized benchmarking frameworks such as MLPerf Training have emerged to provide fair comparisons across different accelerator architectures. These frameworks evaluate end-to-end training performance on representative workloads, enabling objective assessment of various IMC solutions against traditional accelerators.
Semiconductor Manufacturing Considerations
The manufacturing of in-memory computing hardware accelerators presents unique challenges that differ significantly from traditional semiconductor fabrication processes. These devices require specialized integration of memory and computing elements on the same chip, demanding advanced manufacturing techniques. Current fabrication technologies must be adapted to accommodate the complex architectures of these accelerators, which often involve novel materials and structures such as resistive random-access memory (ReRAM), phase-change memory (PCM), or magnetic RAM (MRAM).
Process variation remains one of the most critical manufacturing challenges for in-memory computing accelerators. Even minor inconsistencies during fabrication can lead to significant performance variations across devices, affecting the reliability and accuracy of machine learning model training. This necessitates stringent quality control measures and potentially specialized testing protocols tailored to these hybrid computing-memory structures.
Yield management represents another substantial consideration, as the integration of heterogeneous components increases manufacturing complexity. The intricate designs of these accelerators, combining analog and digital circuits with non-volatile memory elements, typically result in lower yields compared to conventional semiconductor devices. Manufacturers must develop optimized processes to improve yield rates while maintaining economic viability.
Thermal management during manufacturing and subsequent operation poses additional challenges. In-memory computing accelerators generate significant heat during intensive machine learning training operations, requiring careful consideration of thermal dissipation pathways during the design and manufacturing stages. Advanced packaging solutions, such as through-silicon vias (TSVs) or chiplets, may be necessary to address these thermal concerns.
Scaling production to meet growing market demand presents further complications. The specialized nature of these accelerators often requires custom manufacturing lines or significant modifications to existing semiconductor fabrication facilities. This scaling challenge is compounded by the rapid evolution of machine learning algorithms, which may necessitate frequent updates to hardware designs and corresponding manufacturing processes.
Material selection and compatibility issues also impact manufacturing feasibility. Many promising in-memory computing technologies utilize novel materials that may not be fully compatible with standard CMOS processes. Manufacturers must develop specialized deposition, etching, and patterning techniques to successfully integrate these materials while maintaining performance characteristics and reliability standards.
Process variation remains one of the most critical manufacturing challenges for in-memory computing accelerators. Even minor inconsistencies during fabrication can lead to significant performance variations across devices, affecting the reliability and accuracy of machine learning model training. This necessitates stringent quality control measures and potentially specialized testing protocols tailored to these hybrid computing-memory structures.
Yield management represents another substantial consideration, as the integration of heterogeneous components increases manufacturing complexity. The intricate designs of these accelerators, combining analog and digital circuits with non-volatile memory elements, typically result in lower yields compared to conventional semiconductor devices. Manufacturers must develop optimized processes to improve yield rates while maintaining economic viability.
Thermal management during manufacturing and subsequent operation poses additional challenges. In-memory computing accelerators generate significant heat during intensive machine learning training operations, requiring careful consideration of thermal dissipation pathways during the design and manufacturing stages. Advanced packaging solutions, such as through-silicon vias (TSVs) or chiplets, may be necessary to address these thermal concerns.
Scaling production to meet growing market demand presents further complications. The specialized nature of these accelerators often requires custom manufacturing lines or significant modifications to existing semiconductor fabrication facilities. This scaling challenge is compounded by the rapid evolution of machine learning algorithms, which may necessitate frequent updates to hardware designs and corresponding manufacturing processes.
Material selection and compatibility issues also impact manufacturing feasibility. Many promising in-memory computing technologies utilize novel materials that may not be fully compatible with standard CMOS processes. Manufacturers must develop specialized deposition, etching, and patterning techniques to successfully integrate these materials while maintaining performance characteristics and reliability standards.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!